维基百科对智能有如下定义:
智能是一种能够感知或推断信息,并将其作为知识留存下来,自适应地用于某种环境或上下文的能力。
人工智能(Artificial Intelligence)
虽然我们很难对人工智能做一个确切的解释,但可以从查尔斯巴贝奇的分析机讲起。它虽然没有任何特殊的“自适应”能力,但却非常灵活。遗憾的是,理论上虽然完美,但却没有得以实现。
巴贝奇分析机早图灵机50年左右出现。从理论上讲,它能够将任何可计算的函数作为输入,并在完全机械的情况下产生输出。
复杂性理论(complexity theory)由此得以发展,同时人们也意识到构建通用计算机其实相对简单。此外,算法的实现也越发多样。尽管还存在一些技术上的挑战,但在过去的70年中,相同价格可购买到的计算量大约每两年翻一番。
也就是说,构建计算力强大的人工智能系统越发容易。然而,这受到了所提供或输入的数据,以及处理时间的限制。可以做如下思考:如果每台计算机的能力都受到数据和时间的限制,我们还能称之为智能计算机么?
下面我们简单回顾一下人工智能的发展史。人类的智能主要包括归纳总结和逻辑演绎,对应着人工智能中的联结主义(如人工神经网络)和符号主义(如吴文俊方法)。符号主义认为智能是基于逻辑规则的符号操作;联结主义认为智能是由神经元构成的信息处理系统。其发展轨迹如下图所示:
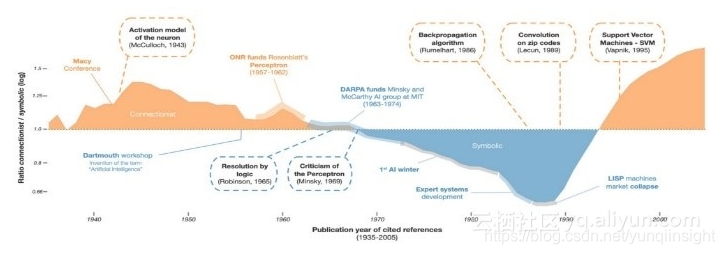
联结主义,即“橙色阵营”在一开始处于领先地位,得益于其与神经科学和人类大脑之间的关系。人类大脑被视为“强AI(Strong Artificial Intelligence)”和“通用人工智能(Artificial General Intelligence,AGI)”唯一的成功应用。然而,第一代神经网络在处理实际问题时屡屡受挫。因为神经网络多数是线性的,并且能力十分有限,深受外界质疑。与此同时,符号主义,即“蓝色阵营”利用严谨的数学理论创造出了更多有用的东西。
随着手工知识的积累,输入或输出数据量急速增长,系统的性能无法适应需求,联结主义逐渐衰败。就好比法律,专家制定出再完备的规则都有可能相互冲突,此时便需要越来越多的“法官”来解决这些问题。这减缓了联结主义的发展。
