阿里云售后技术团队的同学,每天都在处理各式各样千奇百怪的线上问题。常见的有,网络连接失败,服务器宕机,性能不达标,请求响应慢等。但如果要评选,什么问题看起来微不足道事实上却足以让人绞尽脑汁,我相信答案肯定是“删不掉”的问题。比如文件删不掉,进程结束不掉,驱动卸载不了等。
这样的问题就像冰山,影藏在它们背后的复杂逻辑,往往超过我们的预想。
背景
今天我们讨论的这个问题,跟K8S集群的命名空间有关。命名空间是K8S集群资源的“收纳”机制。我们可以把相关的资源,“收纳”到同一个命名空间里,以避免不相关资源之间不必要的影响。
命名空间本身也是一种资源。通过集群API Server入口,我们可以新建命名空间,而对于不再使用的命名空间,我们需要清理掉。命名空间的Controller会通过API Server,监视集群中命名空间的变化,然后根据变化来执行预先定义的动作。

有时候,我们会遇到下图中的问题,即命名空间的状态被标记成了“Terminating”,但却没有办法被完全删除。

从集群入口开始
因为删除操作是通过集群API Server来执行的,所以我们要分析API Server的行为。跟大多数集群组件类似,API Server提供了不同级别的日志输出。为了理解API Server的行为,我们将日志级别调整到最高级。然后,通过创建删除tobedeletedb这个命名空间来重现问题。
但可惜的是,API Server并没有输出太多和这个问题有关的日志。
相关的日志,可以分为两部分。一部分是命名空间被删除的记录,记录显示客户端工具是kubectl,以及发起操作的源IP地址是192.168.0.41,这符合预期;另外一部分是Kube Controller Manager在重复的获取这个命名空间的信息。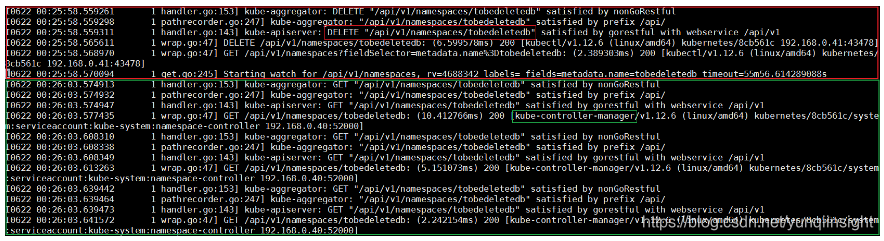
Kube Controller Manager实现了集群中大多数的Controller,它在重复获取tobedeletedb的信息,基本上可以判断,是命名空间的Controller在获取这个命名空间的信息。
Controller在做什么?
