
阿里妹导读:曾被 paper 中各种各样的 Attentioin 搞得晕晕乎乎,尽管零零散散地整理过一些关于Attention 的笔记,重点和线索依然比较凌乱。今天,阿里巴巴工程师楠易,将 Attentioin 的知识系统性地梳理、回顾、总结,不求深刻,但求浅显,希望能帮助对 Attention 有疑惑的同学。
前言
Attention 自2015年被提出后,在 NLP 领域,图像领域遍地开花。Attention 赋予模型区分辨别能力,从纷繁的信息中找到应当 focus 的重点。2017年 self attention 的出现,使得 NLP 领域对词句 representation 能力有了很大的提升,整个 NLP 领域开启了全面拥抱 transformer 的年代。
本文会主要从2个方面来介绍 Attention。
初识 Attention,主要扒一扒 Attention 的历史,然后给出一个通用的框架来回答一个终极问题:what is Attention?
细数 Attention,以上文给出的通用框架视角来审视所有的 Attention,在这个章节,你会和各种各样的 Attention 相遇、相识、相恋(global/local、soft/hard、Bagdanau attention、 Luong attention、 self-attention、 multi-head attention , 以及它们的别名),了解它们之间的联系与差异。
初识Attention
History
Attention 的发展可以粗暴地分为两个阶段。
2015-2017年,自从 attention 提出后,基本就成为 NLP 模型的标配,各种各样的花式 attention 铺天盖地。不仅在 Machine Translation,在 Text summarization,Text Comprehend(Q&A), Text Classification 也广泛应用。奠定基础的几篇文章如下:
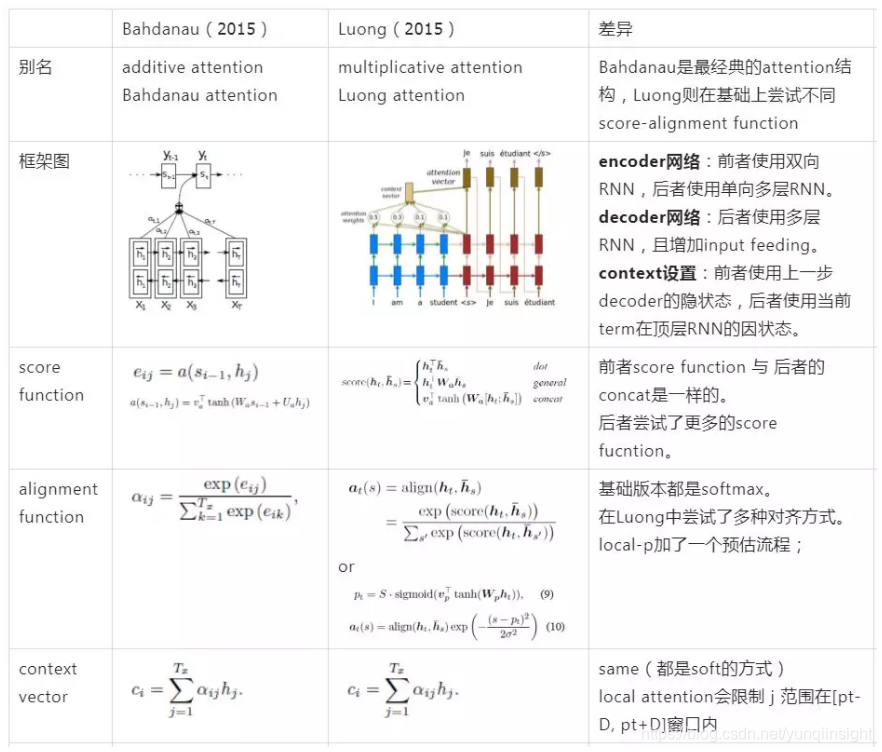
2015年 ICLR 《Neural machine translation by jointly learning to align and translate》首次提出 attention(基本上算是公认的首次提出),文章提出了最经典的 Attention 结构(additive attention 或者 又叫 bahdanau attention)用于机器翻译,并形象直观地展示了 attention 带来源语目标语的对齐效果,解释深度模型到底学到了什么,人类表示服气。
2015年 EMNLP 《Effective Approaches to Attention-based Neural Machine Translation》在基础 attention 上开始研究一些变化操作,尝试不同的 score-function,不同的 alignment-function。文章中使用的 Attention(multiplicative attention 或者 又叫 Luong attention)结构也被广泛应用。
2015年 ICML 《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》是 attention(提出hard/soft attention的概念)在 image caption 上的应用,故事圆满,符合直觉,人类再次表示很服气。
在上面几篇奠基之作之上,2016和2017年 attention 开枝散叶,无往不利。Hiearchical Attention,Attention over Attention,multi-step Attention……这些或叫得上名的或叫不上名。
2017年-至今是属于 transformer 的时代。基于 transformer 强大的表示学习能力,NLP 领域爆发了新一轮的活力,BERT、GPT 领跑各项 NLP 任务效果。奠基之作无疑是:
2017年 NIPS《Attention is all you need》提出 transformer 的结构(涉及 self-attention,multi-head attention)。基于 transformer 的网络可全部替代sequence-aligned 的循环网络,实现 RNN 不能实现的并行化,并且使得长距离的语义依赖与表达更加准确(据说2019年的 transformer-xl《Transformer-XL:Attentive Lanuage Models Beyond a fixed-length context》通过片段级循环机制结合相对位置编码策略可以捕获更长的依赖关系)。
what is Attention ?
直奔主题,终极叩问 "what is attention?" 。这个章节,尝试以统一的抽象框架来定义 attention。如同先编写一个抽象类,后续章节涉及所有的 attention 都继承于这个抽象类。这里我写了两个抽象类,一个叫 alignment-based,一个叫 memroy-based。(两名字我给起的,保留最终解释权)。
alignment-based
如下图所示的 model setting,输入 c(context,有的论文写s),y(input,有的地方也写作 h),输出 z。图中,英文表达原汁原味,细品一下。

