简介:StreamNative 联合创始人翟佳在本次演讲中介绍了下一代云原生消息流平台 Apache Pulsar,并讲解如何通过 Apache Pulsar 原生的存储计算分离的架构提供批流融合的基础,以及 Apache Pulsar 如何与 Flink 结合,实现批流一体的计算。
Apache Pulsar 相对比较新,它于 2017 年加入 Apache 软件基金会,2018 年才从 Apache 软件基金会毕业并成为一个顶级项目。Pulsar 由于原生采用了存储计算分离的架构,并且有专门为消息和流设计的存储引擎 BookKeeper,结合 Pulsar 本身的企业级特性,得到了越来越多开发者的关注。今天的分享分为 3 个部分:
- Apache Pulsar 是什么;
- Pulsar 的数据视图;
- Pulsar 与 Flink 的批流融合。
一、Apache Pulsar 是什么
下图是属于消息领域的开源工具,从事消息或者基础设施的开发者对这些一定不会陌生。虽然 Pulsar 在 2012 年开始开发,直到 2016 年才开源,但它在跟大家见面之前已经在雅虎的线上运行了很长时间。这也是为什么它一开源就得到了很多开发者关注的原因,它已经是一个经过线上检验的系统。

Pulsar 跟其他消息系统最根本的不同在于两个方面:
- 一方面,Pulsar 采用存储计算分离的云原生架构;
- 另一方面,Pulsar 有专门为消息而设计的存储引擎,Apache BookKeeper。
架构
下图展示了 Pulsar 存储计算分离的架构:
- 首先在计算层,Pulsar Broker 不保存任何状态数据、不做任何数据存储,我们也称之为服务层。
