本文介绍一个因为conntrack内核参数设置和iptables规则设置的原因导致TCP连接不能正常关闭(socket一直处于FIN_WAIT_1状态)的案例,并介绍conntrack相关代码在conntrack表项超时后对新报文的处理逻辑。
案例现象
问题的现象:
ECS上有一个进程,建立了到另一个服务器的socket连接。 kill掉进程,发现tcpdump抓不到FIN包发出,导致服务器端的连接没有正常关闭。
为什么有这种现象呢?
梳理
正常情况下kill进程后,用户态调用close()系统调用来发起TCP FIN给对端,所以这肯定是个异常现象。关键的信息是:
- 用户态kill进程。
- ECS网卡层面没有抓到FIN包。
从这个现象描述中可以推断问题出在位于用户空间和网卡驱动中间的内核态中。但是是系统调用问题,还是FIN已经构造后出的问题,还不确定。这时候比较简单有效的判断的方法是看socket的状态。socket处于TIME_WAIT_1状态,这个信息很有用,可以判断系统调用是正常的,因为按照TCP状态机,FIN发出来后socket会进入TIME_WAIT_1状态,在收到对端ACK后进入TIME_WAIT_2状态。关于socket的另一个信息是:这个socket长时间处于TIME_WAIT_1状态,这也反向证明了在网卡上没有抓到FIN包的陈述是合理。FIN包没出虚机网卡,对端收不到FIN,所以自然没有机会回ACK。
真凶
问题梳理到了这里,基本上可以进一步聚焦了,在没有大bug的情况下,需要重点看下iptables(netfilter), tc等机制对报文的影响。果然在ECS中有许多iptables规则。利用iptables -nvL可以打出每条rule匹配到的计数,或者利用写log的办法,示例如下:
# 记录下new state的报文的日志
iptables -A INPUT -p tcp -m state --state NEW -j LOG --log-prefix "[iptables] INPUT NEW: "在这个案例中,通过计数和近一步的log,发现了是OUTPUT chain的最后一跳DROP规则被匹配上了,如下:
# iptables -A OUTPUT -m state --state INVALID -j DROP问题的真凶在此时被找到了:iptables规则丢弃了kill进程后发出的FIN包,导致对端收不到,连接无法正常关闭。
到了这里,离最终的root cause还有两个疑问:
- 问题是否在全局必现?触发的条件是什么?
- 为什么FIN包被认为是INVALID状态?
何时触发
先来看第一个问题:问题是否在全局必现?触发的条件是什么?
对于ECS上与服务器建立TCP连接的进程,问题实际上不是每次必现的。建议用netcat来做测试,验证下是否是全局影响。通过测试,有如下发现:
- 利用netcat做类似的操作,也能复现同样的问题,说明这个确实是全局影响,与特定进程或者连接无关。
- 连接时间比较长时能复现,时间比较短时kill进程时能正常发FIN。
看下conntrack相关的内核参数设置,发现ECS环境的conntrack参数中有一个显著的调整:
net.netfilter.nf_conntrack_tcp_timeout_established = 120
这个值默认值是5天,阿里云官网文档推荐的调优值是1200秒,而现在这个ECS环境中的设置是120秒,是一个非常短的值。
看到这里,可以认定是经过nf_conntrack_tcp_timeout_established 120秒后,conntrack中的连接跟踪记录已经被删除,此时对这个连接发起主动的FIN,在netfilter中回被判定成INVALID状态。而客户在iptables filter表的OUTPUT chain中对INVALID连接状态的报文采取的是drop行为,最终导致FIN报文在netfilter filter表OUTPUT chain中被丢弃。
FIN包被认为是INVALID状态?
对于一个TCP连接,在conntrack中没有连接跟踪表项,一端FIN掉连接的时候的时候被认为是INVALID状态是很符合逻辑的事情。但是没有发现任何文档清楚地描述这个场景:当用户空间TCP socket仍然存在,但是conntrack表项已经不存在时,对一个“新”的报文,conntrack模块认为它是什么状态。
所有文档描述conntrack的NEW, ESTABLISHED, RELATED, INVALID状态时大同小异,比较详细的描述如文档:
The NEW state tells us that the packet is the first packet that we see. This means that the first packet that the conntrack module sees, within a specific connection, will be matched. For example, if we see a SYN packet and it is the first packet in a connection that we see, it will match. However, the packet may as well not be a SYN packet and still be considered NEW. This may lead to certain problems in some instances, but it may also be extremely helpful when we need to pick up lost connections from other firewalls, or when a connection has already timed out, but in reality is not closed.
