时间: 2015 年
级别:APSIPA
机构: 上海电力大学
摘要
新提出的视频编码标准HEVC (High Efficiency video coding)以其比H.264/AVC更好的编码效率,被工业界和学术界广泛接受和采用。在HEVC实现了约40%的编码效率提升的同时,其计算复杂度也显著增加。因此,迫切需要一种高性能的AVC到HEVC转码器。本文提出了一种基于学习的快速转码算法,可以加快CU的判定过程。该方法首先对视频流进行JM解码,然后提取重要特征。这些特征被用作机器学习模型的输入,从而得到特定的CU深度。在x265中,我们跳过未选择的深度,并使用早期剪枝提前终止拆分。实验结果表明,与x265相比,所提转码算法在码率平均下降0.078dB的情况下,最多可节省41%的编码速度。该算法在性能和转码速度之间取得了较好的折中。
介绍
H.264 / AVC是2004年推出的视频压缩行业标准。在过去的十年中,它已经逐渐被接受并应用于在线内容压缩领域。由于带宽、频谱和存储空间的不足,迫切需要新一代视频压缩标准的提出。高效视频编码(HEVC)是由ISO和ITU-T共同制定的新一代视频压缩标准,是H.264的后续标准。这让人们对即将需要将日益增长的超高清内容用于多平台交付产生了巨大的乐观情绪。该算法采用灵活的分块策略,引入了编码树单元(CTU),但没有引入H.264中常用的宏块(MB)。实验结果表明,与H.264相比,HEVC在保证相近视频质量的前提下,可以节省约40%的码率。HEVC帧内编码采用35个方向模式进行预测。采用并行处理架构,加快编码速度,提高性能。
H.264到H.265的转码可能面临平衡码率性能和转码速度的挑战。这两个因素之间的权衡是代码转换框架的关键。H.264采用宏块(MB)作为基本单位。运动估计采用宏块(MB)和子块(subMB)的灵活划分。而在HEVC中,64x64 CTUs是进行进一步拆分的基本单位。