许多人都有这样一种映像,NodeJS比较快; 但是因为其是单线程,所以它不稳定,有点不安全,不适合处理复杂业务; 它比较适合对并发要求比较高,而且简单的业务场景。
在Express的作者的TJ Holowaychuk的 告别Node.js一文中列举了以下罪状:
Farewell NodeJS (TJ Holowaychuk)
• you may get duplicate callbacks
• you may not get a callback at all (lost in limbo)
• you may get out-of-band errors
• emitters may get multiple “error” events
• missing “error” events sends everything to hell
• often unsure what requires “error” handlers
• “error” handlers are very verbose
• callbacks suck
其实这几条主要吐嘈了两点: node.js错误处理很扯蛋,node.js的回调也很扯蛋。
事实上呢?
事实上NodeJS里程确实有“脆弱”的一面,单线程的某处产生了“未处理的”异常确实会导致整个Node.JS的崩溃退出,来看个例子, 这里有一个node-error.js的文件:
var http = require('http'); var server = http.createServer(function (req, res) { //这里有个错误,params 是 undefined var ok = req.params.ok; res.writeHead(200, {'Content-Type': 'text/plain'}); res.end('Hello World\n'); }); server.listen(8080, '127.0.0.1'); console.log('Server running at http://127.0.0.1:8080/');
启动服务,并在地址栏测试一下发现 http://127.0.0.1:8080/ 不出所料,node崩溃了
$ node node-error
Server running at http://127.0.0.1:8080/
c:\github\script\node-error.js:5
var ok = req.params.ok;
^
TypeError: Cannot read property 'ok' of undefined
at Server.<anonymous> (c:\github\script\node-error.js:5:22)
at Server.EventEmitter.emit (events.js:98:17)
at HTTPParser.parser.onIncoming (http.js:2108:12)
at HTTPParser.parserOnHeadersComplete [as onHeadersComplete] (http.js:121:23)
at Socket.socket.ondata (http.js:1966:22)
at TCP.onread (net.js:525:27)
怎么解决呢?
其实Node.JS发展到今天,如果连这个问题都解决不了,那估计早就没人用了。
使用uncaughtException
我们可以uncaughtException来全局捕获未捕获的Error,同时你还可以将此函数的调用栈打印出来,捕获之后可以有效防止node进程退出,如:
process.on('uncaughtException', function (err) {
//打印出错误
console.log(err);
//打印出错误的调用栈方便调试
console.log(err.stack);
});
这相当于在node进程内部进行守护, 但这种方法很多人都是不提倡的,说明你还不能完全掌控Node.JS的异常。
使用 try/catch
我们还可以在回调前加try/catch,同样确保线程的安全。
var http = require('http');
http.createServer(function(req, res) {
try {
handler(req, res);
} catch(e) {
console.log('\r\n', e, '\r\n', e.stack);
try {
res.end(e.stack);
} catch(e) { }
}
}).listen(8080, '127.0.0.1');
