简介: 本文介绍什么是云原生可观测性需求以及告警限制,介绍一站式云原生智能告警运维平台——SLS新版告警。
前言
本篇是SLS新版告警系列宣传与培训的第一篇,后续我们会推出20+系列直播与实战培训视频,敬请关注。
系列目录(持续更新)
- 一站式云原生智能告警运维平台——SLS新版告警发布!(本篇)
- 这才是可观测告警运维平台——20个SLS告警运维场景
- 可观测告警运维系统调研——SLS告警与多款方案对比
1. 云原生观测告警
1.1. 业务发展对开发运维的挑战
现代业务发展对开发运维提出了新的挑战,具体如下:
1.1.1. 业务:稳定性要求越来越高
参考AIOps的目标与挑战,随着越来越多的业务云化数字化,例如今年开始大热的在线教育,任何一个稳定性、可靠性等异常都将给业务带来巨大的损失。要求SLA(服务可靠性)越高越好、MTTR(问题平均修复时间)和Cost(成本)越低越好。
在各大云厂商,也指定了非常多的稳定性制度和要求,例如1-5-10(1分钟发现问题,5分钟定位问题,10分钟解决问题)准则。
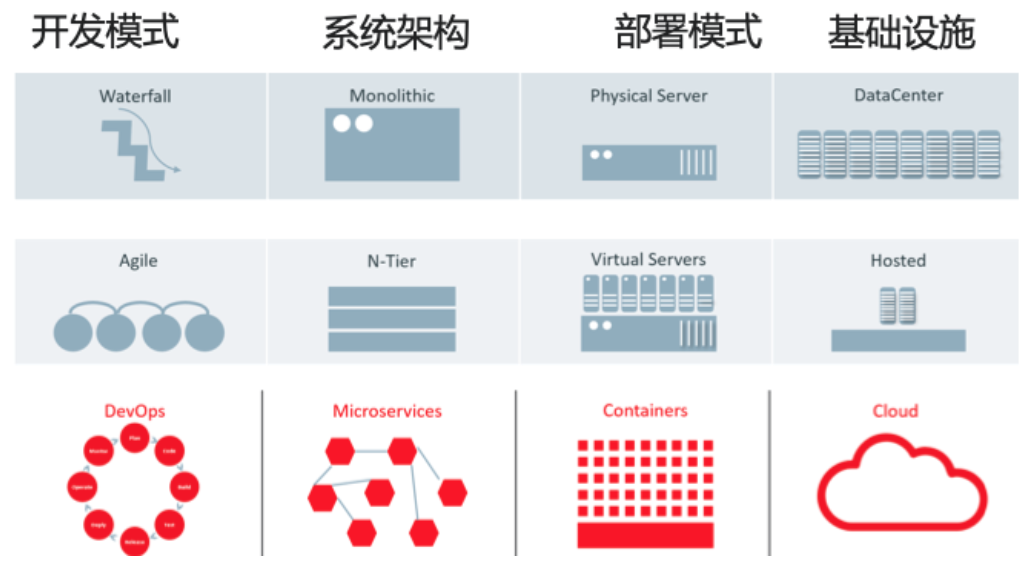
1.1.2. 系统:复杂性越来越高
随着开发模式(敏捷开发、DevOps)、系统架构(分层、微服务)、部署模式(容器化、云原生)、和基础设施(多云、混合云)的快速演变,系统变得原来越复杂。当系统出现问题时,如何发现问题、排查定位原因、解决问题就越来越困难。从监控运维的角度,系统的可观测性也逐步成为是一个基本要求。
1.1.3. 工程师:职责越来越大
因为前述原因,系统从研发集成到上线前后的各个阶段,有大量的工作需要做,不同人员参与的协同会大大降低响应速度,越来越多的公司要求一专多能。开发、测试、运维融合逐步成为趋势,开发人员逐步开始承担测试的工作、部分的运维甚至运营的工作。