- 其次,Pulsar 拥有一个专门为消息和流设计的存储引擎 BookKeeper,我们也称之为数据层。
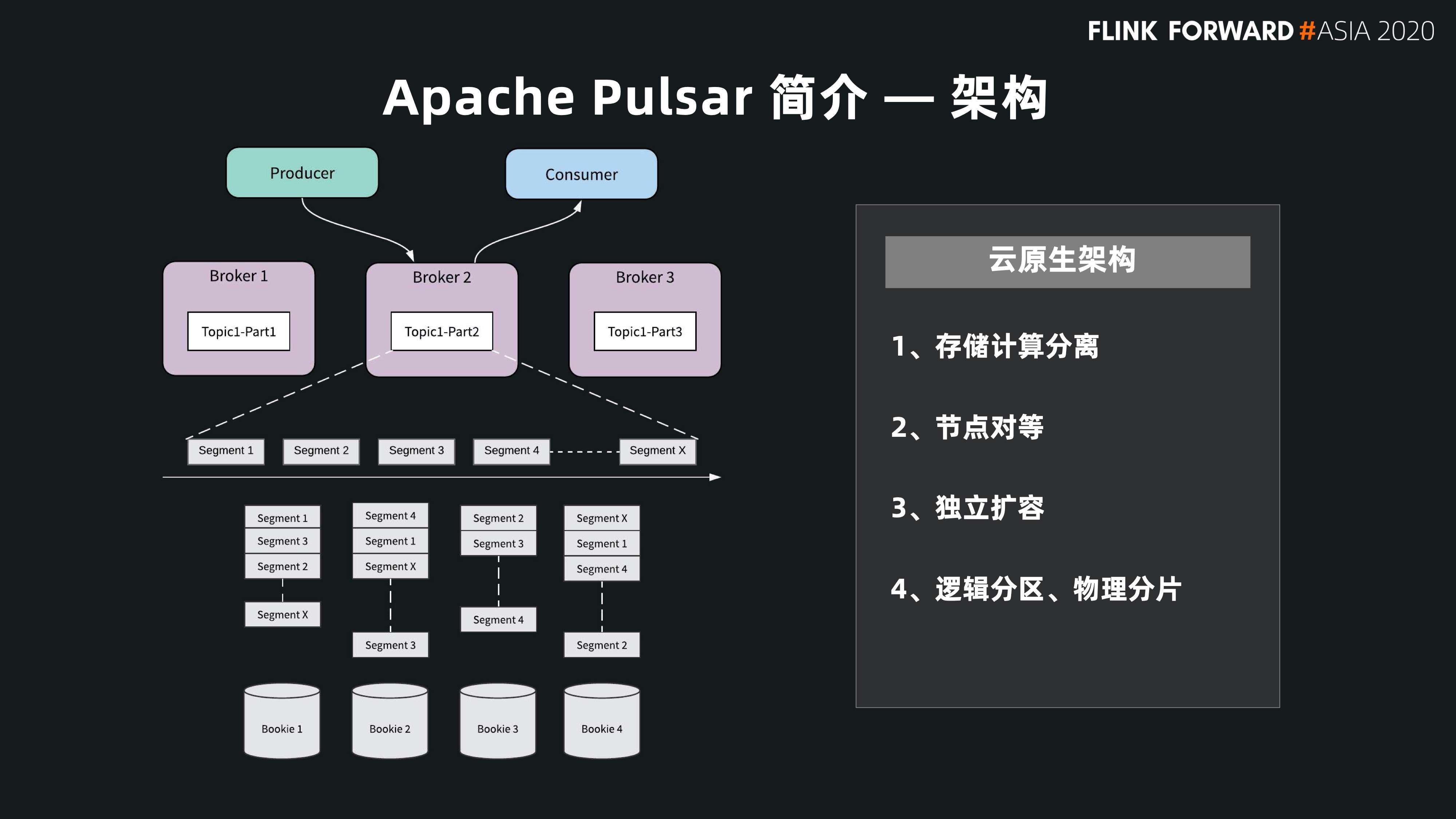
这个分层的架构对用户的集群扩展十分方便:
- 如果想要支持更多的 Producer 和 Consumer,可以扩充上面无状态的 Broker 层;
- 如果要做更多的数据存储,可以单独扩充底层存储层。
这个云原生的架构有两个主要特点:
- 第一个是存储计算的分离;
- 另外一个特点是每一层都是一个节点对等的架构。
从节点对等来说,Broker 层不存储数据,所以很容易实现节点对等。但是 Pulsar 在底层的存储也是节点对等状态:在存储层,BookKeeper 没有采用 master/slave 这种主从同步的方式,而是通过 Quorum 的方式。
如果是要保持多个数据备份,用户通过一个 broker 并发地写三个存储节点,每一份数据都是一个对等状态,这样在底层的节点也是一个对等的状态,用户要做底层节点的扩容和管理就会很容易。有这样节点对等的基础,会给用户带来很大的云原生的便捷,方便用户在每一层单独扩容,也会提高用户的线上系统的可用性和维护性。
同时,这种分层的架构为我们在 Flink 做批流融合打好了基础。因为它原生分成了两层,可以根据用户的使用场景和批流的不同访问模式,来提供两套不同的 API。
- 如果是实时数据的访问,可以通过上层 Broker 提供的 Consumer 接口;
- 如果是历史数据的访问,可以跳过 Broker,用存储层的 reader 接口,直接访问底层存储层。
存储 BookKeeper
Pulsar 另一个优势是有专门为流和消息设计的存储引擎 Apache BookKeeper。它是一个简单的 write-ahead-log 抽象。Log 抽象和流的抽象类似,所有的数据都是源源不断地从尾部直接追加。
