
阿里妹导读:数据安全性被提到了前所未有的高度,数据保护的话题越来越成为敏感。因为,业务的中断时间对用户造成的影响愈来愈大。阿里技术专家凡钧从数据安全的形势与发展,面临的挑战,问题的定义,传统的解决方案,当前云厂商的解决方案,去阐述什么是连续数据保护并提出了弹性的可验证的连续数据保护方案(Elastic Assured Continuous Data Protection)。
一、摘要
相比于传统的连续数据保护等的解决方案,需要在Guest OS 层面或者在专有的存储层面,进行写时数据变化日志的获取,或多或少对生产机的存储性能有很大的影响,一旦上云,必将加重客户的计算成本及存储成本。即使是混合的架构部署,在网络的带宽,实施的复杂性层面也很难与云端实施相比,很难满足传统企业客户的更低的RPO(Recovery Point Objective)及RTO(Recovery Time Objective)的诉求。虽然,连续数据保护的产品定位与快照,复制(Replication)的功能有所重合,但CDP的定位更加宽泛,注重数据的保护,恢复,更高效的业务连续性,不仅仅局限于快照的实现及数据的搬移。
新的Pangu2.0的块存储的全新的架构为实现云端连续性数据保护提供了契机,特别是日志结构块设备(Log Structure Block Device),其中包括:全新的数据写入方式,日志存储方式及快照方式等都极大地方便了连续数据保护的的实现。相信随着企业上云的加速,在兼顾存储性能的同时,将会满足传统高级企业用户的低RTO及低RPO的数据保护的紧迫需求。但数据备份及数据备份在考虑可操作的同时,数据可恢复的操作性在很大程度上决定了数据保护的有效性。
二、数据保护的挑战
在当今,数据安全性被提到了前所未有的高度,数据保护的话题越来越成为敏感。因为,业务的中断时间对用户造成的影响愈来愈大。在2017年,病毒,勒索软件,如WannCry, Peta 及 Locky及频繁的删库误操作,甚至有些对用户的备份软件进行直接攻击,使得云端用户对数据安全及数据保护的期望愈来愈高。

