前言:
不修内功,难成大器。为了将Apache Flink在阿里巴巴真正运行起来,阿里巴巴实时计算团队做了大量的优化,在阿里云上的产品正式命名为实时计算,以Flink SQL为主要API,致力于打造一款全球领先的实时计算引擎。
正文:
阿里云实时计算大可成稻草,小亦是利器
在光明日报近期的文章中,回首互联网接入中国的二十多年,特别是最近五年,被互联网之光照耀的地方,许多人的命运因互联网而发生改变,人们可以通过一个鼠标、一根网线或者一部手机就能与广阔的世界相连。
有了互联网,陕西省山阳县贫困山区的孩子可以免费接受数字教育,通过互联网认识到长颈鹿不是猪身马首的动物。有了互联网,甘肃山村贫困户家里养的山羊二十四小时就能通过专业冷链供应给上海市民。有了互联网,80岁的乌镇老太太可以用手机购物,开直播,成为“网红”。这样的故事还有很多很多。
然而科技并未止步于此,一直在不断向前探索,对于企业来说,互联网一面是阳光,一面是波涛。从互联网时代到人工智能时代,从数据量成指数级的爆发到应对实时计算的探索。到了今天,我们不止将目光局限在淘宝能购物就好,物流能到货就好,我们追求的是越来越精准化的购物体验,对企业也提出了更加实时化,智能化的需求。
实时计算一时间成为了企业向实时化、智能化大数据计算升级转型的稻草,抓住,则可继续在波涛浪潮中翻滚,享受阳光。为了成为全球领先的实时计算引擎,阿里云实时计算花了三年时间来苦练内功。
阿里云实时计算的前半生,我叫Apache Flink™
2015年10月StreamCompute第一版在阿里巴巴集团内部发布,支持集团双十一任务迁移到新平台,保障大屏任务顺利。2016年blink发布上线,成功支持搜索和推荐双11全链路实时化。同年6月,公有云正式对外发布公测,为中国公有云环境下第一家提供流式数据处理平台的产品Apache Flink™正式上线,并从阿里巴巴的搜索和推荐这两大场景开始实现。
对于阿里巴巴来说,为什么需要Apache Flink™
阿里巴巴的商品数据处理经常需要面对增量和全量两套不同的业务流程问题,所以阿里巴巴就在想:能不能有一套统一的大数据引擎技术,用户只需要根据自己的业务逻辑开发一套代码。这样在各种不同的场景下,不管是全量数据还是增量数据,亦或者实时处理,一套方案即可全部支持,这就是阿里巴巴选择 Flink 的背景和初衷。
目前阿里巴巴所有的业务,包括阿里巴巴所有子公司都采用了基于 Flink 搭建的实时计算平台。同时 Flink 计算平台运行在开源的 Hadoop 集群之上。采用 Hadoop 的 YARN 做为资源管理调度,以 HDFS 作为数据存储。因此,Flink 可以和开源大数据软件 Hadoop 无缝对接。
但是彼时的 Flink 不管是规模还是稳定性尚未经历实践,成熟度有待商榷。
阿里云实时计算关键技术揭秘
揭秘关键技术之一:统一API
为了能够真正做到用户根据自己的业务逻辑开发一套代码,能够同时运行在多种不同的场景,Flink 首先需要给用户提供一个统一的 API。在经过一番调研之后,阿里巴巴实时计算认为 SQL 是一个非常适合的选择。在批处理领域,SQL 已经经历了几十年的考验,是公认的经典。
API选定好了,随之而来的就是对SQL 层的技术架构进行升级和替换。阿里巴巴在 SQL 层提出了全新的 Quyer Processor,主要包括一个流和批可以尽量做到复用的优化层(Query Optimizer)以及基于相同接口的算子层(Query Executor)。这样一来, 80% 以上的工作可以做到两边复用,比如一些公共的优化规则,基础数据结构等等。同时,流和批也会各自保留自己一些独特的优化和算子,以满足不同的作业行为。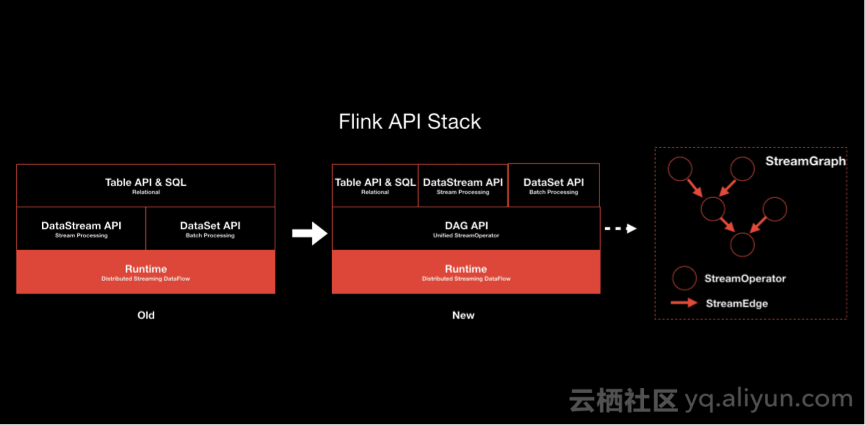
