简介: 本篇将重点介绍Hologres在阿里巴巴网络监控部门成功替换Druid的最佳实践,并助力双11实时网络监控大盘毫秒级响应。
概要:刚刚结束的2020天猫双11中,MaxCompute交互式分析(下称Hologres)+实时计算Flink搭建的云原生实时数仓首次在核心数据场景落地,为大数据平台创下一项新纪录。借此之际,我们将陆续推出云原生实时数仓双11实战系列内容,本篇将重点介绍Hologres在阿里巴巴网络监控部门成功替换Druid的最佳实践,并助力双11实时网络监控大盘毫秒级响应。
3...
2...
1...
00:00:00 。购物车,结算,提交订单,付款
00:01:00...。滴,您的支付宝消费xxx万元。
亿万人同时参与的千亿级项目,破记录的峰值58万笔/秒,剁手党们在整个交易过程中如丝般顺滑,好像参加了一个假的双11,而这一切的背后都离不开阿里巴巴网络能力的强大支持。随着技术的发展,尤其是近年来云和电商业务的愈发兴盛,基础网络也变得越来越庞大和复杂,如何保障这张膨胀网络的稳定性,提供云上用户畅通无阻的购物体验,对网络系统建设者和运维者说更是极大的考验。
理论上来说,故障不可避免,但是如果能够做到快速发现,定位,修复甚至预防故障,缩短故障时长,即可让用户轻微或无感是稳定性追求的终极目标。2015年的微软提出了pingmesh,成为业界事实的解决方案,但是由于天生的某些缺陷性,导致故障发现时间过长。阿里巴巴网络研发事业部从2017年就开始研发站在世界前沿的探测系统AliPing,AliPing实时系统的出现将阿里故障发现带入了秒级响应,数据采集到处理到大盘呈现最快时间延迟在数秒之间,告警+故障定位分钟级,7*24全天候监控着整个阿里的网络状况。
AliPling的核心架构图如下: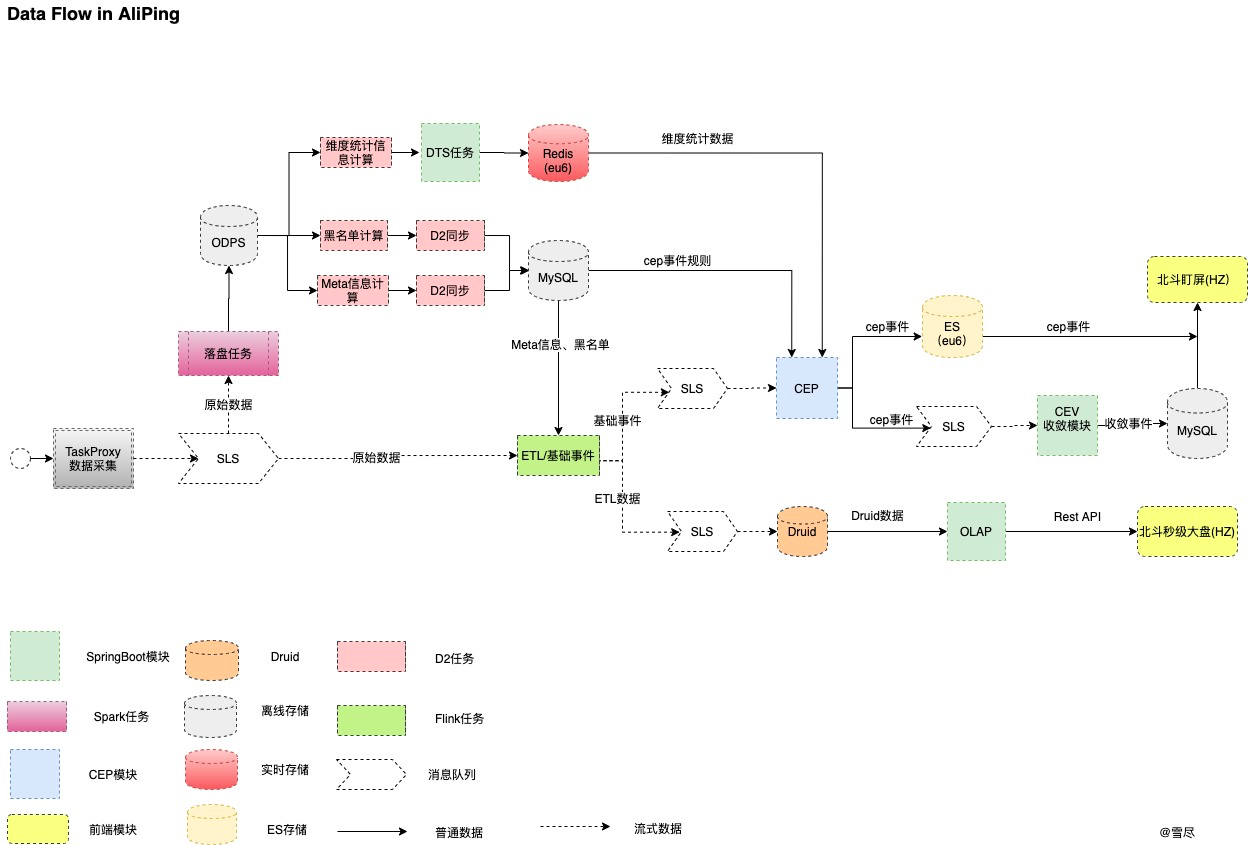
在整个系统中,监控大盘作为故障发现的核心元素,承担着实时呈现网络状况的重任,每一条曲线的起起伏伏,就有可能代表用户的业务在受损, 如何快速实时展示网络状态,并预警/发现网络故障,帮助用户迅速止血,这对于监控团队的监控大盘也是重大的考验。对于监控人员使用的监控大盘来说,困难有多个:
1)数据时效性要求高:需要实时的将处理完的结构化数据(告警,监控)7*24小时的呈现在使用者(GOC, 各个或者监控人员面前,以便及时地发现处理全阿里+蚂蚁的网络故障。