和上一节类似,我们通过开启Kube Controller Manager最高级别日志,来研究这个组件的行为。在Kube Controller Manager的日志里,可以看到命名空间的Controller在不断地尝试一个失败了的操作,就是清理tobedeletedb这个命名空间里“收纳”的资源。
怎么样删除“收纳盒”里的资源
这里我们需要理解一点,就是命名空间作为资源的“收纳盒”,其实是逻辑意义上的概念。它并不像现实中的收纳工具,可以把小的物件收纳其中。命名空间的“收纳”实际上是一种映射关系。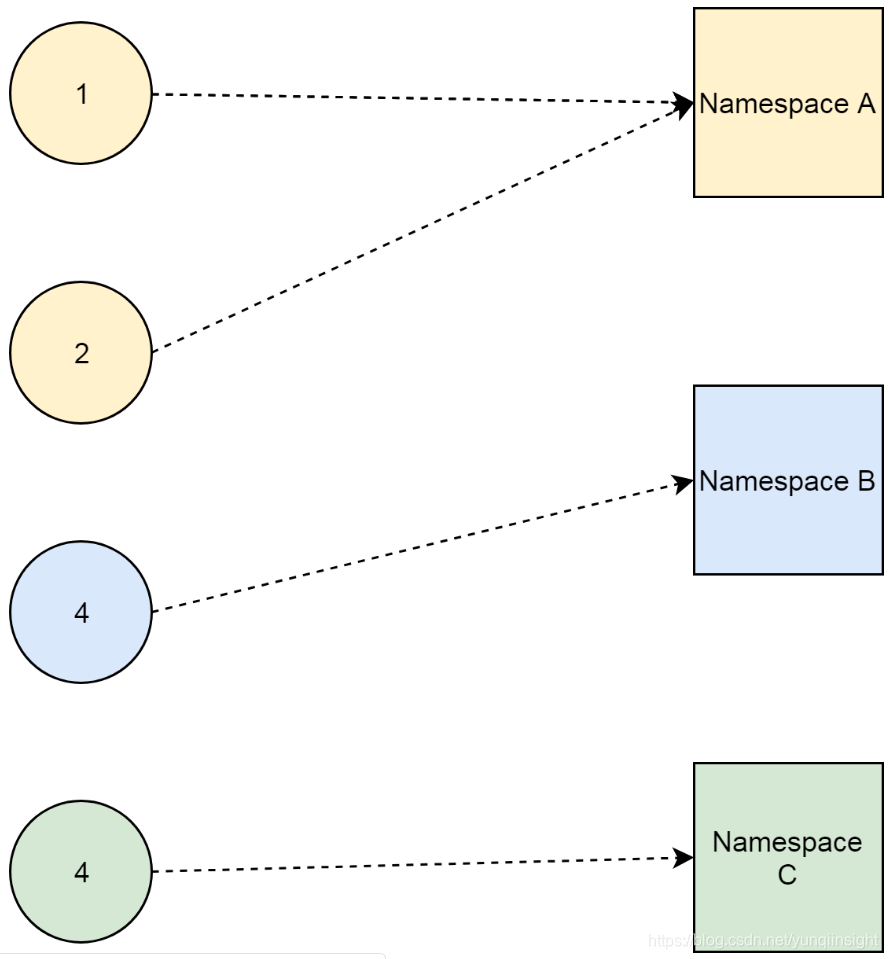
这一点之所以重要,是因为它直接决定了,删除命名空间内部资源的方法。如果是物理意义上的“收纳”,那我们只需要删除“收纳盒”,里边的资源就一并被删除了。而对于逻辑意义上的关系,我们则需要罗列所有资源,并删除那些指向需要删除的命名空间的资源。
API、Group、Version
怎么样罗列集群中的所有资源呢,这个问题需要从集群API的组织方式说起。K8S集群的API不是铁板一块的,它是用分组和版本来组织的。这样做的好处显而易见,就是不同分组的API可以独立的迭代,互不影响。常见的分组如apps,它有v1,v1beta1和v1beta2这三个版本。完整的分组/版本列表,可以使用kubectl api-versions命令看到。
我们创建的每一个资源,都必然属于某一个API分组/版本。以下边Ingress为例,我们指定Ingress资源的分组/版本为networking.k8s.io/v1beta1。
kind: Ingress
metadata:name: test-ingress
spec:rules:- http:paths:- path: /testpathbackend:serviceName: testservicePort: 80用一个简单的示意图来总结API分组和版本。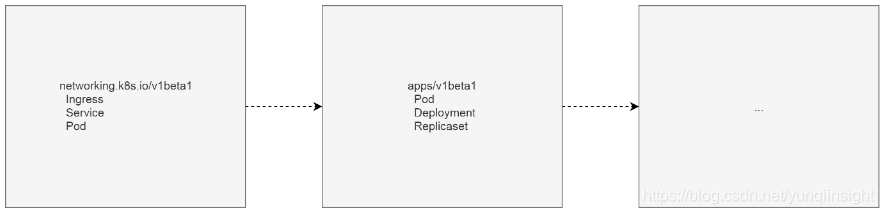
