简介: 数据库将面临怎样的变革?云原生数据库与数据仓库有哪些独特优势?在日前的 DTCC 2020大会上,阿里巴巴集团副总裁、阿里云数据库产品事业部总裁、ACM杰出科学家李飞飞就《云原生分布式数据库与数据仓库系统点亮数据上云之路》进行了精彩分享。
云计算时代,云原生分布式数据库和数据仓库开始崛起,提供弹性扩展、高可用、分布式等特性。
数据库将面临怎样的变革?云原生数据库与数据仓库有哪些独特优势?在日前的 DTCC 2020大会上,阿里巴巴集团副总裁、阿里云数据库产品事业部总裁、ACM杰出科学家李飞飞就《云原生分布式数据库与数据仓库系统点亮数据上云之路》进行了精彩分享。

阿里巴巴集团副总裁、阿里云数据库产品事业部总裁、ACM杰出科学家李飞飞
以下为小编整理的演讲干货实录:
一、背景与趋势
1.背景
数据库的本质是全链路的对“数据”进行管理,包括了生产—处理—存储—消费等,在当下的数据化时代,数据是所有企业最核心的资产之一,所以数据库的价值一直在不断地提升,不断地在新领域发现新的价值。
2.业界趋势
趋势一:数据生产/处理 正在发生质变
关键词:规模爆炸性增长、生产/处理实时化与智能化、数据加速上云
从Gartner、IDC及各个传统厂商分析中可以得到以下几个结论:
- 数据在爆炸性增长,非结构化数据的占比越来越高;
- 生产/处理实时化与智能化的需求越来越高,并追求离在线一体化;
- 数据库系统、大数据系统、数据管理分析系统等上云的趋势明显,数据加速上云势不可挡。
趋势二:云计算加速数据库系统演进
关键词:商业起步 - 开源 - 分析 - 异构NoSQL - 云原生、一体化分布式、多模、HTAP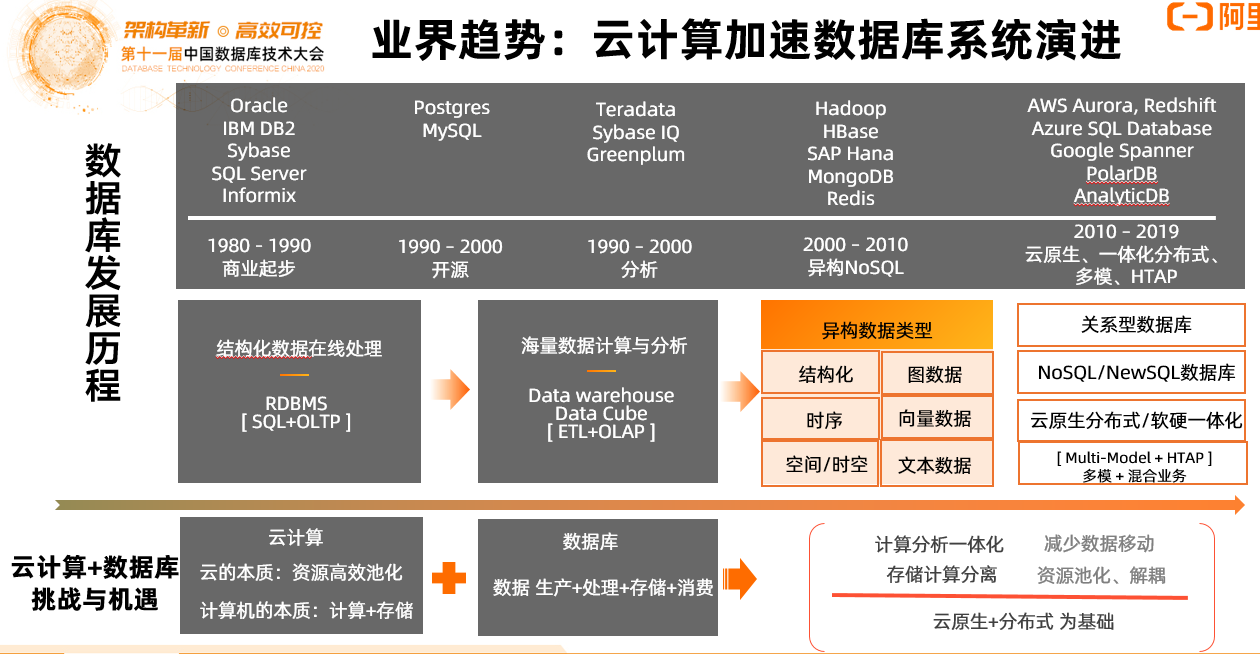
数据库和数据仓库从上世纪八十年代至今的发展缩影
云计算面临两大挑战
挑战一:分布式和ACID的结合
从传统的大数据处理来看,牺牲部分ACID换来的分布式水平拓展虽然非常好,解决了很多场景下的需求,但是应用对ACID的需求一直存在,即使是分布式并行计算的场景当中,应用对ACID的需求也变得越来越强。
挑战二:对资源的使用方式
传统的冯诺依曼架构下计算和存储是紧密耦合的,可将多个服务器通过分布式协议和处理的方式连成一个系统,但是服务器和服务器之间、节点和节点之间,分布式事务的协调、分布式查询的优化,尤其要保证强一致性、强ACID的特性保证的时候,具有非常多的挑战。
