文章目录
- 你们项目中哪些地方有使用到 MQ ?
- 为什么需要使用 MQ?
- MQ 如何避免消息堆积的问题?
- MQ 宕机了消息是否会丢失呢?
- 生产者投递消息,MQ 宕机了如何处理?
- MQ 如何保证消息顺序一致性问题?
- 为什么保证了消息顺序一致性有可能降低我们消费者消费的速率?解决方案
- MQ 如何保证消息幂等问题?
你们项目中哪些地方有使用到 MQ ?
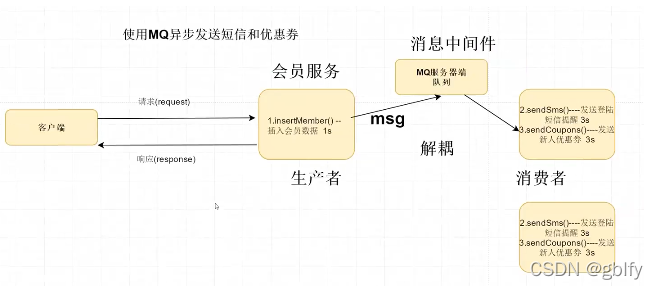
- 使用 MQ 异步发送优惠券;
- 使用 MQ 异步发送通知(短信、邮件);
- 使用 MQ 异步扣库存
- 使用MQ异步审核贷款金额
- 使用MQ异步第三方接口(中国公民信息网)

