简介: 通过阿里云为流利说量身打造的数据湖解决方案,解决了流利说多种应用的各类数据的统一存储,帮助流利说构建数据规模高达上千亿的“中国人英语语音数据库”。
公司介绍
流利说是世界领先的科技驱动的教育公司,作为智能教育的倡行者,流利说拥有一支业内领先的人工智能团队,经过多年积累,流利说已拥有巨型的“中国人英语语音数据库”,累积实现记录大约 37 亿分钟的对话和 504 亿句录音。
流利说自主研发了领先的英语口语评测、写作打分引擎和深度自适应学习系统,从听、说、读、写多个维度提升用户的英语水平,为用户提供一整套系统性的英语学习解决方案,截止 2020 年 6 月 30 日,累计注册用户达1.856 亿。

业务场景介绍
2013 年流利说推出了第一款产品“英语流利说”,集成了语音识别、打分和自适应学习等多种核心技术。具有上下文情景对话、发音指导课程等丰富内容,并提供人工智能英语老师和游戏化的学习体验,为用户在英语学习中获得更多乐趣。这款有趣又有效的产品很快就占领了当时的市场并获得了用户的高度认可。
但业务快速发展,用户数大幅度增长,平台的用户数量已从当初的百万级,增长至过亿,因此业务的高低峰期数据流量变化、业务复杂度和分析难度都给给 IT 架构带来了巨大的挑战。
业务难点
流利说在面对日常业务需求量以及用户数量飞速增长的情况下,流利说常常需要面对以下几个不同的挑战
不同时段流量变化大,系统需要支持动态请求流量
由于每天不同时段流量变化很大,高峰时段的流量会达到平时的 10 倍,需要系统有足,够的能力支持动态变化的请求流量,因此对于系统弹性拓展能力,就提出了很高的要求。
产品组合和功能丰富,如何为系统平稳运行提供保障
由于产品组合和功能越来越丰富,对于系统的能够提供的性能要求不断增加,大量的付费用户对于访问体验有很高的期望,因此需要高可靠、高稳定的系统,来支撑各款产品平稳地运行。
数据量级与应用系统复杂度增加,系统容量和性能成问题
流利说自研口语评测、写作打分引擎和深度自适应学习系统,每天都需要根据用户学习情况进行分析,根据每个用户不同的学习给予评分和指导建议,随着用户数的增加和应用复杂度的增加,对于大数据系统的容量和性能都有着极高的要求。
阿里云数据湖解决方案
针对流利说日常业务对云服务的弹性、稳定性和大算力的极高要求,阿里云为流利说量身定制了一站式数据湖解决方案。
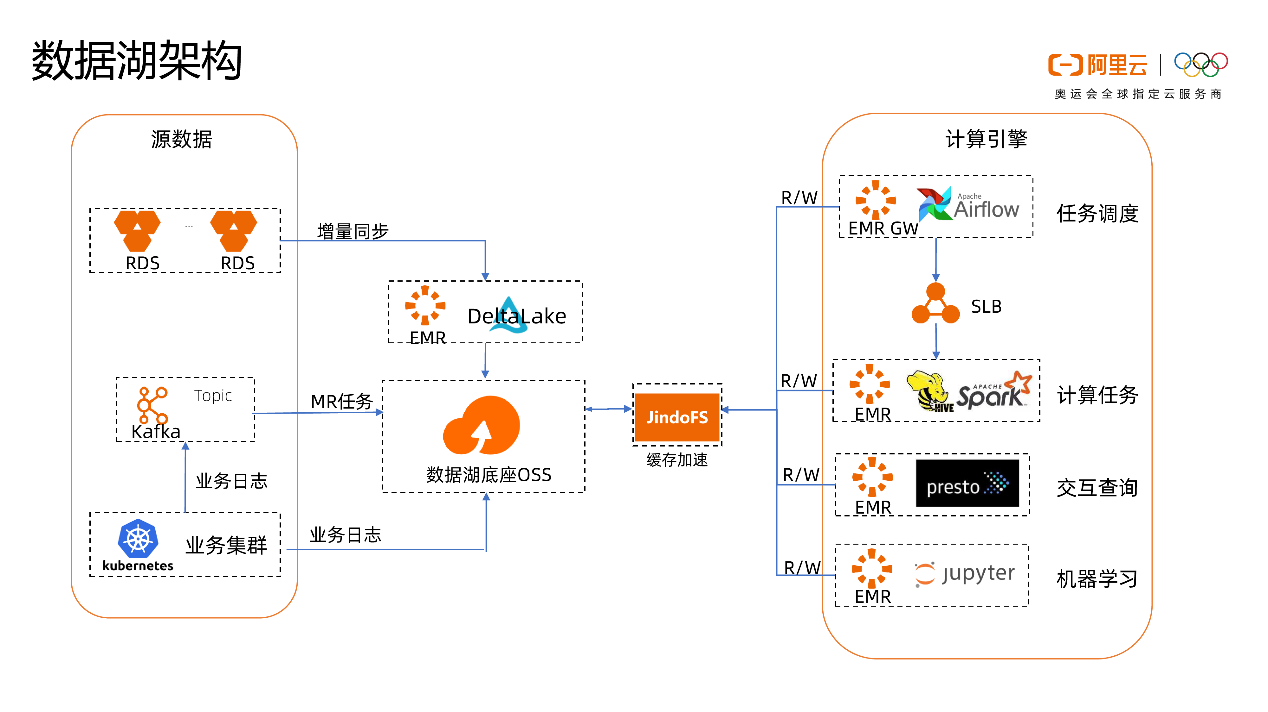
首先,对于数据存储,流利说的大数据平台使用 OSS 作为数据基础层,解决了流利说多类数据的统一存储,同时对接多种计算引擎。而且 OSS 提供了 99.9999999999% (12 个 9)的数据持久性和99.995% 的高可用性,有力的保障流利说的业务稳定和可靠。
在大数据计算方面,通过阿里云 EMR 构建大数据计算集群,提供了包括 Hadoop、Hive、Spark、Presto 在内的多种大数据计算引擎。基于数据湖的存储与计算解耦合架构,所有计算任务的最终数据都是存储到 OSS 持久存储。
同时,阿里云数据湖解决方案对开源生态提供非常友好的支持,客户基于开源框架开发的应用和业务代码,可以不用修改,直接基于阿里云的数据湖解决方案运行。
最后,阿里云 VPC 网络、RAM 等访问控制保障体系,更是为流利说的核心资产“中国人英语语音数据库” 提供了更可控,更细粒度的安全访问控制保护。
达到的效果
通过阿里云为流利说量身打造的数据湖解决方案,解决了流利说多种应用的各类数据的统一存储,帮助流利说构建数据规模高达上千亿的“中国人英语语音数据库”。使用阿里云构建的数据湖,可以充分发挥计算与解耦合架构的优点,结合阿里云 ECS 弹性实例和 K8S,根据实际业务需求,动态扩展、缩减对应计算资源,无须按照业务峰值常驻计算资源,这种灵活的使用模式,能够帮助流利说最大程度地优化成本。
原文链接
本文为阿里云原创内容,未经允许不得转载。


详解 (写给初学者) 结合matlab)
