全球云数据库市场格局
关键词:资源池化,资源解耦

云的本质是用虚拟化技术将资源池化,并且将资源进行解耦。阿里云是核心云厂商之一,基于云原生技术,打造了云原生数据库产品体系,代表中国的数据库厂商,在Gartner将OPDBMS(事务处理 )与DMSA(管理与分析)合二为一的挑战下,历史性第一次进入Gartner Cloud DBMS云数据库全球领导者象限,市场份额来全球第三,在中国业界领先。
数据库系统架构演进
关键词:单节点、共享状态、分布式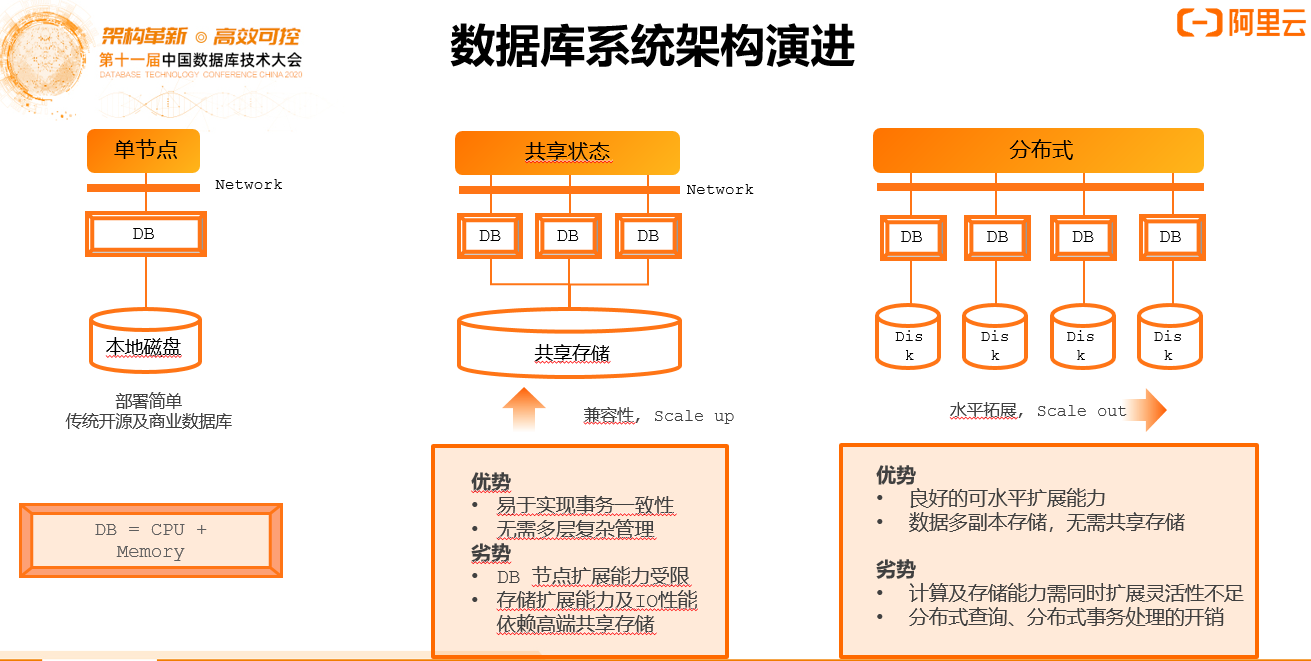
上图是基于存储计算紧耦合,DB代表计算节点,架构当中计算节点的CPU Core和内存还是紧耦合在一起。左边的架构单一,资源紧耦合。右边分布式架构,通过Shared Nothing将多个部分连成一片,理论上具备非常好的水平扩展能力,利用分布式的协议进行分布式的事务处理和查询处理,但是也遇到分布式场景下分布式事务处理、分布式查询等非常多的挑战。
不管是传统的中间件分布分表的形式还是企业级的透明分布式数据库都会面临一个挑战,一旦做了分布式架构,数据只能按照一个逻辑进行Sharding和Partition,业务逻辑和分库逻辑不是完美一致,一定会产生跨库事务和跨sharding处理,每当ACID要求较高的时候,分布式架构会带来较高的系统性能挑战,例如在高隔离级别下当distributed commit占比超过整个事务的5%或者更高以上的话,TPS会有明显的损耗。
完美的Partition Sharing是不存在的,这些是分布式业务需要解决的核心挑战,以及在这个架构需要做到的高一致性保障。
云原生的架构,本质上底下是分布式共享存储,上面是分布式共享计算池,中间来做计算存储解耦,这样可以非常好地提供弹性高可用的能力,做到分布式技术集中式部署,对应用透明。避免传统架构当中的很多挑战,比如分布式事务处理、分布式数据如何去做partition和sharding。
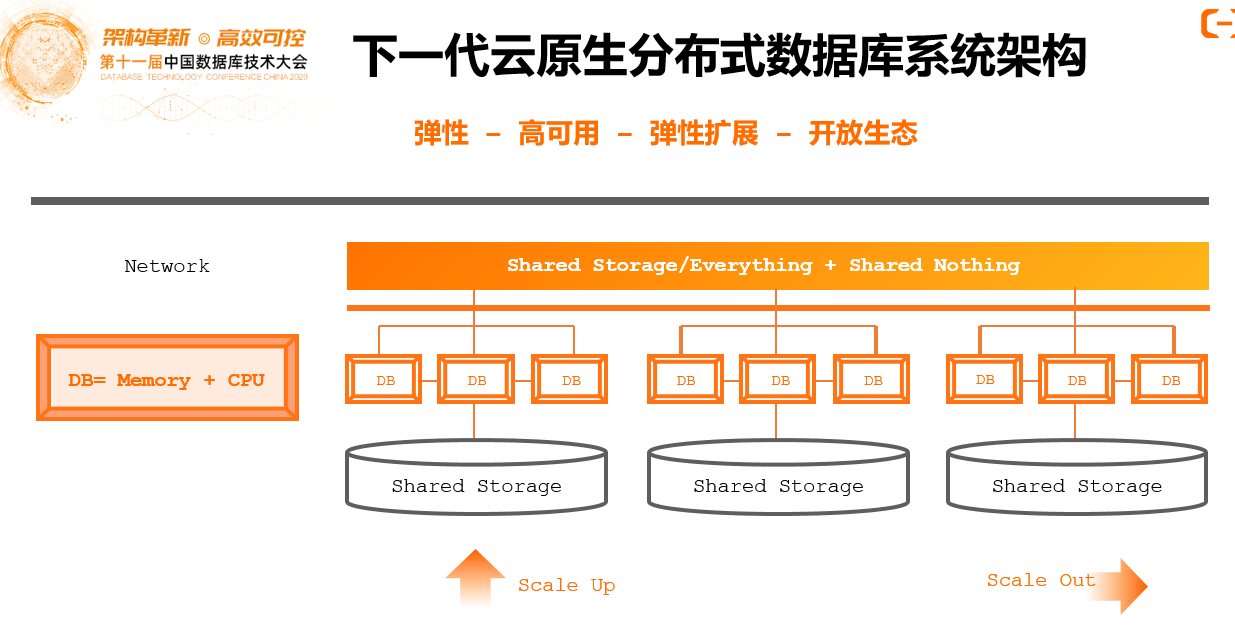
共享存储、共享资源池、共享计算池的时候,它的水平拓展性还存在一定局限性。我们可以结合分布式和云原生的架构融合来解决这个问题。