如上对于NEW状态的描述为:conntrack module看见的一个报文就是NEW状态,例如TCP的SYN报文,有时候非SYN也被认为是NEW状态。
在本案例的场景里,conntrack表项已经过期了,此时不管从用户态发什么报文到conntrack模块时,都算是conntrack模块看见的第一个报文,那么conntrack都认为是NEW状态吗?比如SYN, SYNACK, FIN, RST,这些明显有不同的语义,实践经验FIN, RST这些直接放成INVALID是没毛病的,到这里还是来复现下并看看代码的逻辑吧。
测试
iptables规则设置
用如下脚本来设置下iptables规则:
#!/bin/sh
iptables -P INPUT ACCEPT
iptables -F
iptables -X
iptables -Z
# 在日志里记录INPUT chain里过来的每个报文的状态
iptables -A INPUT -p tcp -m state --state NEW -j LOG --log-prefix "[iptables] INPUT NEW: "
iptables -A INPUT -p TCP -m state --state ESTABLISHED -j LOG --log-prefix "[iptables] INPUT ESTABLISHED: "
iptables -A INPUT -p TCP -m state --state RELATED -j LOG --log-prefix "[iptables] INPUT RELATED: "
iptables -A INPUT -p TCP -m state --state INVALID -j LOG --log-prefix "[iptables] INPUT INVALID: "
iptables -A INPUT -i lo -j ACCEPT
iptables -A INPUT -p tcp --dport 22 -j ACCEPT
iptables -A INPUT -p tcp --dport 21 -j ACCEPT
iptables -A INPUT -p tcp --dport 80 -j ACCEPT
iptables -A INPUT -p tcp --dport 443 -j ACCEPT
iptables -A INPUT -p tcp --dport 8088 -m state --state NEW -j ACCEPT
iptables -A INPUT -p icmp --icmp-type 8 -j ACCEPT
iptables -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
# 在日志里记录OUTPUT chain里过来的每个报文的状态
iptables -A OUTPUT -p tcp -m state --state NEW -j LOG --log-prefix "[iptables] OUTPUT NEW: "
iptables -A OUTPUT -p TCP -m state --state ESTABLISHED -j LOG --log-prefix "[iptables] OUTPUT ESTABLISHED: "
iptables -A OUTPUT -p TCP -m state --state RELATED -j LOG --log-prefix "[iptables] OUTPUT RELATED: "
iptables -A OUTPUT -p TCP -m state --state INVALID -j LOG --log-prefix "[iptables] OUTPUT INVALID: "
# iptables -A OUTPUT -m state --state INVALID -j DROP
iptables -P INPUT DROP
iptables -P OUTPUT ACCEPT
iptables -P FORWARD DROP
service iptables save
systemctl restart iptables.service利用iptables -nvL看规则如下:
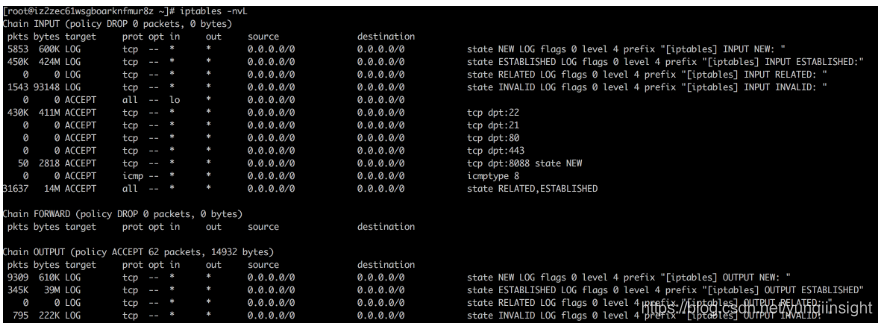
注:测试时并没有显示地drop掉OUTPUT chain的INVALID状态的报文,也能复现类似的问题,因为在INPUT方向对端回的FIN同样也是INVALID状态的报文,会被INPUT chain默认的DROP规则丢弃掉。
将conntrack tcp timeout设置得短点:sysctl -w net.netfilter.nf_conntrack_tcp_timeout_established=20
利用nc测试,第一次建立连接完idle 20秒,conntrack中ESTABLISHED的表项消失 (可以利用iptstate或者conntrack tool查看):
直接kill进程发FIN, 对于conntrack的状态是INVALID。
接续发数据,对于conntrack的状态是NEW。
代码逻辑