HEVC编码器对CU四叉树进行递归遍历。当编码器检查当前深度上的所有候选模式时,当前深度将被分割为子 CU直到最小CU大小。编码器比较所有RD代价,选择RD代价最小的CU深度作为最终深度。转码框架首先对H.264码流进行解码,提取大量信息并使用合适的特征对H.265码流进行重编码。
为了解决码率转换性能和转码速度之间的矛盾,已有许多研究工作。CU的快速判定是一个有意义的研究课题。沈立权等人提出了一种HEVC帧内CU大小和模式选择的快速算法,跳过了一些在空间邻近的CU中很少使用的特定深度级别。Dong Zhang等人提出了一种基于功率谱的率失真优化(PS-RDO)模型,利用残差、模式和运动矢量来估计最佳CU。通过减少CU和PU分区候选个数,可以降低转码复杂度。Fangshun Mu采用一种H.264/AVC编码器级联的HEVC概念编码器架构,加速HEVC编码器的CTU拆分过程。收集H.264/AVC宏块(MBs)的细节信息,减少CU和PU候选模式,以加速CTU拆分过程。郑飞阳等人提出了一种基于H.264解码器残差信息和运动信息的快速转码算法,提出了一种相对有效的CU模式和预测单元(PU)模式选择策略。
为了使预测更加精确,使用机器学习来选择准确的CU深度。一些早期的工作是用这种方法完成的。Xiaolin Shen将CU分裂问题转化为基于支持向量机(SVM)的二分类问题,Luong Pham Van等人提出了一种利用机器学习技术对P图划分分裂标志进行早期预测的快速算法。在每个深度上,该方法帮助确定是否进行分割。
提出了一种基于学习的编码器框架。首先,对输入流进行JM解码,提取有价值的特征;然后使用基于学习的模型,使用这些特征计算每个8x8 CU的特定深度。最后采用早跳、早剪枝的方法跳过无意义深度。