在上图展示中,把Shared Nothing的能力和Shared Storage/Shared everything的能力打通,每个shard下面是一个资源池,能力非常强,弹性很高,同时也可以把这样的部分用分布式技术联系起来,既享受到分布式水平拓展的能力的好处,同时又避免大量的分布式事务和分布式处理场景。因为单个节点计算存储能力都特别强,200TB的数据按照传统的分布式架构,假设1个节点只能处理1TB,那就需要200个分布式节点。云原生架构1个节点可以处理100TB,也就是为2000TB的数据,传统分布式架构需要200个节点,将云原生架构结合起来需要两三个节点,分布式事务处理、分布式查询的概率会大大降低,整个系统的效率会大大提升。
趋势三:下一代企业级数据库关键技术
关键词:HTAP:大数据数据库一体化、云原生+分布式、智能化、Multi-Model 多模、软硬件一体化、安全可信
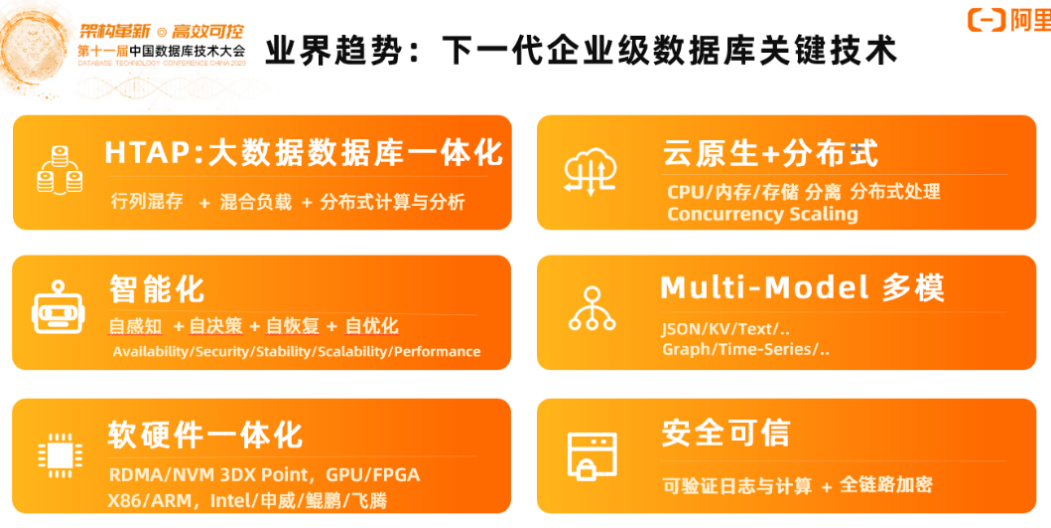
大数据、数据库一体化的趋势包括离在线一体、Transaction and Analytical Processing一体化,离线计算和在线交互式分析的一体化,统称为大数据与数据库一体化。
云原生和分布式技术的深度融合,智能化、机器学习、AI技术在数据库领域的融合,如何简化运维、简化数据库的使用方式。除了结构化数据,如何处理非结构化数据,比如文本等数据,软硬件一体化,如何结合硬件的能力如RDMA和NVM,发挥出硬件的优势。最后是系统的安全可信能力。
二、核心技术&产品介绍
2.1企业级云原生分布式数据库
1)云原生关系型数据库PolarDB
阿里云自研关系型数据库的核心产品是云原生关系型数据库PolarDB,通过这下面张图就可以理解PolarDB的思想,存储和计算分离,通过RAFT来做高可用、高可靠的保障,在计算节点来做一个计算池,下一代版本的PolarDB可以做到多写多读multi-master,计算节点在下一代会进一步解耦,做成共享内存池,CPU Core可以做到共享计算池,然后去访问一份共享内存, PolarPorxy负责做读写分离和负载均衡工作。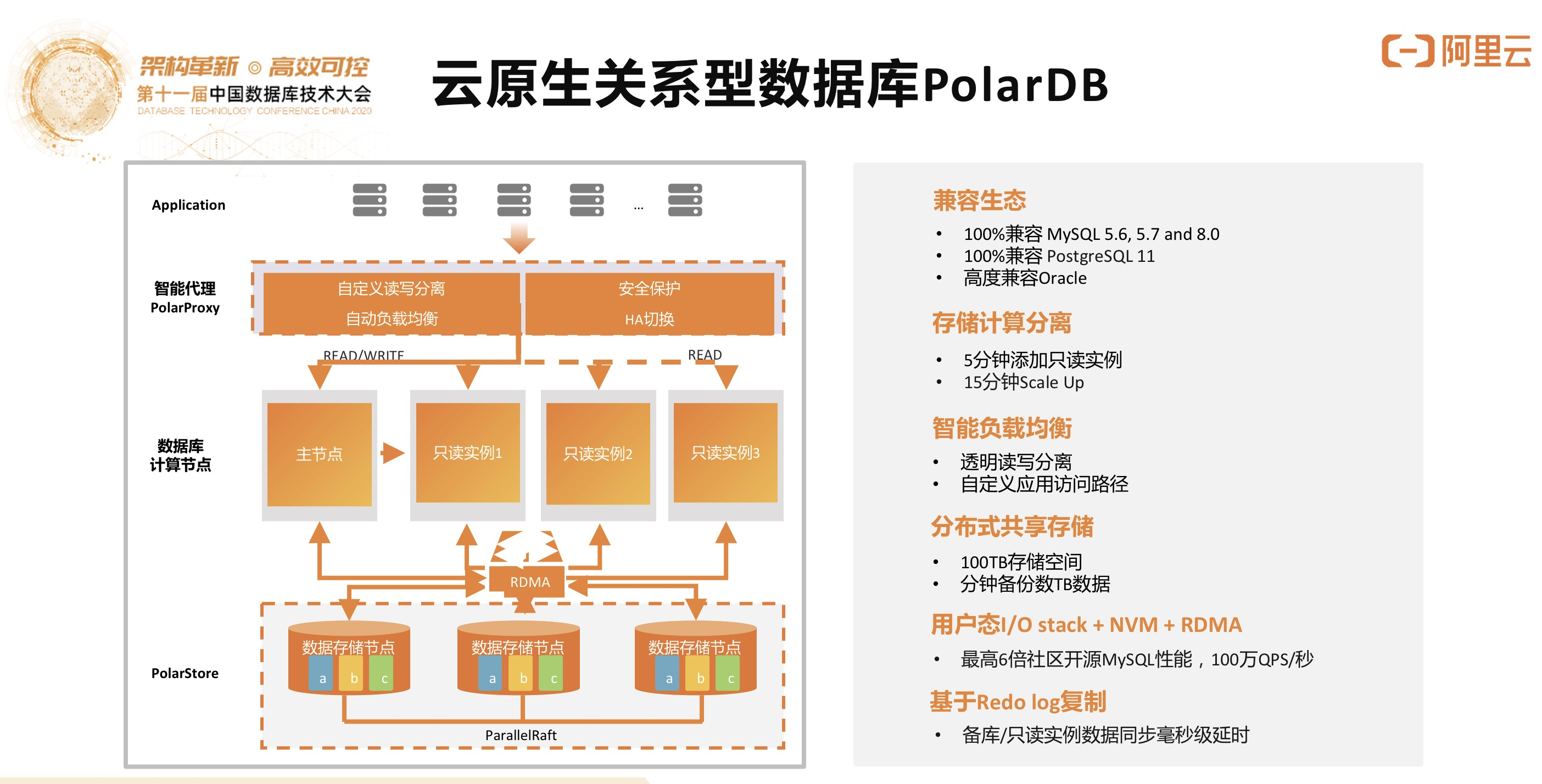
基于这个架构,100%兼容MySQL/PG和高度兼容Oracle的PolarDB诞生了,针对开源和商业数据库的使用场景,在性能上做了大量的优化,比如做Parallel Query Processing,取得了非常优异的性能,整个TCO相对传统数据库可以做到只有1/3到1/6,TPCC同样的负载下性能有大幅度提升。
