简介: 本文介绍数据仓库产品作为企业中数据存储和管理的基础设施,在通过分层存储技术来降低企业存储成本时的关键问题和核心技术。

作者 | 沄浩、士远
来源 | 阿里技术公众号
一 背景
据IDC发布的《数据时代2025》报告显示,全球每年产生的数据将从2018年的33ZB增长到2025年的175ZB,平均每天约产生491EB数据。随着数据量的不断增长,数据存储成本成为企业IT预算的重要组成部分。例如1PB数据存储一年,全部放在高性能存储介质和全部放在低成本存储介质两者成本差距在一个量级以上。由于关键业务需高性能访问,因此不能简单的把所有数据存放在低速设备,企业需根据数据的访问频度,使用不同种类的存储介质获得最小化成本和最大化效率。因此,把数据存储在不同层级,并能够自动在层级间迁移数据的分层存储技术成为企业海量数据存储的首选。
本文介绍数据仓库产品作为企业中数据存储和管理的基础设施,在通过分层存储技术来降低企业存储成本时的关键问题和核心技术。
1 什么是分层存储
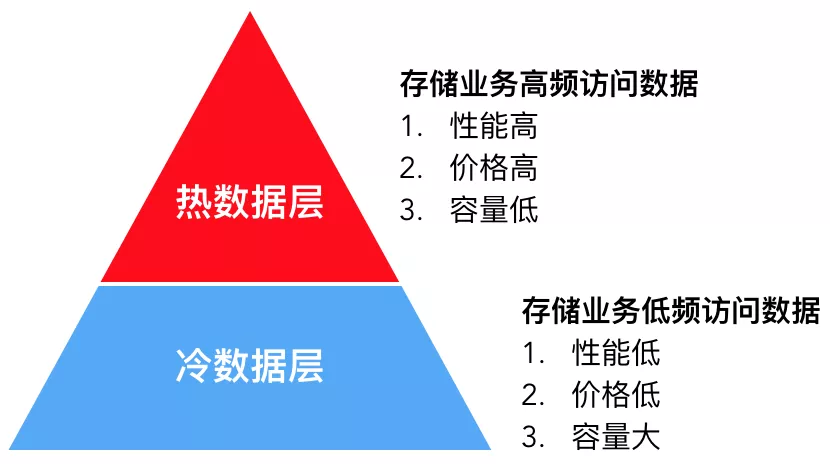
分层存储顾名思义,就是把数据分为高频访问的热数据和低频访问的冷数据,并分别存储在热数据层和冷数据层,达到性能与成本的平衡。
热数据层采用高性能存储介质,单位成本高,为控制预算一般容量较小,只存储关键业务数据,例如ERP,CRM数据,或者最新的订单数据等。
冷数据层则存储非关键业务数据,例如审计日志,运行日志等,或历史沉淀数据,例如一个月前的订单数据。此部分数据体量大,访问频度低,性能要求不高,因此采用单位成本低,容量大的存储介质来降低成本。同时,随着时间流逝,部分热数据访问频度会降低(一般称为数据降温),此时存储系统能够自动迁移该部分数据到冷数据层来降低成本。
2 数据仓库分层存储面临的挑战
数据仓库产品在实现分层存储能力时,面临的几个核心挑战如下:
- 选择合适的存储介质。存储介质既要满足性能、成本需求,还要满足可靠性、可用性、容量可扩展、运维简单等需求。
- 业务上的冷热数据,如何在分层存储中定义?即如何描述哪部分是热数据,哪部分是冷数据。
- 冷热数据如何迁移?随着时间流逝,业务上的热数据降温为冷数据后,数据仓库如何感知温度的变化并执行数据迁移来降低存储成本。
- 如何加速冷数据的访问?冷数据仍然会被访问,比如因法规政策要求,用户需对三个月前数据进行修订,或者需要对过去一年的数据进行统计分析来进行历史回顾和趋势分析。由于冷数据体量大,查询涉及的数据多,存储介质性能低,如果不进行优化,对冷数据的元信息,内容访问可能出现瓶颈影响业务使用。