本文的其余部分组织如下。在第二节中,我们简要介绍了CU的划分和我们的编码器框架。在第三节中,我们将介绍详细的结构,包括特征选择、MBs到CUs的映射以及CU深度的跳跃和修剪。第四节给出了实验结果,第五节对本文进行了总结。
问题分析
高清和超高清视频的出现推动了H.265/HEVC的发展,因为更高分辨率的帧需要在相对较大的编码单元中编码。HEVC采用CU代替AVC中的MB。在H.265中,CUs的范围从64x64到8x8,它们基本上替代了之前标准中的MBs和块。HEVC将帧划分为 CTU,并引入了编码单元(coding unit, CU)、预测单元(prediction unit, PU)和变换单元(transform unit, TU) 3个概念,以方便对块层次结构的语法表示。
编码结构可以分析为递归计算不同大小的CU和PU。图1显示了一个典型的CTU拆分方式。CU以递归的方式划分,从64x64到8x8。对于每种尺寸的CU,计算RD代价,直到遍历所有尺寸的CU。然后采用具有最小RD代价的CU尺寸,并放弃其他拆分方式。因此,编码器必须尝试所有可能的CUs和PUs组合,这大大增加了编码器的计算负担。
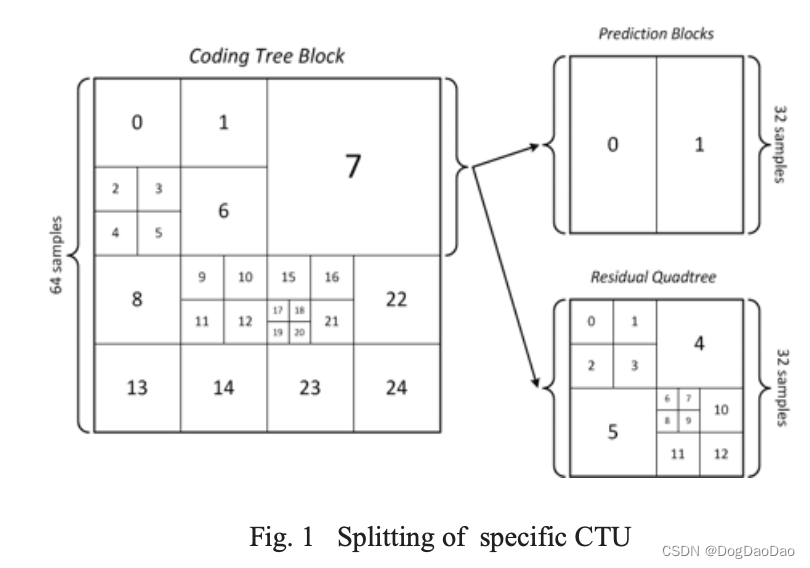
由于H.264的编码结构与HEVC类似,因此可以重用H.264码流中的细节信息来帮助判断特定的CU和PU模式。图2说明了H.264和HEVC之间的相似性。
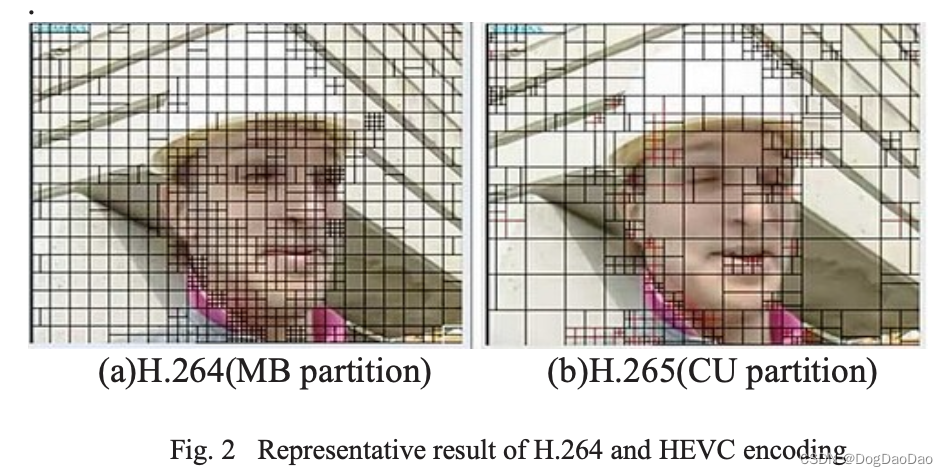
两种编码器都会在纹理特征重要的部分进行分割,在信息较少的部分保持原始大小。通过这种方式,我们可以使用从H.264流中提取的信息来确定CU是否需要拆分。在这个过程中,我们可以通过机器学习显著提高我们的预测。
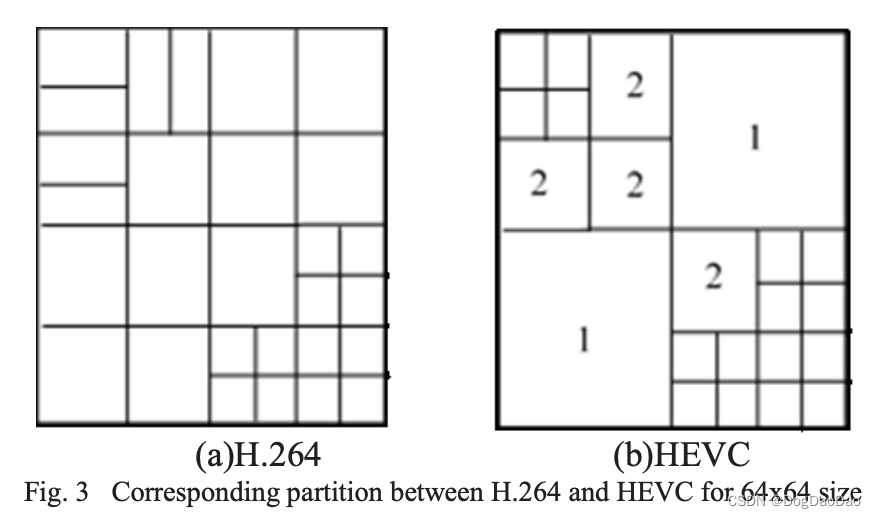