2)数据源复杂:网络数据源众多,业务场景众多,有一分钟数百G的流量监控数据,也有一分钟几十K的IDC网络数据,如何将这些不同种类,不同数据量的业务数据,纳入监控体系发现异常,对整体端到端监控大盘来说也是一种考验。
3)数据指标维度多:对于监控人员来说,需要监控的数据指标维度特别多,可以看作是一个复杂的OLAP查询系统,如何根据自身业务场景从大盘中实时查询所需的业务数据,这对于处理后端数据的OLAP框架也是一个重大挑战。
技术选型
对于监控大盘来说,用户的组合查询条件具有不可预知性,其结构化数据没有办法提前算好,只通过OLAP(联机分析处理)技术,实时对基础数据分析组合,并将结果呈现给用户。Aliping大盘实际就是OLAP技术体现,将不同维度的故障数据(机房、区域、DSW、ASW、PSW、部门、应用等等)通过大盘形式展现在用户面前。
2017年在AliPing系统实施的时候,我们对比了多项OLAP数据库, 其中选择比较有代表性的进行了对比:
1)HIVE
底层基于HDFS存储,将SQL语句分解为MapReduce任务进行查询。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。但是由于底层是HDFS分布式文件系统的限制性,不能进行常见的CUD(对表记录操作)操作,同时Hive需要从已有的数据库或日志进行同步最终入到HDFS文件系统中,当前要做到增量实时同步都相当困难。最重要的是:查询速度慢,无法满足监控大盘秒级相应需求。
2)Kylin
传统OLAP根据数据存储方式的不同分为ROLAP(relational olap)以及MOLAP(multi-dimension olap)。ROLAP 以关系模型的方式存储用作多为分析用的数据,优点在于存储体积小,查询方式灵活,然而缺点也显而易见,每次查询都需要对数据进行聚合计算,为了改善短板,ROLAP使用了列存、并行查询、查询优化、位图索引等技术。Kylin中数据立方的思想就是以空间换时间,通过定义一系列的纬度,对每个纬度的组合进行预先计算并存储。有N个纬度,就会有2的N次种组合。所以最好控制好纬度的数量,因为存储量会随着纬度的增加爆炸式的增长,产生灾难性后果。这个对于庞大的网络数据和不可确定性维度组合,是不可以接受的。
3)ClickHouse