它给用户带来的好处就是写入模式比较简单,可以带来比较高的吞吐。在一致性方面,BookKeeper 结合了 PAXOS 和 ZooKeeper ZAB 这两种协议。BookKeeper 暴露给大家的就是一个 log 抽象。你可以简单认为它的一致性很高,可以实现类似 Raft 的 log 层存储。BookKeeper 的诞生是为了服务我们在 HDFS naming node 的 HA,这种场景对一致性要求特别高。这也是为什么在很多关键性的场景里,大家会选择 Pulsar 和 BookKeeper 做存储的原因。
BookKeeper 的设计中,有专门的读写隔离,简单理解就是,读和写是发生在不同的磁盘。这样的好处是在批流融合的场景可以减少与历史数据读取的相互干扰,很多时候用户读最新的实时数据时,不可避免会读到历史数据,如果有一个专门为历史数据而准备的单独的磁盘,历史数据和实时数据的读写不会有 IO 的争抢,会对批流融合的 IO 服务带来更好的体验。

应用场景
Pulsar 场景应用广泛。下面是 Pulsar 常见的几种应用场景:
- 第一,因为 Pulsar 有 BookKeeper,数据一致性特别高,Pulsar 可以用在计费平台、支付平台和交易系统等,对数据服务质量,一致性和可用性要求很高的场景。
- 第二种应用场景是 Worker Queue / Push Notifications / Task Queue,主要是为了实现系统之间的相互解耦。
- 第三种场景,与 Pulsar 对消息和队列两种场景的支持比较相关。Pulsar 支持 Queue 消费模式,也支持 Kafka 高带宽的消费模型。后面我会专门讲解 Queue 消费模型与 Flink 结合的优势。