我们细拆 Attention Model,以经典的 Bahdanau attention 为例,看看抽象出来的三部曲:
- score function :度量环境向量与当前输入向量的相似性;找到当前环境下,应该 focus 哪些输入信息;
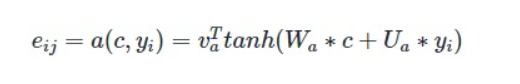
- alignment function :计算 attention weight,通常都使用 softmax 进行归一化;
- generate context vector function :根据 attention weight,得到输出向量;
下图,更加直观地展示这三个接口的位置:

自此之后,要认清一个 attention 的详情,只需要搞清楚这三个部分,所有的变换都是在3个位置进行调整,当然变化最丰富的是 score function。在后一个章节会详细对比不同种类的 attention 在这三个维度上的变换。
memory-based
另一种视角是 QKV 模型,假设输入为 q,Memory 中以(k,v)形式存储需要的上下文。感觉在 Q&A 任务中,这种设置比较合理,transformer 是采用的这种建模方式。k 是 question,v 是 answer,q 是新来的 question,看看历史 memory 中 q 和哪个 k 更相似,然后依葫芦画瓢,根据相似 k 对应的 v,合成当前 question 的 answer。
在这种建模方式下,也分为三步:
- address memory (score function):
,在 memory 中找相似;
- normalize(alignment function) :
- read content (gen context vector function) :
其实还是没有逃出上文三部曲的框架。只是将 input 分裂成了 kvpair。
后文都会以统一的三部曲建模方式(score function,alignment function,generate context vector function)来分析所有 attention。
Attention in Detail
在上文,我们 high-level 地了解了 attention 三部曲的建模方式,接下来要把所有Attention 拉出来排排坐。
Framework
如下图,通常听到的一些 attention,他们的差异其实主要体现在 score-function 层面,其次是体现在 generate context vector function 的层面。我们分别来看看,这些 attention 之间的差异与联系。

generate context vector function
hard / soft attention 是在文章《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》提出的概念,最直观的一种理解是,hard attention 是一个随机采样,采样集合是输入向量的集合,采样的概率分布是alignment function 产出的 attention weight。因此,hard attention 的输出是某一个特定的输入向量。soft attention 是一个带权求和的过程,求和集合是输入向量的集合,对应权重是 alignment function 产出的 attention weight。hard / soft attention 中,soft attention 是更常用的(后文提及的所有 attention 都在这个范畴),因为它可导,可直接嵌入到模型中进行训练,hard attention 文中 suggests a Monte Carlo based sampling approximation of gradient。
alignment function
在 soft attention 中,又划分了 global/local attention(In this paper :《Effective Approaches to Attention-based Neural Machine Translation》)。
直观理解就是带权求和的集合不一样,global attention 是所有输入向量作为加权集合,使用 softmax 作为 alignment function,local 是部分输入向量才能进入这个池子。为什么用 local,背后逻辑是要减小噪音,进一步缩小重点关注区域。接下来的问题就是,怎么确定这个 local 范围?文中提了两个方案 local-m 和 local-p。local-m 基于的假设生硬简单,就直接 pass了。local-p 有一个预估操作,预计当前时刻应该关注输入序列(总长度为S)的什么位置 pt(引入了两个参数向量,vp,wp),然后在 alignment function 中做了一点儿调整,在 softmax 算出来的attention wieght 的基础上,加了一个以 pt 为中心的高斯分布来调整 alignment 的结果。
作者最后阐述 local-p + general(score-function 参考上图中multiplicative attention 中的 general 版本)的方式效果是最好的。但从global/local 视角的分类来看,更常用的依然还是 global attention,因为复杂化的local attention 带来的效果增益感觉并不大。

