简介: 本文除了介绍RobustPeriod的核心技术亮点,还将重点解释如何将它构筑成服务来解决阿里云的业务痛点。
近日,由阿里云计算平台和阿里云达摩院合作的时序多周期检测相关论文RobustPeriod: Robust Time-Frequency Mining for Multiple Periodicity Detection被SIGMOD 2021 (Research Track)接收[1]。这也是阿里巴巴首次以第一单位在SIGMOD 的Research Track发表的论文。
ACM SIGMOD国际数据管理会议(ACM SIGMOD International Conference on Management of Data)由美国计算机协会(ACM)数据管理专业委员会(SIGMOD)发起,是数据库领域具有最高学术地位的国际性学术会议,其论文录取难度极高,SIGMOD位列数据库方向的三大顶级会议之首 (其次是VLDB及ICDE),被中国计算机学会(CCF)推荐为A类会议。本年度的SIGMOD会议将于2021年6月20日至2021年6月25日在中国西安召开。
本次工作是前沿算法与阿里云实际业务场景紧密结合落地的典型案例。论文提出的RobustPeriod是一套具有鲁棒性的时间序列多周期检测通用框架,它不仅在理论上具备创新性,同时基于它构筑的时间序列异常检测和预测服务支撑了阿里云大数据计算平台的多个业务场景。本文除了介绍RobustPeriod的核心技术亮点,还将重点解释如何将它构筑成服务来解决阿里云的业务痛点。
一、业务需求和难点
论文的灵感来源于阿里云大数据计算平台真实的业务场景需求。在大数据平台运维和运营的场景中,有很多需要监控的指标,例如机器的CPU、内存和存储使用率,批处理作业的运行时间,流式作业的吞吐量等。这些指标都属于时间序列,同时这些时间序列中可能存在一些重复出现的模式,即周期性。甚至在一条时间序列中可能存在多种周期性,例如某个作业的TPS曲线,可能既存在天周期,即每天的凌晨都是流量高峰;同时又存在周周期,即工作日相对流量较高,周末流量偏低。如果我们能够自动且精准地识别出每个指标中存在的各个周期,那么就能更高效地对这些指标进行异常监控,及时发现偏离周期性的异常点,甚至可以准确地对这些指标的未来每个时刻的走势进行预测,从而提前进行资源规划。因此,异常检测和预测是周期检测的两个典型应用。此外,由于周期也是时间序列的典型特征之一,该周期的检测和识别也能广泛应用于时间序列之间关系的建模。

图1. 大数据平台运维场景部分监控指标示例(注:图中红色部分表示数据缺失)
然而,对云监控指标进行周期检测并非易事。图1展示了一部分指标的示例,我们发现这类指标具有如下特点:
(1)由于时序数据的复杂性,周期检测受到时序数据中除周期成分外的其他的成分的干扰,包括了趋势的变化(如缓缓增长或下降的趋势),噪音和异常点,甚至由于业务特性或采集问题可能出现大段的数据缺失。图1最左上角还展示了类似『稀疏型』的周期性数据。
(2)天周期、周周期、年周期可能交织存在且存在一些特例,如很多数据集中都有长周末(正常周末2天+额外1天)的现象。
(3)由于涉及的业务场景繁多,不同曲线的业务背景、模式、粒度等都存在较大差异。难以人工设定一些先验的周期信息。
(4)双十一、618等大促,小长假等特殊情况都会对周期的判别造成干扰。
(5)随着业务的发展,周期性并非一成不变而是具有一定动态性。
上述特点给周期的识别带来了很大的挑战。我们需要一套高效鲁棒的通用算法框架,能够自动识别出任意一条时间序列中存在的周期数量,并且准确计算每个周期的长度。
二、RobustPeriod周期检测框架介绍
现有的周期检测算法主要集中在基于周期图(Periodogram)的频域算法和基于自相关函数(ACF)的时域算法两个方向。然而这些算法要么无法很好处理长周期,要么容易受到趋势、噪音和异常值的影响,或者依赖先验的基准周期长度信息,抑或是无法处理多周期的情况,因此这些算法都无法很好地应对上面所提到的诸多挑战。
基于此,我们提出了RobustPeriod,一套具有鲁棒性的时间序列多周期检测通用框架。其基本流程如下图所示,主要包含三个关键步骤:

图2. RobustPeriod周期检测算法框架流程
(1)预处理阶段(Pre-processing)
我们使用线性差值法对缺失值进行填充以应对大段数据缺失的场景。同时使用HP滤波(Hodrick–Prescott trend filtering)对时间序列中的趋势项进行提取并剔除。