实际上,集群有很多API分组/版本,每个API分组/版本支持特定的资源类型。我们通过yaml编排资源时,需要指定资源类型kind,以及API分组/版本apiVersion。而要列出资源,我们需要获取API分组/版本的列表。
Controller为什么不能删除命名空间里的资源
理解了API分组/版本的概念之后,再回头看Kube Controller Manager的日志,就会豁然开朗。显然命名空间的Controller在尝试获取API分组/版本列表,当遇到metrics.k8s.io/v1beta1的时候,查询失败了。并且查询失败的原因是“the server is currently unable to handle the request”。
再次回到集群入口
在上一节中,我们发现Kube Controller Manager在获取metrics.k8s.io/v1beta1这个API分组/版本的时候失败了。而这个查询请求,显然是发给API Server的。所以我们回到API Server日志,分析metrics.k8s.io/v1beta1相关的记录。在相同的时间点,我们看到API Server也报了同样的错误“the server is currently unable to handle the request”。
显然这里有一个矛盾,就是API Server明显在正常工作,为什么在获取metrics.k8s.io/v1beta1这个API分组版本的时候,会返回Server不可用呢?为了回答这个问题,我们需要理解一下API Server的“外挂”机制。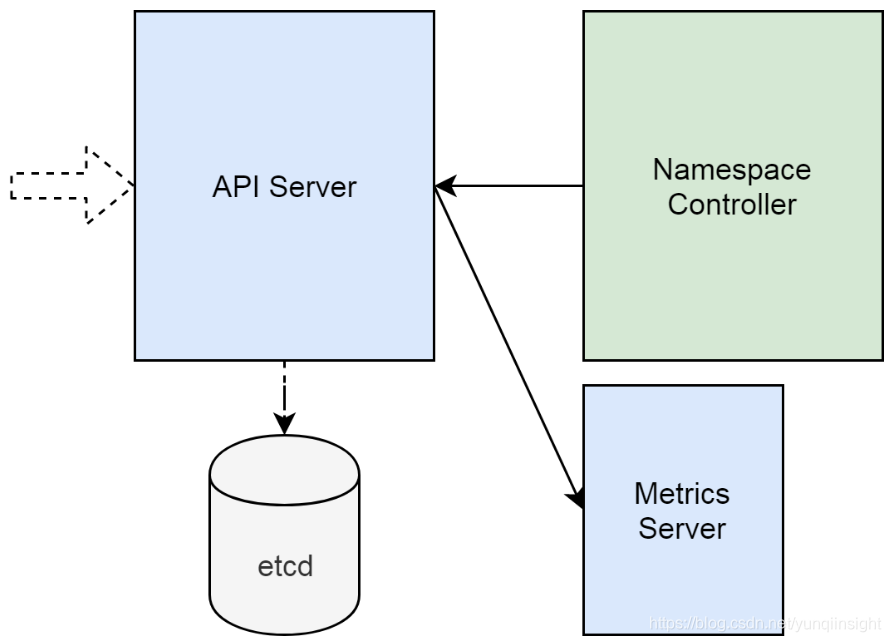
集群API Server有扩展自己的机制,开发者可以利用这个机制,来实现API Server的“外挂”。这个“外挂”的主要功能,就是实现新的API分组/版本。API Server作为代理,会把相应的API调用,转发给自己的“外挂”。
以Metrics Server为例,它实现了metrics.k8s.io/v1beta1这个API分组/版本。所有针对这个分组/版本的调用,都会被转发到Metrics Server。如下图,Metrics Server的实现,主要用到一个服务和一个pod。
