作者 | 吴惠君,吕能,符茂松
责编 | 郭芮
【导语】 本文对比了Heron和常见的流处理项目,包括Storm、Flink、Spark Streaming和Kafka Streams,归纳了系统选型的要点。此外实践了Heron的一个案例,以及讨论了Heron在这一年开发的新特性。
在今年6月期的“基础篇”中,我们通过学习Heron[1][2][3]的基本概念、整体架构和核心组件等内容,对Heron的设计、运行等方面有了基本的了解。在这一期的“应用篇”中,我们将Heron与其他流行的实时流处理系统(Apache Storm[4][5]、Apache Flink[6]、Apache Spark Streaming[7]和Apache Kafka Streams[8])进行比较。在此基础上,我们再介绍如何在实际应用中进行系统选型。然后我们将分享一个简单的案例应用。最后我们会介绍在即将完结的2017年里Heron有哪些新的进展。
实时流处理系统比较与选型
当前流行的实时流处理系统主要包括Apache基金会旗下的Apache Storm、Apache Flink、Apache Spark Streaming和Apache Kafka Streams等项目。虽然它们和Heron同属于实时流处理范畴,但是它们也有各自的特点。
Heron对比Storm(包括Trident)
在Twitter内部,Heron替换了Storm,是流处理的标准。
数据模型的区别
Heron兼容Storm的数据模型,或者说Heron兼容Storm的API,但是背后的实现完全不同。所以它们的应用场景是一样的,能用Storm的地方也能用Heron。但是Heron比Storm提供更好的效率,更多的功能,更稳定,更易于维护。
Storm Trident是Storm基础上的项目,提供高级别的API,如同Heron的函数式API。Trident以checkpoint加rollback的方式实现了exactly once;Heron以Chandy和Lamport发明的分布式快照算法实现了effectively once。
应用程序架构的区别
Storm的worker在每个JVM进程中运行多个线程,每个线程中执行多个任务。这些任务的log混在一起,很难调试不同任务的性能。Storm的nimbus无法对worker进行资源隔离,所以多个topology的资源之间互相影响。另外ZooKeeper被用来管理heartbeat,这使得ZooKeeper很容易变成瓶颈。
Heron的每个任务都是单独的JVM进程,方便调试和资源隔离管理,同时节省了整个topology的资源。ZooKeeper在Heron中只存放很少量的数据,heartbeat由tmaster进程管理,对ZooKeeper没有压力。
Heron对比Flink
Flink框架包含批处理和流处理两方面的功能。Flink的核心采用流处理的模式,它的批处理模式通过模拟块数据的的流处理形式得到。
数据模型的区别
Flink在API方面采用declarative的API模式。Heron既提供declarative模式API或者叫做functional API也提供底层compositional模式的API,此外Heron还提供Python[9]和C++[10]的API。
应用程序架构的区别
在运行方面,Flink可以有多种配置,一般情况采用的是多任务多线程在同一个JVM中的混杂模式,不利于调试。Heron采用的是单任务单JVM的模式,利于调试与资源分配。
在资源池方面,Flink和Heron都可以与多种资源池合作,包括Mesos/Aurora、YARN、Kubernetes等。
Heron对比Spark Streaming
Spark Streaming处理tuple的粒度是micro-batch,通常使用半秒到几秒的时间窗口,将这个窗口内的tuple作为一个micro-batch提交给Spark处理。而Heron使用的处理粒度是tuple。由于时间窗口的限制,Spark Streaming的平均响应周期可以认为是半个时间窗口的长度,而Heron就没有这个限制。所以Heron是低延迟,而Spark Streaming是高延迟。
Spark Streaming近期公布了一项提案,计划在下一个版本2.3中加入一个新的模式,新的模式不使用micro-batch来进行计算。
数据模型的区别
语义层面上,Spark Streaming和Heron都实现了exactly once/effectively once。状态层面上,Spark Streaming和Heron都实现了stateful processing。API接口方面,Spark Streaming支持SQL,Heron暂不支持。Spark Streaming和Heron都支持Java、Python接口。需要指出的是,Heron的API是pluggable模式的,除了Java和Python以外,Heron可以支持许多编程语言,比如C++。
应用程序架构的区别
任务分配方面,Spark Streaming对每个任务使用单个线程。一个JVM进程中可能有多个任务的线程在同时运行。Heron对每个任务都是一个单独的heron-instance进程,这样的设计是为了方便调试,因为当一个task失败的时候,只用把这个任务进程拿出来检查就好了,避免了进程中各个任务线程相互影响。
资源池方面,Spark Streaming和Heron都可以运行在YARN和Mesos上。需要指出的是Heron的资源池设计是pluggable interface的模式,可以连接许多资源管理器,比如Aurora等。读者可以查看[11]了解Heron支持的资源池。
Heron对比Kafka Streams
Kafka Streams是一个客户端的程序库。通过这个调用库,应用程序可以读取Kafka中的消息流进行处理。
