
阿里妹导读:减少故障的最好方法就是让故障经常性的发生。通过不断重复失败过程,持续提升系统的容错和弹性能力。今天,阿里巴巴把六年来在故障演练领域的创意和实践汇浓缩而成的工具进行开源,它就是 “ChaosBlade”。如果你想要提升开发效率,不妨来了解一下。
高可用架构是保障服务稳定性的核心。
阿里巴巴在海量互联网服务以及历年双11场景的实践过程中,沉淀出了包括全链路压测、线上流量管控、故障演练等高可用核心技术,并通过开源和云上服务的形式对外输出,以帮助企业用户和开发者享受阿里巴巴的技术红利,提高开发效率,缩短业务的构建流程。
例如,借助阿里云性能测试 PTS,高效率构建全链路压测体系,通过开源组件 Sentinel 实现限流和降级功能。这一次,经历了 6 年时间的改进和实践,累计在线上执行演练场景达数万次,我们将阿里巴巴在故障演练领域的创意和实践,浓缩成一个混沌工程工具,并将其开源,命名为 ChaosBlade。
ChaosBlade 是什么
ChaosBlade 是一款遵循混沌工程实验原理,提供丰富故障场景实现,帮助分布式系统提升容错性和可恢复性的混沌工程工具,可实现底层故障的注入,特点是操作简洁、无侵入、扩展性强。
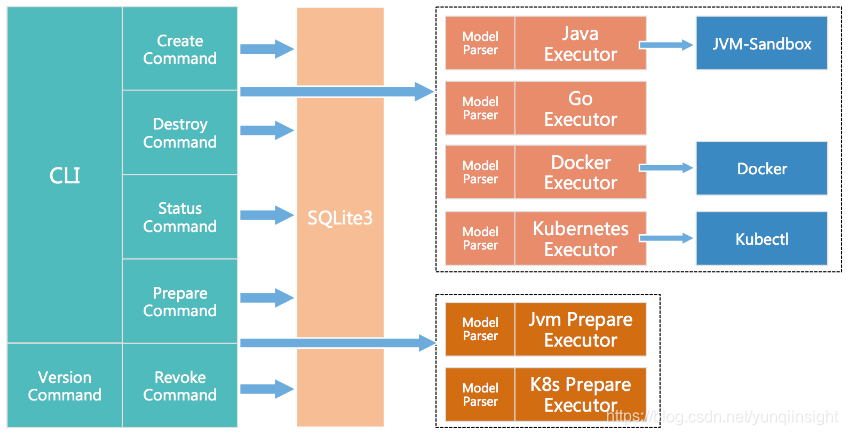
ChaosBlade 基于 Apache License v2.0 开源协议,目前有 chaosblade 和 chaosblade-exe-jvm 两个仓库。
chaosblade 包含 CLI 和使用 Golang 实现的基础资源、容器相关的混沌实验实施执行模块。chaosblade-exe-jvm 是对运行在 JVM 上的应用实施混沌实验的执行器。
ChaosBlade 社区后续还会添加 C++、Node.js 等其他语言的混沌实验执行器。
为什么要开源
很多公司已经开始关注并探索混沌工程,渐渐成为测试系统高可用,构建对系统信息不可缺少的工具。但混沌工程领域目前还处于一个快速演进的阶段,最佳实践和工具框架没有统一标准。实施混沌工程可能会带来一些潜在的业务风险,经验和工具的缺失也将进一步阻止 DevOps 人员实施混沌工程。
混沌工程领域目前也有很多优秀的开源工具,分别覆盖某个领域,但这些工具的使用方式千差万别,其中有些工具上手难度大,学习成本高,混沌实验能力单一,使很多人对混沌工程领域望而却步。
阿里巴巴集团在混沌工程领域已经实践多年,将混沌实验工具 ChaosBlade 开源目的,是为了:
- 让更多人了解并加入到混沌工程领域;
- 缩短构建混沌工程的路径;
- 同时依靠社区的力量,完善更多的混沌实验场景,共同推进混沌工程领域的发展。
ChaosBlade 能解决哪些问题
衡量微服务的容错能力
通过模拟调用延迟、服务不可用、机器资源满载等,查看发生故障的节点或实例是否被自动隔离、下线,流量调度是否正确,预案是否有效,同时观察系统整体的 QPS 或 RT 是否受影响。在此基础上可以缓慢增加故障节点范围,验证上游服务限流降级、熔断等是否有效。最终故障节点增加到请求服务超时,估算系统容错红线,衡量系统容错能力。
验证容器编排配置是否合理
通过模拟杀服务 Pod、杀节点、增大 Pod 资源负载,观察系统服务可用性,验证副本配置、资源限制配置以及 Pod 下部署的容器是否合理。
测试 PaaS 层是否健壮
通过模拟上层资源负载,验证调度系统的有效性;模拟依赖的分布式存储不可用,验证系统的容错能力;模拟调度节点不可用,测试调度任务是否自动迁移到可用节点;模拟主备节点故障,测试主备切换是否正常。
验证监控告警的时效性
通过对系统注入故障,验证监控指标是否准确,监控维度是否完善,告警阈值是否合理,告警是否快速,告警接收人是否正确,通知渠道是否可用等,提升监控告警的准确和时效性。
定位与解决问题的应急能力
通过故障突袭,随机对系统注入故障,考察相关人员对问题的应急能力,以及问题上报、处理流程是否合理,达到以战养战,锻炼人定位与解决问题的能力。
功能和特点
场景丰富度高
ChaosBlade 支持的混沌实验场景不仅覆盖基础资源,如 CPU 满载、磁盘 IO 高、网络延迟等,还包括运行在 JVM 上的应用实验场景,如 Dubbo 调用超时和调用异常、指定方法延迟或抛异常以及返回特定值等,同时涉及容器相关的实验,如杀容器、杀 Pod。后续会持续的增加实验场景。
使用简洁,易于理解
ChaosBlade 通过 CLI 方式执行,具有友好的命令提示功能,可以简单快速的上手使用。命令的书写遵循阿里巴巴集团内多年故障测试和演练实践抽象出的故障注入模型,层次清晰,易于阅读和理解,降低了混沌工程实施的门槛。
场景扩展方便
所有的 ChaosBlade 实验执行器同样遵循上述提到的故障注入模型,使实验场景模型统一,便于开发和维护。模型本身通俗易懂,学习成本低,可以依据模型方便快捷的扩展更多的混沌实验场景。