console.log('Server running at http://127.0.0.1:8080/');
var handler = function (req, res) {
//Error Popuped
var name = req.params.name;
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello ' + name);
};
这种方案的好处是,可以将错误和调用栈直接输出到当前发生的网页上。
集成到框架中
标准的HTTP响应处理会经历一系列的Middleware(HttpModule),最终到达Handler,如下图所示: 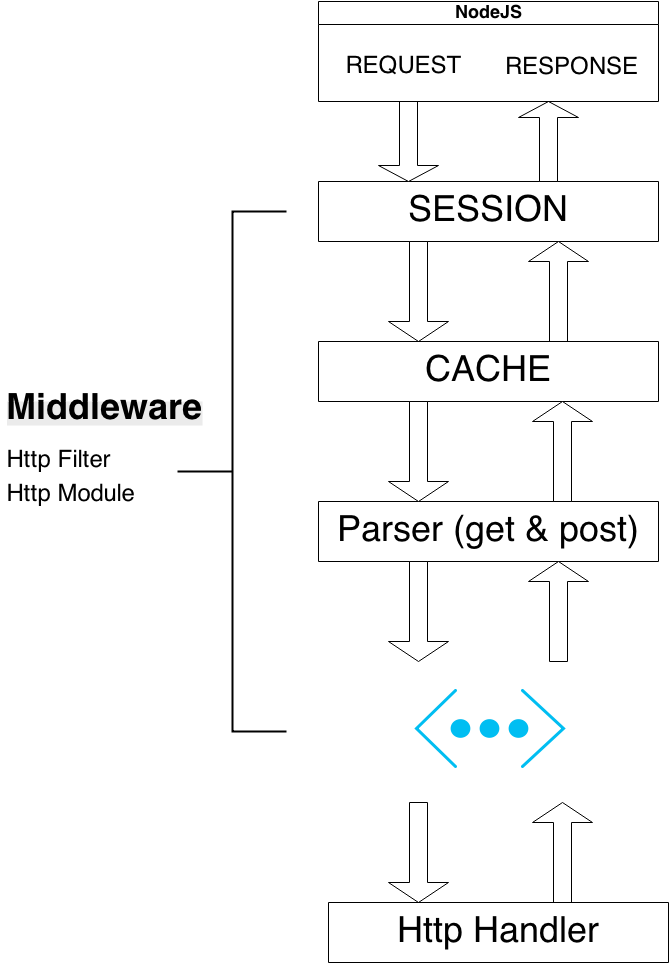
这 些Middleware和Handler在NodeJS中都有一个特点,他们都是回调函数,而回调函数中是唯一会让Node在运行时崩溃的地方。根据这个 特点,我们只需要在框架中集成一处try/catch就可以相对完美地解决异常问题,而且不会影响其它用户的请求request。
事实上现在的NodeJS WEB框架几乎都是这么做的,如 OurJS开源博客所基于的 WebSvr
就有这么一处异常处理代码:
try { handler(req, res); } catch(err) { var errorMsg = '\n' + 'Error ' + new Date().toISOString() + ' ' + req.url + '\n' + err.stack || err.message || 'unknow error' + '\n' ; console.error(errorMsg); Settings.showError ? res.end('<pre>' + errorMsg + '</pre>') : res.end(); }
那么不在回调中产生的错误怎么办?不必担心,其实这样的node程序根本就起不起来。
此外node自带的 cluster 也有一定的容错能力,它跟nginx的worker很类似,但消耗资源(内存)略大,编程也不是很方便,OurJS并没有采用此种设计。
守护NodeJS进程和记录错误日志
现 在已经基本上解决了Node.JS因异常而崩溃的问题,不过任何平台都不是100%可靠的,还有一些错误是从Node底层抛出的,有些异常 try/catch和uncaughtException都无法捕获。之前在运行ourjs的时侯,会偶尔碰到底层抛出的文件流读取异常,这就是一个底层 libuv的BUG,node.js在0.10.21中进行了修复。
面对这种情况,我们就应该为nodejs应用添加守护进程,让NodeJS遭遇异常崩溃以后能马上复活。
另外,还应该把这些产生的异常记录到日志中,并让异常永远不再发生。
使用node来守护node
node-forever 提供了守护的功能和LOG日志记录功能。
安装非常容易
[sudo] npm install forever
使用也很简单
$ forever start simple-server.js
$ forever list
[0] simple-server.js [ 24597, 24596 ]
还可以看日志
forever -o out.log -e err.log my-script.js
使用shell启动脚本守护node
使用node来守护的话资源开销可能会有点大,而且也会略显复杂,OurJS直接在开机启动脚本来进程线程守护。
如在debian中放置的 ourjs 开机启动文件: /etc/init.d/ourjs
这个文件非常简单,只有启动的选项,守护的核心功能是由一个无限循环 while true; 来实现的,为了防止过于密集的错误阻塞进程,每次错误后间隔1秒重启服务
WEB_DIR='/var/www/ourjs'
WEB_APP='svr/ourjs.js'
#location of node you want to use
NODE_EXE=/root/local/bin/node
while true; do
{
$NODE_EXE $WEB_DIR/$WEB_APP config.magazine.js
echo "Stopped unexpected, restarting \r\n\r\n"
} 2>> $WEB_DIR/error.log
sleep 1
done
错误日志记录也非常简单,直接将此进程控制台当中的错误输出到error.log文件即可: 2>> $WEB_DIR/error.log 这一行, 2 代表 Error。




与 多路复用器(Multiplexers))








接口与服务器关联)





