Spark 的核心是建立在统一的抽象弹性分布式数据集(Resiliennt Distributed Datasets,RDD)之上的,这使得 Spark 的各个组件可以无缝地进行集成,能够在同一个应用程序中完成大数据处理。
一、RDD概念
RDD 是 Spark 提供的最重要的抽象概念,它是一种有容错机制的特殊数据集合,可以分布在集群的结点上,以函数式操作集合的方式进行各种并行操作。
通俗点来讲,可以将 RDD 理解为一个分布式对象集合,本质上是一个只读的分区记录集合。每个 RDD 可以分成多个分区,每个分区就是一个数据集片段。一个 RDD 的不同分区可以保存到集群中的不同结点上,从而可以在集群中的不同结点上进行并行计算。
设计背景,迭代式算法,若采用MapReduce则会重用中间结果;MapReduce不断在磁盘中读写数据,会带来很大开销。
二、RDD的典型执行过程

1)读入外部数据源进行创建,分区
2)RDD经过一系列的转化操作,每一次都会产生不同的RDD供给下一个转化擦操作使用
3)最后一个RDD经过一个动作操作进行计算并输出到外部数据源
优点:惰性调用、调用、管道化、避免同步等待,不需要保存中间结果
三、高效的原因
1)容错性:现有方式是用日志记录的方式。而RDD具有天生的容错,任何一个RDD出错,都可以去找父亲节点,代价低。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
2)中间结果保存到内存,避免了不必要的内存开销
3)存放的数据可以是java对象,避免了对象的序列化和反序列化。
四、RDD的依赖关系:窄依赖和宽依赖
窄依赖:(narrow dependency)是指每个父RDD的一个Partition最多被子RDD的一个Partition所使用,例如map、filter、union等操作都会产生窄依赖;(独生子女)即rdd中的每个partition仅仅对应父rdd中的一个partition。父rdd里面的partition只去向子rdd****里的某一个partition!这叫窄依赖,如果父rdd里面的某个partition会去子rdd里面的多个partition,那它就一定是宽依赖!**
宽依赖(shuffle dependency):是指一个父RDD的Partition会被多个子RDD的Partition所使用,例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖;(超生)每一个父rdd的partition数据都有可能传输一部分数据到子rdd的每一个partition中,即子rdd的多个partition依赖于父rdd。宽依赖划分成一个stage!!!
作用:完成Stage的划分
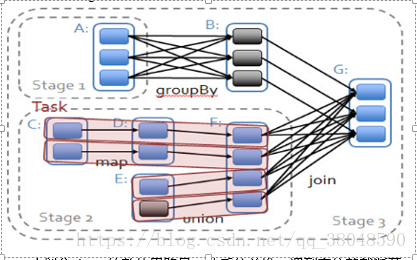
Stage的划分:
spark划分stage的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个RDD加入该stage中。因此在上图中RDD C,RDD D,RDD E,RDDF被构建在一个stage中,RDD A被构建在一个单独的Stage中,而RDD B和RDD G又被构建在同一个stage中。
ShuffleMapStage和ResultStage:
简单来说,DAG的最后一个阶段会为每个结果的partition生成一个ResultTask,即每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的!而其余所有阶段都会生成ShuffleMapTask;之所以称之为ShuffleMapTask是因为它需要将自己的计算结果通过shuffle到下一个stage中;也就是说上图中的stage1和stage2相当于mapreduce中的Mapper,而ResultTask所代表的stage3就相当于mapreduce中的reducer。
*、本文参考
Spark RDD是什么?
spark原理:概念与架构、工作机制



