nf_conntrack模块的报文可以从nf_conntrack_in函数看起,对于conntrack表项中不存在的新表项的逻辑:
nf_conntrack_in @net/netfilter/nf_conntrack_core.c|--> resolve_normal_ct @net/netfilter/nf_conntrack_core.c // 利用__nf_conntrack_find_get查找对应的连接跟踪表项,没找到则init新的conntrack表项|--> init_conntrack @net/netfilter/nf_conntrack_core.c // 初始化conntrack表项|--> tcp_new @net/netfilter/nf_conntrack_proto_tcp.c // 到TCP协议的处理逻辑,called when a new connection for this protocol found。在这里根据tcp_conntracks数组决定状态。reslove_normal_ct
在reslove_normal_ct中, 逻辑是先找利用__nf_conntrack_find_get查找对应的连接跟踪表项。在本文的场景中conntrack表项已经超时,所以不存在。代码逻辑进入init_conntrack,来初始化一个表项。
/* look for tuple match */hash = hash_conntrack_raw(&tuple, zone);h = __nf_conntrack_find_get(net, zone, &tuple, hash);if (!h) {h = init_conntrack(net, tmpl, &tuple, l3proto, l4proto,skb, dataoff, hash);if (!h)return NULL;if (IS_ERR(h))return (void *)h;}init_conntrack
在init_conntrack的如下逻辑里会利用nf_conntrack_l4proto的new来读取和校验一个对于conntrack模块是新连接的报文内容。如果返回值是false,则进入如下if statement来结束这个初始化conntrack表项的过程。在案例的场景确实会在这里就结束conntrack表项的初始化。
对于这个“新”的TCP报文的验证,也就是我们关心的对于一个conntrack表项不存在(超时)的TCP连接,会在new(tcp_new)的逻辑中判断。
if (!l4proto->new(ct, skb, dataoff, timeouts)) {nf_conntrack_free(ct);pr_debug("init conntrack: can't track with proto module\n");return NULL;}tcp_new
在tcp_new的如下逻辑中,关键的逻辑是对new_state的赋值,当new_state >= TCP_CONNTRACK_MAX时,会返回false退出。对于FIN包,new_state的赋值会是TCP_CONNTRACK_MAX (sIV),具体逻辑看如下分析。
/* Called when a new connection for this protocol found. */
static bool tcp_new(struct nf_conn *ct, const struct sk_buff *skb,unsigned int dataoff, unsigned int *timeouts)
{enum tcp_conntrack new_state;const struct tcphdr *th;struct tcphdr _tcph;struct net *net = nf_ct_net(ct);struct nf_tcp_net *tn = tcp_pernet(net);const struct ip_ct_tcp_state *sender = &ct->proto.tcp.seen[0];const struct ip_ct_tcp_state *receiver = &ct->proto.tcp.seen[1];th = skb_header_pointer(skb, dataoff, sizeof(_tcph), &_tcph);BUG_ON(th == NULL);/* Don't need lock here: this conntrack not in circulation yet */// 这里get_conntrack_index拿到的是TCP_FIN_SET,是枚举类型tcp_bit_set的值new_state = tcp_conntracks[0][get_conntrack_index(th)][TCP_CONNTRACK_NONE];/* Invalid: delete conntrack */if (new_state >= TCP_CONNTRACK_MAX) {pr_debug("nf_ct_tcp: invalid new deleting.\n");return false;}
......