揭秘关键技术之二:全新的数据结构
SQL 层的技术架构统一了,阿里巴巴开始寻求以全新的数据结构BinaryRow,从而让 Blink 在 SQL 层的执行效率得到1倍以上的提升。得益于技术架构和基础数据结构的统一,很多代码生成技术得以达到更广范围的复用。同时由于 SQL 的强类型保证,用户可以预先知道算子需要处理的数据的类型,从而可以生成更有针对性更高效的执行代码。
揭秘关键技术之三: 改造 Flink 资源调度系统
为了让 Flink 在 Alibaba 的大规模生产环境中生根发芽,实时计算团队如期遇到了各种挑战,首当其冲的就是如何让 Flink 与其他集群管理系统进行整合。上面说到了Flink 原生集群管理模式尚未完善,也无法原生地使用其他其他相对成熟的集群管理系统。基于此,一系列棘手的问题接连浮现:多租户之间资源如何协调?如何动态的申请和释放资源?如何指定不同资源类型?
通过大量的调研与分析,最终选择的方案是改造 Flink 资源调度系统,让 Flink 可以原生地跑在 Yarn 集群之上;并且重构 Master 架构,以此为契机,阿里巴巴和社区联手推出了全新的 Flip-6 架构,让 Flink 资源管理变成可插拔的架构,为 Flink 的可持续发展打下了坚实的基础。如今 Flink 可以无缝运行在 YARN、Mesos 和 K8s 之上,正是这个架构重要性的有力说明。
揭秘关键技术之四:高可靠性、高稳定性
为了保证 Flink 在生产环境中的高可用,阿里巴巴着重改善了 Flink 的 FailOver 机制。首先是 Master 的 FailOver,Flink 原生的 Master FailOver 会重启所有的 Job,改善后 Master 任何 FailOver 都不会影响 Job 的正常运行;其次引入了 Region-based 的 Task FailOver,尽量减少任何 Task 的 FailOver 对用户造成的影响。有了这些改进的保驾护航,阿里巴巴的大量业务方开始把实时计算迁移到 Flink 上运行。
阿里云实时计算,锤炼后必将大放异彩
阿里云实时计算在阿里巴巴内部是一个不断被挑战,不断强化的过程。阿里巴巴是商业市场的缩影,淘宝、阿里影业等都已应用了阿里云实时计算。支撑了淘宝对选品实时性的高要求,为阿里影业提供了满足未来2-3年随着影院增加,数据增长的报表功能解决方案。
在外部解决了贵州茅台数据采集实时性、稳定性差、各渠道下的流量、交易及售后物流、服务、退款退货等环节分析困难、异常预警信息监控困难等难题。
阿里云实时计算今年4月份正式商业化之后,截止目前,使用用户已经超过2000家。在已有的用户中,实时计算主要应用于实时互联网数据分析、实时数据大屏、实时金融风控、电商实时推荐等诸多领域。阿里集团内淘宝、天猫、天弘基金、菜鸟、工业大脑等诸多业务均大量应用了实时计算技术,在集团外,也包括众安保险、全民TV、新华智云、贵州茅台等诸多公司的应用案例。
2005年,弗里德曼在《地球是平的》一书中,曾兴奋地描述了技术让世界变平的过程,预言全球化的大趋势不可逆转。尽管当今世界,全球化的过程面临一波三折,但全球化的浪潮,终究是不可逆的,特别是在这个互联网时代。今天,阿里云实时计算用自身的实力不断证明了自己,成为全球领先的实时计算引擎。
原文链接
本文为云栖社区原创内容,未经允许不得转载。




)








--- Pandas高级处理分组与聚合)