在帧间预测中,同质区域更可能由较大的块表示。通过对H.264/AVC码流最终分割结果的观察,粗分割通常应用在运动平滑的区域,导致剩余能量较小。如图3所示,HEVC为0到3的四种深度范围内的树单元编码开辟了一种新方法。深度值取决于编码单元的大小,而64x64表示深度0。与H.264中固定大小的MBs进行了比较。该方法对兴趣内容具有较好的适应性。当深度为2时,CU的大小为MB,即16x16。这样就可以通过H.264和HEVC建立CU深度模式映射。直观地说,如果在H.264中对16x16的MBs进行了划分,那么相邻的MBs也进行了划分,那么相应的CU至少要划分到深度2。反过来,CU甚至可能不会被划分为深度1。
提出的算法
正如在第二节中简要介绍的,x264和x265之间的模式映射非常有意义。H.264中16x16大小的MBs可以映射为同帧中x265编码器中对应位置的16x16单元。在H.265/HEVC中,两种编码规则之间必须存在一定的相关性才能支持深度选择。因此,由于有价值的映射,转码框架可以以相对较快的速度工作良好。
系统结构:
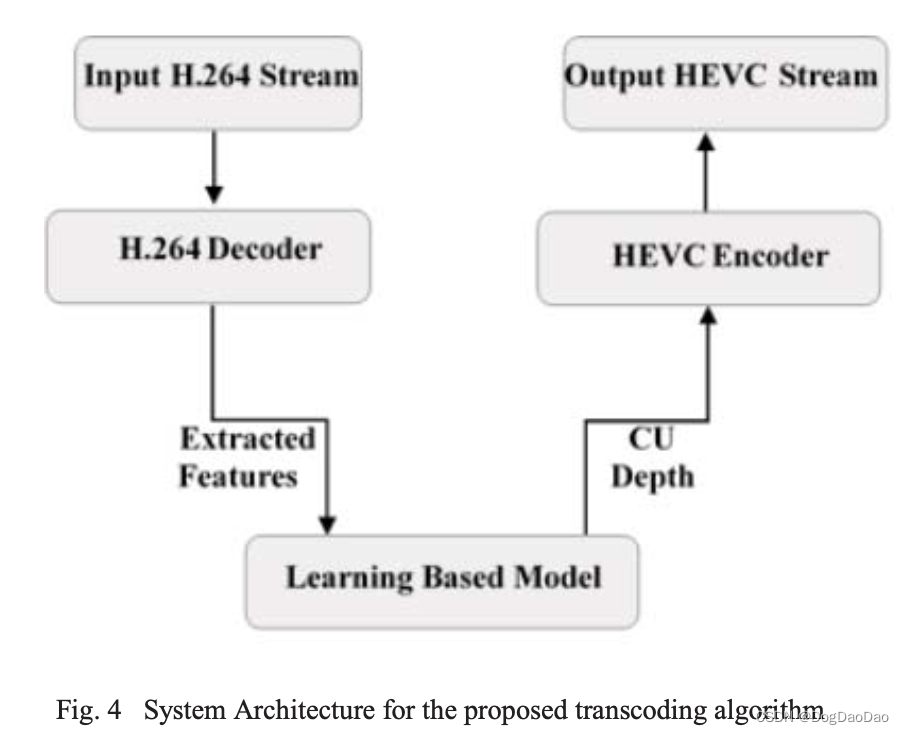
采用IPPP帧结构,提出了一种基于JM解码器和x265编码器的H.264/AVC到H.265/HEVC转码框架。如图4所示,我们在接收流时首先对流进行解码。在解码过程中,所有需要的信息都从流中提取并存储在x265编码器中。然后对提取的特征进行常规计算,并将其作为我们提出的基于学习的模型的输入。基于学习的模型就像一个黑盒,输出精确的指定深度。然后x265精确计算指定深度的RD代价,而不是递归计算所有深度的RD代价。传统上,为特定的CTU计算最佳CU深度是复杂而繁琐的。我们需要遍历从8x8到64x64的所有大小的CTU,计算RD成本并相互比较,以找到最优的选择。
使用SVM作为CU深度映射的深度预测:
该算法基于模式映射,特别是H.264和HEVC之间的CU深度选择。