后来,“橙色阵营”获取了足够的标签数据和计算资源,能够在可接受的时间内对网络进行“训练”,世界各地的研究学者开始进行大量试验。尽管如此,联结主义仍花费了大量的时间使大众重新信任神经网络,开发人员也花了较长才适应了模糊逻辑和统计的概念。
在对人工神经网络进行详细讨论前,本文将先介绍一些其它方法:决策树、概率模型、进化算法。
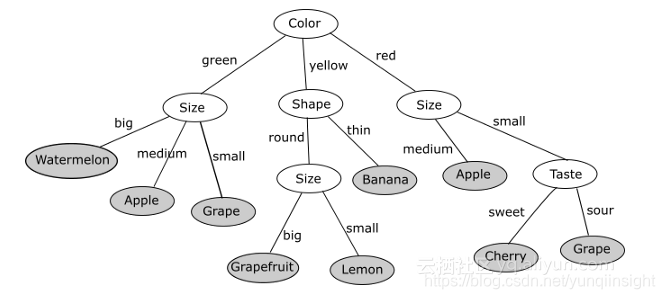
决策树(Decision Tree)是最简单有效的算法之一。其“学习”是通过顺序地遍历数据的每个属性并找到对特定输出具有最大预测能力的属性来执行的。像随机森林这样的高级变体使用了更复杂的学习技术,并在同一个模型中组合多个树,它们的输出是通过“投票”得到的,这与人类的“直觉”类似。
概率模型(Probabilistic models)是统计方法的代表。概率模型与神经网络常共享架构、学习/优化过程甚至符号。但是概率模型大多受概率逻辑(通常是贝叶斯)的约束,而神经网络则无此约束。
进化算法(Evolutionary computation)最初是受到生物进化的启发,且以随机突变和适应度为主。由于修改通常是随机的,其限制噪声的效果突出。进化算法是一种引导式搜索,许多方面与退火过程类似。

上述方法有一个共同点:它们从较差的策略开始,逐渐对其改善,以期在某种性能评估方法中取得更好的分数。
如今,机器学习技术,尤其是深度学习正在主导人工智能的发展。与大多数使用1到2个中间抽象层(所谓的浅模型)机器学习方法不同,深度学习可能包含数百甚至数千个堆叠的可训练层。
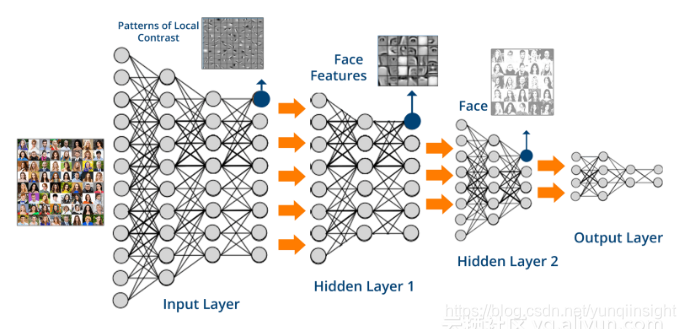
研究学者认为对这样的深度网络进行训练,需要全新的优化程序。事实证明,使用梯度下降的逆向传播(即链式法则)即可很好的进行训练,也可使用Adam或RMSProp。
神经网络训练流程如下:
1、 获取输入
2、 计算输出
3、 评估性能
4、 调节参数
5、 重复训练,至性能最优
梯度下降法只需调整参数使误差最小。但该方法容易使网络陷入局部最优,而没有获得最优性能。然而,最新研究表明许多神经网络已经能够获取全局最优解。
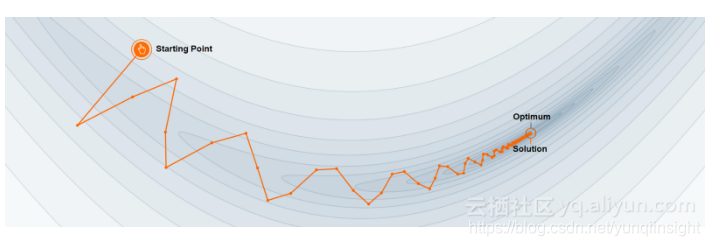
深度学习实现了训练的并行化,即分布式学习。能在同一时间跨多台机器训练相同的体系结构,同时实现梯度交换,加速超过1000倍。