在PolarDB的基础上做了Global Database,跨Region的架构解决了很多出海客户就近读写的需求。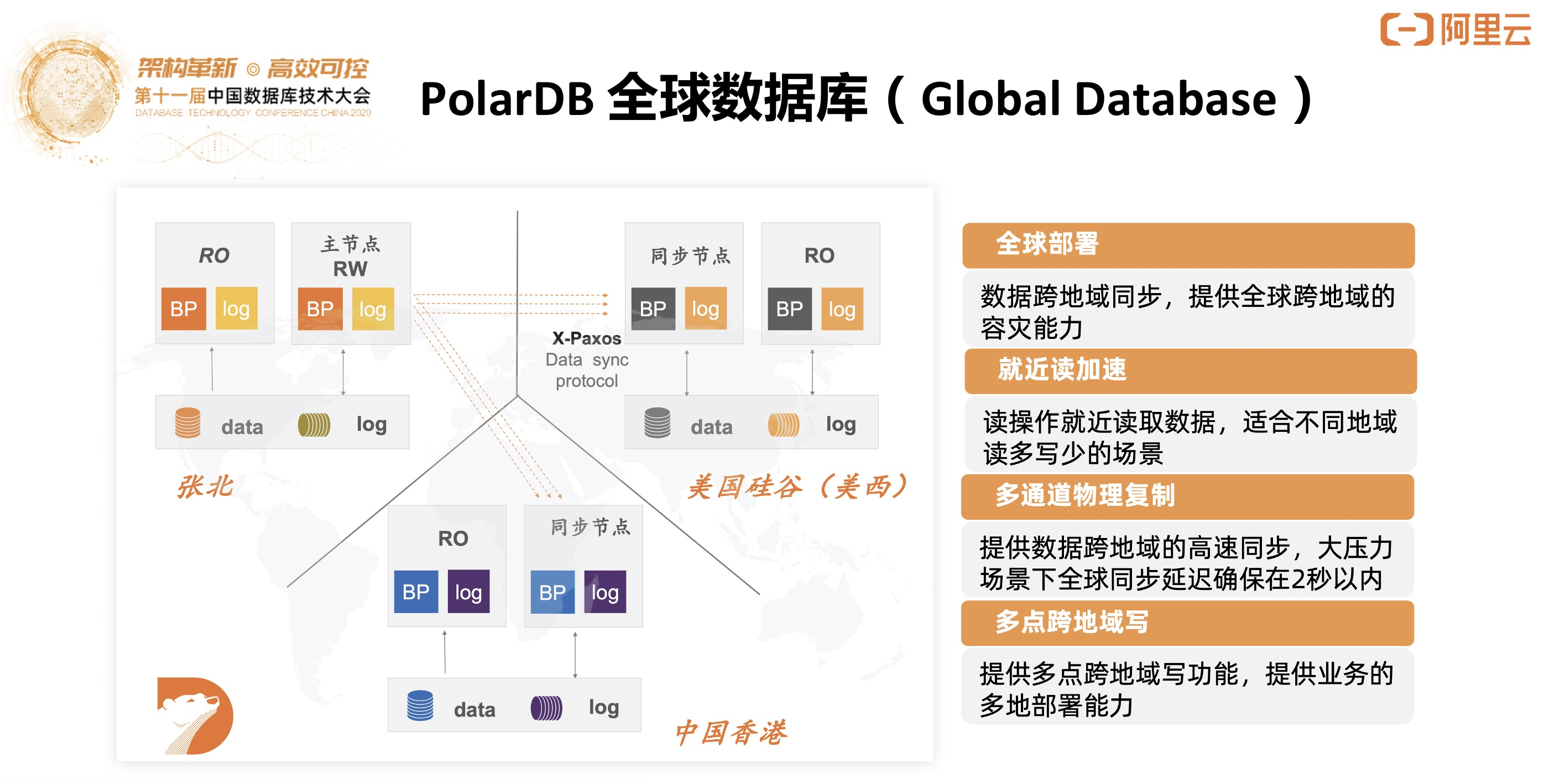
2)云原生分布式数据库PolarDB-X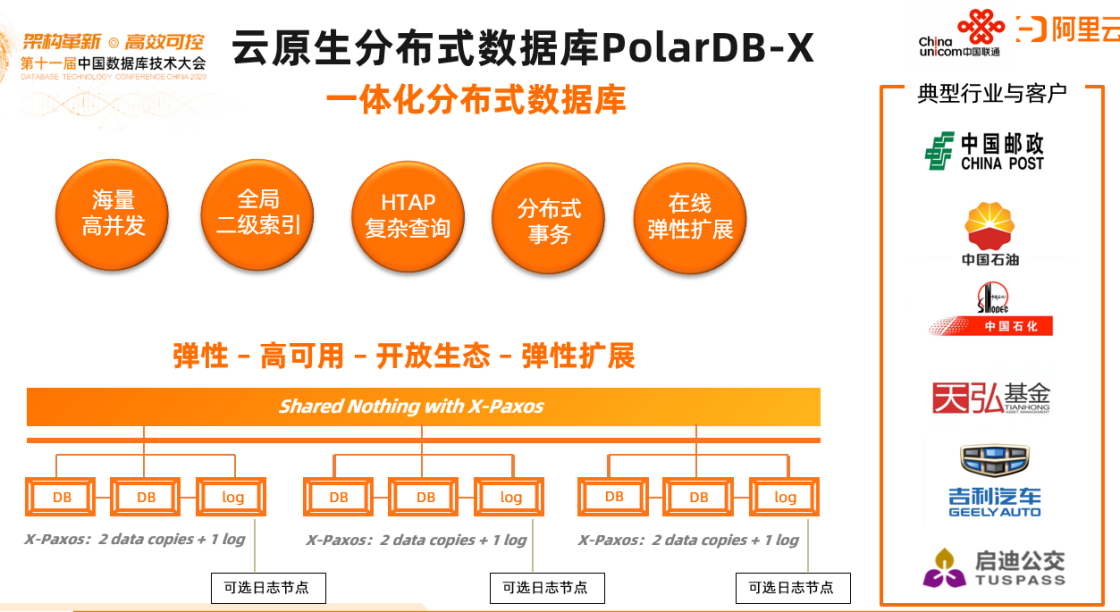
分布式版本的PolarDB-X:基于X-DB以及原来的分库分表DRDS将二者合二为一成为一个透明的一体化分布式数据库PolarDB-X。每个分布式节点包括两个数据节点、一个日志节点,通过优化Paxos确保数据节点和日志节点的数据一致性。
它的特点在于三节点可以做到跨AZ部署做到同城容灾,不需要传统的商业数据库利用数据同步链路来做容灾,直接在存储层做到同城容灾。
异地的两地三中心甚至更多异地容灾架构,比如跨异地的直接部署,因为网络的Latency非常大,可能会影响到性能,还是需要通过类似ADG、DTS这样的产品架构来做数据同步,做到异地容灾架构。
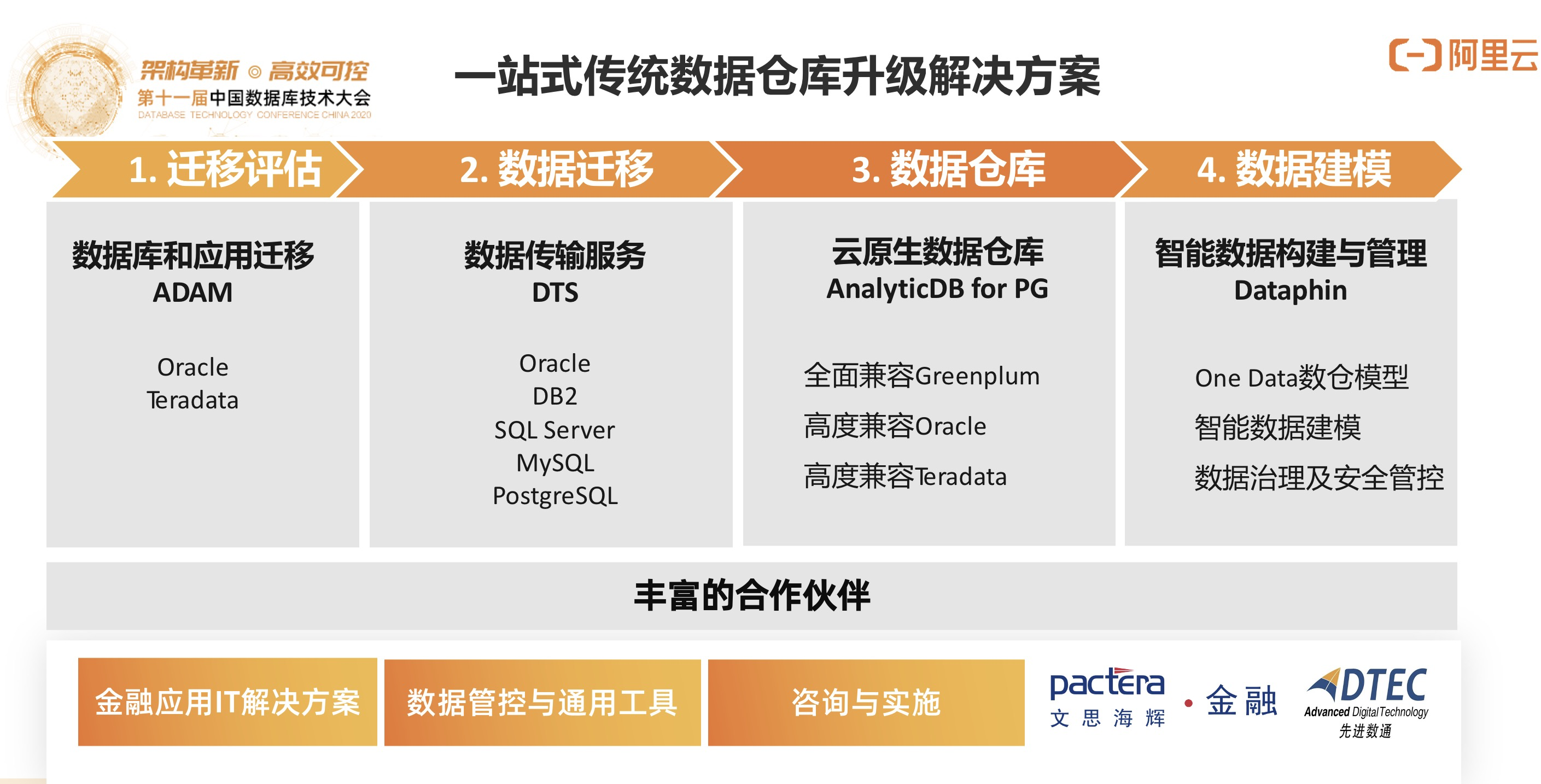
3)数据库及应用迁移改造ADAM
ADAM,全称Advanced Database Application And Application Migration,通过对应用代码和逻辑树的分析生成一个评估报告。评估报告自动生成,可以提供从传统数据库迁移到PolarDB和ADB的迁移分析。
一键迁移的方案通过ADAM来做应用代码的扫描,通过DTS去做数据的实时同步,迁移到云原生的数据库当中,可以做到对于客户的应用无切入的改造。
如图所示: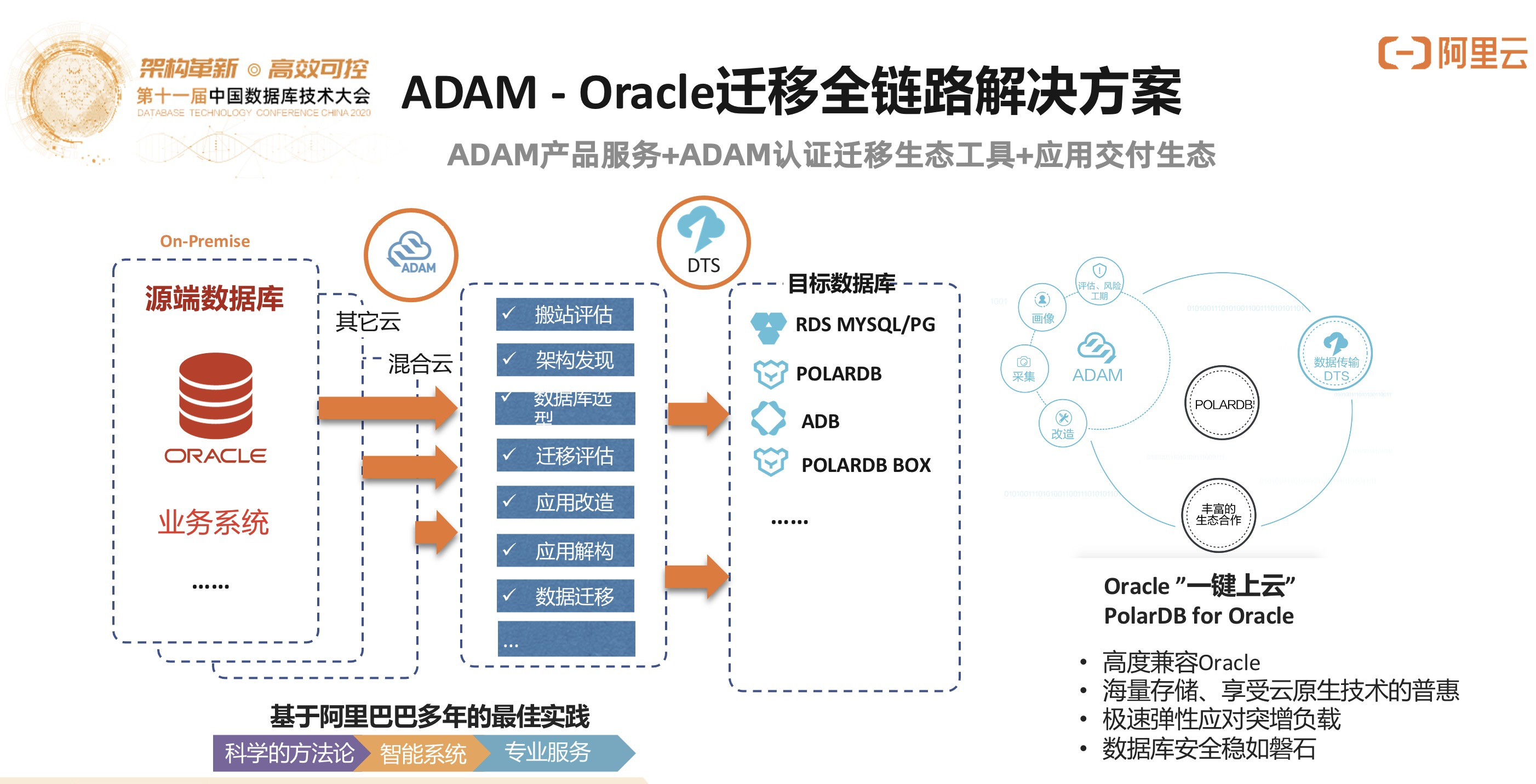
总结来说,分布式只是一个技术,实际上很多数据库的应用是不需要分布式,通过云原生的能力就可以很好地满足应用弹性、高可用、水平拓展的需求。真正需要分布式的能力就可以结合Shared Nothing架构和技术来做扩展,所以要根据应用需求从客户视角出发设计系统和应用迁移改造方案。
2.2云原生数据仓库与数据湖
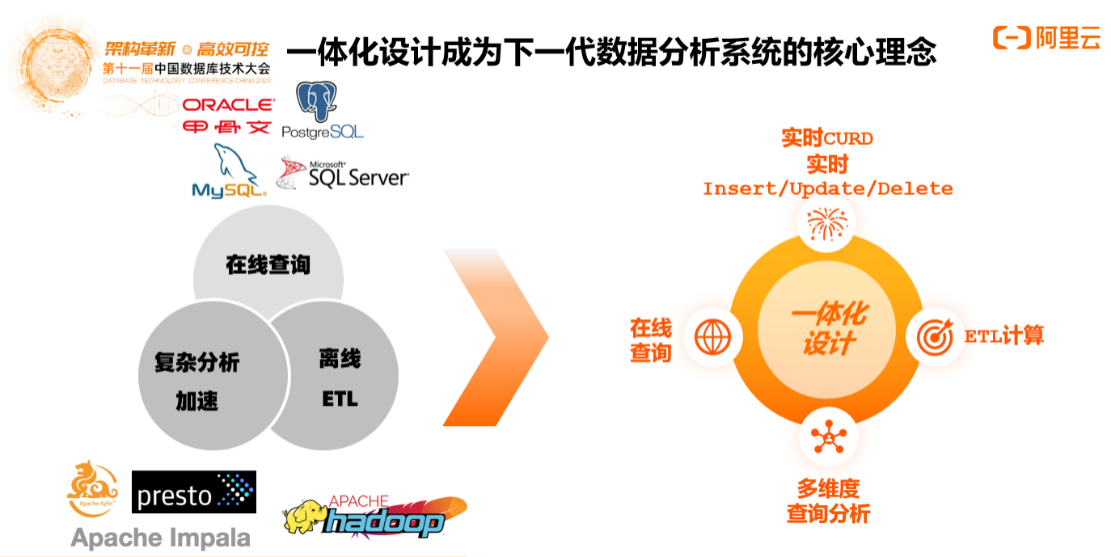
一体化设计成为下一代数据分析系统的核心理念