如图4所示,所提算法的总体框架分为两部分:(i) H.264到HEVC的转码。(ii)训练最佳CU深度映射模型。首先使用JM解码器对输入流进行解码,并在前期工作的基础上提取特征。Eduardo Peixoto提出,MV相位方差和DCT系数也可以帮助预测深度。我们尝试将这些特征加入到SVM模型中,以提高准确率。结果显示BDRATE增加了。由于特征与视频之间的相关性可能紧密或微弱,视频与MV相位方差之间相对较弱的相关性可能会对CU深度决策产生负面影响。对于快速CU深度决策来说,选择正确合适的特征并获得良好的结果比使用所有特征更合理。因此,该算法使用分区和MB信息。
这些特征可以分为三类:(i) CTU的QP值,CTU的QP值在22 ~ 37之间,我们将其分为四类(22,27,32,37)。由于QP值对结果有很大影响。(ii)表示数据流中Skip或16x16 Mb大小的Mb类型(iii)表示具体Mb的详细信息的分区类型(16x8,8x16,8x8 Mb大小)。由于H.264需要16mb的数据流,考虑到特定区域中相邻Mb的空间相关性,并构成16x16 Mb到64x64 CTU之间的CU深度映射,因此需要考虑MBs的相邻特征。如图5所示,由于HEVC的CTU采用了表示深度1和0的两种尺寸,因此我们使用32x32和64x64尺寸作为范围来计算不同相邻MBs之间的空间相关性。在32x32和64x64的情况下,以16x16为基本单元计算两个特征的和和方差。因为和代表深度0到1的划分,而方差更多地反映了深度2到3。当我们获得特征时,首先预测QP,并根据QP值进入不同的模型。对于不同的QP值,求和和方差计算函数相同,具体值不同。
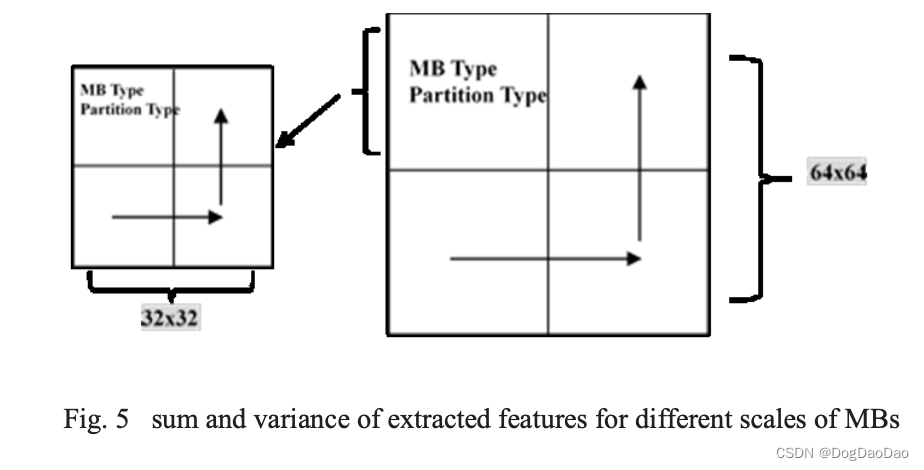