二 数据仓库分层存储关键技术解析
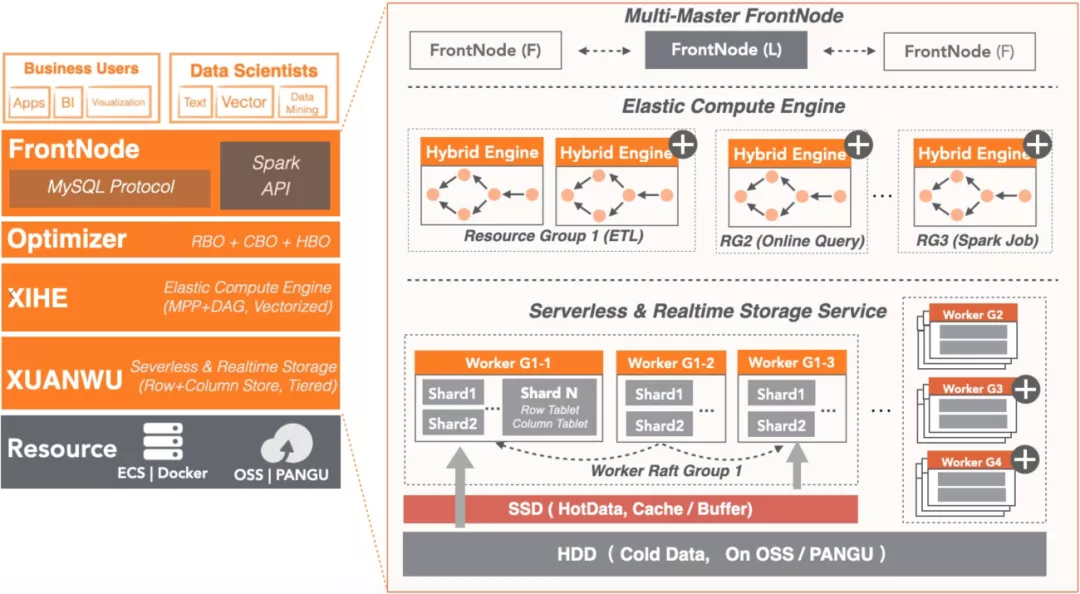
本章将以阿里云数据仓库AnalyticDB MySQL版(下文简称ADB)为原型介绍如何在数据仓库产品中实现分层存储,并解决其核心挑战。ADB的整体架构分为三层:
- 第一层是接入层:由多个前端节点构成,主要负责接入用户查询,进行SQL解析、优化、调度。
- 第二层是计算引擎层:由多个计算节点组成,负责执行用户查询。
- 第三层是存储引擎层:由多个存储节点组成,用户数据按Shard切片存储,每个Shard有多个副本保证高可靠和高可用。
1 冷热数据存储介质的选择
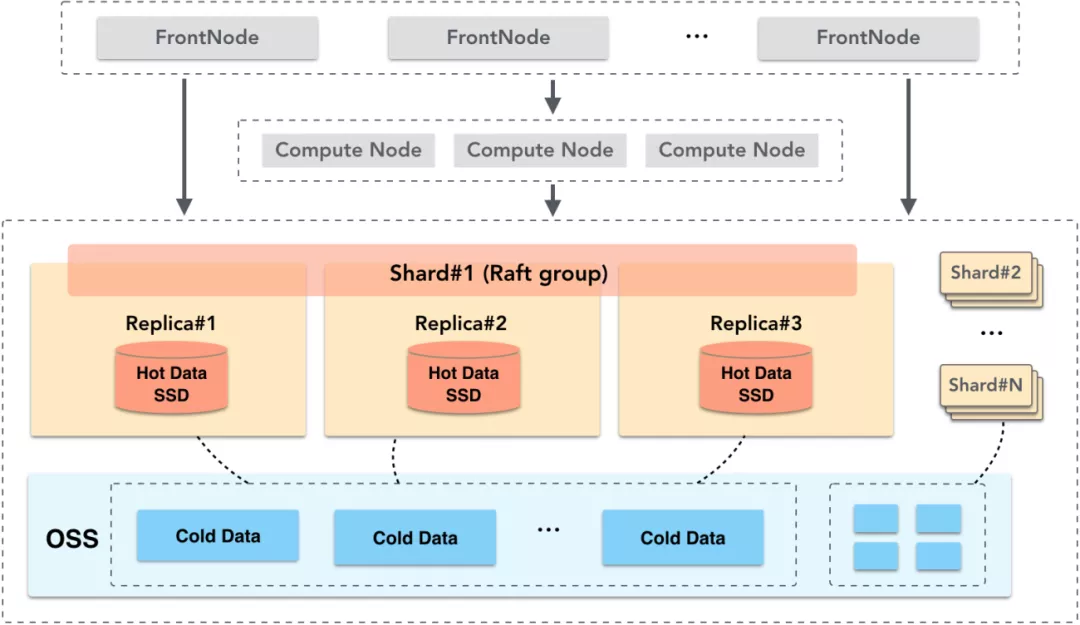
对于业务上的热数据,需采用高性能存储介质满足其快速查询需求。SSD相对HDD来说,成本较高,但其具有高IOPS和高带宽的特性,因此ADB把热数据层建立在SSD上,并使用数据多副本机制,出现存储节点异常时,通过切换服务节点来保证高可靠和高可用。
业务上的冷数据,一般是历史沉淀的业务数据或日志数据,这些数据体量大,访问频度低,因此容量大、成本低是存储介质的主要选择因素。对于冷数据层,ADB选择建立在阿里云OSS上。阿里云对象存储服务OSS作为阿里云提供的海量、低成本、高持久性的云存储服务,其数据设计持久性不低于99.9999999999%,服务可用性不低于99.995%。OSS提供的这些特性满足了冷数据层对成本和可靠性的需求,同时相对于自己维护HDD磁盘,OSS自身具有容量无限扩展能力,满足海量数据存储需求。并且OSS可以远程访问,因此存储节点的副本间可以共享数据来进一步降低成本。
2 冷热数据定义问题
业务自身对冷热数据的定义比较明确。比如企业中一些需要高频访问的CRM、ERP数据均为热数据。而对于审计日志,或数天前的订单数据,其访问频度低,则可定义为冷数据。核心问题是,业务上的这些数据,如何在分层存储中描述其冷热属性并保证存储位置的准确性。例如企业促销活动,大量用户正在线上进行业务交互,此时如果分层存储错误的把客户信息、商品信息等关键数据迁移到冷区,则会引起相关查询性能受损,最终出现客户登录受阻,客户点击失败等业务异常,导致企业受损。ADB解决这个问题的方法是在用户建表时指定存储策略(storage_policy)来精确关联业务上的冷热数据和分层存储中的冷热存储,下面是示例。