此外,经过训练的网络可以处理相似的任务,即迁移学习,这也是人工神经网络广泛流行的重要原因。例如,经过图像分类训练的网络可以用于其他计算机视觉任务,自然语言处理和其他领域。更重要的是,同一个网络还可以用来解决不同模式的问题。
强化学习(Reinforcement Learning,RL)则将它们结合在了一起。RL的最初想法来自行为心理学,科研人员探究了在行为心理学中奖励如何影响学习和塑造动物的行为。
RL并不需要出现正确的输入/输出对,也不需要精确校正次优化的行为。举个例子,我们并不需要教会机器人如何精确移动,只需根据它走多远或多快对其进行奖励,它会自己找出正确的路线。然而,这种训练模式在实践中也是最具挑战性的,即使是相对简单的任务,通常也需要付出大量的努力才能正确设置。
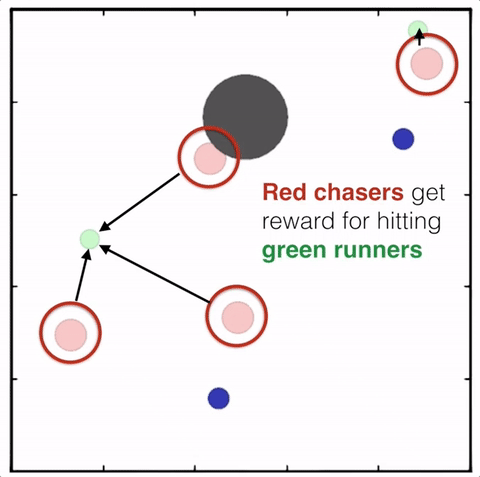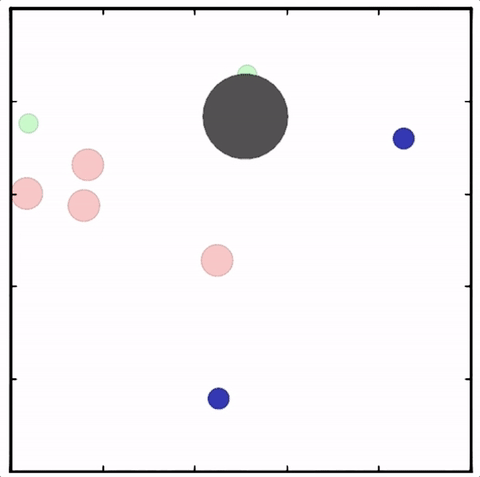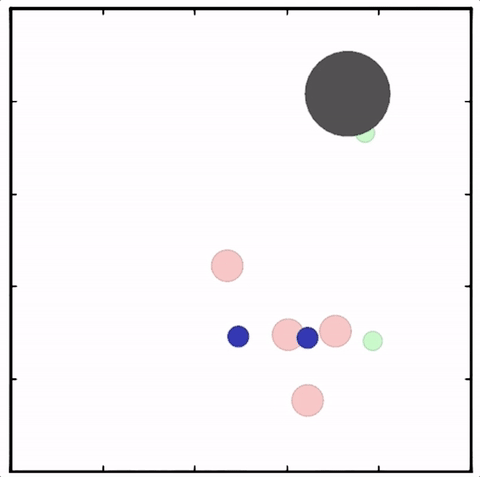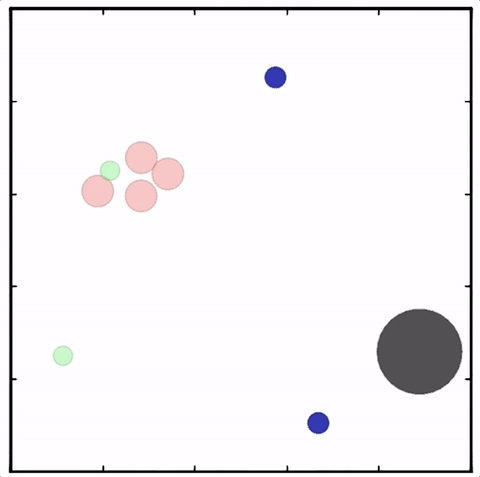
在实际问题中,通常很难在环境中指定奖励,研究人员目前更多地关注内部奖励模型。
与RL并行的是逆向强化学习(Inverse Reinforcement Learning):当完成复杂的任务时,强化学习的回报函数很难指定,我们希望有一种方法能够找到高效且可靠的回报函数,这种方法就是逆向强化学习。
通用人工智能中一些框架来自于严格的数学理论,一些受神经元回路的启发,还有一些基于心理模型。本文将以HTM、AIXI、ACT-R和SOAR为例进行介绍。
层级实时记忆算法 (Hierarchical Temporal Memory,HTM),HTM算法旨在模拟新大脑皮层的工作原理,将复杂的问题转化为模式匹配与预测。它强调对“神经元”进行分层级,以及信息模式的空间特性与时间特性。
稀疏分布表示(Sparse Distributed Representation, SDR)是HTM算法中的一个重要概念。实际上,它只是拥有几千个元素的位数组。就像大脑中的信息总是通过亿万神经细胞中的小部分活跃细胞来表示一样,HTM使用稀疏分布表示语义相关的输入。