而上图中最后的apiservice,则是把“外挂”和API Server联系起来的机制。下图可以看到这个apiservice详细定义。它包括API分组/版本,以及实现了Metrics Server的服务名。有了这些信息,API Server就能把针对metrics.k8s.io/v1beta1的调用,转发给Metrics Server。
节点与Pod之间的通信
经过简单的测试,我们发现,这个问题实际上是API server和metrics server pod之间的通信问题。在阿里云K8S集群环境里,API Server使用的是主机网络,即ECS的网络,而Metrics Server使用的是Pod网络。这两者之间的通信,依赖于VPC路由表的转发。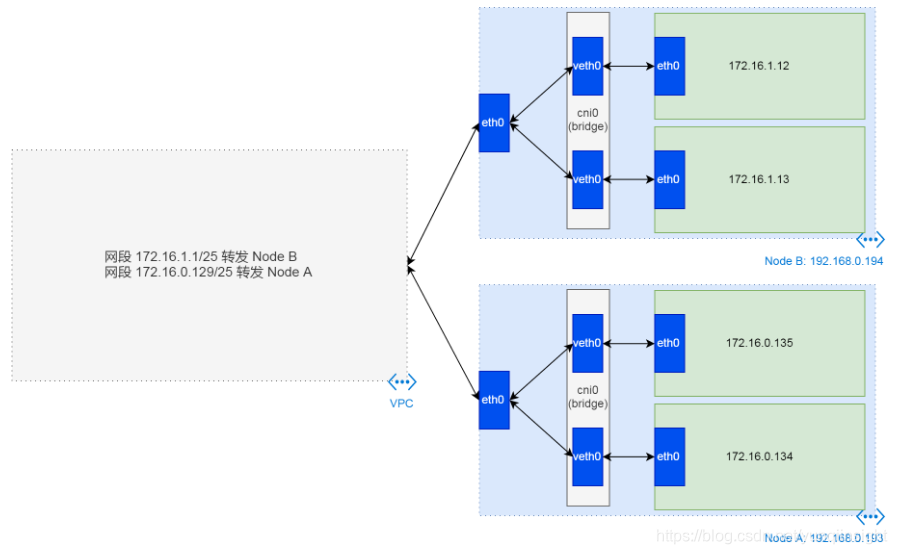
以上图为例,如果API Server运行在Node A上,那它的IP地址就是192.168.0.193。假设Metrics Server的IP是172.16.1.12,那么从API Server到Metrics Server的网络连接,必须要通过VPC路由表第二条路由规则的转发。
检查集群VPC路由表,发现指向Metrics Server所在节点的路由表项缺失,所以API server和Metrics Server之间的通信出了问题。
Route Controller为什么不工作?
为了维持集群VPC路由表项的正确性,阿里云在Cloud Controller Manager内部实现了Route Controller。这个Controller在时刻监听着集群节点状态,以及VPC路由表状态。当发现路由表项缺失的时候,它会自动把缺失的路由表项填写回去。
现在的情况,显然和预期不一致,Route Controller显然没有正常工作。这个可以通过查看Cloud Controller Manager日志来确认。在日志中,我们发现,Route Controller在使用集群VPC id去查找VPC实例的时候,没有办法获取到这个实例的信息。
