享学课堂作者:逐梦々少年
转载请声明出处!
上次我们详细的学习了Java中的序列化机制,但是我们日常开发过程中,因为java的序列化机制的压缩效率问题,以及序列化大小带来的传输的效率问题,一般很少会使用原生的序列化机制,而是使用常见的序列化开源框架来实现序列化操作,接下来我们学习一下开发常用的序列化机制及原理分析
常见的序列化框架
xml序列化
在java发展早期开始,为了统一接口,xml协议横空出世,良好的可读性,自由度极高的扩展性,成了很长一段时间的序列化标准规范。实现xml序列化/反序列化的方案有很多,最常见的是XStream 和 Java 自带的 XML 序列化和反序列化两种 ,并且还有基于xml协议的soap协议实现的webservice接口等。可以说xml序列化是开发中最常见也是发展时间最久的协议,并且支持跨进程和跨语言交互,但是缺陷也很明显,即xml规范下的每一个属性和值都是固定的标签形式,导致序列化后的字节流文件很大,远超于java自身的序列化方案,而且效率很低,一般建议使用在内部系统或者性能要求不高,但是对于接口的复杂度和准确性要求比较高的接口交互,或者适合多语言多进程之间交互的统一规范,不适合QPS过高的工程使用
JSON序列化
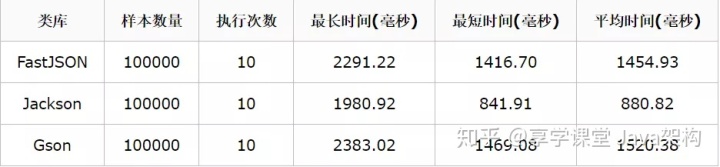
在xml序列化发展了多年后,也浮现了一些问题,比如开发并不简便,解析xml复杂度较高,还有xml的标准规范比较多,自由度过高,导致很难有效的指定格式校验等,于是一种新的轻量级的序列化交互的方案--JSON(JavaScript Object Notation)出现了,相对于xml来说,json格式语法简单,自由度较高,有很高的可读性,并且在JSON序列化后的字节流小于xml序列化的结果,解析起来更方便,于是基于JSON的接口成了新的标准规范之一,到现在也出现了很多JSON的序列化/反序列化的开源框架,比如开发中最常见到的Jackson、阿里巴巴开源的FastJson、谷歌的GSON等,而这三种框架各有优劣,通过测试一万个对象的序列化和反序列化的效率,对比如下:
序列化:
反序列化:
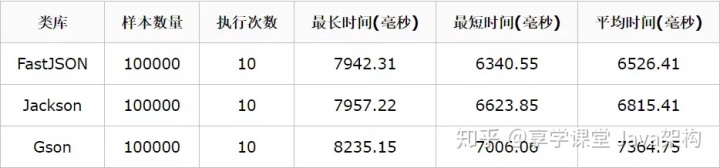
可以看出来序列化的时候,Gson的速度明显稍微慢了一些,Jackson反而最快,而在反序列化的时候,三个表现都很稳定,时间都差不多,但是当数据比较大的时候,测试结果又有所不同,测试结果和数据来自https://blog.csdn.net/Sword52888/article/details/81062575 提供的代码和脚本,可以得出对应结论:
- 1、 当数据小于 100K 的时候,建议使用 Gson
- 2、 当数据100K 与 1M 的之间时候,建议使用各个JSON引擎性能差不多
- 3、 当数据大与 1M 的时候,建议使用 JackSon 与 FastJson
而在稳定性上面,默认情况下Gson在各种情况下的表现最好,Jackson配合对应的配置化也能达到很好的稳定性,而FastJson表现的不稳定,所以对于这几种json库的使用,建议环境较复杂场景下使用JackSon,加上自定义的配置化可以更灵活的处理更多的场景,但是在复杂度一般,仅仅在乎性能的场景下,建议使用FastJson,因为FastJson的api更易用,依赖少,简单场景下使用简单
Hessian序列化
Hessian是一个支持跨语言传输的二进制文本序列化协议,对比Java默认的序列化,Hessian的使用较简单,并且性能较高,现在的主流远程通讯框架几乎都支持Hessian,比如Dubbo,默认使用的就是Hessian,不过是Hessian的重构版
Avro序列化
Avro序列化设计初衷是为了支持大批量数据交换的应用,支持二进制序列化方式,并且自身提供了动态语言支持,可以更加便捷、快速处理大批量的Avro数据