(2)多重周期的分解(Decoupling Multiple Periodicities)
为了解决多重周期交织在同一个时间序列中的问题,我们首先使用最大重复离散小波转换(Maximal overlap discrete wavelet transform, MODWT)分离出不同层次的周期性。MODWT具备的良好特性使得它可以应对任意长度的时间序列,同时可以很好地处理不平稳的时间序列和非高斯噪音。基于分解出的不同层次的周期成分和它们对应的小波方差(wavelet variance), 我们可以对这些周期成分进行强弱排序,并优先输出更显著的周期成分。
(3)单周期检测(Robust Single Periodicity Detection)
在完成了多重周期的分解后,接下来的问题就变成了如何准确地对单重周期进行检测。在这个阶段我们设计了一套称为Huber-ACF-Med的流程,它包含两个子步骤。首先是利用基于Huber-Periodogram的Fisher’s Test生成每个层次的周期长度候选项,然后再利用ACF对这些候选项进行验证优化,最终得到这条时间序列所包含的所有周期长度。
在我们的论文中,我们不仅从理论上对RobustPeriod的合理性进行了论证,同时在模拟数据集、公开数据集和阿里云计算平台的真实数据集中对我们的算法进行了充分的验证,利用消融分析验证了每一个步骤的重要性,并和其他的前沿经典算法如Siegel,AUTOPERIOD,Wavelet-Fisher进行了对比。结果显示,无论是在单周期还是多周期场景的检测中,我们的算法都取得了最优的效果。特别是在有趋势噪音和异常值的真实数据集中,我们的算法具有明显优势。
三、基于RobustPeriod构筑的TData/IAD时序异常检测和预测服务
前文提到,异常检测和预测是周期检测的两个典型应用,为了让RobustPeriod能在实际业务场景中发挥效用,我们将它整合到了阿里云大数据智能运维TData平台和达摩院决策智能IAD (Intelligent Anomaly Detection)平台,并且在它的基础上构筑出了时序异常检测和时序预测这两项通用在线服务。
(1)TData, IAD平台的时序异常检测
图3展示了时序异常检测服务的算法框架,主要包括周期检测、周期分解RobustSTL/RobustTrend, 和统计检验三大模块[2-9]。RobustPeriod作为核心前置模块决定了后续的算法分析链路,影响了最终检测的准确性。当RobustPeriod识别出某条时间序列的周期性后,我们基于各层次周期成分的长度,利用RobustSTL和RobustTrend分解算法准确分离出趋势项、周期项和残差项,进而更加准确地识别出曲线是否有偏移原有模式的异常点,满足用户不同场景、不同类型的异常检测需求。对于TData的用户来说,只需将指标接入并选择关注的异常类型,不需要具备任何机器学习基础,也不需要提供曲线的任何先验信息或标注,即可得到准确的检测结果。
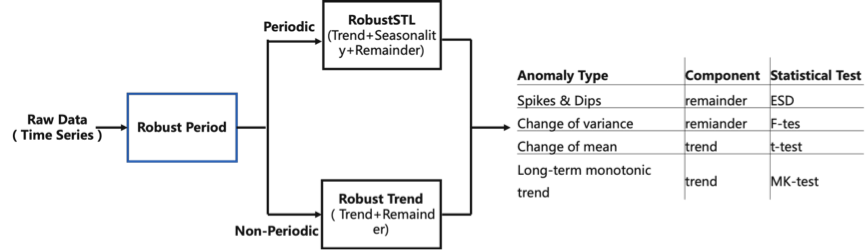
图3. TData时序异常检测算法框架
(2)TData, IAD平台的时序预测
图4展示了时序预测服务的算法框架,主要包括周期检测、预测和评估三大模块。预测模块作为RobustPeriod的下游,我们同样基于周期检测的结果采用了分而治之的思想。对于具有周期性的曲线使用了TBATS模型(Exponential smoothing state space model with Box-Cox transformation, ARMA errors, Trend and Seasonal components)进行预测,因为它可以高效处理复杂的周期成分。而对于那些被判别为不具备周期性的曲线,我们则直接利用经典的ARIMA模型进行预测。
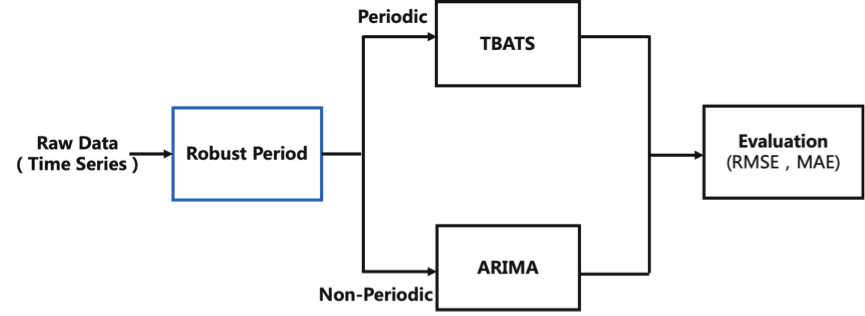
图4. TData时序预测算法框架
此外TData/IAD时序异常检测和时序预测服务的算法均搭建在阿里云之上,充分利用了云服务带来的性能优势和稳定性,即使面对海量的指标,分析流程也能在秒级完成。
四、最佳业务实践
阿里云大数据智能运维TData平台和达摩院决策智能IAD平台提供的时序异常检测和预测通用服务,接入成本低结果准确且运行稳定,目前已经为阿里云计算平台,阿里数据,搜索推荐等的多个BU的产品提供支持,这里我们列举了几例最佳实践给大家提供参考。
(1)MaxCompute数据质量异常检测(DQC)