- 第四个场景是 IoT 应用,因为 Pulsar 在服务端有 MQTT 协议的解析,以及轻量级的计算 Pulsar Functions。
- 第五个方面是 unified data processing,把 Pulsar 作为一个批流融合的存储的基础。
我们在 2020 年 11 月底的 Pulsar Summit 亚洲峰会,邀请 40 多位讲师来分享他们的 Pulsar 落地案例。如果大家对 Pulsar 应用场景比较感兴趣,可以关注 B 站上 StreamNative 的账号,观看相关视频。
二、Pulsar 的数据视图
在这些应用场景中,Unified Data Processing 尤为重要。关于批流融合,很多国内用户的第一反应是选择 Flink。我们来看 Pulsar 和 Flink 结合有什么样的优势?为什么用户会选择 Pulsar 和 Flink 做批流融合。
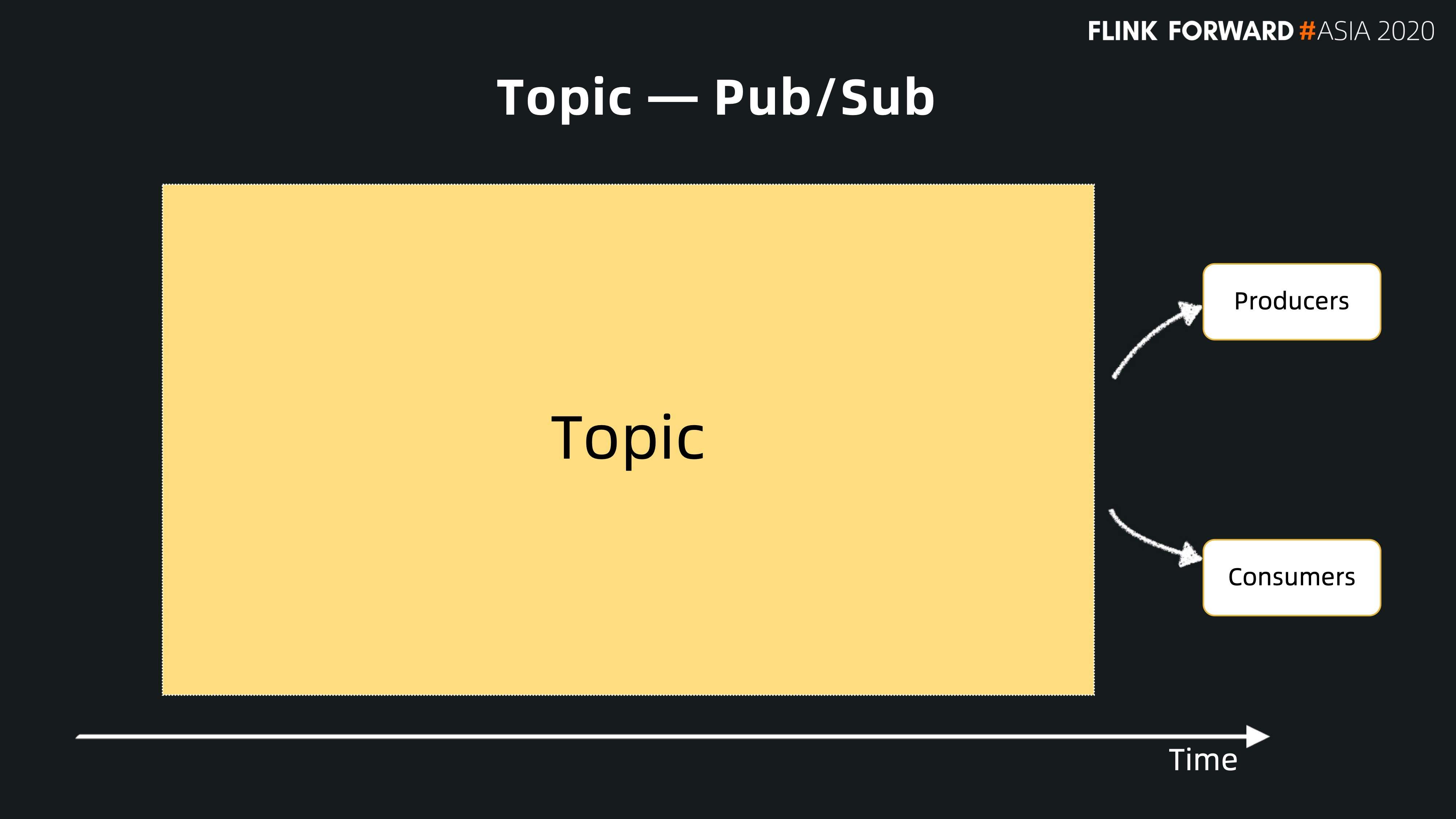
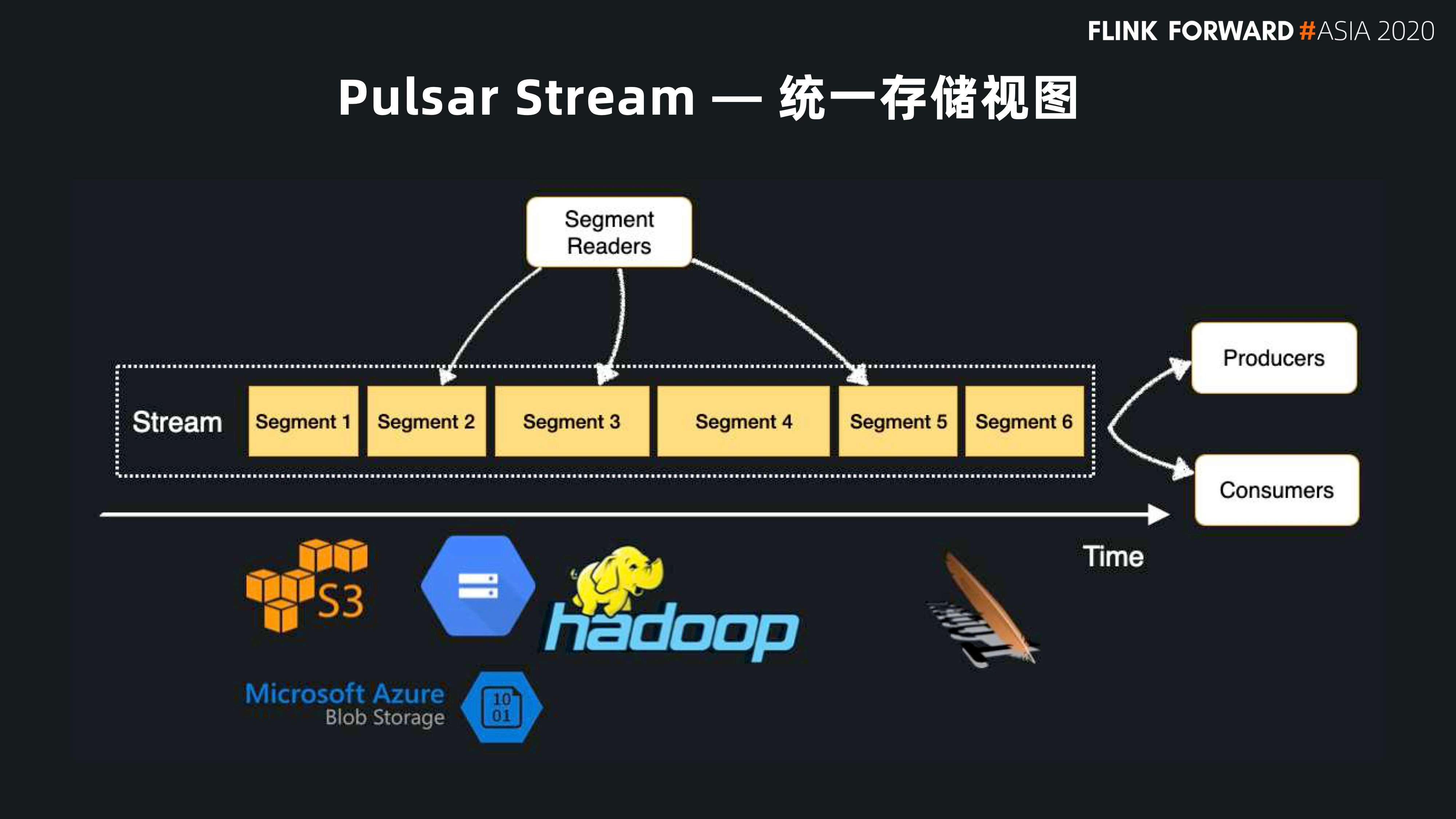
首先,我们先从 Pulsar 的数据视图来展开。跟其他的消息系统一样,Pulsar 也是以消息为主体,以 Topic 为中心。所有的数据都是 producer 交给 topic,然后 consumer 从 topic 订阅消费消息。
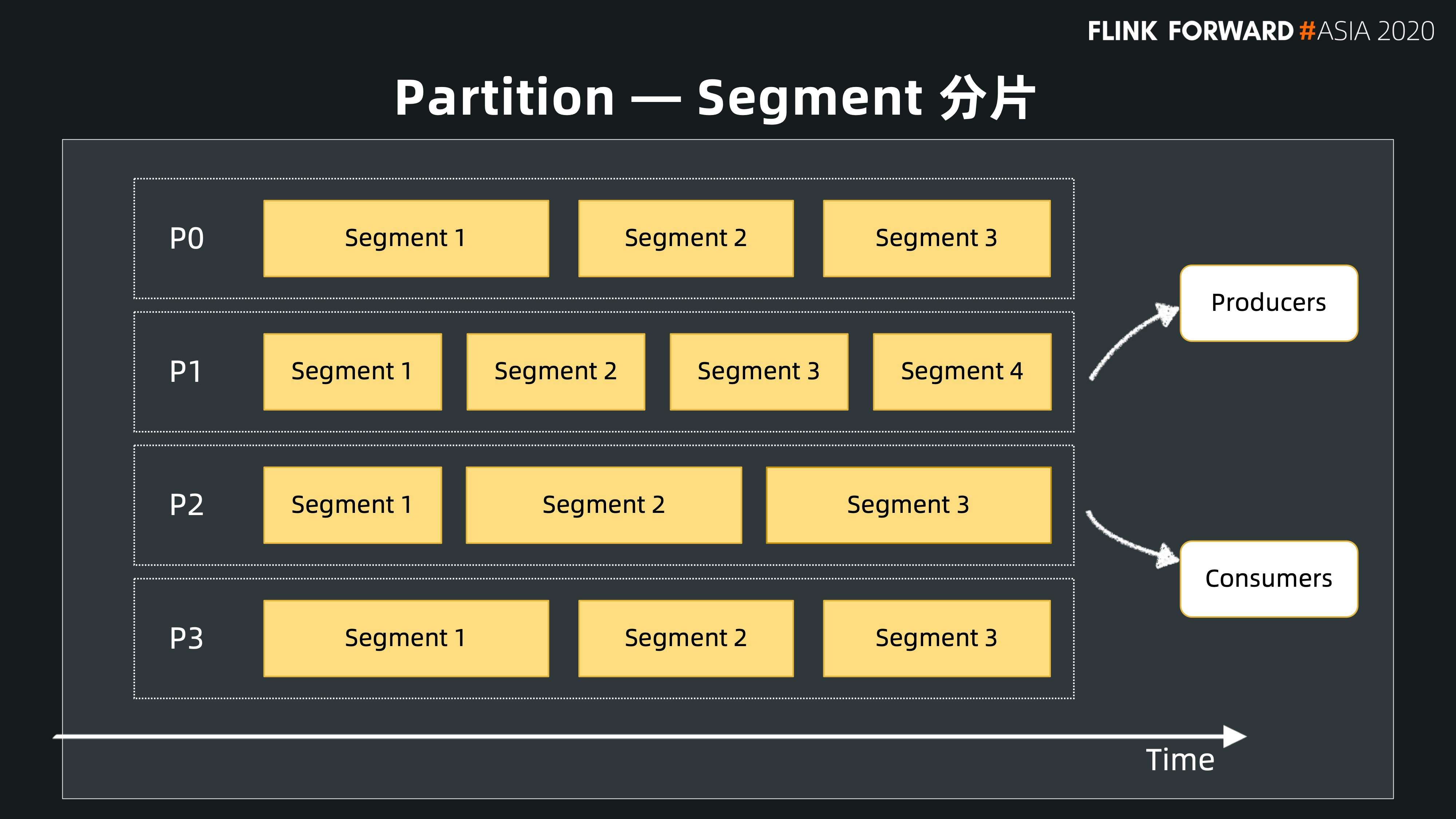
Partition 分区