Kyro序列化
Kyro序列化是主流的比较成熟的序列化方案之一,目前广泛使用在大数据组件中,比如Hive、Storm等,性能比起Hessian还要优越,但是缺陷较明显,不支持跨语言交互,在dubbo2.6.x版本开始已经加入了Kyro序列化的支持
Protobuf序列化
Protobuf是谷歌提出的序列化方案,不同的是此方案独立于语言、平台,谷歌提供了多个语言如java、c、go、python等语言的实现,也提供了多平台的库文件支持,使用比较广泛,优点在于性能开销很小,压缩率很高,但是缺陷也很明显,可读性很差,并且protobuf需要使用特定语言的库进行翻译转换,使用起来较为麻烦
Protobuf序列化的使用
首先现在使用Protobuf,有手动编译和maven依赖jar两种方案,实际开发中我们一般使用maven坐标引入jar,坐标如下:
<dependency><groupId>com.dyuproject.protostuff</groupId><artifactId>protostuff-core</artifactId><version>1.0.8</version></dependency><dependency><groupId>com.dyuproject.protostuff</groupId><artifactId>protostuff-runtime</artifactId><version>1.0.8</version></dependency>编写一个便捷的序列化转换工具类:
package com.demo.utils;import com.dyuproject.protostuff.LinkedBuffer;
import com.dyuproject.protostuff.ProtobufIOUtil;
import com.dyuproject.protostuff.runtime.RuntimeSchema;public class SerializeUtils{/****序列化方法*/public static <T> byte[] serialize(T t,Class<T> clazz) {return ProtobufIOUtil.toByteArray(t, RuntimeSchema.createFrom(clazz),LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE));}/****反序列化方法*/public static <T> T deSerialize(byte[] data,Class<T> clazz) {RuntimeSchema<T> runtimeSchema = RuntimeSchema.createFrom(clazz);T t = runtimeSchema.newMessage();ProtobufIOUtil.mergeFrom(data, t, runtimeSchema);return t;}使用的时候直接使用工具类进行自动的转换传输即可
注:使用的时候注意jdk版本和jar版本的兼容问题,并且需要序列化的实体并不需要实现Serializable 接口
当然,我们接下来手动编译protobuf使用,了解下protobuf的语法以及原理
手动编译Protobuf
手动编译protobuf我们需要一个Protobuf编译器的支持,这里推荐直接点击地址,在github上下载:
https://github.com/google/protobuf/releases
或者直接百度云:http://pan.baidu.com/s/1gefsM9X 下载,这里博主选择直接百度云集成的环境下载
1:解压protoc-3.0.0-beta-2-win32会得到一个protoc.exe的文件.