全热表
所有数据存储在SSD并且不会降温,适用于全表数据被频繁访问,且对访问性能有较高要求的场景,比如CRM、ERP数据。
Create table t1(id int,dt datetime
) distribute by hash(id)
storage_policy = 'HOT';全冷表
所有数据存储在OSS,适用于体量大,访问频度低,需要减少存储成本的场景,比如审计日志数据。
Create table t2(id int,dt datetime
) distribute by hash(id)
storage_policy = 'COLD';冷热混合表
适用于数据冷热有明显时间窗口的场景。例如最近7天的游戏日志数据,广告点击数据等需高频访问,作为热数据存储,而7天前的数据可降温为冷数据,低成本存储。
注:冷热混合表需配合表的分区使用。除storage_policy外,还需指定hot_partition_count属性。hot_partition_count指按分区值倒序,取最大N个分区为热分区,其余为冷分区。下例中,表按天分区,hot_partition_count = 7表示分区值最大的7个分区,也就是最近7天的数据为热数据。
Create table t3(id int,dt datetime
) distribute by hash(id)
partition by value(date_format(dt, '%Y%m%d'))
lifecycle 365
storage_policy = 'MIXED' hot_partition_count = 7;修改冷热策略
随业务的变化,表的访问特性可能发生变化,企业可以随时修改表的存储策略来适应新的存储需求。
(1)由热表修改为冷表:
Alter table t1 storage_policy = 'COLD';(2)修改热分区的个数,修改为最近14天的数据为热数据:
Alter table t3 storage_policy = 'MIXED' hot_partition_count = 14;3 冷热数据自动迁移问题
随时间流逝,热数据的访问频度降低,降温为冷数据。比如一些日志数据,在数天后就很少再访问,分层存储需把这部分数据由热数据层迁移到冷数据层来降低成本。这里的核心问题是如何知道哪部分数据的温度降低了需要迁移?下面通过一个冷热混合表,来说明ADB解决该问题的方法。如下是一张日志表,最近三天数据为热数据,满足高性能在线查询需求,三天前数据为冷数据,低成本存储并满足低频访问需求。
