前言
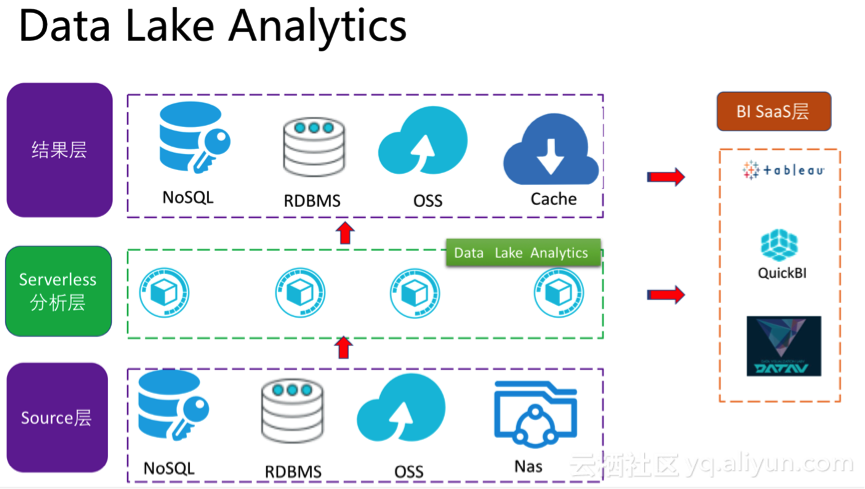
近期阿里云重磅推出新的数据分析引擎Data Lake Analytics,Data Lake Analytics是Serverless化的交互式联邦查询服务。无需ETL,使用标准SQL即可分析与集成对象存储(OSS)、数据库(PostgreSQL/MySQL/SQL Server等)、NoSQL(TableStore等)数据源的数据。本文将重点剖析Data Lake Analytics的出现,给传统数据分析带来了哪些变革。
极大的降低运行成本传统解决方案里,做数据分析,需要先购买一些分析节点实例(计算和存储一体化),无论是计算还是存储任何一方先到达瓶颈,都要线性的扩服务器资源,分析任务空闲的时候,计算资源的成本依旧需要承担。Data Lake Analytics是基于serverless架构的数据分析引擎,意味着客户使用分析服务无需购买或者管理服务器,升级透明,Data Lake Analytics基于ECS轻松做到弹性伸缩服务。能让业务真正做到按需扩存储,按使用量付费分析,不分析只需要拥有存储成本,整个方案成本极低。
数据分析架构更加灵活无论是自建Hadoop、开源的Greenplum等方案,存储和计算成本都是一体化的。选择了某种大数据分析技术后,存储和计算的方案都是固化的。而Data Lake Analytics的出现,则打破了这一架构局限性,使得数据分析方案更加灵活。客户可以选择将海量的KV查询的数据存储TableStore中,Data Lake Analytics可以告诉的查询处理TableStore中的数据。可以将业务流水数据存储在关系型数据库(MySQL、SQL Server、PostgreSQL)中,Data Lake Analytics可以赋予上述数据库复杂的查询能力。用户可以将日志或者归档数据存储在OSS中,使用Data Lake Analytics快速的分析处理OSS中的数据。在对于云上中小企业来说,可以结合业务的特点选择最廉价的存储搭配最普惠灵活的的分析能力,同时Data Lake Analytics还可以很好的将上述众多数据源做联邦查询。
ETL搬数据时代结束以往数据分析,需要将各路数据源(关系型数据库、日志、NoSQL等),按照天或者小时级别做抽取,汇总到数据仓库中做数据关联处理。Data Lake Analytics设计之初天然具有联邦分析能力,使得客户的数据不再需要搬迁至数据仓库汇总分析,而是就地分析。同时还能很好的跨异构数据源做关联分析、回流至关系型数据库或者OLAP引擎。
分析时效性大幅提升传统数仓,无论是H+1 还是T+1方案,由于数据同步周期长,架构链路长,导致时效性很差。Data Lake Analytics的多数据源联邦查询处理能力,避免了数据搬迁的同时,大大提升了数据处理的时效性,同时由于缩短了采集、存储、计算的链路,方案运行更加稳定。
总结
传统数据分析的抽取-装载-转换-回流的架构支撑了数据仓库多年的发展,而Data Lake Analytics的出现,给传统数据分析架构带来革新的同时,也赋予了云上目前OSS、TableStore、关系型数据库(PostgreSQL/MySQL/SQL Server等)存储强大的分析能力。对于云上中小企业来说,可以选择用最廉价、最适合业务场景的存储,来搭配最普惠灵活的的分析能力。阿里云Data Lake Analytics正是最普惠灵活的分析能力的实践者,目前公测期间免费试用,欢迎大家前来体验。
了解更多大数据家族产品详情,欢迎点击:
https://et.aliyun.com/bigdatarelease
点击观看大数据家族产品发布会:
https://yq.aliyun.com/webinar/play/508
【阿里云新品发布】开启新一代数据智能开发之路:
https://yq.aliyun.com/roundtable/325525
原文链接
本文为云栖社区原创内容,未经允许不得转载。



