数据库市场不仅是TP关系型数据库。这也是为什么Gartner将传统的OPDBMS(事务处理)与DMSA(管理与分析)合二为一成为Cloud DBMS,并且断言Modern DBMS can do both and there is only one Cloud DBMS market。除了事务处理,数据库系统也需通过计算分析实现数据处理的一体化,例如在数据仓库和数据湖领域发挥作用。
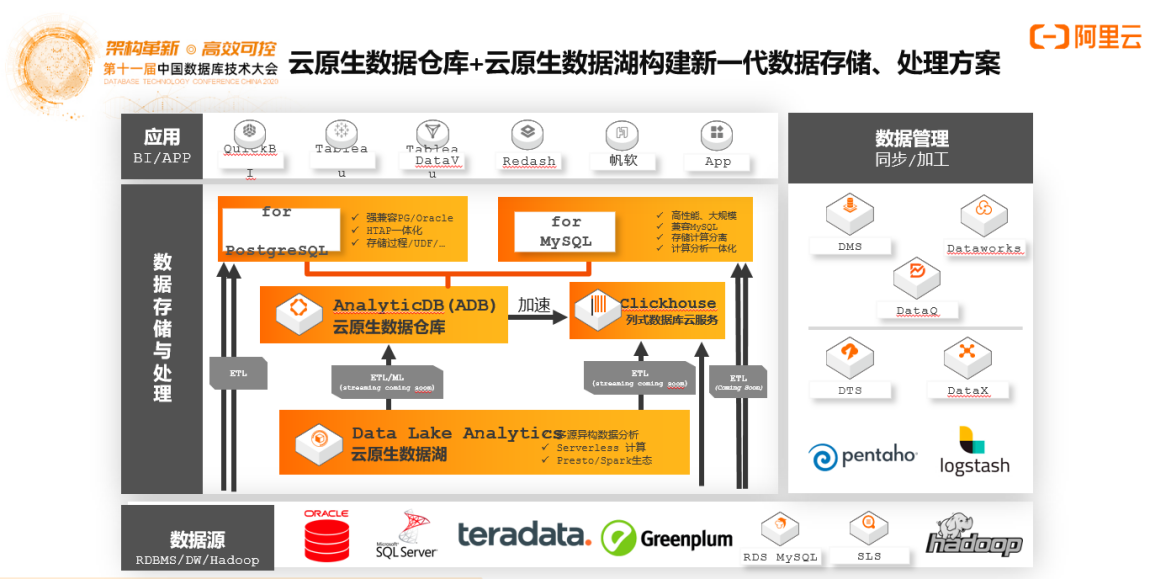
云原生数据仓库+云原生数据湖构建新一代数据存储、处理方案
数据分析领域是群雄格局的现状,在线查询、离线计算,有非常多细分领域,利用云原生计算技术的资源池化、资源解耦,会看到下一代云原生的数据系统。下一代的云原生数据仓应该具备实时在线的“增删改查”能力,在此基础上支持离在线一体化,既能做在线交互式分析和查询又能做复杂的离线ETL和计算,支持多维度的数据分析,这就是对云原生数据仓库的核心要求。
数据仓库当中的增删改查和TP数据库存在一定区别,因为对隔离机制的要求相比没有那么高,例如不需要做到snapshot isolation,因为是一个分析系统,但是一定要支持传统数据库的在线增删改查的能力,不是只能支持Batch Insertion的场景。
1)云原生数据仓库
数据仓库适用于范式化、有结构的数据处理,适用于已经Normalized数据管理和应用,已经有了非常清晰稳定的业务逻辑,需要范式化进行管理。
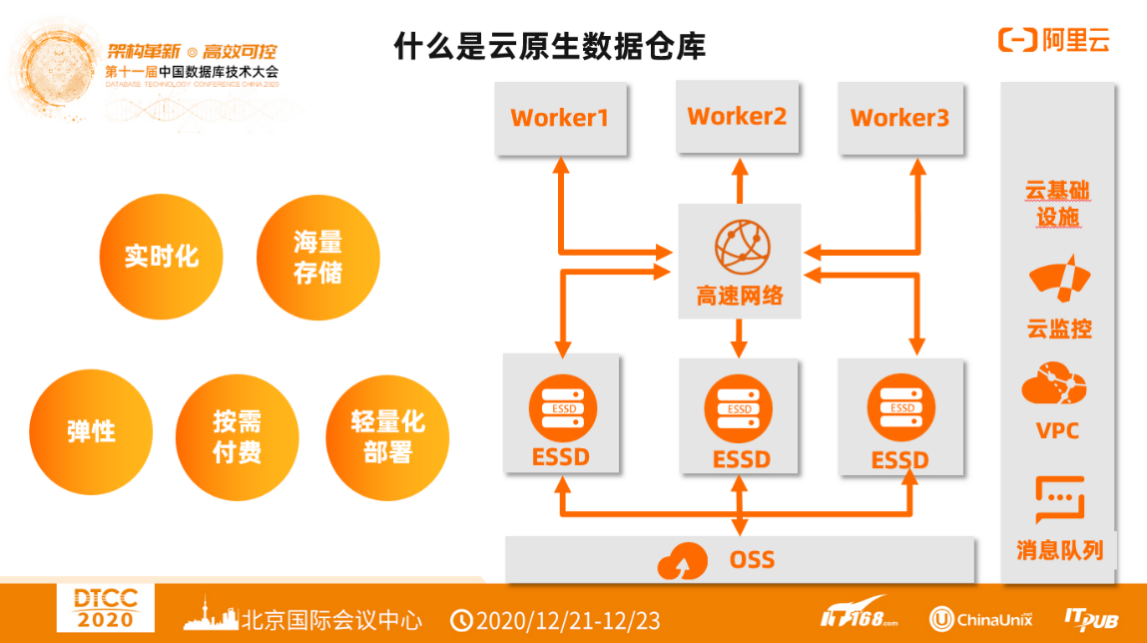
云原生数据仓库利用云原生架构对传统数据仓库进行升级和改造,资源池化、资源解耦实现弹性、高可用、水平拓展、智能化运维是云原生的核心本质之一。
如果把这些结合在一起,阿里云就是OSS、亚马逊就是S3,低成本的对象存储作为冷存储池,同时利用高效的云盘做一个本地的缓存,计算节点进行解耦,对本地节点进行加速,通过高速网络连成一个池,再对应用做统一的透明式服务。
AnalyticDB 云原生数据仓库

这个架构展开底下是对象存储,利用RAFT协议实现数据一致性,对每个计算节点的本地缓存加速利用ESSD弹性云盘。上面是计算池,在数据仓库为了实现大数据和数据库一体化,数据仓库领域的计算节点也需要将大数据的离线计算能力做得更强,离线大数据系统基本上都是基于BSP+DAG,传统数据库领域则是MPP架构,所以为了做到离在线一体化将MPP和BSP+DAG进行结合,做一个Hybrid的计算引擎,针对此再做一个Hybrid的查询和计算优化器。上面的是MetaData管理,力求做到原数据共享。