随着业务数字化时代的到来,可预见到运营角色更深入的与开发、运维角色融合也是一个趋势,也就是说开发工程师未来投入到运营(Ops)的时间也会逐步增加。

1.2. 什么是可观测性
传统监控一般以一个白盒方式监控系统,专注发现核心指标异常,例如500错误,客户订单成功率等。一般这种问题发生时,准取性极高(例如大量500错误,大量订单失败,一定表示SLA有问题),一般也都比较严重。因为是黑盒,进一步排错和修复时间和成本极大,往往给开发运维人员带来极大压力。
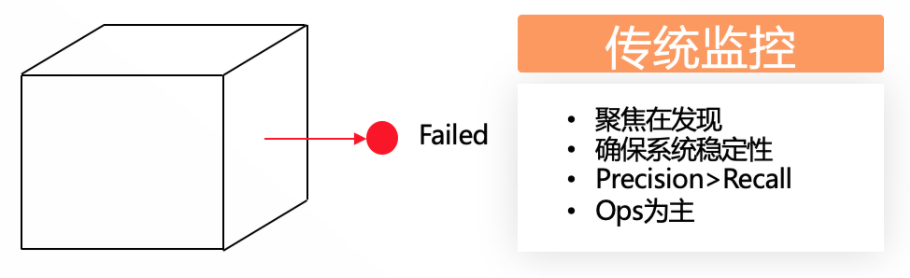
根据海恩法则(Heinrich's Law),每一起严重事故背后,必然有29次轻微事故和300起未遂先兆以及1000起事故隐患。如果提前处理那些不那么严重的问题、先兆或者隐患,其实是可以避免后续的严重事故的,也就避免了其带来的巨大压力和损失。

