现在做任何事情都要看投入产出比,对应到数据库上其实就是性价比。POLARDB作为一款阿里自研数据库,经常被问的问题是:性能怎么样?能不能支撑我的业务?价格贵不贵?很显然,在早期调研阶段,对稳定性、可靠性很难有量化的指标时,性能的好快就成了一个非常关键的决策因子。
POLARDB在一开始设计时就把性能作为一项关键的需求指标列入产品需求说明书,从架构设计到新硬件选型,再到代码实现,从驱动到分布式块存储,再到分布式文件系统和数据库引擎,打通整个技术栈做协同优化,最终才能保证性能上有数量级的提升。
高性能背后的技术
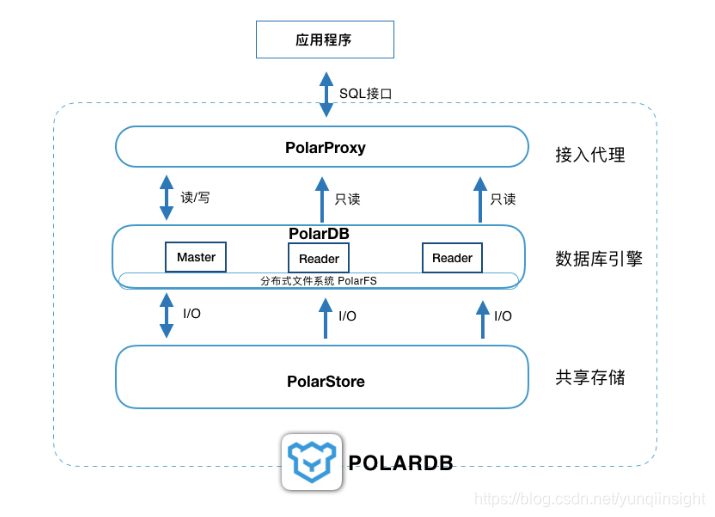
在2018杭州云栖大会上分享的这张架构图展示了POLARDB的内部细节。自下而上来看,POLARDB由__共享分布式存储PolarStore__,__分布式文件系统PolarFS__,__多节点的数据库集群PolarDB__和__提供统一入口的代理PolarProxy__这四部分组成。
PolarFS
PolarFS设计中采用了如下技术以充分发挥I/O性能:
- PolarFS采用了绑定CPU的单线程有限状态机的方式处理I/O,避免了多线程I/O pipeline方式的上下文切换开销。
- PolarFS优化了内存的分配,采用MemoryPool减少内存对象构造和析构的开销,采用巨页来降低分页和TLB更新的开销。
- PolarFS通过中心加局部自治的结构,所有元数据均缓存在系统各部件的内存中,基本完全避免了额外的元数据I/O。
- PolarFS采用了全用户空间I/O栈,包括RDMA和SPDK,避免了内核网络栈和存储栈的开销。
在相同硬件环境下的对比测试,PolarFS中数据块3副本写入性能接近于单副本本地SSD的延迟性能。从而在保障数据可靠性的同时,极大地提升POLARDB的单实例TPS性能。
PolarDB
在数据库PolarDB中开创性地引入了物理日志(Redo Log)代替了传统的逻辑日志,不仅极大地提升了复制的效率和准确性,还节省了50%的 I/O 操作,对于有频繁写入或更新的数据库,性能可提升50%以上。