为了方便扩展,Pulsar 在 topic 内部也有分区的概念,这跟很多消息系统都类似。上面提到 Pulsar 是一个分层的架构,它采用分区把 topic 暴露给用户,但是在内部,实际上每一个分区又可以按照用户指定的时间或者大小切成一个分片。一个 Topic 最开始创建的时候只有一个 active 分片,随着用户指定的时间到达以后,会再切一个新的分片。在新开一个分片的过程中,存储层可以根据各个节点的容量,选择容量最多的节点来存储这个新的分片。
这样的好处是,topic 的每一个分片都会均匀地散布在存储层的各个节点上,实现数据存储的均衡。如果用户愿意,就可以用整个存储集群来存储分区,不再被单个节点容量所限制。如下图所示,该 Topic 有 4 个分区,每一个分区被拆成多个分片,用户可以按照时间(比如 10 分钟或者一个小时),也可以按照大小(比如 1G 或者 2G)切一个分片。分片本身有顺序性,按照 ID 逐渐递增,分片内部所有消息按照 ID 单调递增,这样很容易保证顺序性。
Stream 流存储
我们再从单个分片来看一下,在常见流(stream)数据处理的概念。用户所有的数据都是从流的尾部不断追加,跟流的概念相似,Pulsar 中 Topic 的新数据不断的添加在 Topic 的最尾部。不同的是,Pulsar 的 Topic 抽象提供了一些优势:
- 首先,它采用了存储和计算分离的架构。在计算层,它更多的是一个消息服务层,可以快速地通过 consumer 接口,把最新的数据返回给用户,用户可以实时的获取最新的数据;
- 另外一个好处是,它分成多个分片,如果用户指定时间,从元数据可以找到对应的分片,用户可以绕过实时的流直接读取存储层的分片;
- 还有一个优势是,Pulsar 可以提供无限的流存储。
做基础设施的同学,如果看到按照时间分片的架构,很容易想到把老的分片搬到二级存储里面去,在 Pulsar 里也是这样做的。用户可以根据 topic 的消费热度,设置把老的,或者超过时限或大小的数据自动搬到二级存储中。用户可以选择使用 Google,微软的 Azure 或者 AWS 来存储老的分片,同时也支持 HDFS 存储。