Create table Event_log (event_id bigint,dt datetime,event varchar
) distribute by hash(event_id)
partition by value(date_format(dt, '%Y%m%d')) lifecycle 365
storage_policy = 'MIXED' hot_partition_count = 3;在本例中,表首先按天分区。
partition by value(date_format(dt, '%Y%m%d')) lifecycle 365
并定义冷热策略为混合模式,最新3天的数据是热数据。
storage_policy = 'MIXED' hot_partition_count = 3
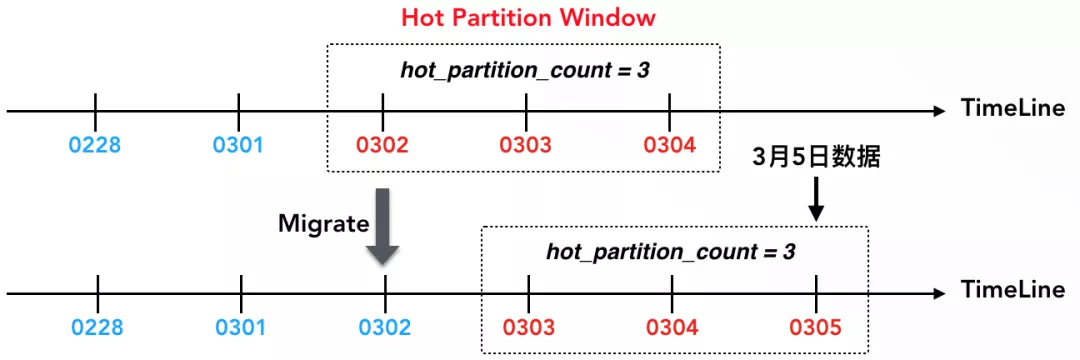
在ADB中,冷热数据以分区为最小粒度,即一个分区要么在热区,要么在冷区,然后通过热分区窗口来判定某个分区是否为热分区(表属性中的hot_partition_count定义了热分区窗口的大小)。在本例中,假定当前日期是3月4日,则3月2日、3日、4日这三天的数据处于热分区窗口中,因此是热分区。当写入3月5日的数据后,则3月3日、4日、5日这三天数据组成了新的热分区窗口,3月2日数据降温为冷数据,后台会自动执行热冷迁移,把3月2日的数据由热区迁移到冷区。通过热分区窗口,客户根据业务场景可以明确定义冷热边界,一旦数据降温则自动迁移。
4 冷数据访问性能问题
冷数据存储在OSS上,OSS是远程存储系统并通过网络访问,延迟较高。例如判断文件是否存在,获取文件长度等元信息操作,单次交互的访问延迟在毫秒级别。同时,OSS带宽有限,一个账号下整体只有GB级别带宽,提供的整体QPS也只有数十万,超过后OSS就会限流。数据仓库内部存储着大量文件,如果不对OSS访问做优化,则会出现查询异常。例如查询可能涉及数百万个文件,仅仅获取这些文件的元信息就会达到OSS的QPS上限,最终导致查询超时等异常,因此需对OSS的访问进行优化来保证业务的可用性并提高查询性能。如下对元信息访问优化和数据访问优化分别介绍。
元信息访问优化
