
总的来说,Spark采用更先进的架构,使得灵活性、易用性、性能等方面都比Hadoop更有优势,有取代Hadoop的趋势,但其稳定性有待进一步提高。我总结,具体表现在如下几个方面。
 1
1Q:为什么选择Kafka去承担类似数据总线的角色?
A:绝大部分是由于它简单的架构以及出色的吞吐量, 并且与Spark也有专门的集成模块. Kafka的出色吞吐量主要是来自于最大化利用系统缓存以及顺序读写所带来的优点, 同时offset和partition的涉及也提供了较好的容灾性.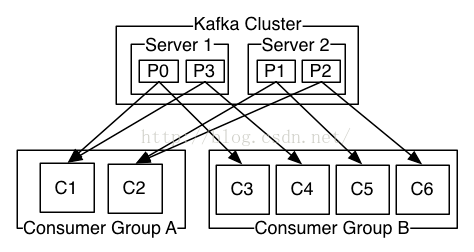
2Q:为什么选择Spark作为流计算引擎?
A:主要是由于Spark本身优雅的RDD设计让分布式编程更简单, 同时结合Spark的内存缓存层也使得计算更快,而Spark对各种技术的集成与支持, 能够使技术栈更简单和通用, 也是选用它的一个重要原因. 而Spark的DirectKafkaInputDStream也提供了简单有效的HA.
3Q:Spark和Hadoop的操作模型区别
A:Hadoop:只提供了Map和Reduce两种操作所有的作业都得转换成Map和Reduce的操作。
Spark:提供很多种的数据集操作类型比如Transformations 包括map, filter, flatMap, sample, groupByKey, reduceByKey, union, join, cogroup, mapValues,sort,partionBy等多种操作类型,还提供actions操作包括Count,collect, reduce, lookup, save等多种。这些多种多样的数据集操作类型,给开发上层应用的用户提供了方便。
4Q:spark Streaming 是什么?
A:Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
首先,Spark Streaming把实时输入数据流以时间片Δt (如1秒)为单位切分成块,Spark Streaming会把每块数据作为一个RDD,并使用RDD操作处理每一小块数据,每个块都会生成一个Spark Job处理,最终结果也返回多块。在Spark Streaming中,则通过操作DStream(表示数据流的RDD序列)提供的接口,这些接口和RDD提供的接口类似。
正如Spark Streaming最初的目标一样,它通过丰富的API和基于内存的高速计算引擎让用户可以结合流式处理,批处理和交互查询等应用。因此Spark Streaming适合一些需要历史数据和实时数据结合分析的应用场合。当然,对于实时性要求不是特别高的应用也能完全胜任,另外通过RDD的数据重用机制可以得到更高效的容错处理。
5Q:Spark streaming+Kafka应用
A:WeTest舆情监控对于每天爬取的千万级游戏玩家评论信息都要实时的进行词频统计,对于爬取到的游戏玩家评论数据,我们会生产到Kafka中,而另一端的消费者我们采用了Spark Streaming来进行流式处理,首先利用上文我们阐述的Direct方式从Kafka拉取batch,之后经过分词、统计等相关处理,回写到DB上(至于Spark中,由此高效实时的完成每天大量数据的词频统计任务。

小伙伴们冲鸭,后台留言区等着你!
关于Spark,今天你学到了什么?还有哪些不懂的?除此还对哪些话题感兴趣?快来留言区打卡啦!留言方式:打开第XX天,答:……
同时欢迎大家搜集更多问题,投稿给我们!风里雨里留言区里等你~
福利
1、扫描添加小编微信,备注“姓名+公司职位”,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!

推荐阅读:
如何高效地准备技术面试?
漫画:有趣的“帽子问题”
我为什么放弃了 Chrome?
5天破10亿的哪吒,为啥这么火,Python来分析
通俗易懂:图解10大CNN网络架构
互联网公司上演反腐风暴;GitHub CEO 对断供表示无能为力;程序员面试锦集| 开发者周刊
在其他国家被揭穿骗子又盯上非洲? 这几个骗子公司可把非洲人民坑苦了……











)