这样的好处是:对最新的数据可以通过 BookKeeper 做快速返回,对于老的冷数据可以利用网络存储云资源做一个无限的流存储。这就是 Pulsar 可以支持无限流存储的原因,也是批流融合的一个基础。
总体来说,Pulsar 通过存储计算分离,为大家提供了实时数据和历史数据两套不同的访问接口。用户可以依据内部不同的分片位置,根据 metadata 来选择使用哪种接口来访问数据。同时根据分片机制可以把老的分片放到二级存储中,这样可以支撑无限的流存储。
Pulsar 的统一体现在对分片元数据管理的方面。每个分片可以按照时间存放成不同的存储介质或格式,但 Pulsar 通过对每个分片的 metadata 管理,来对外提供一个分区的逻辑概念。在访问分区中的一个分片的时候我可以拿到它的元数据,知道它的在分区中的顺序,数据的存放位置和保存类型 Pulsar 对每一个分片的 metadata 的管理,提供了统一的 topic 的抽象。
三、Pulsar 和 Flink 的批流融合
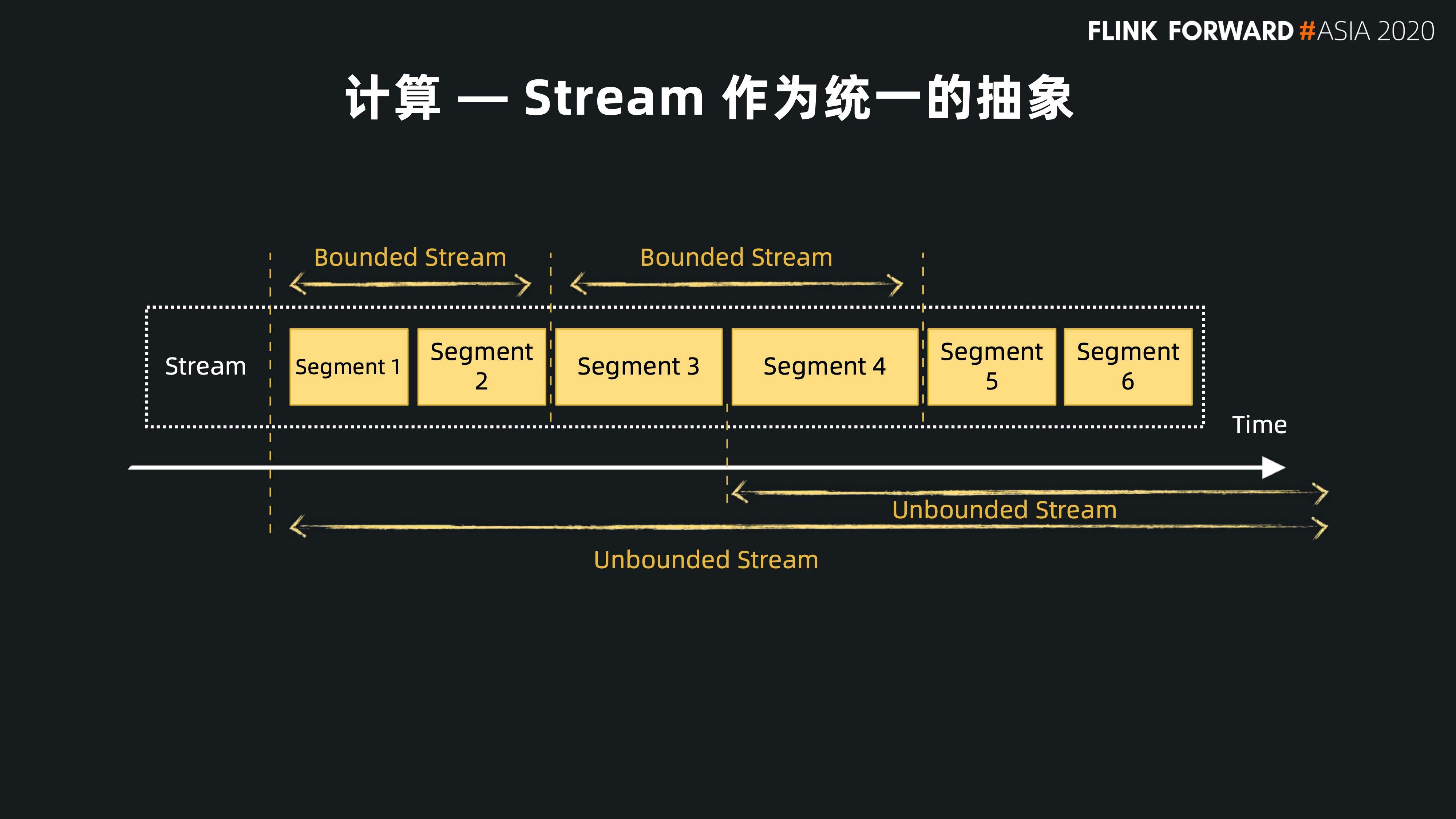
在 Flink 中,流是一个基础的概念,Pulsar 可以作为流的载体来存储数据。如果用户做一个批的计算,可以认为它是一个有界的流。对 Pulsar 来说,这就是一个 Topic 有界范围内的分片。
在图中我们可以看到,topic 有很多的分片,如果确定了起止的时间,用户就可以根据这个时间来确定要读取的分片范围。对实时的数据,对应的是一个连续的查询或访问。对 Pulsar 的场景来说就是不停的去消费 Topic 的尾部数据。这样,Pulsar 的 Topic 的模型就可以和 Flink 流的概念很好的结合,Pulsar 可以作为 Flink 流计算的载体。