数据模型的区别
Kafka Streams与Kafka绑定,需要订阅topic来获取消息流,这与Heron的DAG模型完全不同。对于DAG模式的流计算,DAG的结点都是由流计算框架控制,用户计算逻辑需要按照DAG的模式提交给这些框架。Kafka Streams没有这些预设,用户的计算逻辑完全用户控制,不必按照DAG的模式。此外,Kafka Streams也支持反压(back pressure)和stateful processing。
Kafka Streams定义了2种抽象:KStream和KTable。在KStream中,每一对key-value是独立的。在KTable中,key-value以序列的形式解析。
应用程序架构的区别
Kafka Streams是完全基于Kafka来建设的,与Heron等流处理系统差别很大。Kafka Streams的计算逻辑完全由用户程序控制,也就是说流计算的逻辑并不在Kafka集群中运行。Kafka Streams可以理解为一个连接器,从Kafka集群中读取和写入键值序列,计算所需资源和任务生命周期等等都要用户程序管理。而Heron可以理解为一个平台,用户提交topology以后,剩下的由Heron完成。
选型
归纳以上对各个系统的比较,我们可以得到如上的表基于以上表格的比较,我们可以得到如下的选型要点:
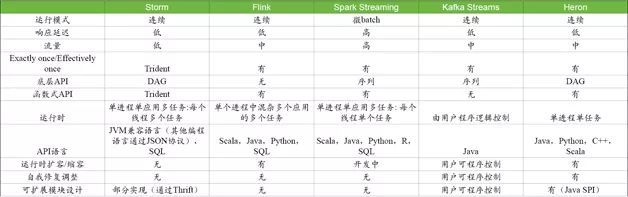
Storm适用于需要快速响应、中等流量的场景。Storm和Heron在API上兼容,在功能上基本可以互换;Twitter从Storm迁移到了Heron,说明如果Storm和Heron二选一的话,一般都是选Heron。
Kafka Streams与Kafka绑定,如果现有系统是基于Kafka构建的,可以考虑使用Kafka Streams,减少各种开销。
一般认为Spark Streaming的流量是这些项目中最高的,但是它的响应延迟也是最高的。对于响应速度要求不高、但是对流通量要求高的系统,可以采用Spark Streaming;如果把这种情况推广到极致就可以直接使用Spark系统。
Flink使用了流处理的内核,同时提供了流处理和批处理的接口。如果项目中需要同时兼顾流处理和批处理的情况,Flink比较适合。同时因为需要兼顾两边的取舍,在单个方面就不容易进行针对性的优化和处理。
总结上面,Spark Streaming、Kafka Streams、Flink都有特定的应用场景,其他一般流处理情况下可以使用Heron。
Heron案例学习
让我们在Ubuntu单机上来实践运行一个示例topology,这包括如下几个步骤:
安装Heron客户端,
启动一个Heron示例topology,
其他topology操作命令。安装Heron工具包,
运行Heron Tracker,
运行Heron UI。
运行topology
首先找到Heron的发布网页:https://github.com/twitter/heron/releases,找到最新的版本0.16.5。可以看到Heron提供了多个版本的安装文件,这些安装文件又分为几个类别:客户端client、工具包tools和开发包API等。
安装客户端
下载客户端安装文件heron-client-install-0.16.5-ubuntu.sh:
wget https://github.com/twitter/heron/releases/download/0.16.5/heron-client-install-0.16.5-darwin.sh
然后执行这个文件:
chmod +x heron-*.sh
./heron-client-install-0.16.5--PLATFORM.sh --user
其中--user参数让heron客户端安装到当前用户目录~/.hedon,同时在~/bin下创建一个链接指向~/.heorn/bin下的可执行文件。
Heron客户端是一个名字叫heron的命令行程序。可以通过export PATH=~/bin:$PATH让heron命令能被直接访问。运行如下命令来检测heron命令是否安装成功:
heron version
运行示例topology
首先添加localhost到/etc/hosts,Heron在单机模式时会用/etc/hosts来解析本地域名。
Heron客户端安装时已经包含了一个示例topology的jar包,在~/.heron/example目录下。我们可以运行其中一个示例topology作为例子:
heron submit local ~/.heron/examples/heron-examples.jar \com.twitter.heron.examples.ExclamationTopology ExclamationTopology \--deploy-deactivated
heron submit命令提交一个topology给heron运行。关于heron submit的命令的格式,可以用过heron help submit来查看。
当Heron运行在单机本地模式时,它会将运行状态和日志等信息存放在~/.herondata目录下。我们可以可以查看刚才运行的示例topology目录,具体位置是:
ls -al ~/.herondata/topologies/local/${USER_NAME}/ExclamationTopology
Topology生命周期
一个topology的生命周期包括如下几个阶段:
submit:提交topology给heron-scheduler。这时topology还没有处理tuples,但是它已经准备好,等待被activate;
activate/deactivate:让topology开始/停止处理tuples;
