前提:ubuntu下将python3.5.2设为默认(百度)
一.下载stgcn
(gitbub上fork后导入到gitee快些): st-gcn: Spatial Temporal Graph Convolutional Networks (ST-GCN) for Skeleton-Based Action Recognition in PyTorch博客:https://blog.csdn.net/weixin_42661709/article/details/105056325
二.开始配置
1.安装pytorch0.4.0:
sudo pip3 install torch==0.4.0 -f https://download.pytorch.org/whl/cup/stable -i Simple Index
2.openpose pythonAPI
ubuntu16.04 openpose cpu版 python3_I'm you.的博客-CSDN博客
3.下载依赖包:
sudo apt-get install ffmpeg
pip3 install -r requirements.txt
4.安装
cd st-gcn
cd torchlight;
sudo python3 setup.py install;
cd ..5.下载模型
法一(相当慢):bash tools/get_models.sh 法二:从别人的网盘下载(写文章-CSDN博客)
pose_iter_440000.caffemodel放到st-gcn/models/pose/coco中
st_gcn.kinetics.pt等文件 放到 st-gcn/models中

6.运行Demo(配置差可以试个短视频就几帧那种。想跑图片就把.jpg改成.mp4)
python main.py demo [--video ${PATH_TO_VIDEO}] [--openpose ${PATH_TO_OPENPOSE}]新版STGCN:python3 main.py demo --openpose '/home/chq/openpose/build' --video '/home/chq/st-gcn/resource/media/skateboarding.mp4'
旧版:python3 main.py demo_old --video /home/chq/st-gcn/resource/media/test.mp4 --openpose /home/chq/openpose/build
旧版默认保存在 ./data/demo_result/下,也可以自己设置保存位置如:--output_dir /home/chq/st-gcn/resource/media_out
第一个图是10秒的视频我跑了两天.....第二个图是改图片后缀了测试的图片

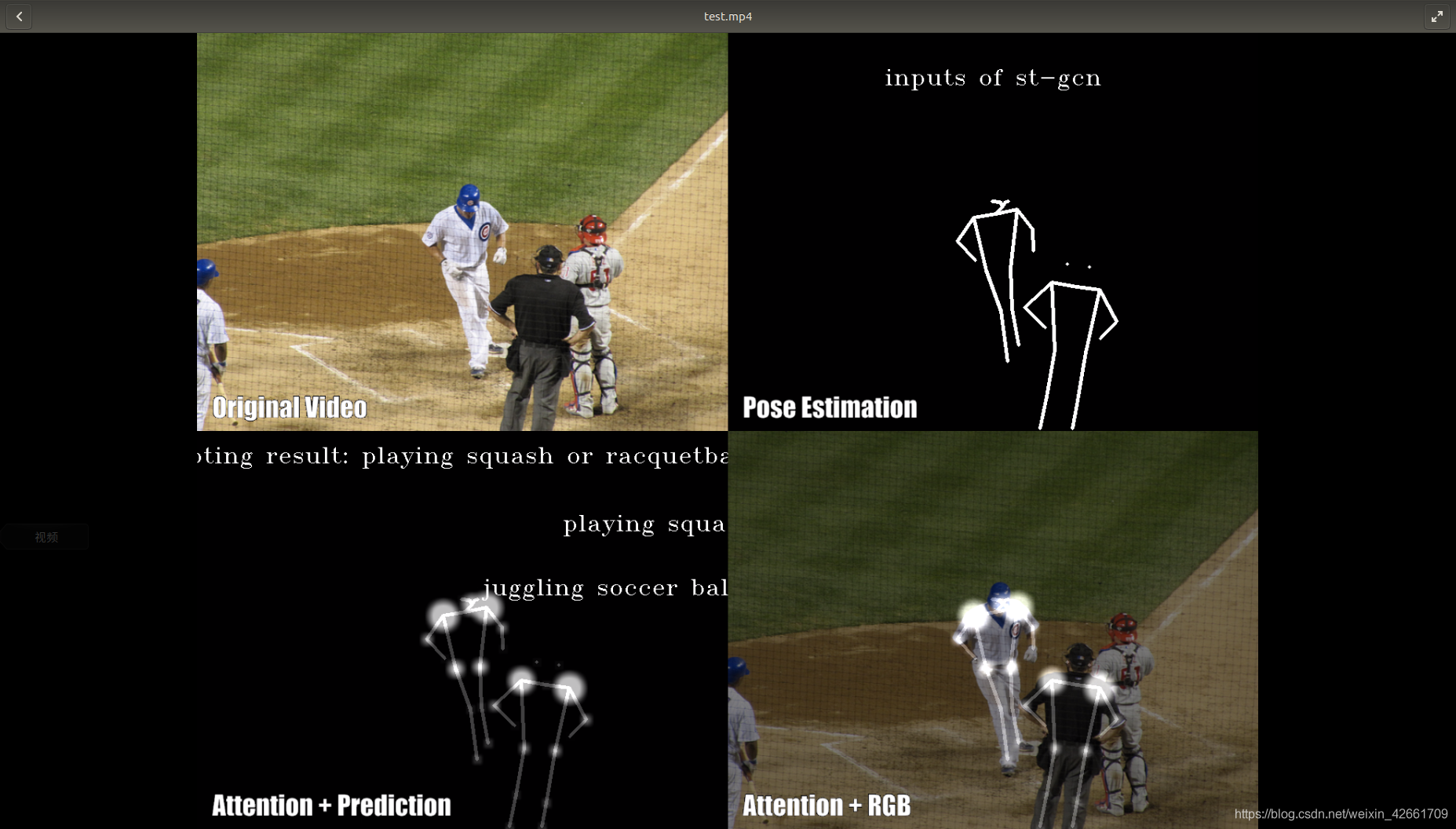
6.解决错误:
1.cpu版的cuda问题

device = torch.device("cuda" if args.cuda else "cpu")。将io.py中103行True修改为False

2.RuntimeError: Error(s) in loading state_dict for Model

问题解决:
原因是作者提供(bash tools/get_models.sh)的模型参数—— st_gcn.kinetics.pt 有问题。所以要下载从另外的途径下载可用的文件https://pan.baidu.com/s/1JrfpRqt0uF8AydiJuxANZw#list/path=%2F&parentPath=%2Fsharelink53688367-280314025530152
(password: j4rt )。放到models下后重新测试运行。
任何程序错误,以及技术疑问或需要解答的,请扫码添加作者VX : 18565453898










)