- 有界的计算可以视为一个有界的流,对应 Pulsar 一些限定的分片;
- 实时的计算就是一个无界的流,对 Topic 中最新的数据做查询和访问。
对有界的流和无界的流,Pulsar 采取不同的响应模式:
-
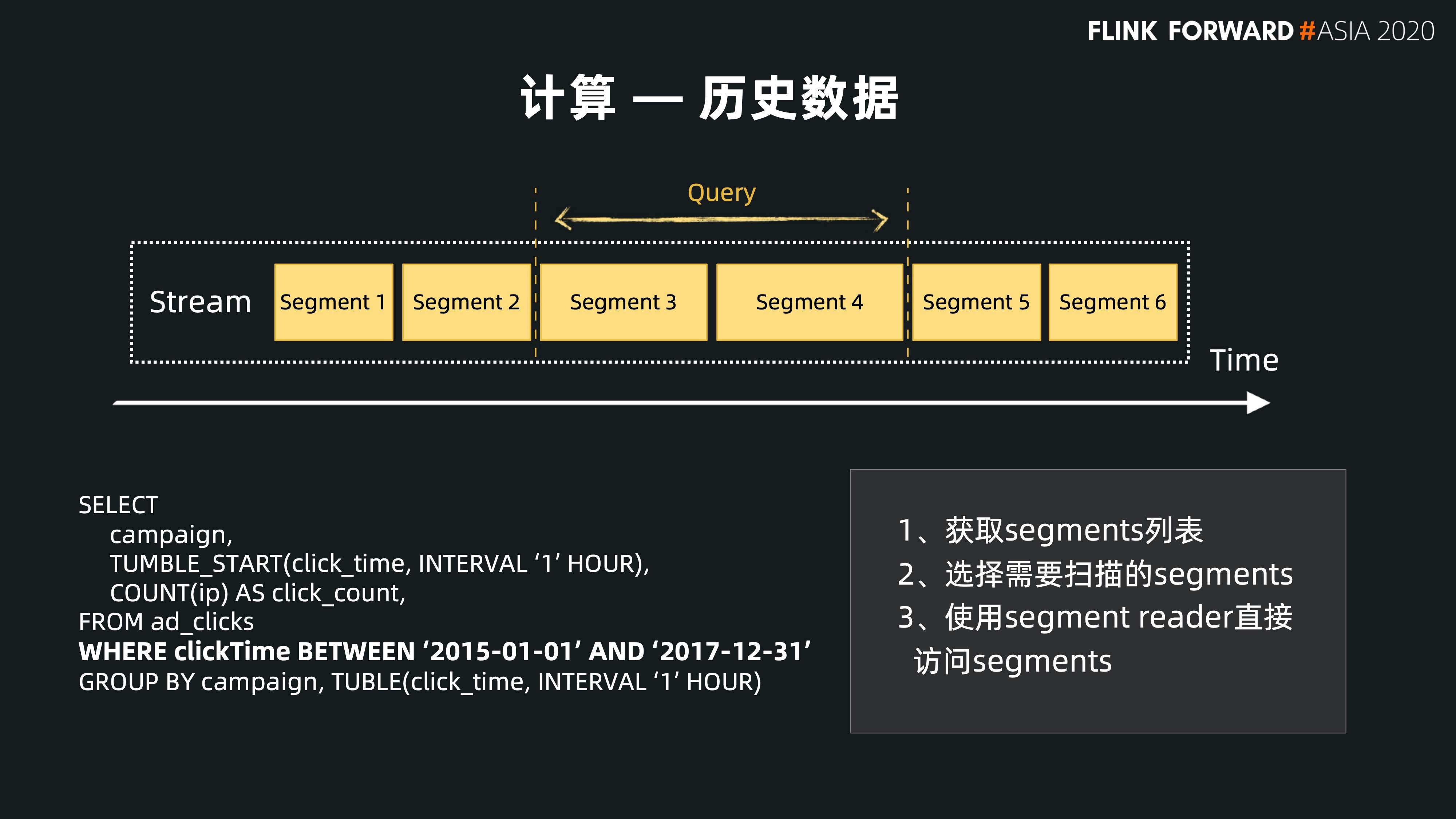
第一种是对历史数据的响应。如下图所示,左下角是用户的 query,给定起止的时间限定流的范围。对 Pulsar 的响应分为几步:
- 第一步,找到 Topic,根据我们统一管理的 metadata,可以获取这个 topic 里面所有分片的 metadata 的列表;
- 第二步,根据时间限定在 metadata 列表中,通过两分查找的方式来获取起始分片和终止的分片,选择需要扫的分片;
- 第三步,找到这些分片以后通过底层存储层的接口访问需要访问的这些分片,完成一次历史数据的查找。
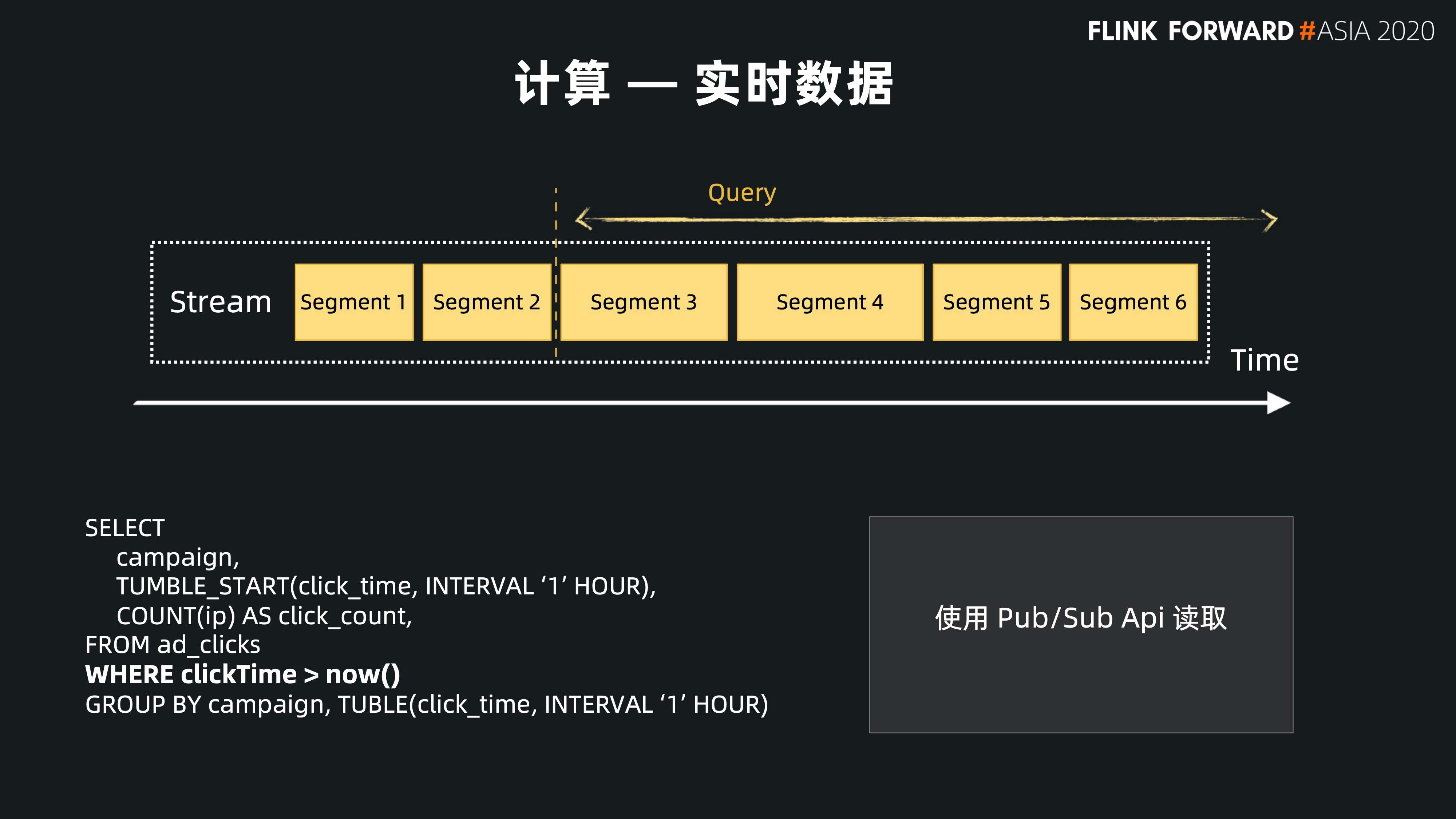
- 对实时数据的查找,Pulsar 也提供和 Kafka 相同的接口,可以通过 consumer 的方式来读取最尾端分片(也就是最新的数据),通过 consumer 接口对数据进行实时访问。它不停地查找最新的数据,完成之后再进行下一次查找。这种情况下,使用 Pulsar Pub/Sub 接口是一种最直接最有效的方式。
简单来说,Flink 提供了统一的视图让用户可以用统一的 API 来处理 streaming 和历史数据。以前,数据科学家可能需要编写两套应用分别用来处理实时数据和历史数据,现在只需要一套模型就能够解决这种问题。