MaxCompute是阿里云提供的一项面向分析的EB级别大数据计算服务,不仅服务于阿里集团、蚂蚁金服、菜鸟、优酷、高德等事业部,同时也为公共云和专有云用户提供计算能力。对于海量数据计算服务而言,数据准确性是数据质量的关键,也是所有离线系统加工时的第一保障要素。因此MaxCompute为用户提供了数据质量的异常校验功能,当产出的数据较往常模式有变化时,会通知用户或阻塞生产链路以防止数据污染扩散。
过去,用户需要为每一个计算任务手工配置数据质量校验规则,随着用户增长和业务体量的扩大,目前仅阿里巴巴内部每天运行的任务数就已经达到近千万,人工配置规则需要耗费过多人力,已经无法满足需求。因此MaxCompute为数据质量监控提供了动态阈值的功能,其底层即是Tdata异常检测服务。
MaxCompute上运行的数据计算任务与其对应的业务紧密相关,因此数据质量监控指标所展现出的模式也受其对应业务的影响。这也就意味着,不同数据计算任务的数据质量监控指标可能具有完全不同的周期性,例如大促期间菜鸟的业务高峰可能相对与淘宝天猫的电商业务高峰就具有一定滞后性。而我们的RobustPeriod则很好地解决了这类业务痛点,针对不同的任务曲线,我们都可以自动化地对其周期性进行精准计算和分解,从而提升异常检测的准确性。目前DQC的动态阈值功能已经覆盖了阿里集团多个BU,同时作为付费项目输出到了公共云,为更多外部用户提供了智能检测的服务。
(2)实时计算Flink作业流量预测和自动扩缩容(AutoScale)
实时计算Flink是阿里云基于Apache Flink 构建的企业级、高性能实时大数据处理系统。在阿里集团内部,目前全部核心业务已经用上Blink。除了技术大考双11之外,ET城市大脑实时计算规划着杭州交通,淘宝、天猫每天为数亿用户展现实时的“专属”页面。Flink作业通常需要长时间持续运行,数据和作业的流量会随着时间不断变化,因此所需的作业资源也会随之变化。如果按照作业低峰期的需求进行资源配置,作业将在流量高峰出现时计算延迟等异常情况而无法正常运行;而如果持续以作业高峰期的资源需求量进行配置,则会造成集群的资源使用率变低。因此我们需要自动化的、自适应地对Flink作业进行动态资源调优,以保证作业正常运行的前提下优化资源利用率,这就是Flink的自动扩缩容功能(AutoScale) 期望达到的目标。
早期的AutoScale版本属于被动扩缩容,即只有检测出作业出现延迟等因为资源问题导致的异常状态时,才会触发资源的调优。这种被动扩缩容的方式虽然能缓解作业的异常问题,但触发调整时作业已经受到了不同程度的影响。因此在阿里云内部使用的最新的版本中,TData为实时计算Flink的AutoScale功能提供了时序预测服务,使其能提前感知作业流量的变化趋势,从而提前对作业资源的配置进行规划和调整,减少作业因为资源问题出现的异常情况,同时最大限度地提升资源使用率。
(3) 阿里数据官智能洞察和商业数据的异常检测
DT阿里数据官是一款面向用户的对话式智能数据机器人,以自然语言交互的智能问答,帮助用户快捷的找到所需数据,随时随地掌握业务动向;以智能洞察为基础的数据报告支持用户订阅,每日推送至钉钉,助力高效决策。智能洞察旨在自动的从多维数据中发掘有价值的规律和信息传递给用户,其洞察结果往往可以协助回答业务关注的问题。比如:某品牌的销售趋势是否健康或其售卖产品的周期性?今天支付金额上升的主要原因有哪些?某关注指标和其他指标的相关性等。我们的鲁棒高效周期检测(Seasonality)以及其他洞察可以帮助业务同学深入挖掘业务状况,定位根因,为制定快速决策提供基础。同时,我们基于周期检测分解的时序异常检测的效果比原有算法相比有了巨大的提高,能力全量的在DT oneMonitor上线,合作也从“异常检测”扩大到了的“数据洞察”,“数据安全”等更加广阔的领域,让算法更强力和更广泛的为商业赋能。
(4) 搜索烽火台智能异常检测和智能化运维
搜索的监控系统之前是基于规则的阈值报警,面对周期性指标,毛刺和稀疏数据等复杂场景难以适用,导致大部分指标报警泛滥,给用户带来很大的困扰。于是搜索kmon同学基于高频报警场景联合达摩院算法尝试增加异常检测进行智能报警治理报警泛滥问题。在采用了IAD系统之后,各项异常检测有了很大的提高,基于周期性的指标波动算法也能很好的识别。
作者:张颖莹,文青松,孙亮,何凯,柯旻,蒋君伟
原文链接
本文为阿里云原创内容,未经允许不得转载






--WRITE_ROW_EVENT)