2:解压protobuf-3.0.0-beta-2.(3.0.0-beta是版本号,可能会有所不同)
3.将protoc.exe文件放到2步骤解压后文件夹java/src/这个目录里面(src里面,不是跟src并级)
4.WINDOS+R 输入cmd命令并切换至3步骤的src目录的上级目录,就是java目录下会发现这个目录有个POM文件,使用maven编译命令编译(mvn install),然后会在java目录下生成target以及一个jar。OK到目前位置,安装算完成了
接下来是编译环节,将上面生成的那个jar和一开始的那个exe文件放到需要编译文件的同一目录下 ,使用编译指令(cmd):
protoc --java_out=xxx/xxx.proto如果出现:Missing input file错误,那么就使用 以下指令:
protoc xxx/xxx.proto --java_out=./接下来,我们开始编写一个protobuf的简单demo,后缀为proto,代码如下:
syntax="proto2";
package com.demo.serial;
option java_package = "com.demo.serial";
option java_outer_classname="UserProtos";
message User {
required string name=1;
required int32 age=2;
}首先我们先看看上面编写的内容分别代表什么意思:
syntax="proto2";
这里指定了protobuf编译的版本,目前主流为proto2,当然也有不少选择最新的proto3版本,而每个大版本之间的差异还是很大的,具体区别参见官方说明:https://developers.google.com/protocol-buffers/docs/proto3
接着是:
option java_package = "com.demo.serial"
这里指定的是上一行我们设置的package对应java文件里面的package名称
option java_outer_classname="UserProtos"
这里指定了如果编译完毕生成的java类的名称
message User
这里的message代表给User类指定对应属性类型
required string name=1
这里出现了一个特殊的修饰符类型required,在protobuf中,有如下几种修饰符:
- required: 格式良好的 message 必须包含该字段一次。
- optional: 格式良好的 message 可以包含该字段零次或一次(不超过一次)。
- repeated: 该字段可以在格式良好的消息中重复任意多次(包括零)。其中重复值的顺序会被保留。
注意:在proto3版本中,为了兼容性考虑,required修饰符已经取消
完成这些以后,我们使用指令:
protoc --java_out=xxx/xxx.proto生成protobuf转换后的实体类,然后我们在pom中引入:
<dependency> <groupId>com.google.protobuf</groupId><artifactId>protobuf.java</artifactId><version>3.7.0</version>
</dependency>然后进行序列化:
UserProtos.User user=UserProtos.User.newBuilder().setAge(300).setName("Mic").build();
byte[] bytes=user.toByteArray();
for(byte bt:bytes){
System.out.print(bt+" ");
}我们将这个结果打印出来的字节如下:
10 3 77 105 99 16 -84 2可以看出来序列化的数值看不明白,但是的确字节数很小,说明protobuf进行了算法压缩,那么我们就要了解下protobuf压缩算法相关的详细操作,首先我们要知道protobuf的type对应的各个语言的类型:
.proto TypeNotesC++ TypeJava TypePython Type[2]Go Typedoubledoubledoublefloat*float64floatfloatfloatfloat*float32int32使用可变长度编码。编码负数的效率低 - 如果你的字段可能有负值,请改用 sint32int32intint*int32int64使用可变长度编码。编码负数的效率低 - 如果你的字段可能有负值,请改用 sint64int64longint/long[3]*int64uint32使用可变长度编码uint32int[1]int/long[3]*uint32uint64使用可变长度编码uint64long[1]int/long[3]*uint64sint32使用可变长度编码。有符号的 int 值。这些比常规 int32 对负数能更有效地编码int32intint*int32sint64使用可变长度编码。有符号的 int 值。这些比常规 int64 对负数能更有效地编码int64longint/long[3]*int64fixed32总是四个字节。如果值通常大于 228,则比 uint32 更有效。uint32int[1]int/long[3]*uint32fixed64总是八个字节。如果值通常大于 256,则比 uint64 更有效。uint64long[1]int/long[3]*uint64sfixed32总是四个字节int32intint*int32sfixed64总是八个字节int64longint/long[3]*int64boolboolbooleanbool*boolstring字符串必须始终包含 UTF-8 编码或 7 位 ASCII 文本stringStringstr/unicode[4]*stringbytes可以包含任意字节序列stringByteStringstr[]byte
Protobuf序列化的原理分析
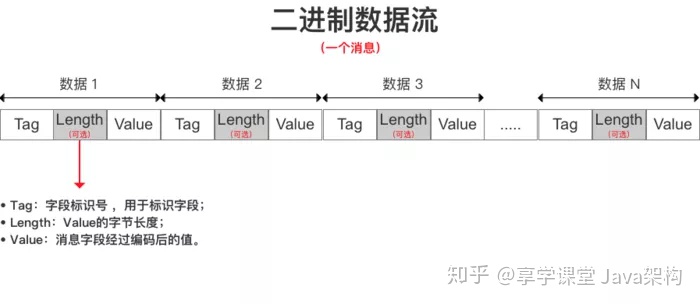
了解了Protobuf的type转换的格式以后,我们再来看,Protobuf的存储格式,Protobuf采用了T-L-V的存储格式存储数据,其中的T代表tag,即key,L则是length,代表当前存储的类型的数据长度,当是数值类型的时候L被忽略,V代表value,即存入的值,protobuf会将每一个key根据不同的类型对应的序列化算法进行序列化,然后按照keyvaluekeyvalue的格式存储,其中key的type类型与对应的压缩算法关系如下:
write_type编码方式type存储方式0Varint(负数使用Zigzag辅助)int32、int64、uint32、uint64、sint32、sint64、bool、enumT-V164-bitfixed、sfixed64、doubleT-V2Length-delimistring、bytes、embedded、messages、packed repeated fieldsT-L-V3(弃用)Start groupGroups(deprecated)弃用4(弃用)End groupGroups(deprecated)弃用532-bitfixed32、sfixed32、floatT-V
需要注意的是protobuf的key计算按照(field_number << 3) | wire_type 方式计算,而这里的field_number是指定义的时候该字段的域号,如:required string name=1;这里的name字段的域号为1,在protobuf中规定:
- 如果域号在[1,15]范围内,会使用一个字节表示Key;
- 如果域号大于等于16,会使用两个字节表示Key;
key编码完成后,该字节的第一个比特位表示后一个字节是否与当前字节有关系,即:
- 如果第一个比特位为1,表示有关,即连续两个字节都是Key的编码;
- 如果第一个比特位为0,表示Key的编码只有当前一个字节,后面的字节是Length或者Value;
注意:protobuf中的域号定义要小于2048 ,原因为,最大的域号即2个字节16个比特位表示key,去掉位移的三位,还剩下13位,再去掉两个字节开头的第一个用来表示是否存在关系的比特位,即16-3-2=11,最后只有11位参与计算,二进制计算后2^11== 2048 ,所以域号不得超过2048
了解了以上的那些,我们看看,上述我们编写的案例,算法是如何实现的呢?
varint编码
上述我们的案例中,出现了int32类型,对应的压缩算法为varint,我们看下age=300,这个值是如何序列化的
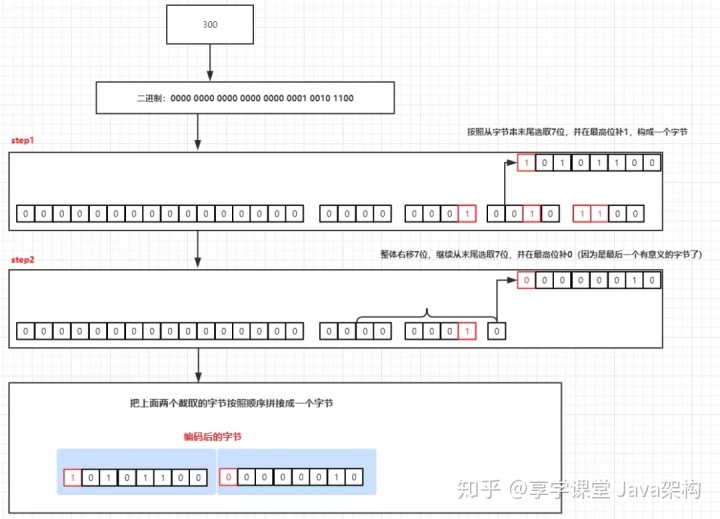