图6给出了SVM训练和预测的具体过程。如上所述,提取三类特征并进行分类。然后根据这些特征的空间相关性对其进行预处理;计算不同尺度MBs的和和方差。在支持向量机(SVM)的基础上训练模型,由支持向量机(SVM)训练特征得到CU深度预测映射模型。该模型根据不同特征的范围输出指定的深度。在训练过程中,采集大量训练视频的特征作为SVM训练模型的输入。如图6所示的第二步,预处理后的特征可能包括不同尺度的特征之和和方差。我们计算4个较小块在一定尺度下的值的总和,以及一个较小块与其他3个较小块的方差,作为我们的预处理。所有特征的组合可能有上万种,每个特定特征的范围可能非常大,每个特征的波动范围也很大。SVM训练模型首先给出所有特征的组合及其对应的深度。
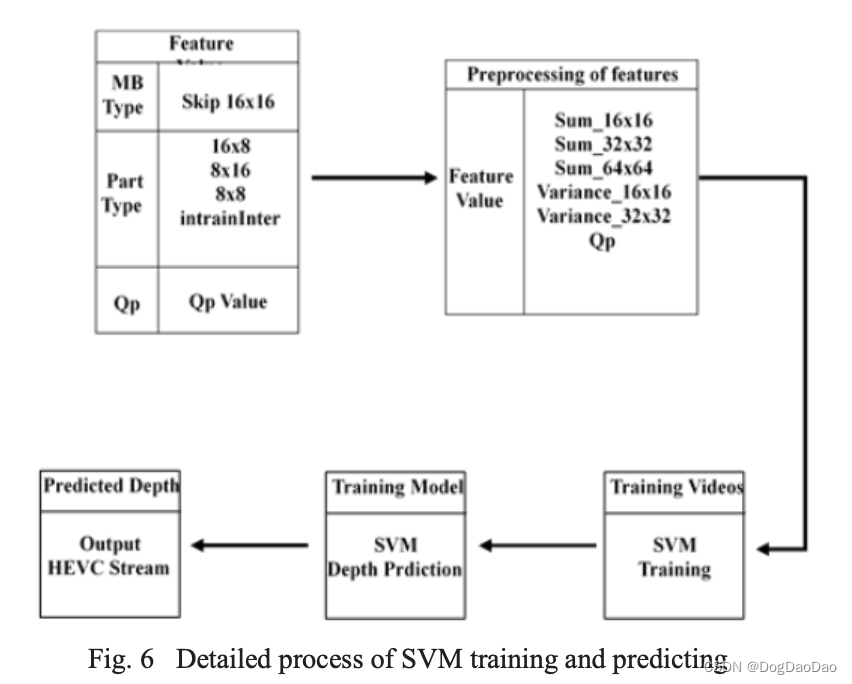
但我们不会计算特征的所有组合,因为在许多情况下,输出深度可能会发生变化,即使其中一个特征只有一点点变化。这可能会导致判断上的一些错误。因此,当其中一两个特征在一定范围内发生变化而深度不变时,将这些特征与其对应的深度进行组合。
提前跳过和提前剪枝:
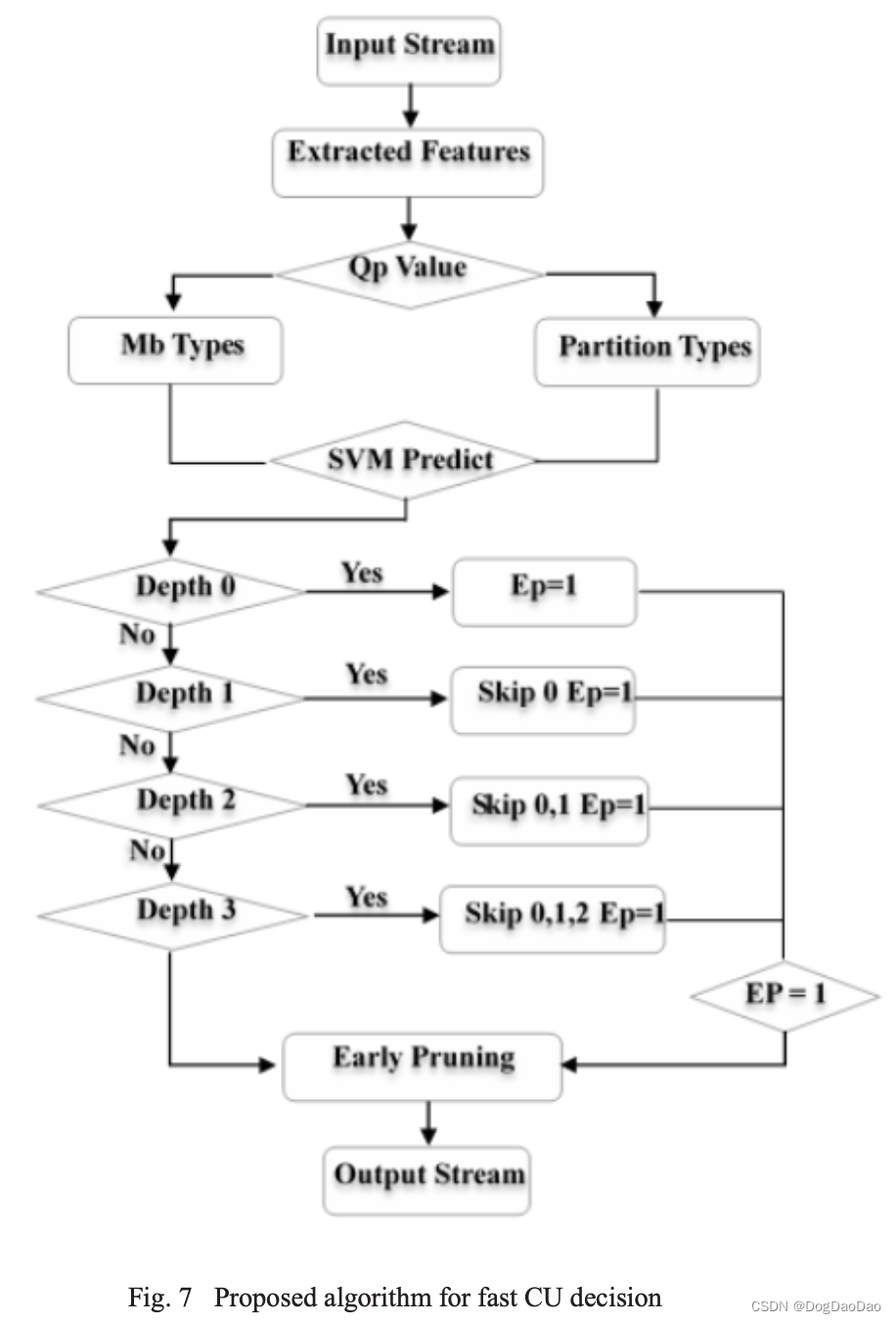
SVM训练模型将根据输入计算特征并获得指定的深度。然后将此深度设置为在x265中执行的深度,以进行提前跳过和提前修剪。
深度范围从0到3,深度0表示64x64的尺寸,而深度3将尺寸缩小为8x8。当预测深度介于1到3之间时,将执行早期跳跃。如果我们跳过不必要的深度,可以节省大量不必要的计算。当深度小于预测深度时,跳过所有PU模式的RD代价计算。
图7描述了所提算法的过程,标志EP表示CU分裂提前结束。它表示早期剪枝,预测深度首先计算所有PU模式,我们假设最小RD成本模式必须存在于此深度。超过这个深度的可以放弃。x265采用递归四叉树编码策略对图像块进行划分。当EP等于1时,递归停止,这意味着进行剪枝。