云原生数据仓库AnalyticDB MySQL
AnalyticDB(ADB)就是基于这个思想设计的云原生数据仓库,ADB MySQL兼容MySQL这个生态,成为TPC-DS性能与性价比榜单第一。将交互式分析和复杂的离线ETL计算统一支持起来。ADB基于PG也做了另外一个版本,就是ADB for PG。针对传统数据仓库,例如TeraData、利用PG对Oracle的兼容性来做传统数据仓库的升级,利用云原生的架构,存储和计算分离,针对传统数据仓库进行云原生的升级改造,查询执行器和其他模块中做了大量优化。
云原生数据仓库AnalyticDB for PostgreSQL

例如向量化执行(vector execution)、Code Generation,ADB PG也支持把非结构化数据向量化变成高维向量数据以后处理,然后将向量数据和结构化数据在一个引擎当中进行处理实现非结构化数据和结构化数据的融合处理。ADB PG拿到了TPC-H性能和性价比榜单第一的成绩。
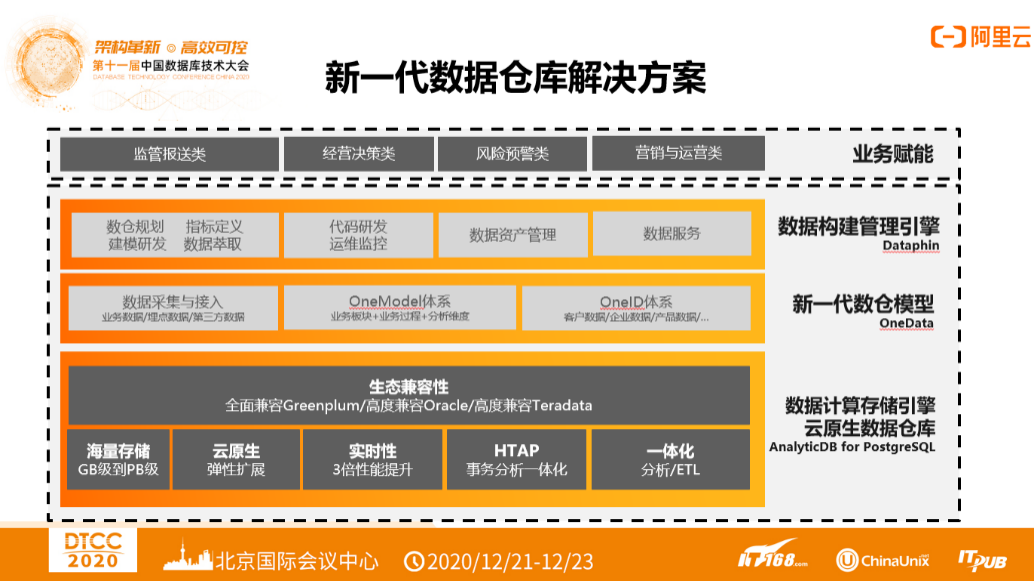
2)新一代数据仓库解决方案
基于此推出了新一代数据仓库的架构,底下是核心的云原生数据仓库ADB,上面是数据建模和数据资产管理,因为数据仓库领域不仅仅是引擎的问题,还包括建模等一系列问题。针对传统数据仓库做了升级到云原生数据仓库的解决方案,利用ADB、生态合作伙伴以及整个智能化工具实现一体化的解决方案。
DLA 云原生数据湖分析(Serverless,统一元数据+开放存储与分析计算)
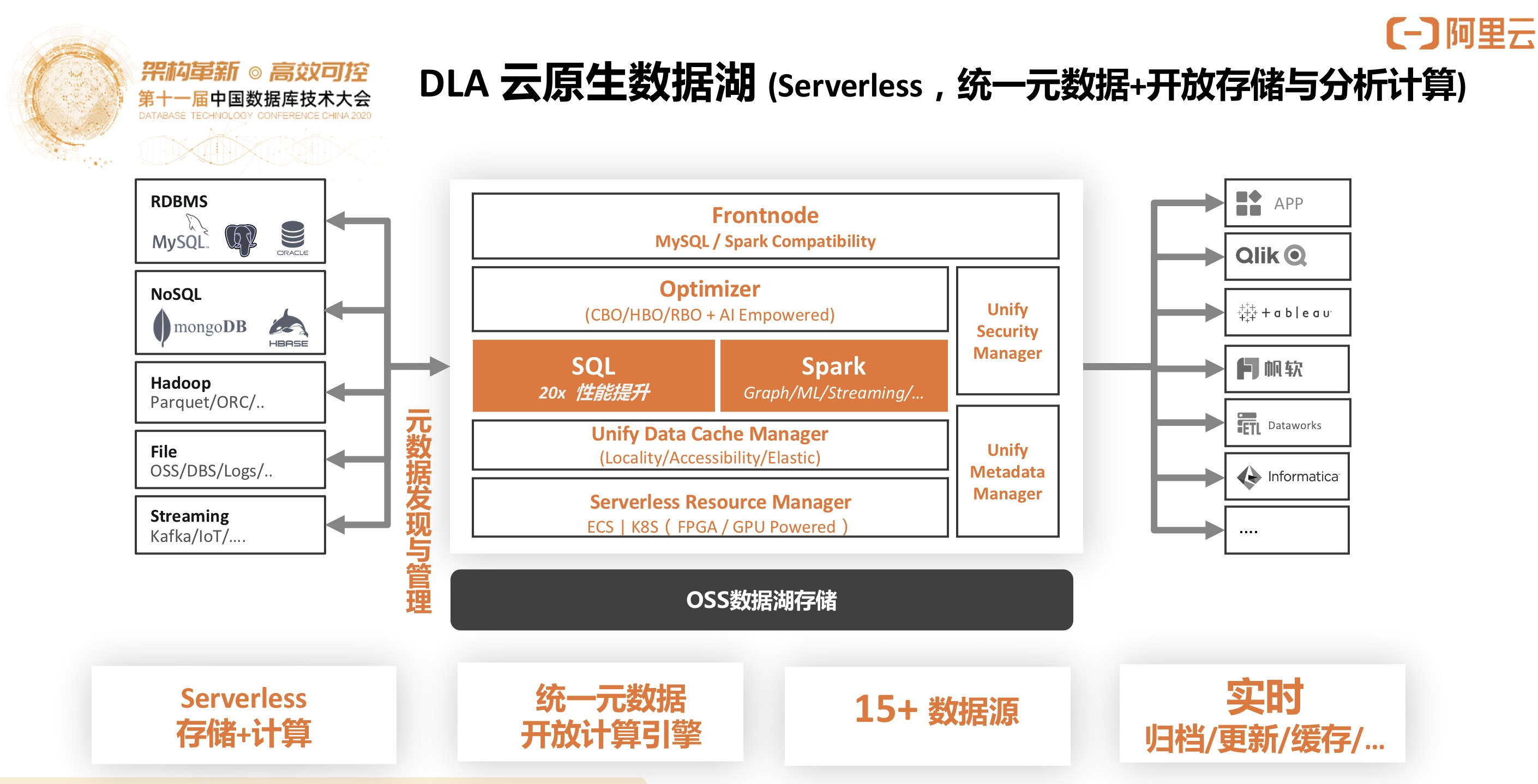
数据源更加复杂与多样的场景是云原生数据湖和数据仓库最大的区别。数据湖的核心场景是对多源异构的数据源进行统一的管理和计算与分析处理。云原生数据湖拥有统一的界面对多源异构数据进行管理、计算和分析,核心点在于元数据管理和发现,集成不同的计算引擎对多源异构数据进行管理和分析。
Data Lake Analytics + OSS 云原生数据湖
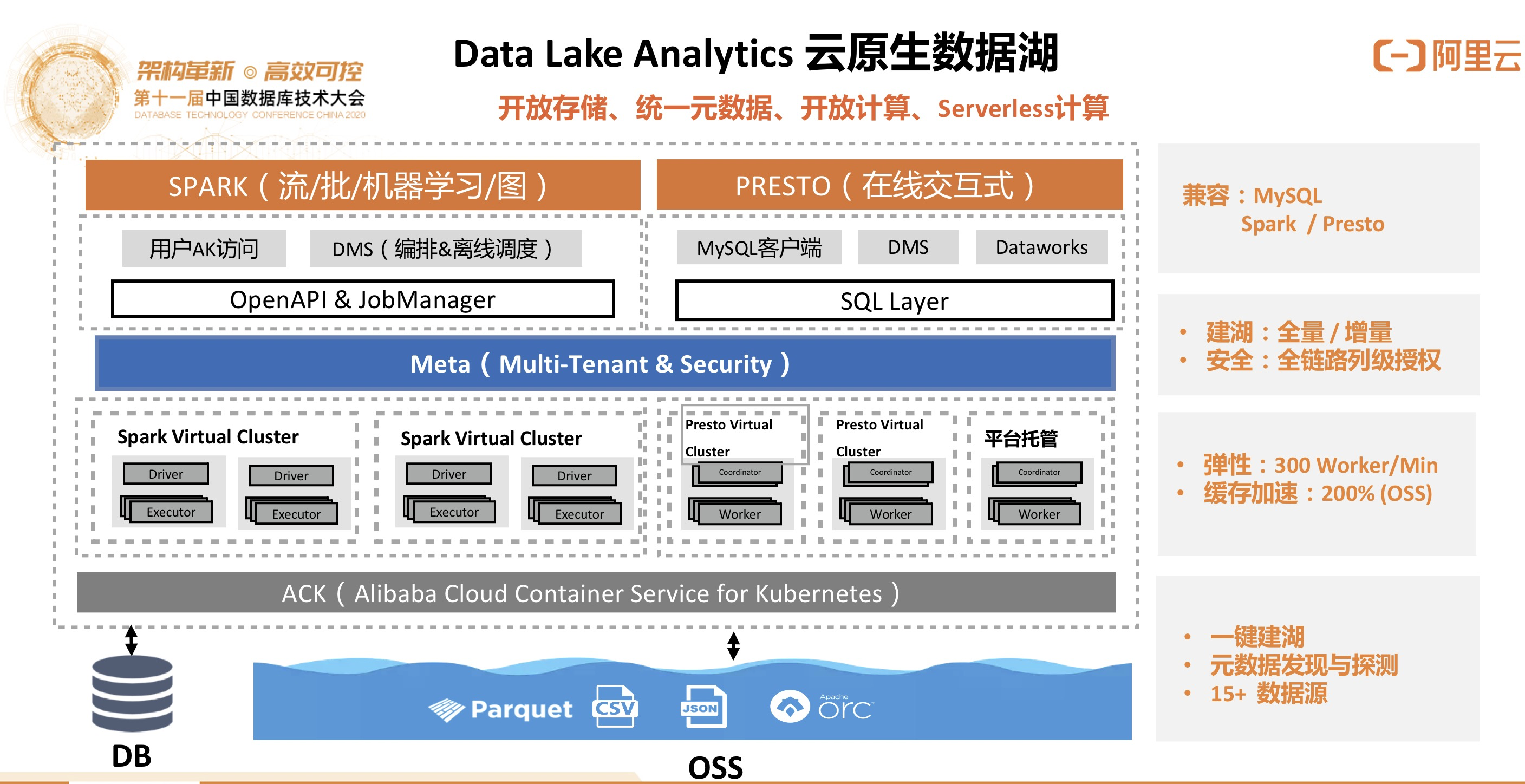
上图为云原生数据湖分析Data Lake Analytics的架构,下面是对象存储或者其它不同的存储源,搭载Kubernetes+Container技术,通过serverless技术来做分析和计算,以及多用户之间的隔离安全保护,这样可以满足客户针对多源异构数据实现低成本、弹性的丰富的计算和分析处理需求。