ADB作为数据仓库,底层存储了大量的数据文件和索引文件。ADB优化元信息访问的方法是对文件进行归档,即把一个分区内的所有文件打包在一个归档文件中,并提供一层类POSIX的文件访问接口,通过这个接口去读取文件内容。
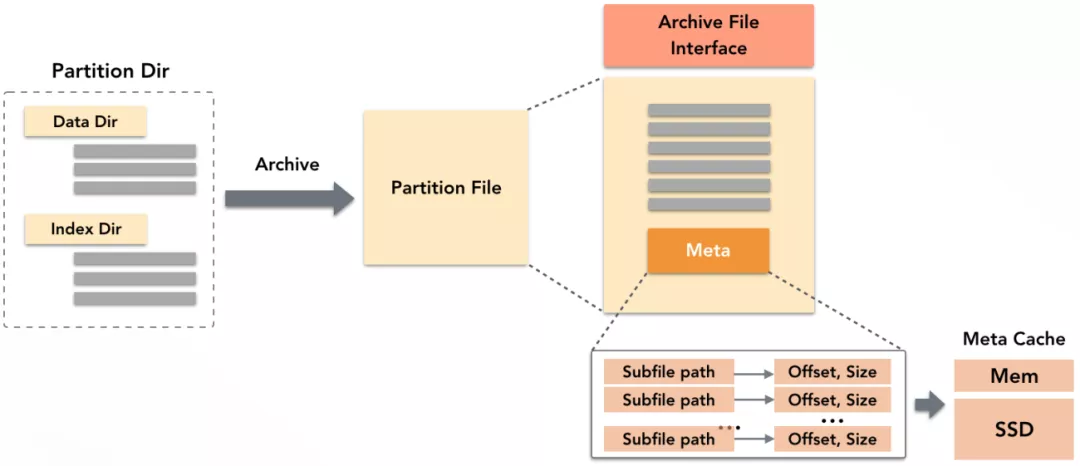
归档文件的Meta里内存储了每个子文件的偏移和长度等元信息。读取时,先加载归档文件的Meta,只需要一次交互即可拿到所有子文件元信息,交互次数降低数百倍。为进一步加速,ADB在存储节点的内存和SSD上分别开辟了一小块空间缓存归档文件的Meta,加载过即无需再访问OSS获取元信息。同时,归档后只需一个输入流便可读取所有子文件数据内容,避免为每个子文件单独开启输入流的开销。
数据访问优化
查询中,无论是扫描索引,还是读取数据块,都需要读取OSS上文件的内容,而OSS无论访问性能还是访问带宽都有限。为加速文件内容的读取,ADB存储节点会自动利用SSD上的一块空间做数据Cache,且Cache的上层提供了类POSIX的文件访问接口,数据扫描算子(Table Scanner)可以像访问普通文件一样访问Cache中的内容。
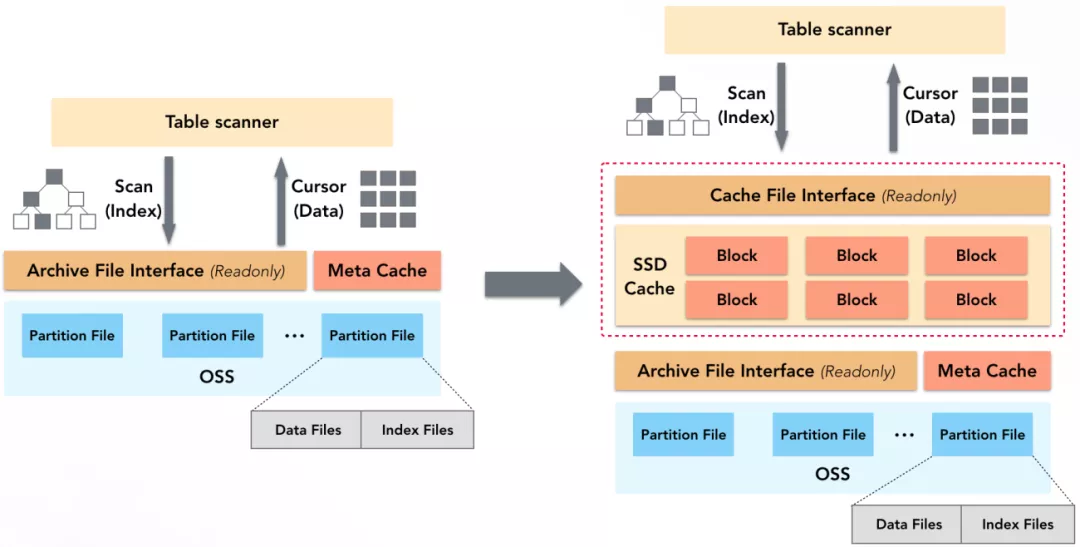
查询中对OSS的所有访问(索引、数据等)都可借助SSD Cache加速,只有当数据不在Cache中时才会访问OSS。针对这块Cache,ADB还做了如下优化:
- 多粒度的Cache Block,加载元信息时使用较小的Block,加载数据时使用较大的Block,以此提高Cache空间利用率。
- 元数据预热,自动加载数据和索引的元数据到Cache中并锁定,以实现元数据高效访问。
- 基于冷热访问队列的类LRU算法,实现无锁化高性能换入换出。
- 自动IO合并,相邻数据的访问合并为一个请求,减少与OSS的交互次数。
三 总结
随着企业数据量的不断增长,存储成本成为企业预算中的重要组成部分,数据仓库作为企业存储和管理数据的基础设施,通过分层存储技术很好的解决了企业中存储成本与性能的平衡问题。对于分层存储技术中的关键挑战,本文以云原生数据仓库AnalyticDB MySQL为原型,介绍了其如何通过冷热策略定义,热分区窗口,文件归档,SSD Cache来解决冷热数据定义,冷热数据迁移,冷数据访问优化等关键问题。
原文链接
本文为阿里云原创内容,未经允许不得转载。

..doc...)

