}tcp_conntracks是一个三维数组,作为TCP状态转换表(TCP state transition table)存在。
- tcp_conntrack数组最外层的下标是0,表示ORIGINAL,是发出包的一端。
- 在案例的场景中,中间层的外标由get_conntrack_index决定。get_conntrack_index(th)根据报文中的FIN flag拿到枚举类型tcp_bit_set (定义如下)的值TCP_FIN_SET。枚举类型tcp_bit_set和下面将要介绍的tcp_conntracks数组的中间下标一一对应。
/* What TCP flags are set from RST/SYN/FIN/ACK. */
enum tcp_bit_set {
TCP_SYN_SET,
TCP_SYNACK_SET,
TCP_FIN_SET,
TCP_ACK_SET,
TCP_RST_SET,
TCP_NON- 里层的下标为TCP为TCP_CONNTRACK_NONE,是枚举类型tcp_conntrack中的0。
tcp_conntracks数组
数组的内容如下,在源码里有非常多的注释说明状态的转换,这里先略去,具体可参考数组定义。这里只关注在conntrack表项超时后,收到第一个报文时对报文状态的定义。
static const u8 tcp_conntracks[2][6][TCP_CONNTRACK_MAX] = {{
/* ORIGINAL */
/*syn*/ { sSS, sSS, sIG, sIG, sIG, sIG, sIG, sSS, sSS, sS2 },
/*synack*/ { sIV, sIV, sSR, sIV, sIV, sIV, sIV, sIV, sIV, sSR },
/*fin*/ { sIV, sIV, sFW, sFW, sLA, sLA, sLA, sTW, sCL, sIV },
/*ack*/ { sES, sIV, sES, sES, sCW, sCW, sTW, sTW, sCL, sIV },
/*rst*/ { sIV, sCL, sCL, sCL, sCL, sCL, sCL, sCL, sCL, sCL },
/*none*/ { sIV, sIV, sIV, sIV, sIV, sIV, sIV, sIV, sIV, sIV }},{
/* REPLY */
/*syn*/ { sIV, sS2, sIV, sIV, sIV, sIV, sIV, sIV, sIV, sS2 },
/*synack*/ { sIV, sSR, sIG, sIG, sIG, sIG, sIG, sIG, sIG, sSR },
/*fin*/ { sIV, sIV, sFW, sFW, sLA, sLA, sLA, sTW, sCL, sIV },
/*ack*/ { sIV, sIG, sSR, sES, sCW, sCW, sTW, sTW, sCL, sIG },
/*rst*/ { sIV, sCL, sCL, sCL, sCL, sCL, sCL, sCL, sCL, sCL },
/*none*/ { sIV, sIV, sIV, sIV, sIV, sIV, sIV, sIV, sIV, sIV }}
};根据上面的分析,对conntrack模块的新报文来说,取值如下:
tcp_conntracks[0][get_conntrack_index(th)][TCP_CONNTRACK_NONE] =>tcp_conntracks[0][get_conntrack_index(th)][0]- 当报文带有FIN时:tcp_conntracks0[0] = tcp_conntracks0[0] => INVALID状态 // 本案例
- 当报文带有RESET时:tcp_conntracks0[0] = tcp_conntracks0[0] => INVALID状态
- 当报文带有SYNACK时:tcp_conntracks0[0] = tcp_conntracks0[0] => INVALID状态
- 当报文带有SYN和ACK时, 对于conntrack模块是NEW状态
总结
当操作系统使用iptables时(或者在其他场景中使用netfilter提供的hook点),大部分关于nf_conntrack_tcp_timeout_established的优化都是建议把默认的5天调小,以避免conntrack表满的情况,这个是推荐的最佳实践。但是从另一个角度,到底设置到多小比较好?除非你能明确地知道你的iptables规则对每一个报文的过滤行为,否则不建议设置到几百秒及以下级别。
当把nf_conntrack_tcp_timeout_established设置得很短时,对于超时的conntrack表项,关闭连接时的FIN或者RST(linger enable)很容易被iptables规则丢弃,在本文案例中iptables的filter表规则中的每个chain都显示地丢弃了INVALID状态报文,即使不显示丢弃,通常设置规则的时候INPUT chain的默认规则也不会允许INVALID状态的包进入,采取丢弃行为。最终的影响就是让用户态的socket停在诸如FIN_WAIT_1和LAST_ACK等不太常见的状态,造成TCP连接不能正常关闭。
原文链接
本文为云栖社区原创内容,未经允许不得转载。



