可观测性是对传统监控的升级,其要求进行白盒化监控,对各种可能的隐患、先兆、不严重问题进行监测、跟踪处理。且不再只是在发布后,而是在开发、测试阶段就进行。

因此对比两者,可以发现,传统监控主要由SRE人员从系统外部进行监控,关注指标,发现问题(Know What);而可观测性由DevOps人员从系统内部进行监控,关注指标、日志和跟踪等数据各种数据,发现问题并挖掘原因(Know Why)。
1.3. 可观测性的挑战
根据AIOps平台方案选择,可知各种监控数据(指标、日志、跟踪等)的中台都有各种方案,同样的监控系统也有非常多的选择。

主要挑战就是:
- 数据覆盖不完整、存在数据孤岛(无法关联协同)
- 使用门槛高,不人性化
1.4 告警运维系统的痛点
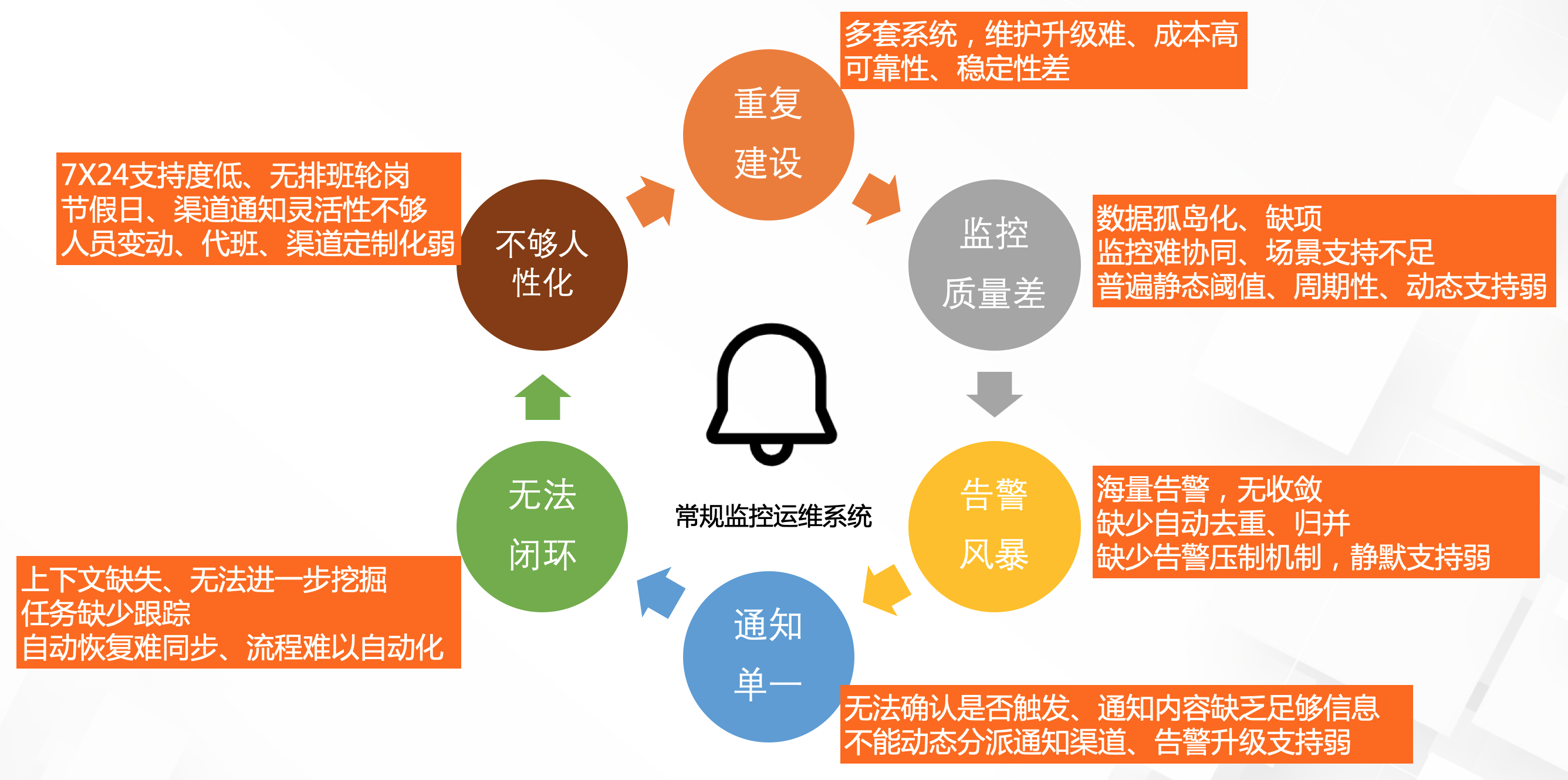
可观测性对于告警监控运维系统是有很高的要求的,但现状却不容乐观,我们可以看到常规监控运维系统存在如下6大痛点:
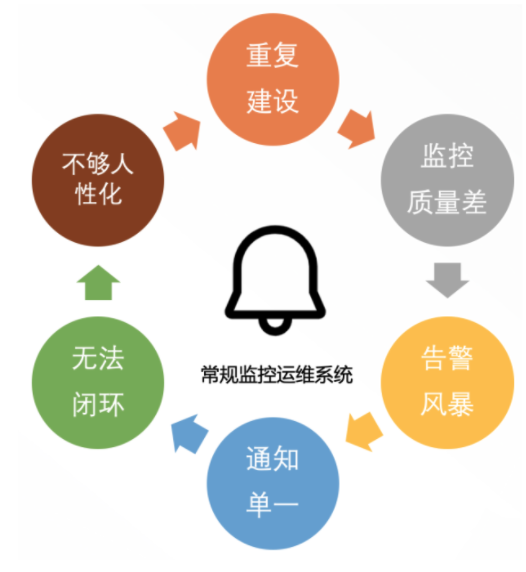
具体展开细化如下:
2. 什么是SLS告警运维系统
2.1. SLS(日志服务)是什么
SLS是阿里云上云原生观测分析平台,为Log/Metric/Trace等数据提供大规模、低成本、实时平台化服务。目前对内已经是“阿里巴巴 + 蚂蚁金服”系统的数据总线,数年稳定支撑双十一、双十二、新春红包活动。对外则已经服务阿里云几十万企业客户。

2.2. SLS新版告警——一站式智能告警运维系统
SLS新版告警在中国站等发布公测(国际站预计4月发布),新版在SLS云原生可观测性平台上提供了一站式智能运维告警系统。