restart:重启一个topology,让资源管理器重新分配容器;
kill:撤销topology, 释放资源。
这些阶段都是通过heron命令行客户端来管理的。具体的命令格式可以通过heron help查看。
Heron工具包
Heron项目提供了一些工具,可以方便查看数据中心中运行的topology状态。在单机本地模式下,我们也可以来试试这些工具。这些工具主要包括:
Tracker:一个服务器提供restful API,监视每个topology的运行时状态;
UI:一个网站,调用Tracker restful API展示成网页。
一个数据中心内可以部署一套工具包来涵盖整个数据中心的所有topology。
安装工具包
用安装Heron客户端类似的方法,找到安装文件,然后安装它:
wget https://github.com/twitter/heron/releases/download/0.16.5/heron-tools-install-0.16.5-darwin.sh
chmod +x heron-*.sh
./heron-tools-install-0.16.5-PLATFORM.sh --user
Tracker工具
启动Tracker服务器:heron-tracker
验证服务器restful api:在浏览器中打开http://localhost:8888

UI 工具
启动UI网站:heron-ui
验证UI网站:在浏览器中打开http://localhost:8889

Heron新特性
自从2016年夏Twitter开源Heron以来,Heron社区开发了许多新的功能,特别是2017年Heron增加了“在线动态扩容/缩容”、“effectively once传输语义”、“函数式API”、“多种编程语言支持”、“自我调节(self-regulating)”等。
在线动态扩容/缩容
根据Storm的数据模型,topology的并行度是topology的作者在编程topology的时候指定的。很多情况下,topology需要应付的数据流量在不停的变化。topology的编程者很难预估适合的资源配置,所以动态的调整topology的资源配置就是运行时的必要功能需求。
直观地,改变topology中结点的并行度就能快速改变topology的资源使用量来应付数据流量的变换。Heron通过update命令来实现这种动态调整。Heron命令行工具使用packing算法按照用户指定的新的并行度计算topology的新的packing plan,然后通过资源池调度器增加或者减少容器数量,并再将这个packing plan发送给tmaster合并成新的physical plan,使得整个topology所有容器状态一致。Heron实现的并行度动态调整对运行时的topology影响小,调整快速。
Effectively once传输语义
Heron在原有tuple传输模式at most once和at least once以外,新加入了effectively once。原有的at most once和at least once都有些不足之处,比如at most once会漏掉某些tuple;而at least once会重复某些tuple。所以effectively once的目标是,当计算是确定性(deterministic)的时候,结果精确可信。
Effectively once的实现可以概括为两点:
分布式状态checkpoint;
topology状态回滚。
tmaster定期向spout发送marker tuple。当topology中的一个结点收集齐上游的marker tuple时,会将当时自己的状态写入一个state storage,这个过程就是checkpoint。当整个topology的所有结点都完成checkpoint的时候,state storage就存储了一份整个topology快照。如果topology遇到异常,可以从state storage读取快照进行恢复并重新开始处理数据。
函数式API (Functional API)
函数式编程是近年来的热点,Heron适应时代潮流在原有API的基础上添加了函数式API。Heron的函数式API让topology编程者更专注于topology的应用逻辑,而不必关心topology/spout/bolt的具体细节。Heron的函数式API相比于原有的底层API是一种更高层级上的API,它背后的实现仍然是转化为底层API来构建topology。
Heron函数式API建立在streamlet的概念上。一个streamlet是一个无限的、顺序的tuple序列。Heron函数式API的数据模型中,数据处理就是指从一个streamlet转变为另一个streamlet。转变的操作包括:map、flatmap、join、filter和window等常见的函数式操作。
多种编程语言支持
以往topology编写者通常使用兼容Storm的Java API来编写topology,现在Heron提供Python和C++的API,让熟悉Python和C++的程序员也可以编写topology。Python和C++的API设计与Java API类似,它们包含底层API用来构造DAG,将来也会提供函数式API让topology开发者更专注业务逻辑。
在实现上,Python和C++的API都有Python和C++的heron-instance实现。它们不与heron-instance的Java实现重叠,所以减少了语言间转化的开销,提高了效率。
自我调节(self-regulating)