数据变得越来越重要: 数据=资产 数据=资源
2017年1月,“Gitlab误删库事件”引起业界对信息安全和重大风险的敏感神经。值得关注的是,在Gitlab恢复的过程中,发现只有db1.staging的数据库可以用于恢复,而其它的5种备份机制都不可用。而db1.staging 是6小时前的数据,而且传输速率有限,导致恢复进程缓慢,Gitlab 最终丢掉了差不多6个小时的数据。
因此,如何降低数据丢失的风险,减小数据保护的窗口,降低用户的损失,提供高效的恢复机制,是用户的迫切需要。另外,从一个侧面可以看出,低RTO及可验证的恢复性,对数据保护的重要性;数据的可恢复性相对于存储成本在此刻是及其重要的救命稻草。
三、连续性数据保护的定义
存储网络协会(SNIA)对于连续性数据保护的定义为:连续数据保护是一套方法,它可以捕获或跟踪数据的变化,并将其独立保存放在生产数据以外,以确保数据可以恢复到过去的任意时间点。连续数据保护,可以基于块、文件或应用实现,可以为恢复提供足够的恢复粒度,实现几乎无限多的恢复时间点。
全球最具权威的IT研究与顾问咨询公司(Gartner)的定义为:连续数据保护是一种恢复方法,它连续或者近似连续的捕获或跟踪数据文件或者数据块的变化,同时以日志的形式进行保存。这种能力提供了更加细粒度的实时点,以减少数据的的丢失,并且使得任意的恢复点成为可能。一些CDP解决方案可以被配置去抓取连续的数据改变(真的CDP)或者以一定的时间抓取数据改变(准CDP)。
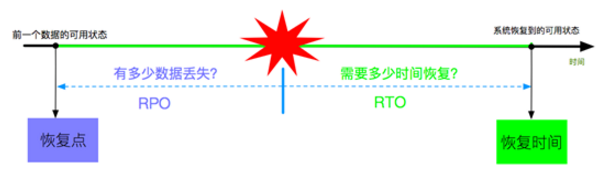
为了更好的表达CDP的状态,需要引入两个概念:RPO和RTO。
- RPO(Recovery Point Objective):恢复点目标,指出现灾难的时候会丢失多长时间的数据,即是备份间隔。
- RTO(Recovery Time Objective):恢复时间目标,指出现灾难的时候多长时间可以让业务继续运作,即恢复时间。
- 真正的CDP概念被定义为RPO=0,RTO趋近于0,才能被成为CDP。当RPO不为0时称之为:Near CDP(准CDP)。
四、连续性数据保护的特点
传统的数据保护解决方案专注在对数据的周期性备份上,因此一直伴随有备份窗口、数据一致性以及对生产系统的影响等问题。而CDP为用户提供了新的数据保护手段,系统管理者无须关注数据的备份过程(因为CDP系统会不断监测关键数据的变化,从而不断地自动实现数据的保护),而是仅仅当灾难发生后,简单地选择需要恢复到的数据备份时间点即可实现数据的快速恢复。
连续数据保护和传统的灾难恢复技术相比,连续数据保护具有如下明显的特点:
1、首先可以大大提高数据恢复时间点目标(RPO)。备份技术实现的数据保护间隔一般为24小时(每天备份一次),因此用户会面临数据丢失多达24小时的风险,采用快照技术,可以将数据的丢失风险降低到几个小时之内,而CDP能够实现的数据丢失量可以降低到几秒(当然,不同的CDP产品和解决方案提供的时间精度也不尽相同)。实际上,在传统数据保护技术中采用的是对“单时间点(SinglePoint-In-Time)”的数据拷贝进行管理的模式,而连续数据保护保护可以实现对“任意时间点(Any Point-In-Time)”的数据保护。
2、虽然复制(Replication)技术可以通过与生产数据的同步获得数据的最新状态,但其无法规避由人为的逻辑错误或病毒攻击所造成的数据丢失。当生产数据由于以上原因导致数据遭到破坏时(例如数据被误删除),复制技术会将遭到破坏的数据状态同步到后备数据存储系统,使后备数据也受到破坏。CDP系统可以使数据状态恢复到数据遭到破坏之前的任意一个时间点,也就可以消除前者具有的风险。
3、由于恢复时间和恢复对象的粒度更细,所以连续数据保护保护的数据恢复也更加灵活。目前的部分产品和解决方案允许最终用户(而不仅仅是系统管理员)直接对数据进行恢复操作,这在很大程度上方便了使用者。

五、实现方式
连续数据保护实现的关键技术是对数据变化的记录和保存,以便实现任意时间点的快速恢复。一般来讲,有三种实现方式:
- 基准参考数据模式。建立参考数据拷贝,根据生产数据变化记录数据差异日志,根据日志差异按需恢复数据。基准参考数据模式原理简单,实现起来比较容易,但由于数据恢复时需要从最原始的参考数据开始,逐步进行数据恢复,因此恢复时间比较长,尤其是恢复时间点越靠近当前的时间,恢复所需要的时间就越长。
- 复制参考数据模式。生产数据和参考数据副本实时同步,在同步的同时记录回退日志或事件,基于回退日志(Undo Log)差异实现数据按需恢复。复制参考数据模式和基准参考数据模式在实现原理上恰好相反。复制参考数据模式在数据恢复时,恢复的时间点越靠近当前,所需要的恢复时间越短。但在数据的保存过程中,需要同时进行数据和日志记录的同步,需要较多的系统资源。
- 合成参考数据模式。合成参考数据模式是以上两种模式的折衷,较好地实现了以上两种模式的妥协,因此可以得到较好的资源占用和恢复时间效果。但需要复杂的软件管理和数据处理功能,实现起来比较复杂。 连续数据保护技术或解决方案的实现有多种模式。
不同的传统厂商建立了不同的连续数据保护保护模型,参考SNIA的存储共享模型, 可以将实现连续数据保护的产品或解决方案分为基于应用、基于文件和基于数据块的连续数据保护保护。本文主要从数据块层面讲CDP的实现。基于块的CDP功能直接运行在物理的存储设备或逻辑的卷管理器上,甚至也可以运行在数据传输层上。当数据块写入生产数据的存储设备时,CDP系统可以捕获数据的拷贝并将其存放在另外一个存储设备中。 基于数据块的数据保护又有基于主机层、基于传输层和基于存储层三类实现方式。
六、传统数据保护产品的CDP
下面以FalconStorCDP、VeeamCDP及EMC RecoverPoint这3个厂商,从不同背景进行分析,具有一定的代表性:飞康是传统的连续数据保护产品的代表。EMC传统的存储厂商,收购以前的RecoverPoint打造自己的数据保护套件, 方案建立在自己的存储上,提供物理机到虚拟机的保护方案。Veeam 是虚拟机保护的后起之秀,主打虚拟化平台上,VMWARE 及 HYPERV的数据保护,扩展到云端,目前的方案依赖于VMWare的VAIO 虚拟化数据获取框架。