2.3智能化、安全可信与生态工具
1)云原生+智能化数据库管控平台

智能化的数据管控平台利用云原生技术和人工智能技术进行智能化的数据库管理运维,包括分区、索引推荐、异常检测、慢SQL治理、参数调优等,这样可以大量提升管理运维的效率,我们研发了一个Database Autonomy Service模块(DAS)来实现数据库系统的自动驾驶,大幅度提升运维管控的效率。
2)云端全程加密数据永不泄露
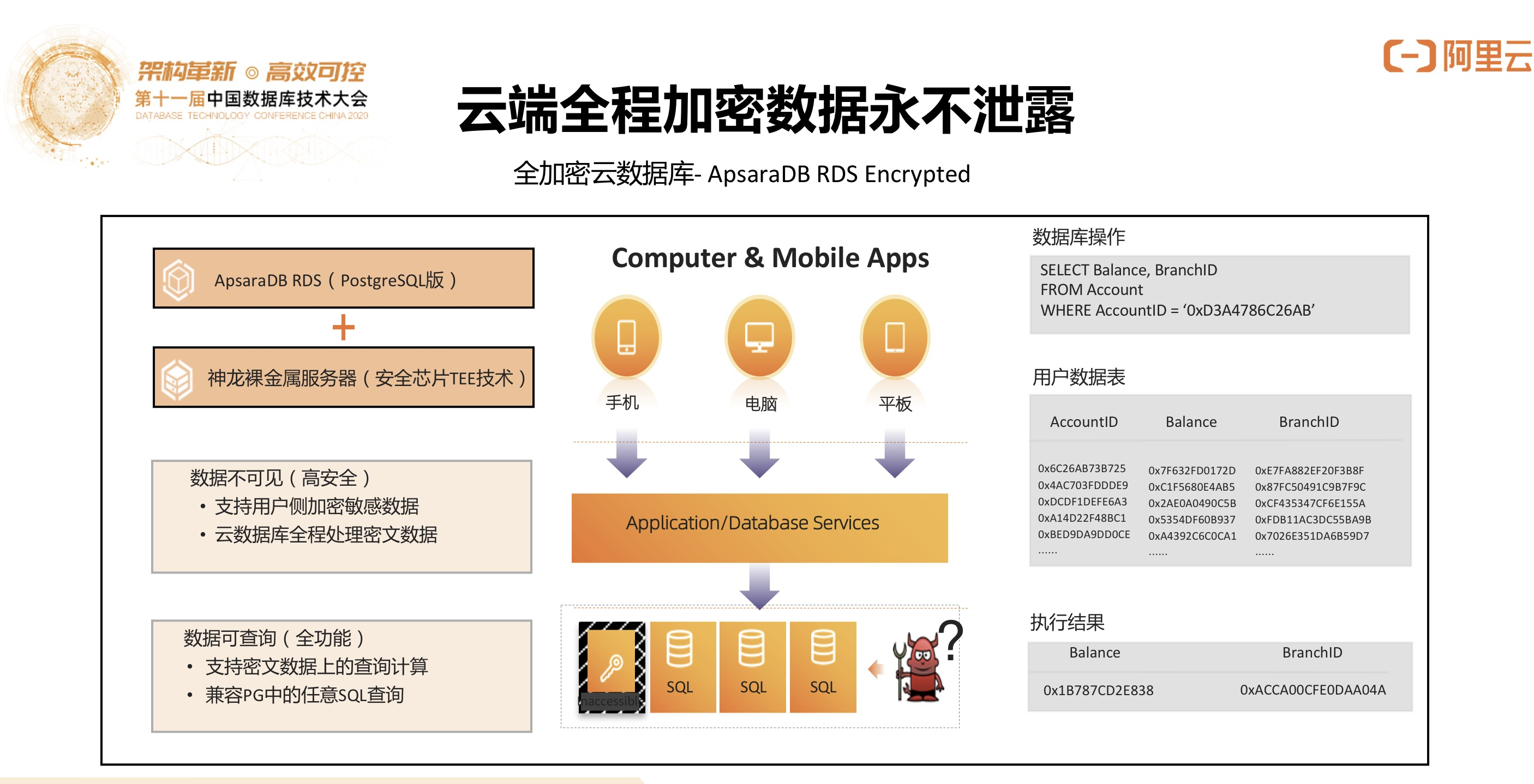
除了传统的Access Control,传输与落盘加密,我们研发了全加密数据库,确保数据的绝对安全,结合安全硬件TEE来做到这一点,可以做到数据处理的全程加密。
3)数据库生态工具
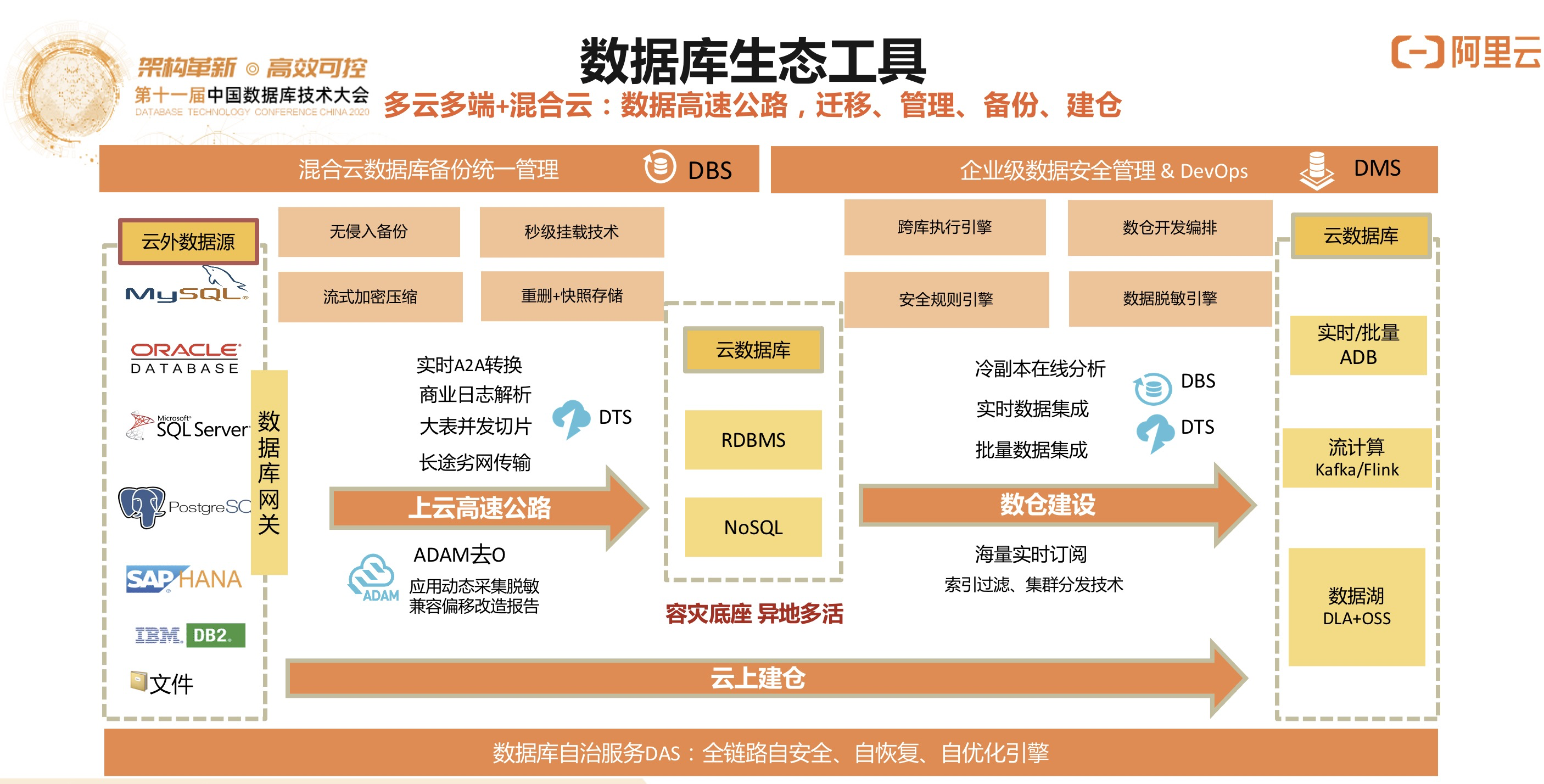
除了前面提到的数据库应用迁移工具ADAM和数据库同步工具DTS,我们还提供了丰富的其他数据库生态工具,包括数据管理服务DMS和数据数据库备份服务DBS,可以提供数据血缘关系、数仓开发与建模、数据安全管理、数据备份容灾、CDM等一系列的企业级数据处理能力和面向开发者的服务能力。
4)数据库备份解决方案DBS
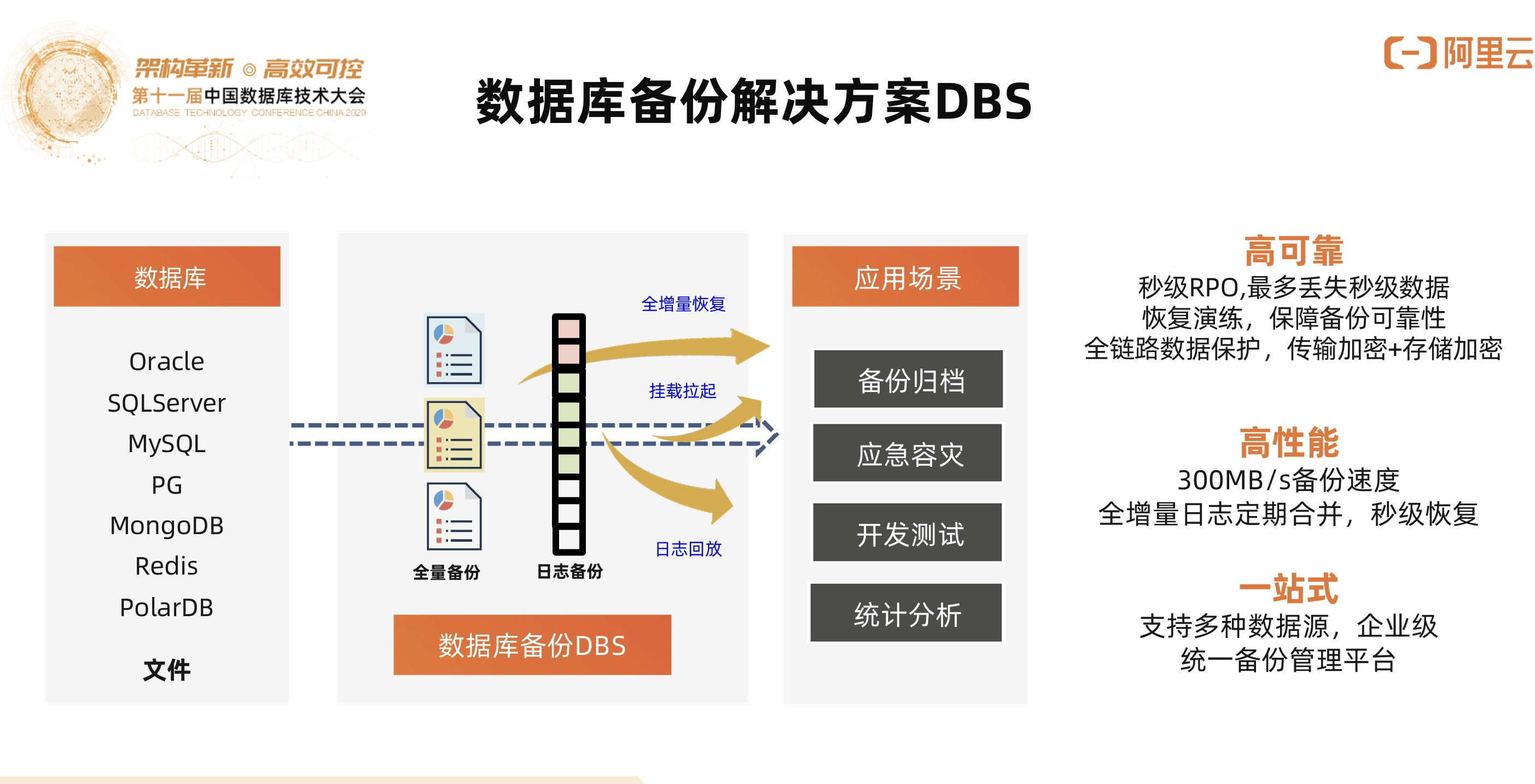
DBS可以做传统数据多云多端的备份,把线下的数据备份到云上,也可以把云上的数据备份到线下,实现秒级RPO,支持多种数据源多源多端的云备份,并且支持Snapshot Recovery。
三、案例分析
1)双十一购物节•数据库挑战
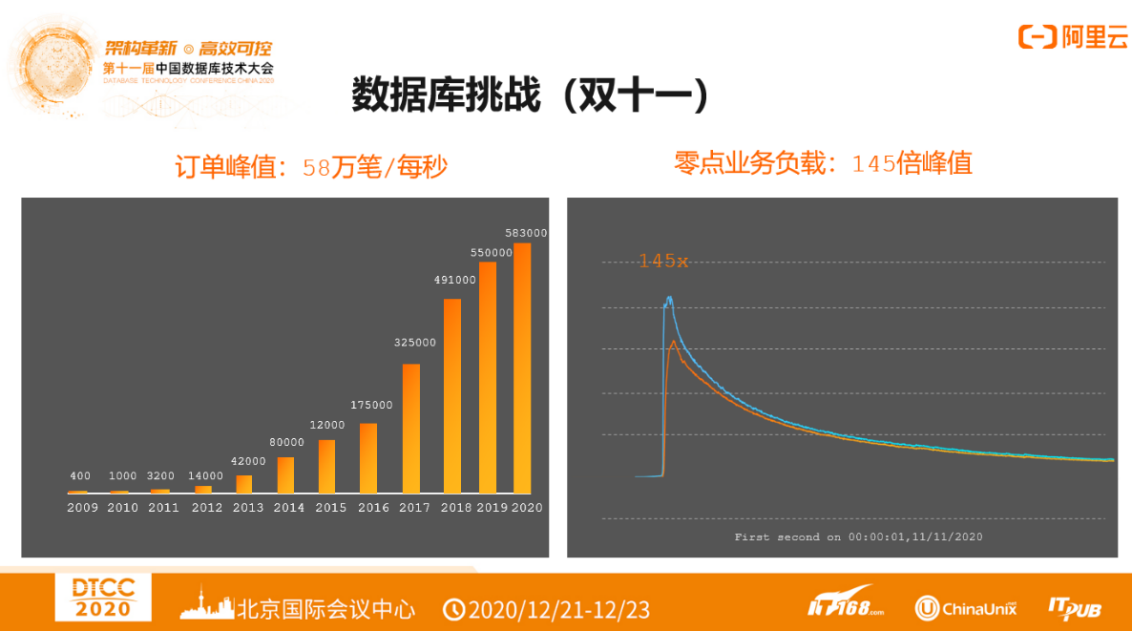
上图为2020年“双十一”真实曲线,145倍的系统峰值瞬间迸发,利用云原生能力和分布式能力的结合可以完美平滑地支持“双十一”高并发海量数据的挑战。
2)中国邮政•大型传统商用数据库替换
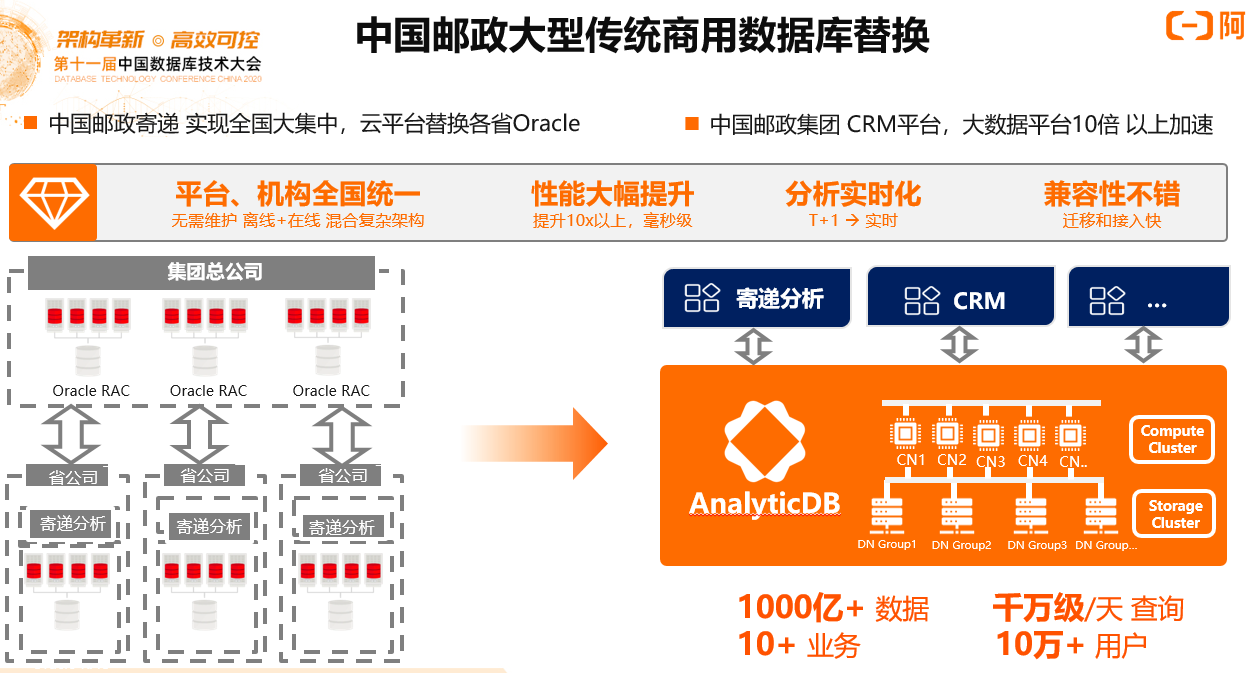
中国邮政以前是基于传统的商业数据仓库,如今利用ADB云原生数仓进行升级,提供更可靠的离在线一体化计算分析能力,实现对全国数据寄递平台统一到一个系统的诉求。
3)某超大型部委客户
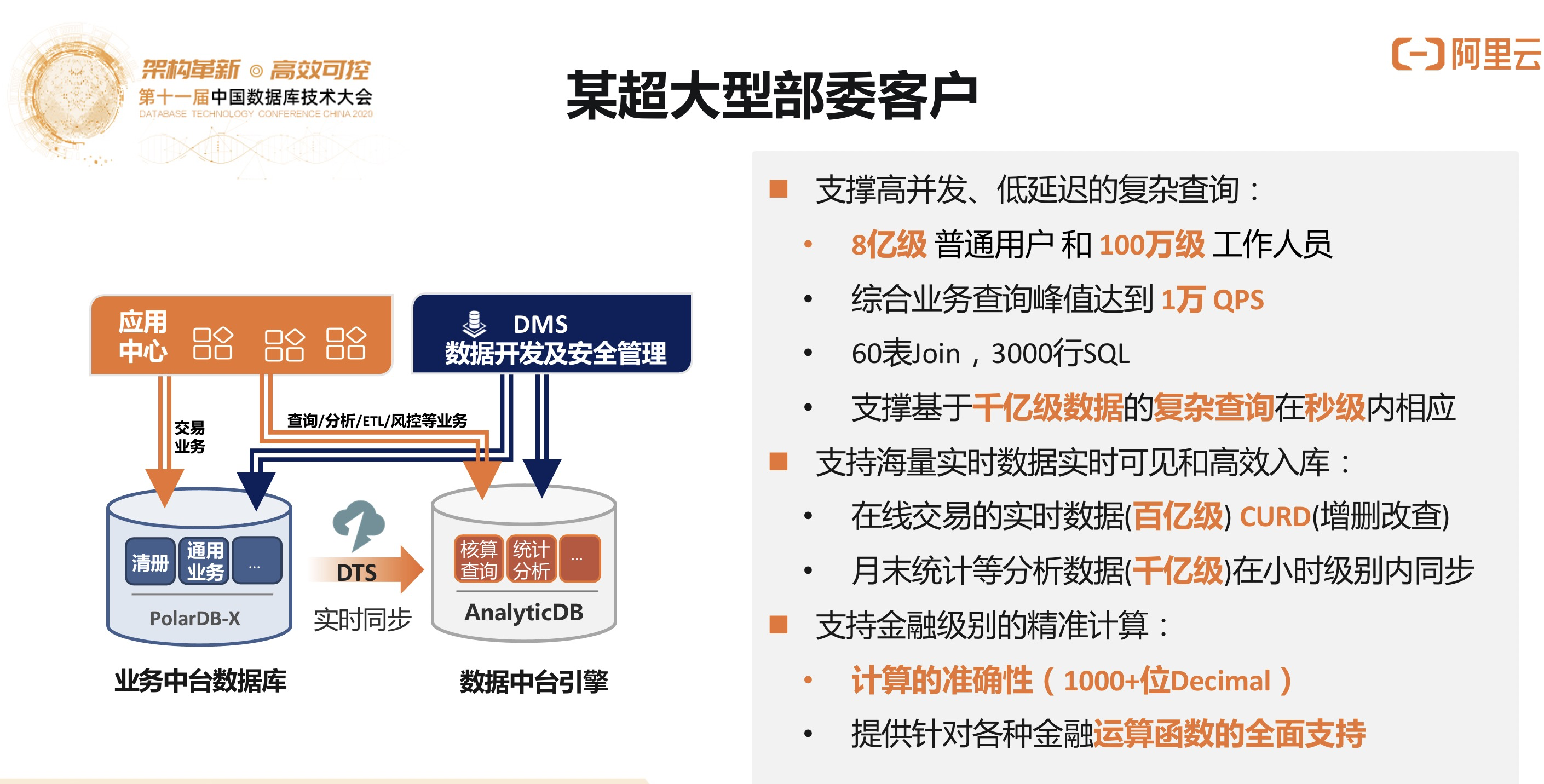