新版告警提供对日志、时序等各类数据的告警监控,亦可接受三方告警,对告警进行降噪、事件管理、通知管理等,新增40+功能场景,充分考虑研发、运维、安全以及运营人员的告警监控运维需求。
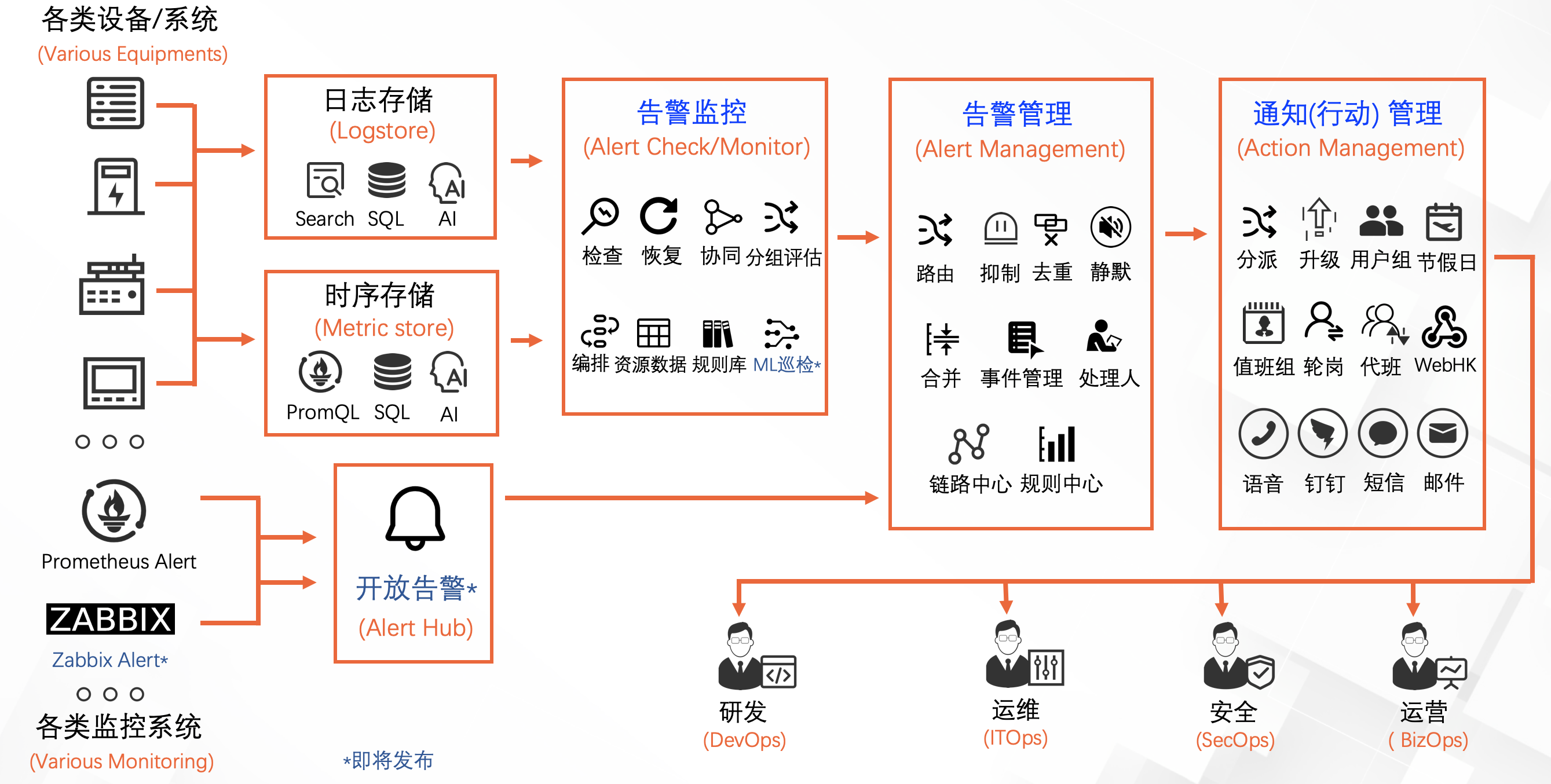
可以看到新版告警由4个模块组成:告警监控、告警管理、通知(行动)管理以及即将发布的开放告警组成。下面逐步介绍各个模块的作用。
2.3. 优势
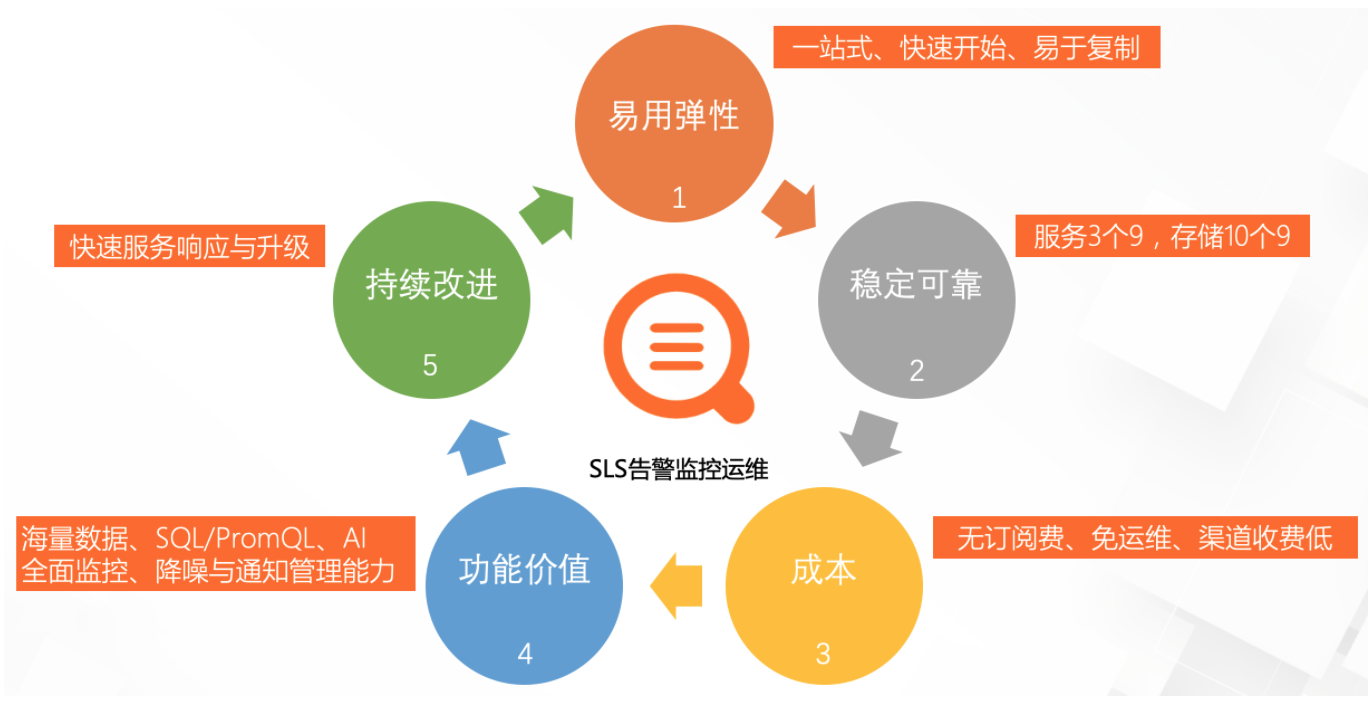
使用SLS新版告警,可以有效缓解前面提到的告警运维系统的痛点,和其他自建、商业化或云厂商提供的方案比,具备如下5大优势:
2.4. 告警监控概述
通过告警监控规则配置,定期检查评估,查询统计源日志、时序存储,按照监控编排逻辑,评估结果,并触发告警或恢复通知,最终发送给告警策略。