这个是由俄罗斯yandex公司开发的,专门为在线数据分析而设计。根据官方提供的文档来看,ClickHouse 日处理记录数"十亿级"(没测过)。其机制采用列式存储,数据压缩,支持分片,支持索引,并且会将一个计算任务拆分分布在不同分片上并行执行,计算完成后会将结果汇总,支持SQL和联表查询但是支持不够好,支持实时更新,自动多副本同步。总体来说,ClickHouse还算不错,但是由于不够成熟,官方支持度不够,bug也多多,最重要的是集团内也没看到人用,只能放弃。
4)Druid
是一种能对历史和实时数据提供亚秒级别的查询的数据存储系统。Druid 支持低延时的数据摄取,灵活的数据探索分析,高性能的数据聚合,简便的水平扩展。适用于数据量大,可扩展能力要求高的分析型查询系统。其机制将热点和实时数据存储在实时节点(Realtime Node)内存中,将历史数据存储在历史节点(history node)的硬盘中,实时+伪实时的结构,保证查询基本都在毫秒级。高速摄入,快速查询正是满足了我们的需求,同时还有通用计算引擎团队的有力支持,在早期我们选择了druid作为了我们监控大盘的OLAP支持系统。
新OLAP网络监控系统
随着业务的复杂化,业务进一步增多,Druid使用过程中也暴露出一系列问题:
1)数据量摄入的瓶颈, 集团上云,流量的引入,使我们数据量激增,数据写入出现了数次大故障
2)由于业务复杂多变,我们需要增加维度数据,Druid增加相对来说过程比较复杂
3)Druid的查询方式不友好,有一套自己的查询语言,对于SQL支持太差,浪费大量时间学习
4)不支持高并发,对于大促来说简直是灾难。有两年双十一,我们只能上线踢用户保证监控大盘可用。
随着暴露出的问题越来越多,我们也在寻找一款既能替代Druid解决当前问题,又能满足实时OLAP多维分析场景需求的产品。
也是在集团内其他部门沉淀的最佳实践中知道Hologres,并且了解到Hologres支持行存模式下的高并发点查和列存模式下的实时OLAP多维分析,觉得这一点很贴合我们网络监控系统的要求,于是就抱着试试的心态先去测试体验Hologres。通过全链路的测试和大量的场景数据验证,能满足我们场景需求,于是就决定上线Hologres至正式生产中。
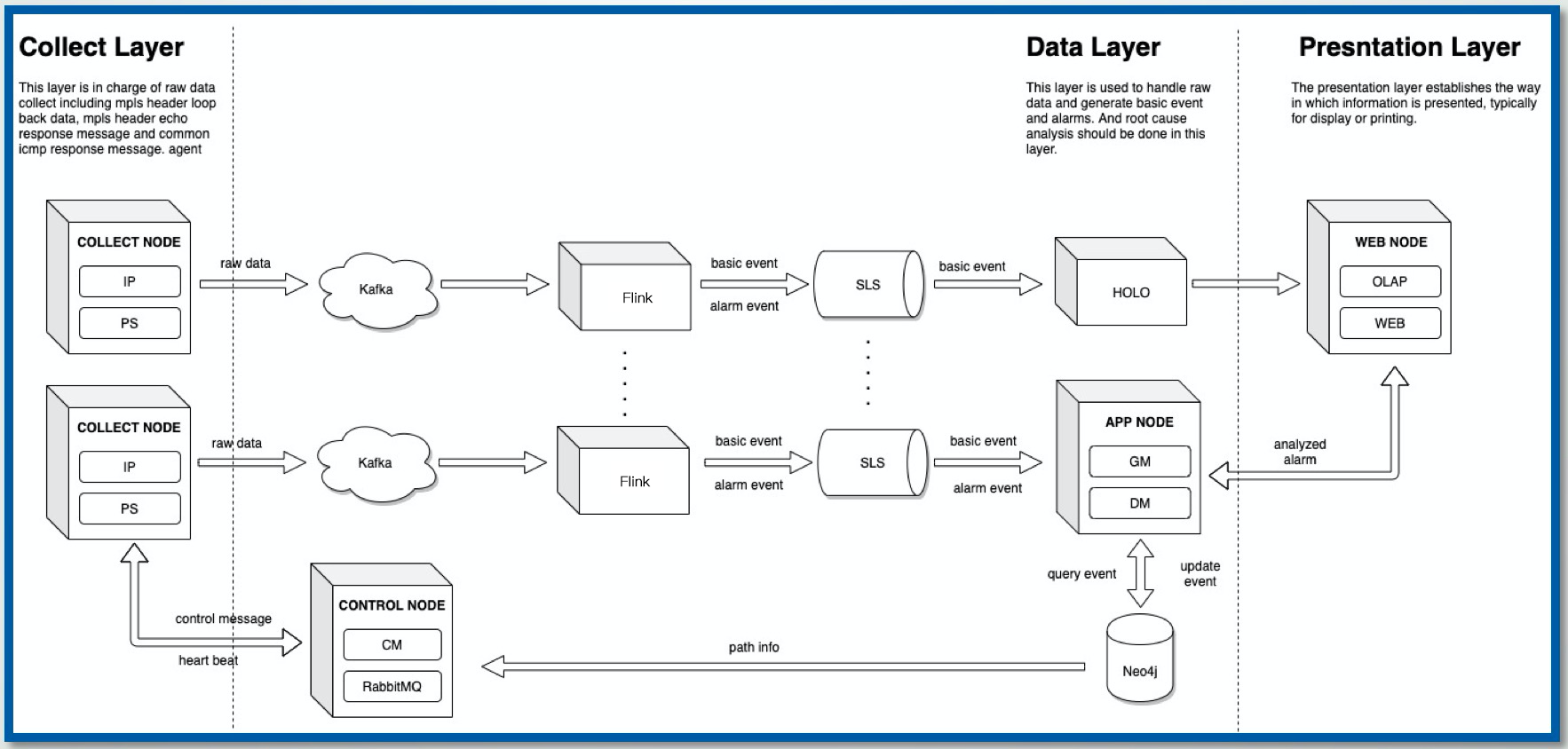
改造后的新OLAP监控系统如下图所示,整体的数据流程大致如下:
- Kafka实时采集网络相关的监控指标数据,并写入Flink中轻度汇总加工