国税总局的全国税务数据统一系统应用,利用PolarDB-X分布式数据库以及DTS和ADB实现了从TP到AP数据处理、计算、分析、查询、处理一整套的解决方案,同时通过DMS来做数据开发和管理。支撑高并发、低延迟的复杂查询;支撑海量实时数据实时可见和高效入库;支持金融级别的精准计算。
4)阿里云数据库技术对抗新冠疫情
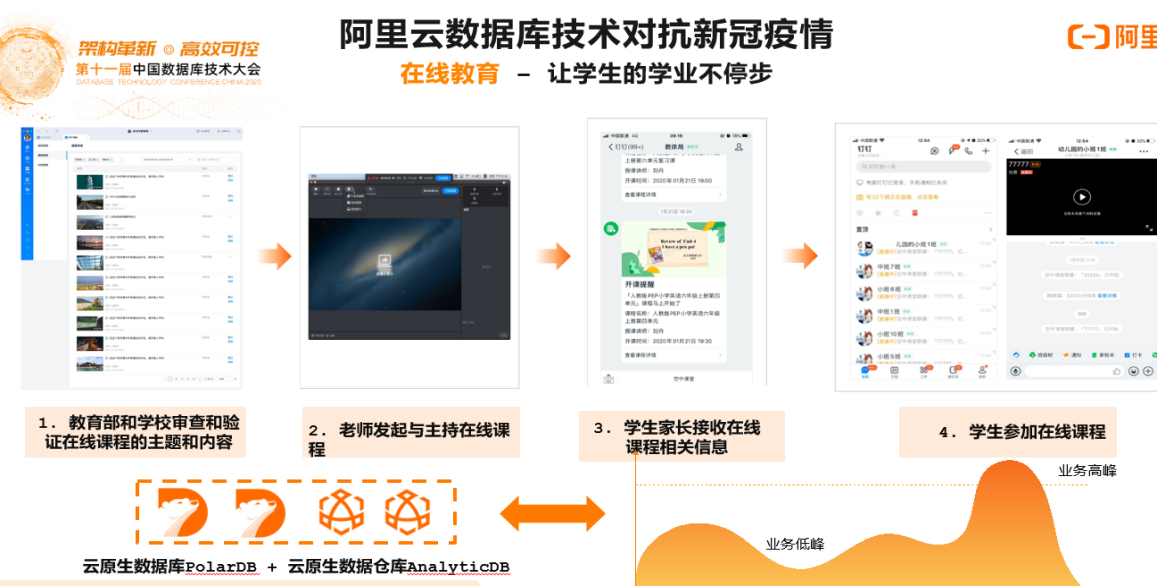
利用云原生数据库提供的弹性高可用和智能化运维能力,结合分布式去做水平拓展,为广大的企业和用户提供非常好的弹性高可用能力,疫情期间在线教育行业开始大规模地使用云原生、分布式的新一代数据库技术架构和产品实现降本增效对抗疫情。
5)客户案例•中国联通
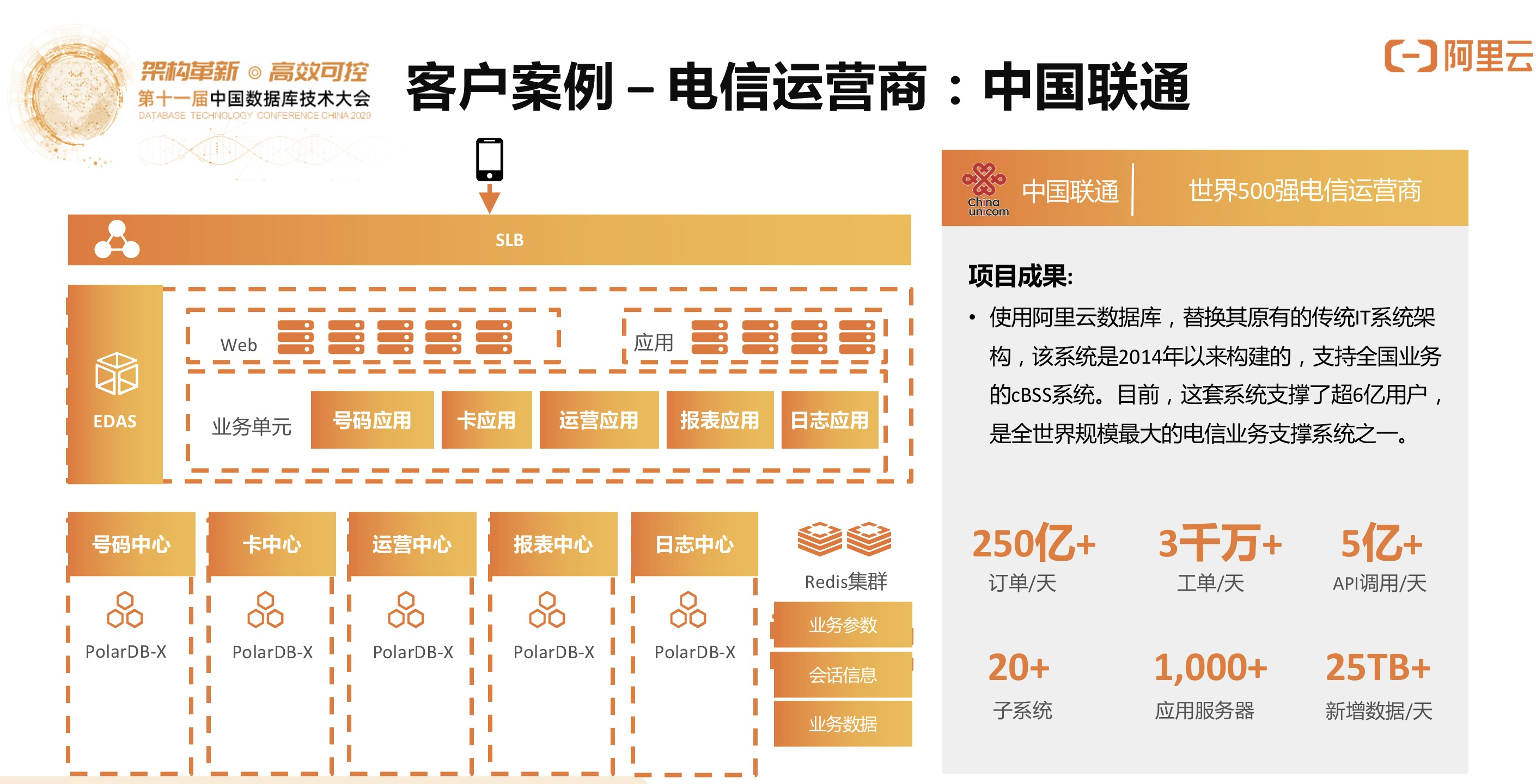
中国联通的核心cBSS系统,针对传统的商业数据库进行升级改造,利用分布式数据库PolarDB-X的能力帮助实现这种核心的计费系统实时在线的交易数据处理。
6)客户案例•马来西亚电商巨头 PrestoMall

马来西亚的第三大电商PrestoMall,因为用传统的商业数据库Oracle成本太高,尤其是大促场景瞬间高并发的挑战,利用云原生数据库PolarDB对传统商业数据库进行升级改造,实现了TCO的大幅下降。
7)客户案例•国际广告商数据湖分析+计算解决方案
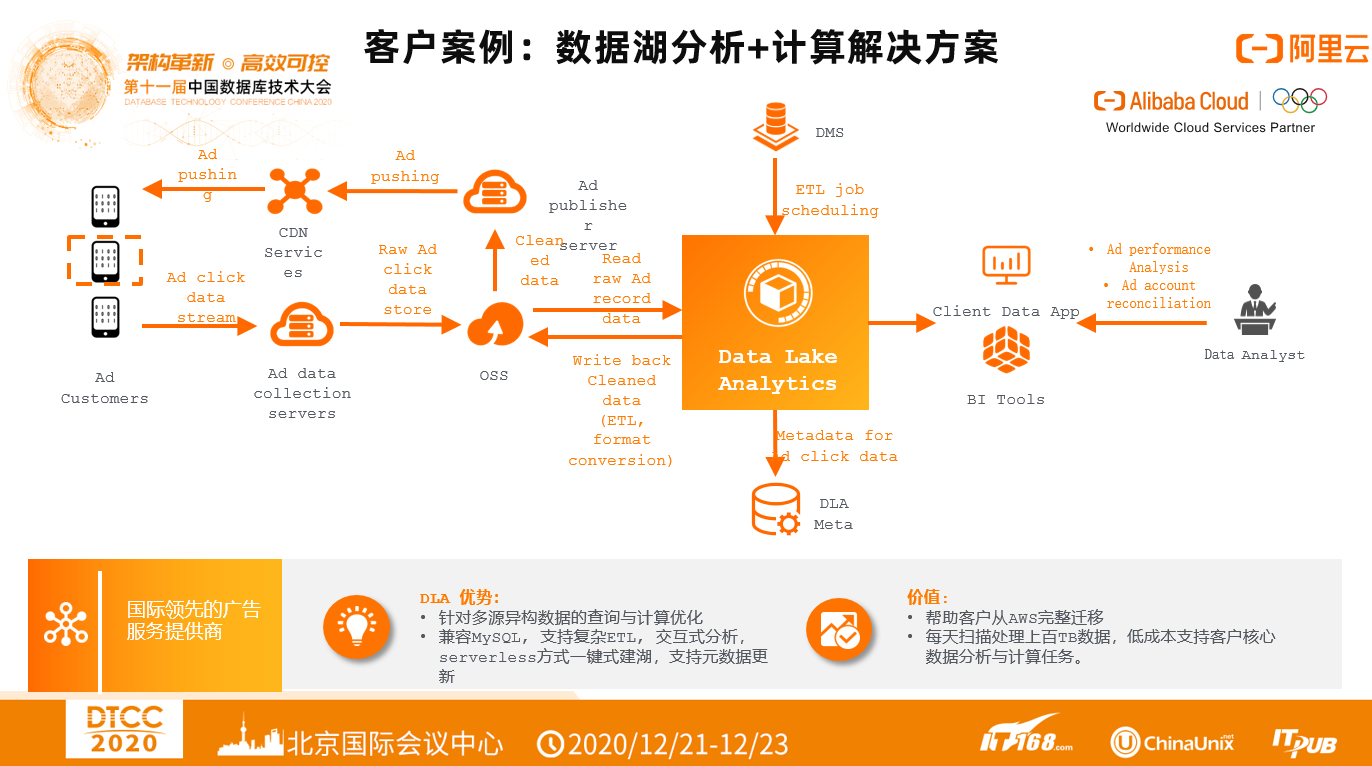
某国际领先广告厂商,文字、图片、和结构化数据等多源异构数据的处理无法统一到一个数据仓库里面进行,利用数据湖来做一个统一的分析引擎。利用DLA+OSS构建了新一代serverless数据湖,大大提升了对多源异构数据的访问处理和计算能力、同时节省了大量的计算成本。针对复杂丰富的计算分析场景,实现平滑的解决方案顺利从AWS迁移过来。
四、总结
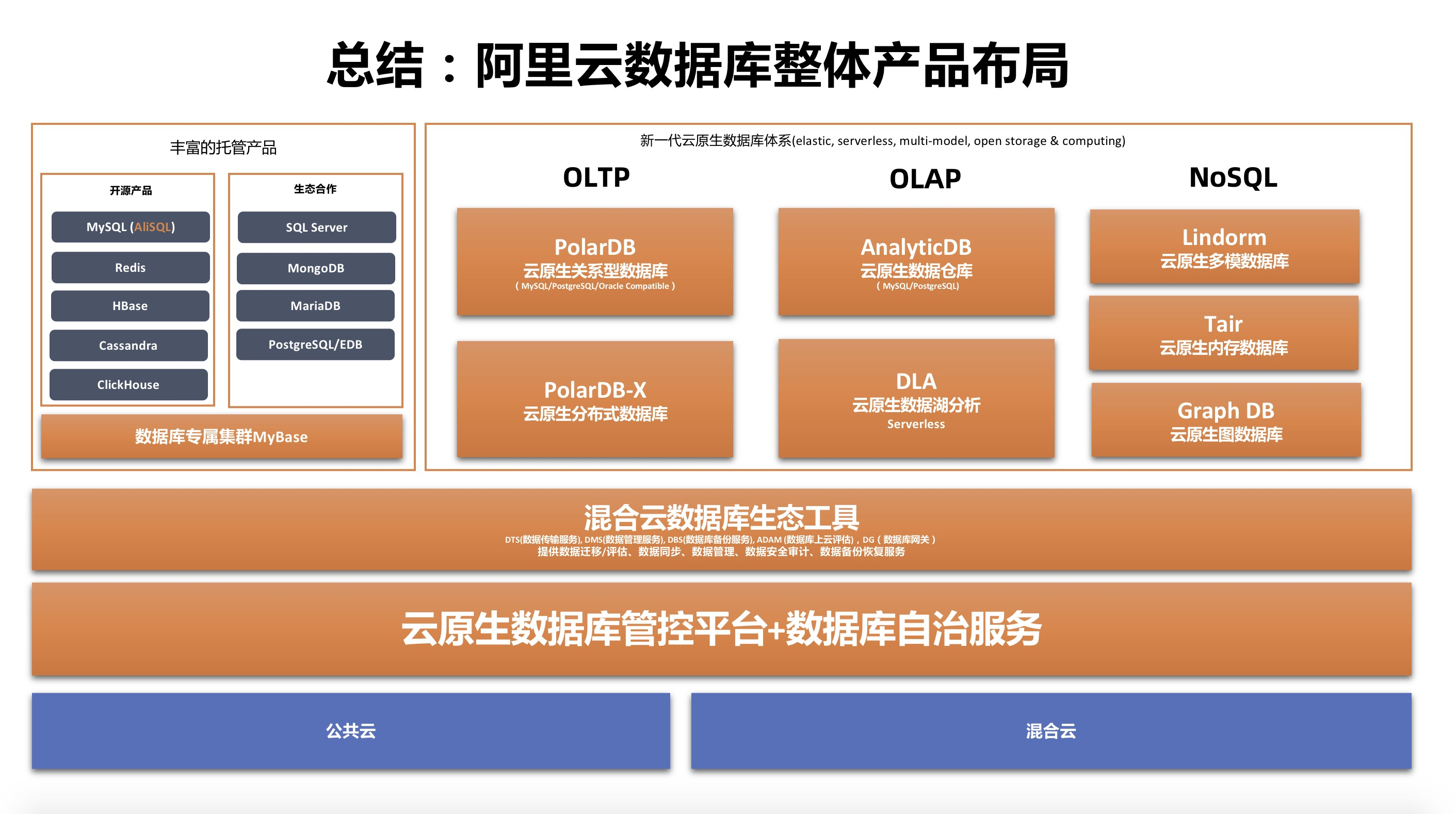
上图为阿里云数据库的产品大图,从OLTP、OLAP、NoSQL到数据库生态工具与云原生智能化管控,阿里云希望利用丰富的云原生数据库产品体系为企业级客户和用户提供更好更可靠的产品与性价比更高的解决方案。
作者:louth
原文链接
本文为阿里云原创内容,未经允许不得转载












自定义adapter,像考试时前面的10几道单选题的实现...)



未被调用)