PolarProxy
PolarProxy存在的意义是可以把底层的多个计算节点的资源整合到一起,提供一个统一的入口,让应用程序访问,极大地降低了应用程序使用数据库的成本,也方便了从老系统到POLARDB的迁移和切换。本质上,PolarProxy是一个容量自适应的分布式无状态数据库代理集群,动态的横向扩展能力,可以将POLARDB快速增减读节点的优势发挥到极致,提升整个数据库集群的吞吐,访问它的ECS越多,并发越高,优势越明显。
关于成本
抛开成本谈性能,都是耍流氓。
首先,POLARDB存储与计算分离的架构,可以让CPU、内存和磁盘摆脱互相制约的困扰,让计算和存储作为单独的资源池进行管理和分配,大幅降低资源碎片,提升整体的资源利用率。计算和存储的机型不同,我们还可以更有针对性地做定制和优化,降低单位资源的成本。
通用意义上,规模效应带来的边际成本递减这件事,会一直发生。在阿里巴巴超大规模的基础设施的基础上,我们可以持续不断地从全球供应链、低能耗数据中心、服务器研发等多个维度来降低我们的成本。
性价比
不管技术上有多先进,成本上有多低,最终还是需要用户认可。
所以,我们从用户角度来看,最关心的其实还是性价比,即同样的费用,是否可以获取更好的性能。
我们简单算笔账,来看一下POLARDB和RDS MySQL的性价比。
公平起见,我们使用同样的数据库配置,测试数据集和测试方法,然后分别计算出二者的价格和性能。
其中,
- 数据库配置采用生产环境常见的『8核 32G ,500G存储』的配置
- 数据集和测试方法采用通用的sysbench OLTP测试用例(--oltp-tables-count=10 --oltp-table-size=500000)
- 性能指标我们取QPS(Query per Second 每秒钟处理请求数)和TPS( Transaction per Second 每秒钟处理事务数)
此外,不管是RDS MySQL还是POLARDB,都具备了通过增加只读节点来达到横向扩展读(Scale out)的能力,不同的是,POLARDB随着节点数的增加,并不需要额外的存储费用,因此,我们需要多对比几种架构,从1个读节点到3个读节点,具体如下:
| 集群架构 | POLARDB 月价(计算规格+存储) | RDS MYSQL 月价 | POLARDB比RDS贵 | POLARDB 性能(QPS) | RDS MySQL性能(QPS) | POLARDB性能提升 | 千元性能指标(RDS vs. POLARDB) |
|---|---|---|---|---|---|---|---|
| 1主1备 | 2000*2 +1575=5575 | 4100+400=4500 | +24% | 53879.46 | 18625.49 | +190% | 4139 vs. 9664 |
| 1主2备 | 2000*3+1575=7575 | (4100+400)+(5.13+0.001*400)*24*30=8481 | -10% | 66626.63 | 26357.94 | +150% | 3107 vs. 8795 |
| 1主3备 | 2000*4+1575=9575 | (4100+400)+(5.13+0.001400)24302=12463 | -23% | 80268.27 | 43087.33 | +86% | 3457 vs. 8383 |
表中的一些基础价格(以2018.11.8 当天价格为例):
- POLARDB存储月价:1575元/月 = 500GB * 3.5元/GB/月
- POLARDB 1个节点的月价是2000元
- MySQL高可用版实例(双节点)的月价是4100元
- MySQL高可用版实例存储月价:400元/月 = 500GB * 0.8元/GB/月
- MySQL只读实例小时价:5.13元/小时
- MySQL只读实例存储小时价:0.001元/GB/小时
用下图展示会更清晰一些,其中灰色的『备库』不对外提供服务。由此可见,POLARDB的性价比非常高,所有节点都提供服务,因此资源利用率也较RDS高。

彩蛋——免费使用的复杂SQL查询加速
在实际应用中,客户的业务是复杂的,很多时候业务访问会掺杂着大量的统计分析类的复杂SQL(Ad-hoc query),这时候MySQL的单线程模型处理起来就会捉襟见肘。
POLARDB为了应对这种场景,内置了并行查询引擎,针对大表复杂查询(比如TCP-H基准测试)性能可提升8倍,特别适用于执行时长超过1分钟的慢SQL(比如报表查询)。同时还支持了集合运算、WITH、窗口函数OVER等高级语法。该功能目前已经公测,免费使用,详细参考『SQL加速』。
以下图表是我们做了一个对比测试,在使用SQL加速的情况下,查询效率是不使用SQL加速直接查询的8倍以上,具体的测试用例包括,
- Point query on non-indexed column(无索引列的单行查询)
- Aggregate query(聚合查询)
- TPC-H

目前SQL加速功能,提供了额外的连接地址,提供非事务的复杂查询服务。底层的计算节点和存储复用POLARDB现有的资源,一份数据多种访问方式,省去了数据迁移的烦恼,也不需要额外的成本投入。
技术实现上,包括以下几点,
- 插件式计算引擎,负责分布式算子计算
- 单表计算下推到数据库引擎
- 大SQL并行计算

原文链接
本文为云栖社区原创内容,未经允许不得转载。



