EMCRecoverPoint/SE 是针对 EMC CLARiiON 系列阵列的全面解决方案,而 EMC RecoverPoint则是针对整个数据中心的全面解决方案。两种产品都提供了使用连续数据保护 (CDP)的同步本地复制,以及具有任意时间点恢复功能的同步和异步连续远程复制 (CRR)。在RecoverPoint 应用装置上同时运行CDP和CRR实现本地和远程(CLR) 数据保护,使您能够用单个解决方案同时在本地和远程保护相同数据。 飞康CDP解决方案整合了数据备份、系统恢复、灾难恢复、本地及异地容灾等多项功能。飞康CDP是基于磁盘的备份与容灾一体化解决方案,实现文件/数据库/操作系统的实时备份与瞬间恢复;实现了验证、演练的本地/异地容灾功能整合。
**七、主要云厂商的数据保护方式
**
AWS仅提供原生的快照功能及帮助客户上云的手段,数据备份等功能依赖于传统的数据保护厂商;Azure提供基于虚拟机的基本的备份及恢复方式,没有提供CDP等高级功能。

八、可验证的弹性的连续数据保护CDP
根据Gartner的描述的弹性的云备份引擎,其中规定的了成功弹性备份的几个特征:
- 弹性的云备份引擎需要快速的RTO,这就要求备份引擎和数据恢复在一个数据中心。
- 弹性的云备份引擎需要有全备份,没有过大的WAN数据传输,将备份与生产机职责分开。
- 并且要确保数据的可恢复性。
连续数据保护CDP本质上作为一种高级的数据保护方案,由云厂商进行,具有传统备份所不具有的弹性。传统厂商为了上云,必然需要将数据经过WAN传输到云端,必然耗费CPU资源,必然耗费IO资源。为了躲避资源的耗费,可能采取定时开启的任务方式,连基本的弹性的备份都保证不了,更谈不上CDP。可验证性,强调了CDP方案的可靠性,可操作性。为了保证应用程序的数据的跨卷一致性,需要卷之间建立一致性组(Consistency Group)及应用程序的一致性(Application Consistency)。

九、结论
数据保护不是亡羊补牢,需要未雨绸缪。随着企业上云的快速增长,传统企业对云端数据保护的诉求更加突出;随着数据重要性的日益提高,用户对数据丢失的敏感程度前所未有,从而使得云端数据保护与用户需求之间的矛盾更加凸显。传统的基于块存储的连续数据保护因为大多依赖于特定的存储设备,并不具有云端实现所具有的弹性,并不适应云端分布式环境的复杂性。连续数据保护作为传统或者混合云数据保护的重要补充,定会以新的解决方案的出现而被企业用户所重视。全新的Pangu2.0的块存储的架构为实现云端连续性数据保护提供了契机,随着企业上云的加速,在兼顾存储性能的同时,将会满足传统高级企业用户的低RTO及低RPO的数据保护的紧迫需求。后续文章将会着重阐述基于基准参考数据模型的云端连续数据保护,该方案基于Pangu2.0的Block Storage实现连续性数据保护,着重描述连续数据保护的秒级数据恢复机制。
原文链接
本文为云栖社区原创内容,未经允许不得转载。



