可以看出来,我们首先将300转为二进制,结果为100101100,由于当前是int32,所以不足32位,高位全部补0,即为00000000000000000000000100101100,接着第二步,从低位到高位取7位,8位是一个字节,当前的最高位为标志位,如果下一个字节内还有非0得数值(即有意义存在),则最高位补1,如果没有最高位补0,当最高位为0后,压缩存储结束,从age=300,我们可以看出来,取7位则是0101100,由于后一个字节中还存在值,所以最高位补1,则为10101100,而下一个字节则从第8位(低位到高位)开始,继续获取7个字节,则为0000010,由于后续的一个字节中,不存在有意义的值,则最高位补0,代表后续不存在有意义的值了,不需要继续压缩,则为00000010,也就是说原本32个比特位的数值,现在只有16个比特位,4个字节压缩到了2个字节,而我们都知道计算机中,高位为1代表负数,计算机中对负数的计算为先将结果取反后,再去补码操作,而负数的补码则是在反码的基础上+1,那么我们现在将结果反过来,先去-1,得到反码,则为10101011,再去取反,得到原码,则为01010100,现在我们将这个值转换为十进制,则可以知道结果为84,由于高位为1,则代表是负数,最终结果为-84,而00000010由于高位是0,代表本身为正数,正数的原码反码补码都是自身,所以直接转换为十进制结果为2,现在我们把这两个结果和上述打印的结果比较一下,是不是发现是一样的?当然,我们也从这个过程中发现了一些问题,比如小于128的值,我们甚至只需要1个字节就能存储完毕,但是如果我们需要存储的值很大,超过了268435455以后的数值,甚至需要五个字节来存储(超过28个有效比特位),但是绝大多数情况下,我们都不会使用这么大的数值,所以一般情况下,我们都能比之前使用更小的字节存储,达到压缩的目的
字符串压缩
在Protobuf中存储字符串格式,使用的T-L-V存储方式,标识符Tag采用Varint编码,字节长度Length采用Varint编码,string类型字段值采用UTF-8编码方式存储,所以tag得值为1 <<3 | 2 =10,L的值存储为00000011,即为3,而V的存储,把每一个字符按照UTF-8的编码后的字节流数组,分别为77 105 99,而在Protobuf编码后的字节流则是按照如图的顺序,所以打印出来的结果如上的10 3 77 105 99 16 -84 2
负数存储-write_type为0
在计算机中,负数会被表示为很大的整数,因为计算机定义负数符号位为数字的最高位,所
以如果采用 varint 编码表示一个负数,那么一定需要 5 个比特位。所以在 protobuf 中通过
sint32/sint64 类型来表示负数,负数的处理形式是先采用 zigzag 编码(把符号数转化为无符
号数),在采用 varint 编码。
sint32:(n << 1) ^ (n >> 31)
sint64:(n << 1) ^ (n >> 63)
比如存储一个(-300)的值
-300
原码:0001 0010 1100
取反:1110 1101 0011
加 1 :1110 1101 0100
n<<1: 整体左移一位,右边补 0 -> 1101 1010 1000
n>>31: 整体右移 31 位,左边补 1 -> 1111 1111 1111
n<<1 ^ n >>31
1101 1010 1000 ^ 1111 1111 1111 = 0010 0101 0111
十进制: 0010 0101 0111 = 599
然后再使用varint 算法得到两个字节
1101 0111(-41),0000 0100(4)
总结
基于Protobuf序列化原理分析,为了有效降低序列化后数据量的大小,可以采用以下措施:
- 字段标识号(Field_Number)尽量只使用1-15,且不要跳动使用 Tag是需要占字节空间的。如果Field_Number>16时,Field_Number的编码就会占用2个字节,那么Tag在编码时就会占用更多的字节;如果将字段标识号定义为连续递增的数值,将获得更好的编码和解码性能
- 若需要使用的字段值出现负数,请使用sint32/sint64,不要使用int32/int64。 采用sint32/sint64数据类型表示负数时,会先采用Zigzag编码再采用Varint编码,从而更加有效压缩数据
- 对于repeated字段,尽量增加packed=true修饰 增加packed=true修饰,repeated字段会采用连续数据存储方式,即T - L - V - V -V方式
2.将结果赋值给a,则a = 3
public static void main(String[] args){int a = 8;a ^= 11;//a = 8^11 = 3System.out.println(a);//3}既然来了,点个关注再走呗~
安装docker)
...)









)
)