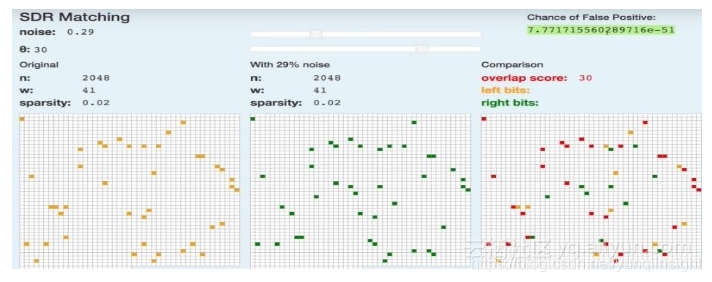
HTM算法中的抑制(Inhibition)类似于批规范化和其他一些正则化技术,提升(Boosting)在机器学习中已经是一个相对较老的概念,层次结构(Hierarchical Structure)并没有真正的大脑皮层的结构灵活。HTM对物体间关系的重视程度低,甚至连稀疏分布表示也可以用普通神经网络构建。总体来说,HTM需要进行大量调整才能获取与其它机器学习算法相当的性能。
接下来介绍AIXI,它是一个对通用人工智能的理论上的数学形式化表示。然而,它有一个显著的缺点——无法计算。事实上,许多机器学习算法均不能精确计算,只能做近似处理。AIXI表示如下:
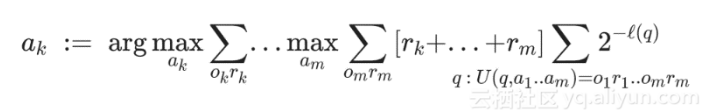
AIXI的核心是一个强化学习智能体,在诸多方面与Schmidhuber开发的Godel Machine类似。然而,它们都是AGI的描述性模型,复杂程度高,无法执行,但不可否认,它们都是人工智能研究人员的灵感源泉。
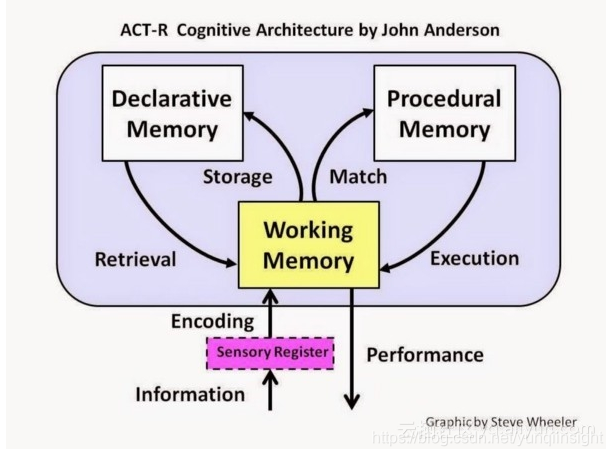
相反,ACT-R,即理性思维的自适应控制系统 (AdaptiveControl of Thought—Rational),它不仅是一种理论,而且是一种用LISP编写的软件框架。
ACT-R主要关注不同类型的内存,较少关注其中数据的转换。该理论试图理解人类如何获得和组织知识以及如何产生智力活动,其研究进展基于神经生物学研究成果并从中得以验证,且已成功地为许多不同认知现象建立起合理的模型。然而,它在实际应用中并未取得成功,最终只作为研究人员的工具。SOAR与ACT-R有着相似的根源和基本假设,但它更关注于实现AGI,而不是建立人类认知的模型。
ACT-R和SOAR是人工智能符号主义的经典代表,在认知科学的发展中起到了重要作用,但是应用它们相比现代联结主义需要更多的配置和先验知识。此外,神经影像和其他用于心智研究的工具越发详细和准确,而且ACT-R和SOAR在某一定程度上过于僵化,无法保持相关性。
原文链接
本文为云栖社区原创内容,未经允许不得转载。
)










报名通道即将关闭(附参会提醒)...)

)