但是集群还在,ECS还在,所以VPC不可能不在了。这一点我们可以通过VPC id在VPC控制台确认。那下边的问题,就是为什么Cloud Controller Manager没有办法获取到这个VPC的信息呢?
集群节点访问云资源
Cloud Controller Manager获取VPC信息,是通过阿里云开放API来实现的。这基本上等于,从云上一台ECS内部,去获取一个VPC实例的信息,而这需要ECS有足够的权限。目前的常规做法是,给ECS服务器授予RAM角色,同时给对应的RAM角色绑定相应的角色授权。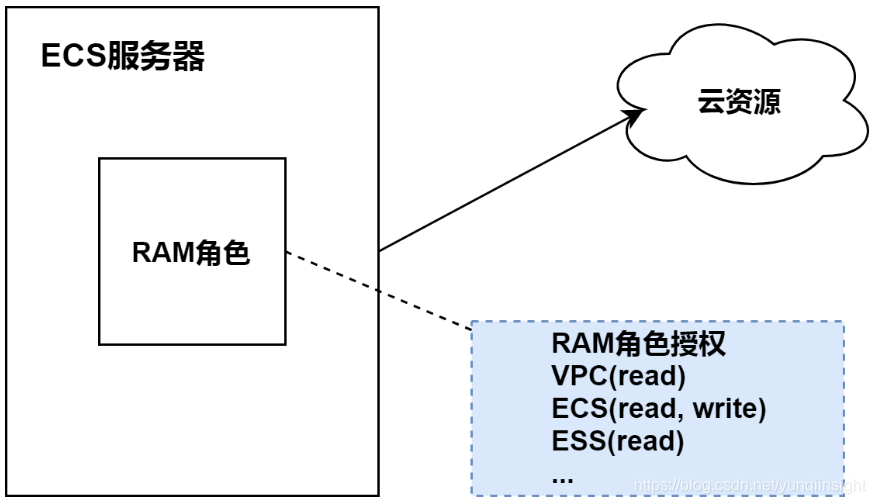
如果集群组件,以其所在节点的身份,不能获取云资源的信息,那基本上有两种可能性。一是ECS没有绑定正确的RAM角色;二是RAM角色绑定的RAM角色授权没有定义正确的授权规则。检查节点的RAM角色,以及RAM角色所管理的授权,我们发现,针对vpc的授权策略被改掉了。

当我们把Effect修改成Allow之后,没多久,所有的Terminating状态的namespace全部都消失了。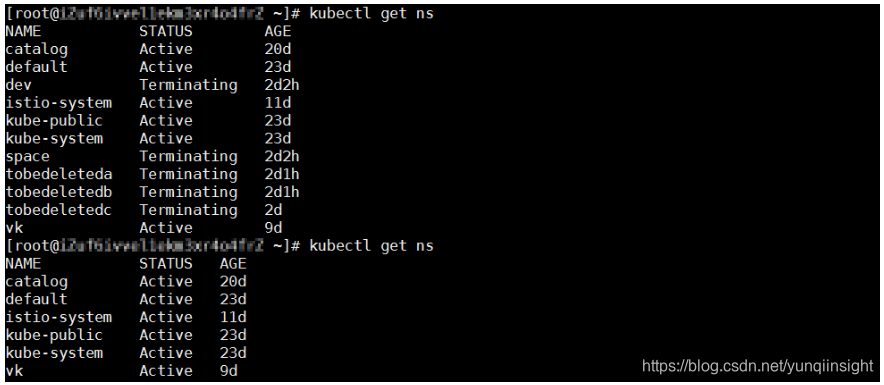
问题大图
总体来说,这个问题与K8S集群的6个组件有关系,分别是API Server及其扩展Metrics Server,Namespace Controller和Route Controller,以及VPC路由表和RAM角色授权。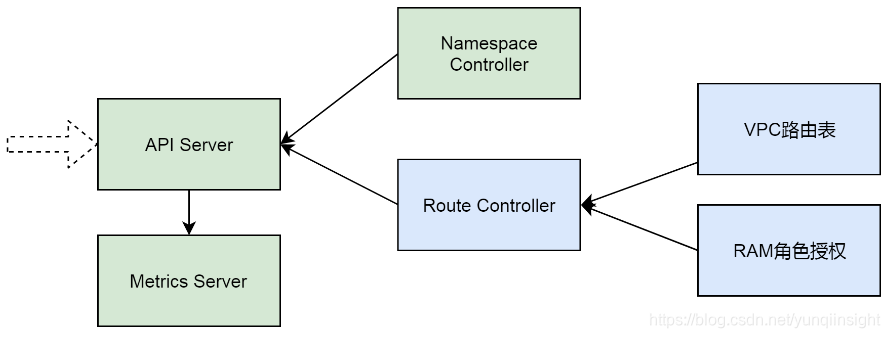
通过分析前三个组件的行为,我们定位到,集群网络问题导致了API Server无法连接到Metrics Server;通过排查后三个组件,我们发现导致问题的根本原因是VPC路由表被删除且RAM角色授权策略被改动。
后记
K8S集群命名空间删除不掉的问题,是线上比较常见的一个问题。这个问题看起来无关痛痒,但实际上不仅复杂,而且意味着集群重要功能的缺失。这篇文章全面分析了一个这样的问题,其中的排查方法和原理,希望对大家排查类似问题有一定的帮助。
原文链接
本文为云栖社区原创内容,未经允许不得转载。



