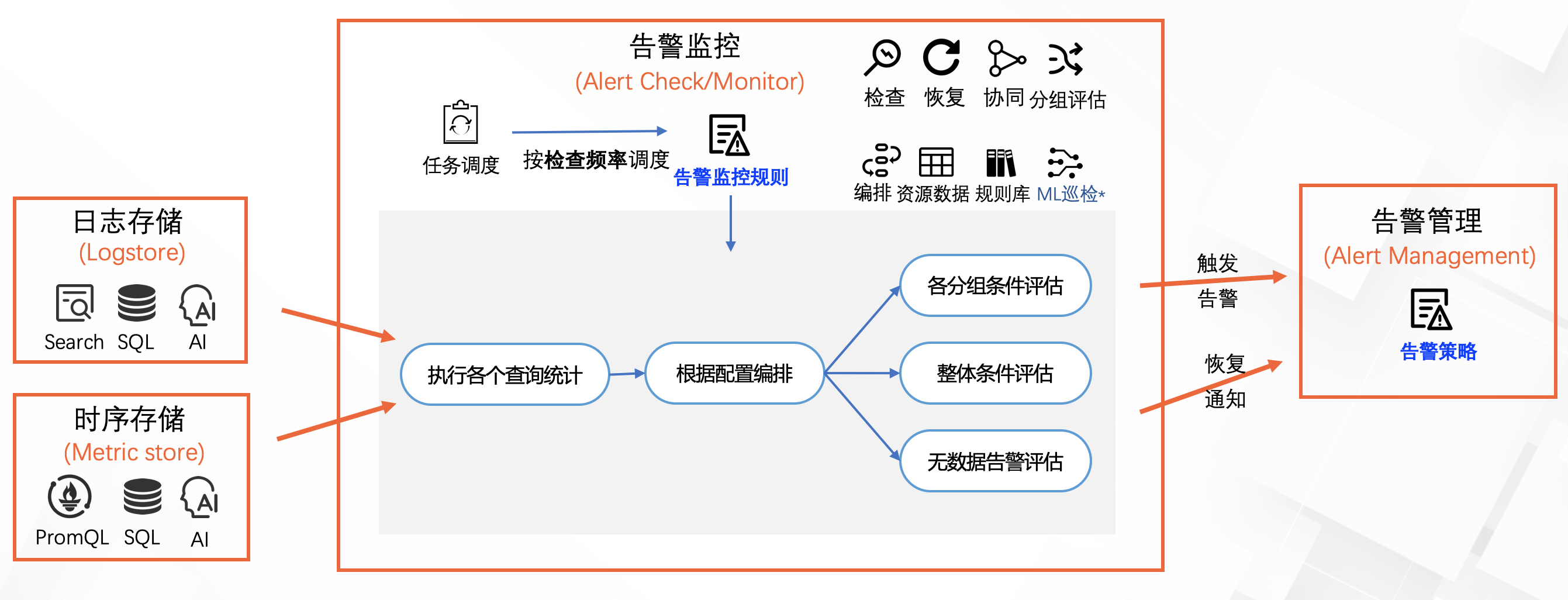
告警监控提供的功能可以分为如下3类:

基础能力
其中值得强调的是SLS告警监控的基础能力支持大规模日志/时序/跟踪等实时监控,而查询统计语法也是使用通用统一的SQL(并扩展)的方式提供。也就是SQL = Search + PromQL + SQL92。
例如对特定机器是否在线监控,可以使用SQL、PromQL、或者两者子查询协同、甚至多层嵌套使用机器学习的算法来找出异常。
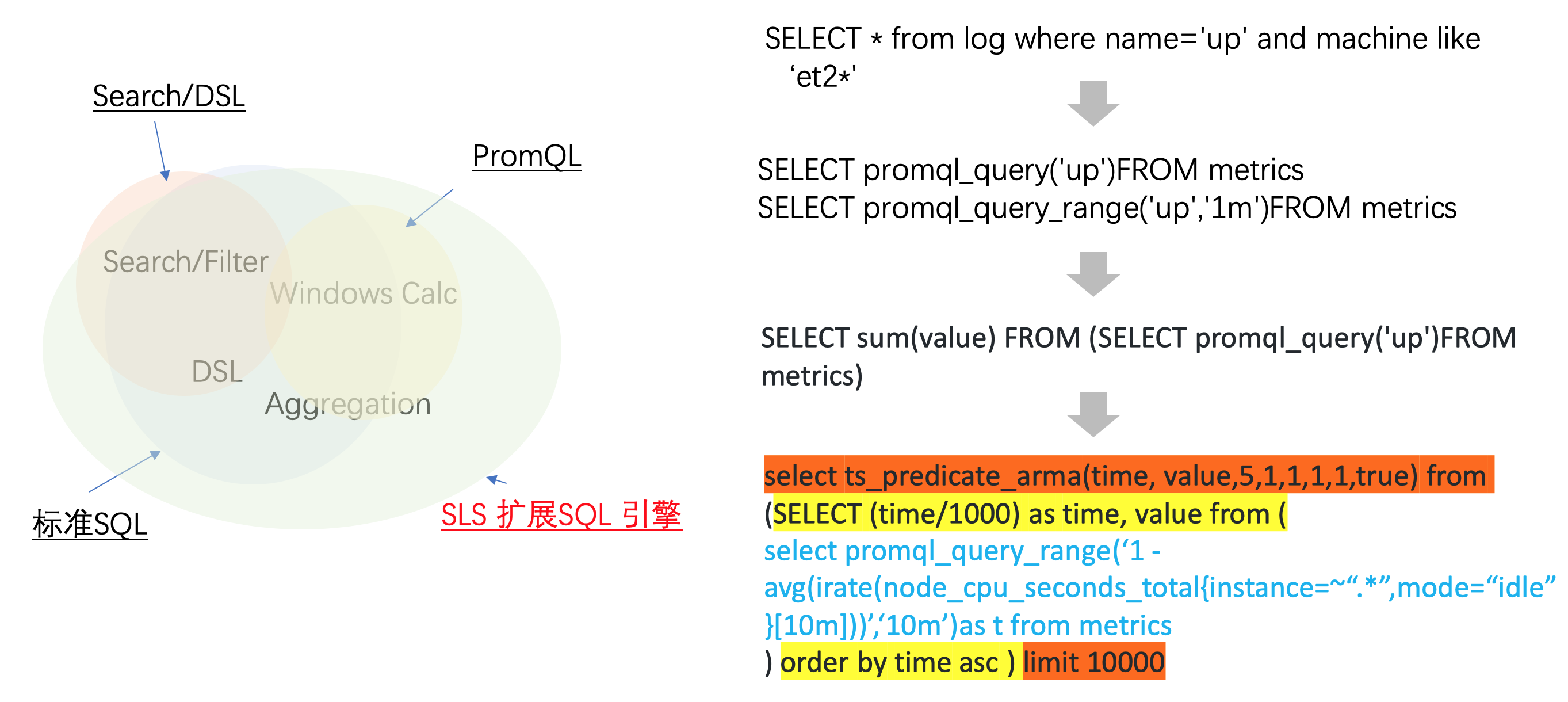
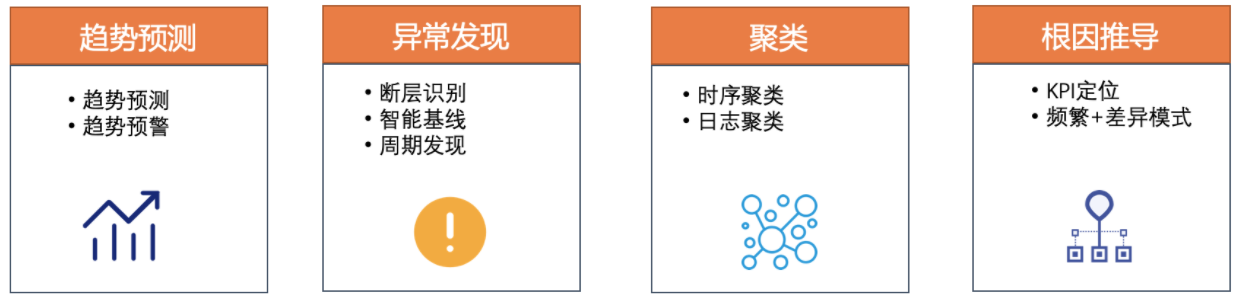
其中机器学习算法是直接在SQL扩展方式提供,覆盖了以下4个场景:
2.5. 告警管理