score-function
如何生成输出向量,有上面提及的那些变换。接下来是变化更加丰富的 score function。最为常用的 score function 有上文图中的那几种(基本全乎了吧)。其实本质就是度量两个向量的相似度。如果两个向量在同一个空间,那么可以使用 dot 点乘方式(或者 scaled dot product,scaled 背后的原因是为了减小数值,softmax 的梯度大一些,学得更快一些),简单好使。如果不在同一个空间,需要一些变换(在一个空间也可以变换),additive 对输入分别进行线性变换后然后相加,multiplicative 是直接通过矩阵乘法来变换(你是不是也曾迷惑过为什么attention 要叫做 additive 和 multiplicative attention?)。
后文我们将介绍几个具有代表性的 attention,通过具体的 attention example 来进一步理解。以及一些花样 attention,看大家都怎样变着法儿用 attention。
Bahdanau Attention & Luong Attention
在对比之中,认知更清晰,一图表达所有。这两个 Attention 就是整个 Attention 的奠基之作。Tensorflow 中实现了这两种 Attention 的 API。
Self Attention & Multi-head Attention
why self attention ?
有很多文章写 self-attention,但是写 why self-attention 的并不多。所以打算多花点笔墨来写 why。
RNN 的长距离依赖比较 tricky:RNN 很强大(可以作为 encoder 对长度任意的序列进行特征抽取,基于特征抽取的能力可以胜任分类任务,另一方面可以作为Generators 学习 Language Model),其实核心就是长距离依赖(gate architectures - 线性操作让信息可以保持并流动,并选择性地让信息通过),可以对长度任意的序列进行表达,但是这种方式还是比较 tricky。并且这种序列建模方式,无法对具有层次结构的信息进行很好的表达。
RNN 由于递归的本质,导致无法并行。
CNN 在 NLP 中扮演了 n-gram 的 detector 角色,在层内可以并行。CNN works well,基于的假设是局部信息相互依赖。CNN 具有 Hierarchical Receptive Field,使得任意任意两个位置之间的长度距离是对数级别的。
所以有没有一种方法,能够做到既能又能还能?
相对于 CNN,要 constant path length 不要 logarithmic path length , 要 variable-sized perceptive field,不要固定 size 的 perceptive field;
相对于 RNN,考虑长距离依赖,还要可以并行!
这就是 self attention。下图可以看到 self-attention 和 convolution 有点儿神似,它摒弃了 CNN 的局部假设,想要寻找长距离的关联依赖。看下图就可以理解 self-attention 的这几个特点:
- constant path length & variable-sized perceptive field :任意两个位置(特指远距离)的关联不再需要通过 Hierarchical perceptive field 的方式,它的 perceptive field 是整个句子,所以任意两个位置建立关联是常数时间内的。
- parallelize : 没有了递归的限制,就像 CNN 一样可以在每一层内实现并行。

self-attention 借鉴 CNN中 multi-kernel 的思想,进一步进化成为 Multi-Head attention。每一个不同的 head 使用不同的线性变换,学习不同的 relationship。
what is self-attention?
已经有很多很好的文章介绍 transformer 和 self-attention,以及内部细节。有兴趣的同学可以看下参考资料【11】,介绍得比较详细,下图是完整版本的 multi-head attention 的示例图(引用自上述链接中)。这是基于上文中提及了 QKV 的 memory-based 的建模方式。需要说明的几个点:
- QKV 都是对输入 x 的线性映射。
- score-function 使用 scaled-dot product。
- multihead 的方式将多个 head 的输出 z,进行 concat 后,通过线性变换得到最后的输出 z。

transformer 框架中 self-attention 本身是一个很大的创新,另一个有意思的是 three ways of attention 的设计。attention weight 一列以英译中,encoder 输入machine learning,decoder 输入机器学习。
- Encoder self-attention:Encoder 阶段捕获当前 word 和其他输入词的关联;
- MaskedDecoder self-attention :Decoder 阶段捕获当前 word 与已经看到的解码词之间的关联,从矩阵上直观来看就是一个带有 mask 的三角矩阵;
- Encoder-Decoder Attention:就是将 Decoder 和 Encoder 输入建立联系,和之前那些普通 Attention 一样;