Heron结合Dhalion框架开发了新的health manager模块。Dhalion框架是一个读取metric然后对topology进行相应调整或者修复的框架。Health manager由2个部分组成:detector/diagnoser和resolver。Detector/diagnoser读取metric探测topology状态并发现异常,resolver根据发现的异常执行相应的措施让topology恢复正常。Health manager模块的引入,让Heron形成了完整的反馈闭环。
现在常用的两个场景是:1. detector监测back pressure和stmgr中队列的长度,发现是否有些容器是非常慢的;然后resolver告知heron-scheduler来重新调度这个结点到其他host上去;2. detector监测所有结点的状态来计算topology在全局层面上是不是资源紧张,如果发现topology资源使用量很大,resolver计算需要添加的资源并告知scheduler来进行调度。
结束语
在本文中,我们对比了Heron和常见的流处理项目,包括Storm、Flink、Spark Streaming和Kafka Streams,归纳了系统选型的要点,此外我们实践了Heron的一个案例,最后我们讨论了Heron在这一年开发的新特性。
最后,作者希望这篇文章能为大家提供一些Heron应用的相关经验,也欢迎大家向我们提供建议和帮助。如果大家对Heron的开发和改进感兴趣,可以查看Heron官网(http://heronstreaming.io)和代码(https://github.com/twitter/heron)。
参考文献
[1] Maosong Fu, Ashvin Agrawal, Avrilia Floratou, Bill Graham, Andrew Jorgensen, Mark Li, Neng Lu, Karthik Ramasamy, Sriram Rao, and Cong Wang. “Twitter Heron: Towards Extensible Streaming Engines.” In 2017 IEEE 33rd International Conference on Data Engineering (ICDE), pp. 1165-1172. IEEE, 2017.
[2] Sanjeev Kulkarni, Nikunj Bhagat, Maosong Fu, Vikas Kedigehalli, Christopher Kellogg, Sailesh Mittal, Jignesh M. Patel, Karthik Ramasamy, and Siddarth Taneja. “Twitter heron: Stream processing at scale.” In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, pp. 239-250. ACM, 2015.
[3] Maosong Fu, Sailesh Mittal, Vikas Kedigehalli, Karthik Ramasamy, Michael Barry, Andrew Jorgensen, Christopher Kellogg, Neng Lu, Bill Graham, and Jingwei Wu. “Streaming@ Twitter.” IEEE Data Eng. Bull. 38, no. 4 (2015): 15-27.
[4] http://storm.apache.org/
[5] http://storm.apache.org/releases/current/Trident-tutorial.html
[6] https://flink.apache.org/
[7] https://spark.apache.org/streaming/
[8] https://kafka.apache.org/documentation/streams/
[9] https://twitter.github.io/heron/api/python/
[10] https://github.com/twitter/heron/tree/master/heron/instance/src/cpp
[11] https://github.com/twitter/heron/tree/master/heron/schedulers/src/java/com/twitter/heron/scheduler
作者简介:吴惠君,Twitter软件工程师,致力于实时流处理引擎Heron的研究和开发。他毕业于Arizona State University,专攻大数据处理和移动云计算,曾在国际顶级期刊和会议发表多篇学术论文,并有多项专利。
吕能,Twitter实时计算平台团队成员。专注于分布式系统,曾参与过Twitter的Manhattan键值存储系统,Obs监控警报系统的开发,目前负责Heron的开发研究。曾在国际顶级期刊和会议发表多篇学术论文。
符茂松,Twitter实时计算平台团队主管,负责Heron, Presto等服务。Heron的原作者之一。专注于分布式系统,在SIGMOD, ICDE等会议期刊发表多篇论文。本科毕业于华中科技大学;研究生毕业于Carnegie Mellon University。
本文为《程序员》原创文章,未经允许不得转载。
1月13日,SDCC 2017之数据库线上峰会即将强势来袭,秉承干货实料(案例)的内容原则,邀请了来自阿里巴巴、腾讯、微博、网易等多家企业的数据库专家及高校研究学者,围绕Oracle、MySQL、PostgreSQL、Redis等热点数据库技术展开,从核心技术的深挖到高可用实践的剖析,打造精华压缩式分享,举一反三,思辨互搏,报名及更多详情可点击「阅读原文」查看。











)