- Flink将初步加工完成的基础粒度的实时数据实时写入Hologres中,由Hologres提供统一的存储
- Hologres直接实时对接监控大屏,大屏实时展示多种监控指标的变化情况,不符合预期的数据实时报警,相应的业务人员立即排查问题并解决。
业务价值
今年也是Hologres第一年参与AIS网络故障监控的双11作战,作为新秀交出了令我们比较满意的答卷。整体来说对于业务的价值主要表现如下:
1)TB级数据毫秒级响应
对于实时监控来说,时间就是生命线,越快发现故障就能越快止血,如何根据用户输入的复杂组合条件,在TB级数据中,仅仅以秒级甚至是毫秒级的响应筛选出符合要求的数据(OLAP),这对很多系统来说都是很大的挑战,而实战证明,合理的利用Hologres索引功能,并通过资源的合理分配等,在OLAP实时性上完美的满足了监控业务的需要。
2)支持高并发
双11的监控大屏往往需要查询查询历史数据,并根据历史数据做报警预测,以往的系统最多只能支撑不到数十用户的查询(数10天数据),而Hologres能支撑数百用户的大规模并行查询并且依旧没有达到上限,在今年双11的0点时,面对数百倍的平时数据量冲击,监控曲线依旧平滑如旧,毫无滞涩之感。
3)写入性能高
对于之前数十万/秒,数百万/秒的写入能力,Druid的表现不是很好容易出现涌塞现象,而Hologres可以轻松做到,这也就轻松解决了我们的实时写入瓶颈问题。
4)学习成本低
Hologres兼容Postgres,全SQL支持,非常方便新用户上手,无需再花费时间和精力去研究语法。同时Hologres对于BI工具的兼容性很好,无需做改造就能对接监控大屏,节约大量时间。
对每一个天猫双11剁手人来说,每一次的丝滑般购物体验都离不开阿里网络能力的支撑,而监控大盘就是阿里网络状况的眼睛。Hologres作为大盘的核心环节,给大盘持续赋能。但是,作为一个新生儿,HOLO仍然有一些不太成熟的地方,在透明升级、稳定性等环节上依存在提升空间。我们也愿意同Hologres一起成长,期待明年双11 Hologres更优秀的表现。
作者简介:唐傥,隶属网络研发事业部网络,现从事网络稳定性开发研究工作,前北邮研究生导师,拥有数个网络和算法相关专利。
原文链接
本文为阿里云原创内容,未经允许不得转载。













」开放下载了!)