ChaosBlade 的演进史
EOS(2012-2015):
故障演练平台的早期版本,故障注入能力通过字节码增强方式实现,模拟常见的 RPC 故障,解决微服务的强弱依赖治理问题。
MonkeyKing(2016-2018):
故障演练平台的升级版本,丰富了故障场景(如:资源、容器层场景),开始在生产环境进行一些规模化的演练。
AHAS(2018.9-至今):
阿里云应用高可用服务,内置演练平台的全部功能,支持可编排演练、演练插件扩展等能力,并整合了架构感知和限流降级的功能。
ChaosBlade(2019.3):
是 MonkeyKing 平台底层故障注入的实现工具,通过对演练平台底层的故障注入能力进行抽象,定义了一套故障模型。配合用户友好的 CLI 工具进行开源,帮助云原生用户进行混沌工程测试。

近期规划
功能迭代:
- 增强 JVM 演练场景,支持更多的 Java 主流框架,如 Redis,GRPC
- 增强 Kubernetes 演练场景
- 增加对 C++、Node.js 等应用的支持
社区共建:
1、欢迎访问 ChaosBlade@GitHub,参与社区共建,包括但不限于:
- 架构设计
- 模块设计
- 代码实现
- Bug Fix
- Demo样例
- 文档、网站和翻译
原文链接
本文为云栖社区原创内容,未经允许不得转载。


...)
















...)