该算法还采用了决策树的动态剪枝方法来降低预测误差。这意味着可能需要考虑一些特殊情况。图6列出了特征的预处理结果。其中,一些组合可能导致模糊预测。当特征表明预测深度至少为2时,如果16x16 CU的和和方差都超过一定的阈值。深度可以转到2或3。在这种情况下,EP被赋值为0,只会多计算一个深度。这意味着深度2和3将被计算。在保证编码速度的前提下,大大降低了预测误差。
实验结果
由于之前的工作和分析,所提算法没有在H.265/HEVC参考模型(HM)上实现,该科学模型不适合实际应用。我们采用x265作为基准编码器,而不是HM,因为它在工业上的常用。x265是HEVC编码的开源实现,目标是在基于通用多核CPU平台上进行实时编码。因此,在现代多核计算机上,x265的编码速度几乎是原始HM的数百倍。目前x265已经被FFMPEG、VLC等著名工具所使用。
对于转码框架,首先使用JM对流进行解码,提取信息,因为JM可以获得更多的特征,且解码速度较快。
为了测试算法的效果,使用4个QPs(22,27,32,37)对所有测试用例进行编码和比较,x265采用相同的QPs。我们定义了两个参数来比较性能和分析质量退化。他们是PSNR和Bits。定义如公式 1 和 2
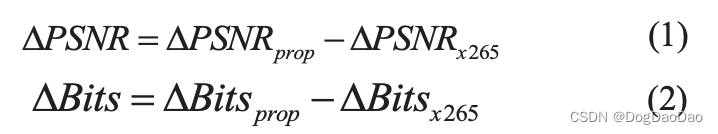
为了使结果更加直观和令人信服,我们计算了BD-PSNR。采用了应用最广泛的Bjontegaard失真度-psnr (BD-PSNR)[8]为了评估编码效率的提高,时间节省如下公式 3 表示
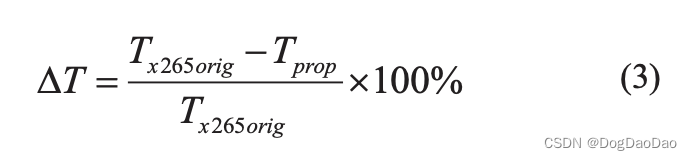
利用B类和E类的所有标准测试序列,每个类中只测试一个视频,训练其他视频,建立SVM训练模型。我们用这种方式交叉验证结果。在测试和验证算法的过程中,通过检测原始深度和预测深度来修正算法以提高精度。我们可以从我们的方法中推断出深度0和1一定达到了真实的深度,因为深度0和1占据了大部分的深度,并且会显著地影响结果。显然,要更准确地预测深度0和1要简单得多。实验结果为我们的代码转换架构提供了一个相对较好的映射表。