每一个告警监控规则会将触发的告警(含恢复通知)发送给一个预先配置的告警策略,通过告警策略配置,对所有接受到的告警进行路由分派、抑制、去重、静默、合并操作,后再分派给特定行动策略。
通过告警中心控制台可以管理告警的状态(包括设置处理人),和查看告警链路与规则态势。
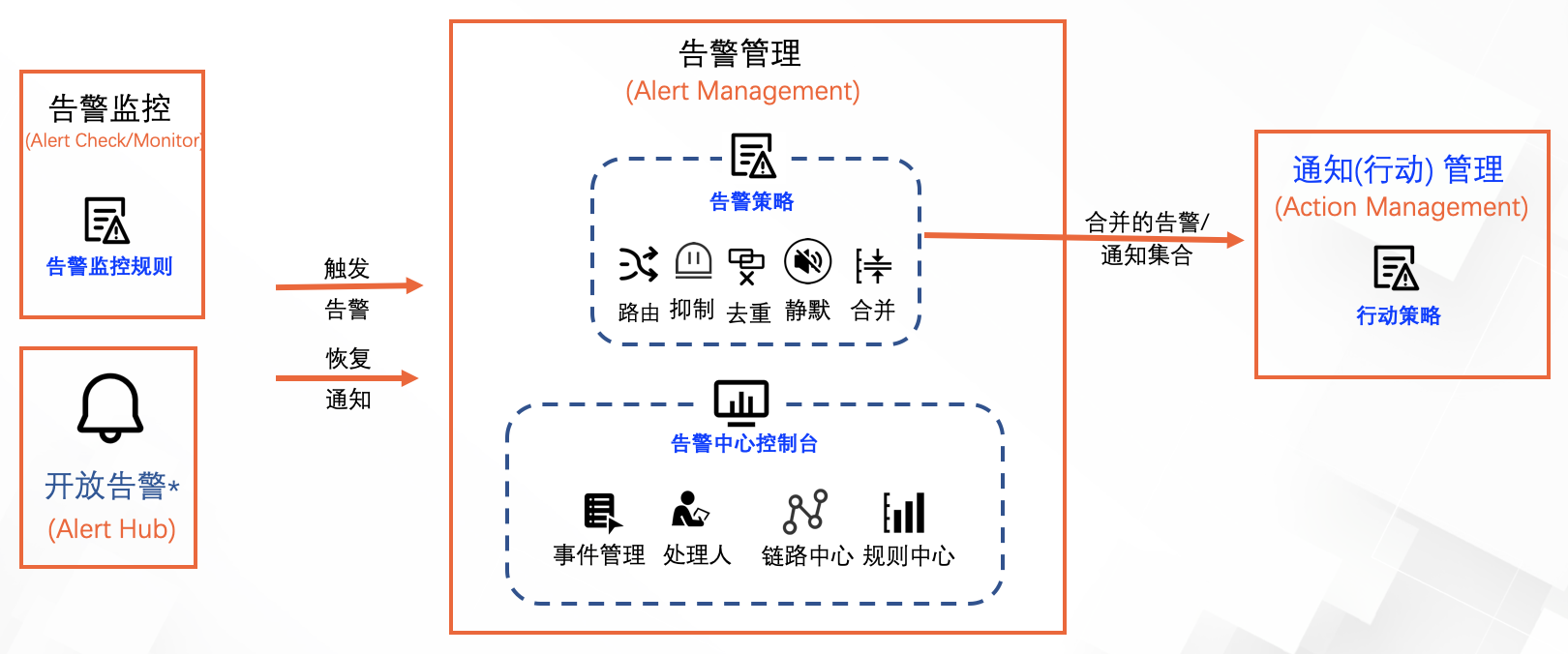
告警管理提供的功能也可以分为3类,如下:

2.6. 行动(通知)管理
每一个告警策略根据配置分派合并后将每个告警合并集合发送给特定的行动策略。由行动策略根据配置动态分派给特定通知渠道通知到特定的人/组/值班组,也支持告警未及时处理下的通知升级。
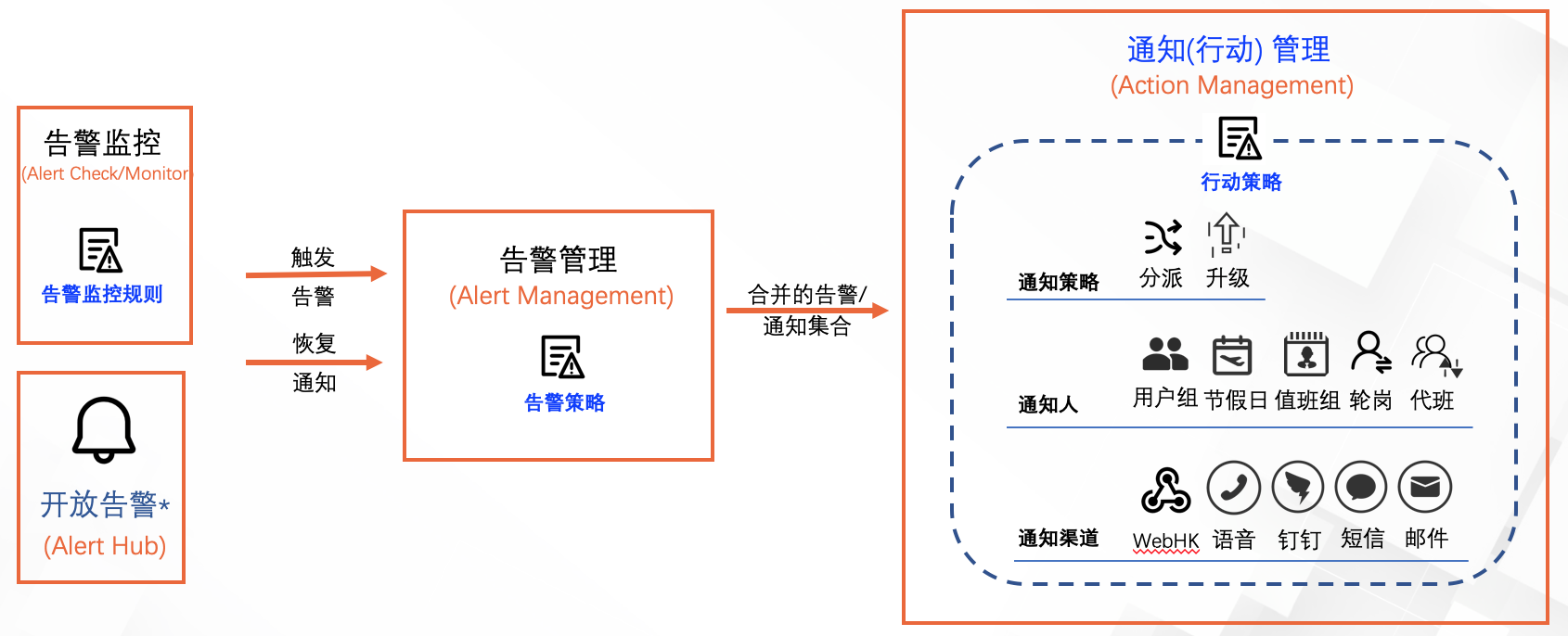
行动(通知)管理提供的功能也可以分为3类,如下:

原文链接
本文为阿里云原创内容,未经允许不得转载。



