在 transformer 中除了上诉提及的东西,还有 positional encoding,residuals 这些小而美的东西。在复杂度方面在原文中也与 RNN-CNN 进行了对比。
花样 Attention
下面简要介绍几种花样的 attention:
RNN 对序列建模,但是缺乏层次信息。而语言本身是具有层次结构,短语组成句子,句子组成篇章。因此研究者十分希望把语言中的这些层次结构在模型中得以体现,Hierarchical 的方式就出现了。《Hierarchical Attention Networks for Document Classification》,从 word attention 到 sentence attention,如下图一。
在匹配或者检索任务中(如Q&A,IR),要衡量 query,doc 相似度,这时候attention 的方法中,query 和 doc 就互为对方的 cotext,query 对 doc 算一次attention,doc对query 算一次 attention,《Attention-over-Attention Neural Networks for Reading Comprehension 》,如下图二。
上文介绍 why self-attention 时已经提及了 RNN 和 CNN 的一些优点和问题,几乎和 transformer 同时,facebook 发表了《Convolutional Sequence to Sequence Learning》,同样地想借用 CNN 的优点来补足 RNN 不能并行的弱点,用 CNN 结合 attention 来对序列进行建模,如下图三。
随着 transformer 的爆红,围绕 transformer 的花边,出现了 weighted-transformer 《Weighted Transformer Network For Machine Translation》。今年出现了 transformer-xl 《Transformer-xl :attentive language models beyond a fixed-length context》,如下图四, 想达到对任意长度的输入进行特征抽取,而不是 transformer 切成 segment 的定长输入。

总结
Why Attention Works?
从上面的建模,我们可以大致感受到 Attention 的思路简单,四个字“带权求和”就可以高度概括,大道至简。做个不太恰当的类比,人类学习一门新语言基本经历四个阶段:死记硬背(通过阅读背诵学习语法练习语感)->提纲挈领(简单对话靠听懂句子中的关键词汇准确理解核心意思)->融会贯通(复杂对话懂得上下文指代、语言背后的联系,具备了举一反三的学习能力)->登峰造极(沉浸地大量练习)。
这也如同attention的发展脉络,RNN 时代是死记硬背的时期,attention 的模型学会了提纲挈领,进化到 transformer,融汇贯通,具备优秀的表达学习能力,再到 GPT、BERT,通过多任务大规模学习积累实战经验,战斗力爆棚。
要回答为什么 attention 这么优秀?是因为它让模型开窍了,懂得了提纲挈领,学会了融会贯通。
那又是如何开窍的?是因为它懂得了"context is everything"。
1.在语言模型中:语言模型(language model)是整个 NLP 领域的基础,语言模型的精准程度基本上直接掌握所有 NLP 任务效果的命脉。而 context 又掌握着语言模型的命脉,语义不孤立,在特定 context 下展示特定的一面,模型如果可以学习到这些知识,就可以达到见人说人话,见鬼说鬼话的理想状态。
在语义表达上能把 context 用好的都是成功的典范(参考:word2vec 靠学习 word 及其 context 发家,ELMo-deep contextualized word representations, BERT 从句子中抠掉一个词用上下文去预测这个词,transformer-xl 较 transformer 使用更全面的 context 信息,XLNet 一大重要贡献也是研究如何使用上下文信息来训练语言模型)。
2.在其他领域中:Attention 是把 context 用好的典范之一。Attention 背后本质的思想就是:在不同的 context 下,focusing 不同的信息。这本来就是一个普适的准则。所以 Attention 可以用到所有类似需求的地方,不仅仅是 NLP,图像,就看你对 context 如何定义。
在很多的应用场景,attention-layer 肩负起了部分 feature-selection,featue-representation 的责任。举个例子,transfer learning with Domain-aware attention network for item recommemdation in e-commerce 中提及:不同场景的用户的行为有不同的偏好(场景是 context,价格,品牌是不同的信息),天猫用户对品牌看重,亲淘用户 focus 价格,可以通过 attention-layer 学习到不同 context 下,用户的 Attention 在哪里。在 ctr 预估中,Deep Interest Network for Click-Through Rate Prediction 出发点类似。在推荐场景中,文章 Feature Aware Multi-Head Attention 在手淘猜你喜欢排序模型中的应用 。这些都是attention 在业务场景落地的参考。
原文链接
本文为云栖社区原创内容,未经允许不得转载。



















)