表1展示了算法的运行结果。在BD-PSNR仅下降0.078dB的情况下,平均节省了x265 41%的编码速度。在所有测试序列中,720p序列的编码时间节省较少,BD-PSNR值增加较多。
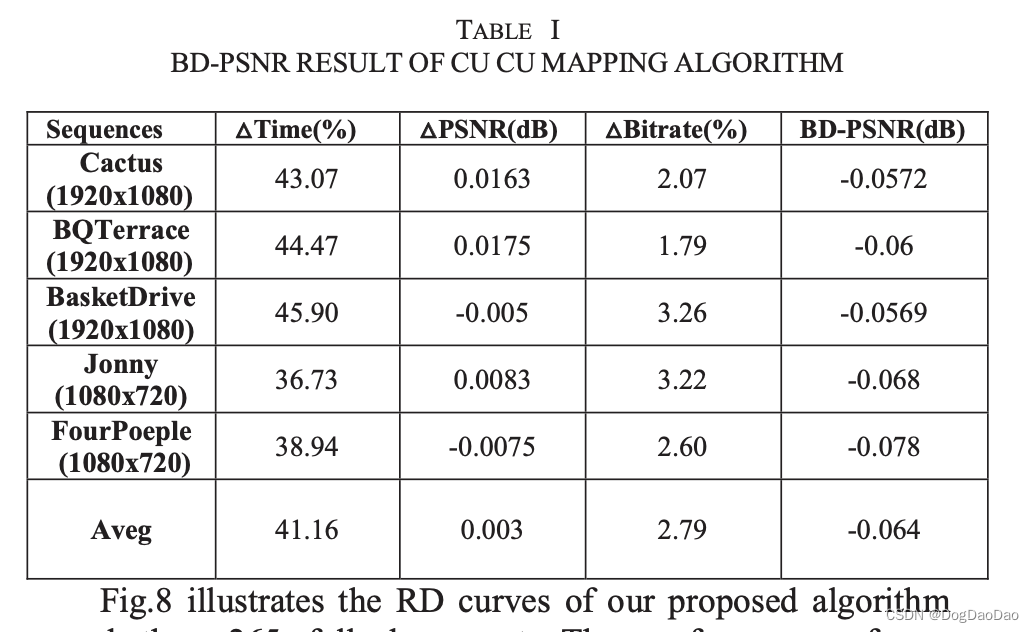
分辨率在一定程度上影响了转码算法的性能,可以作为转码算法的一个特征,因为以往的实验大多是在速度非常慢的HM上进行的。基于x265的实验结果更具有参考价值和实用性。
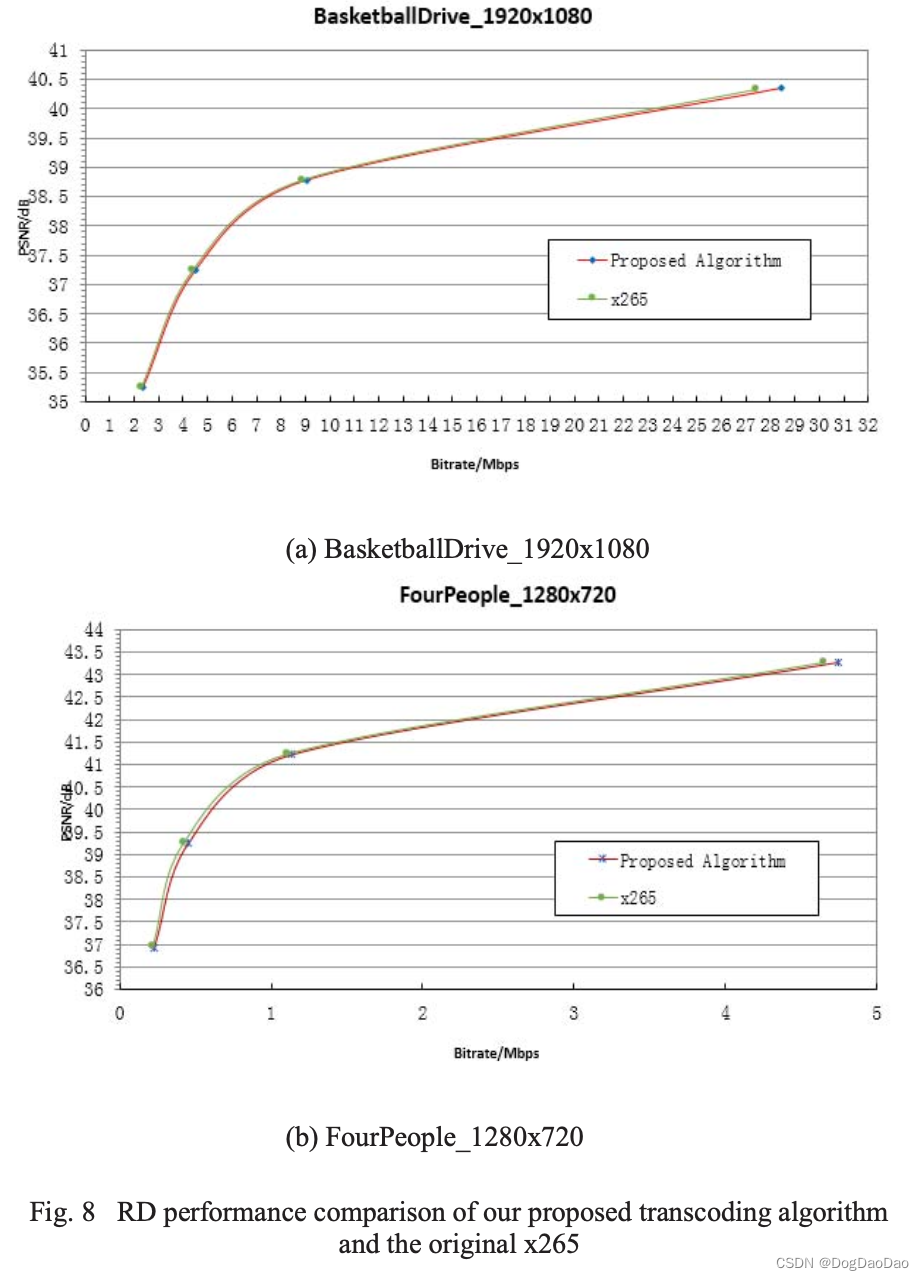
图8展示了本文算法和x265全rdo预置的RD曲线。基于transcoding的CU映射算法的性能与x265相当。码率较低时,码率失真性能略有下降。在节省编码速度和码率性能之间取得了很好的折中,BD-PSNR平均损失不超过0.08dB。
结论
针对H.264到H.265的转码,提出了一种基于学习的快速CU判决算法。该方法为基于机器学习的快速转码提供了一种新的途径。在转码框架中,整个算法包括三个重要方面:(1)首先经过JM解码的比特流;针对x264中每个特定的16x16 MB,提取了几个重要的特征。(2) x265跳过了不必要的CU深度,即深度小于上面提到的确定深度。这些深度的计算是不需要的。直接跳到确定的深度,无需冗余计算。(3)如果确定的深度不是上一个深度,可以放弃后续的深度计算。换句话说,只计算选定的深度。跳过CU和提前剪枝可以在不影响编码性能的前提下降低x265编码的复杂度。实验结果表明,在比特率损失很小的情况下,该算法可以节省40%以上的编码时间。进一步的工作将集中在基于4k甚至8k视频的快速PU决策映射上,以满足时代的需求。



)



函数与示例)










的使用)