为什么需要使用 MQ?
1.异步处理(多线程和 MQ)
2.实现解耦
3.流量削峰(MQ 可以实现抗高并发)
可以按场景简述,录单流程:用户手机端填写录单流程,服务端接收到请求信息后,存储数据库,响应客户录单成功,然后写一条消息到MQ中,具体生成整张保单信息的耗时处理,报单中心模块监听MQ信息进行处理,最后,给客户发送保单成功短信通知。
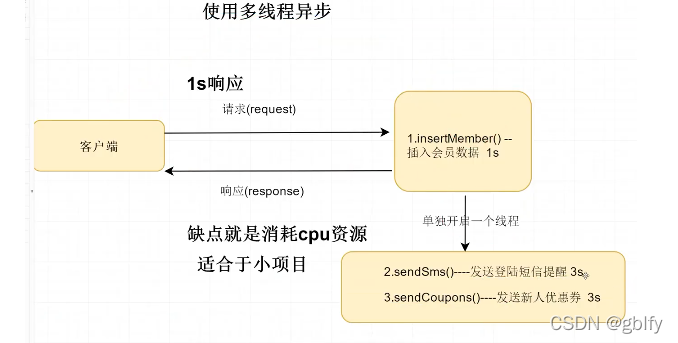
解耦:客户端请求到服务端,用户信息写入落库,主线程响应客户端,另起一个子线程发送MQ系统,耗时操作,让具体的业务系统慢慢处理。当采用多线程时,主线程和子线程都在同一个服务器上,当服务器当即后,一些操作就无法完成;当使用MQ时,具体业务耗时逻辑的操作有另一个服务器负责去完成,二者没有关联,当前这宕机后后者无影响。
流量削峰:
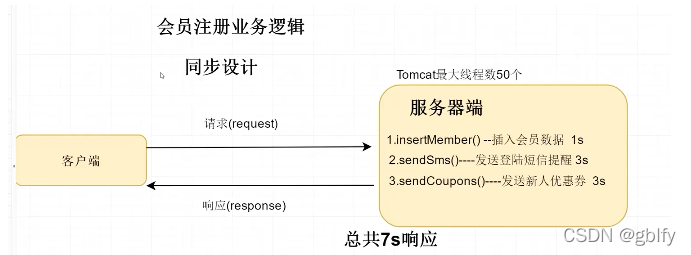
背景:客户端50个请求到服务端tomcat,而tomcat内部线程容量是有限制的,比如说同时处理只能处理50个任务,当其他任务进行来时,会缓存对队列中,当处理的请求越来越多就会阻塞线程或者内存溢出。
处理方案:客户端50个请求到服务端tomcat,而tomcat不做具体耗时逻辑处理,信息落库后,直接响应客户端,然后发一条消息到业务系统的MQ中就可以了。
MQ 与多线程实现异步的区别?
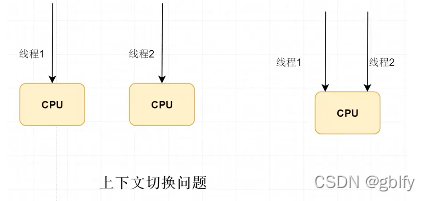
1.多线程方式实现异步可能会消耗到我们的 CPU资源,可能会影响到我们业务线程执行 会发生 CPU竞争的问题,例如:单核多线程,cpu上下文切换,会出现卡顿现象
2.MQ 方式实现异步是完全解耦,适合于大型互联网项目;
3.小的项目可以使用多线程实现异步,大项目建议使用 MQ 实现异步;
MQ 如何避免消息堆积的问题?
1.提高消费者消费的速率;(对我们的消费者实现集群)
2.消费者应该批量形式获取消息 减少网络传输的次数;
说明:同一个组中多个消费者不会重复消费同一条消息。(均摊策略等等)
理解:
1.产生背景: 生产者投递消息的速率与我们消费者消费的速率完全不匹配。
2.生产者投递消息的速率>消费者消费的速率 导致我们消息会堆积在我们 MQ 服务器端中,没有及时的被消费者消费 所以就会产生消息堆积的问题
3.注意的是:
rabbitMQ 消费者我们的消息消费如果成功的话 消息会被立即删除。
kafka 或者 rocketMQ 消息消费如果成功的话,消息是不会立即被删除。
MQ 宕机了消息是否会丢失呢?
不会,因为我们消息会持久化在我们硬盘中。
MQ 如何保证消息不丢失?
1.MQ 服务器端 消息持久化到硬盘
2.生产者 消息确认机制 必须确认消息成功刷盘到硬盘中,才能够人为消息投递成功。
3.消费者 必须确认消息消费成功 。
rabbitMQ 中:才会将该消息删除。
rocketMQ 或者 kafka 中:消息消费后会提交 offse偏移量,消息并不会立即删除。
(消息删除通过日志保留策略配置,过了48小时在进行删除)
生产者投递消息,MQ 宕机了如何处理?
1.生产者投递消息会将 msg 消息内容记录下来,后期如果发生生产者投递消息失败;
2.可以根据该日志记录实现补偿机制;
3.补偿机制(获取到该 msg 日志消息内容实现重试)
MQ 如何保证消息顺序一致性问题?
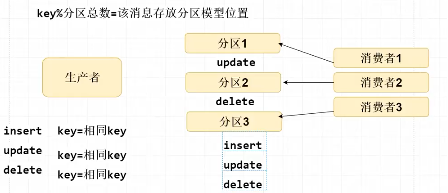
将消息需要投递到同一个 MQ 服务器,同一个分区模型中存放,最终被同一个消费者消费。
核心原理:设定相同的消息 key,根据相同的消息 key 计算 hash 存放在同一个分区中。
产生背景:
MQ服务器集群或者MQ采用分区模型架构存放消息,每个分区对于一个消息者消费消息。
解决消息顺序一致性问题:
核心办法:消息一定要投递到同一个MQ、同一个分区模型,最终被同一个消费者消费。
根据消息key计算%分区模型总数。
理解:
1.大多数的项目是不需要保证 MQ 消息顺序一致性的问题,只有在一些特定的场景可能会需要,比如 MySQL 与 Redis 实现异步同步数据;
2.所有消息需要投递到同一个 MQ 服务器,同一个分区模型中存放,最终被同一个消费者消费,核心原理:设定相同的消息 key,根据相同的消息 key 计算 hash 存放在同一个分区中。
如果保证了消息顺序一致性有可能降低我们消费者消费的速率。
为什么保证了消息顺序一致性有可能降低我们消费者消费的速率?解决方案

MQ 如何保证消息幂等问题?












![ES启动异常:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]](http://pic.xiahunao.cn/ES启动异常:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144])
)