Pulsar 主要提供一个数据的载体,通过基于分区分片的架构为上面的计算层提供流的存储载体。因为 Pulsar 采用了分层分片的架构,它有针对流的最新数据访问接口,也有针对批的对并发有更高要求的存储层访问接口。同时它提供无限的流存储和统一的消费模型。

四、Pulsar 现有能力和进展
最后我们额外说一下 Pulsar 现在有怎样的能力和最近的一些进展。
现有能力
schema
在大数据中,schema 是一个特别重要的抽象。在消息领域里面也是一样,在 Pulsar 中,如果 producer 和 consumer 可以通过 schema 来签订一套协议,那就不需要生产端和消费端的用户再线下沟通数据的发送和接收的格式。在计算引擎中我们也需要同样的支持。
在 Pulsar-Flink connector 中,我们借用 Flink schema 的 interface,对接 Pulsar 自带的 Schema,Flink 能够直接解析存储在Pulsar 数据的 schema。这个 schema 包括两种:
- 第一种是我们常见的对每一个消息的元数据(meatdata)包括消息的 key、消息产生时间、或是其他元数据的信息。
- 另一种是对消息的内容的数据结构的描述,常见的是 Avro 格式,在用户访问的时候就可以通过Schema知道每个消息对应的数据结构。
同时我们结合 Flip-107,整合 Flink metadata schema 和 Avro 的 metadata,可以将两种 Schema 结合在一起做更复杂的查询。

source
有了这个 schema,用户可以很容易地把它作为一个 source,因为它可以从 schema 的信息理解每个消息。
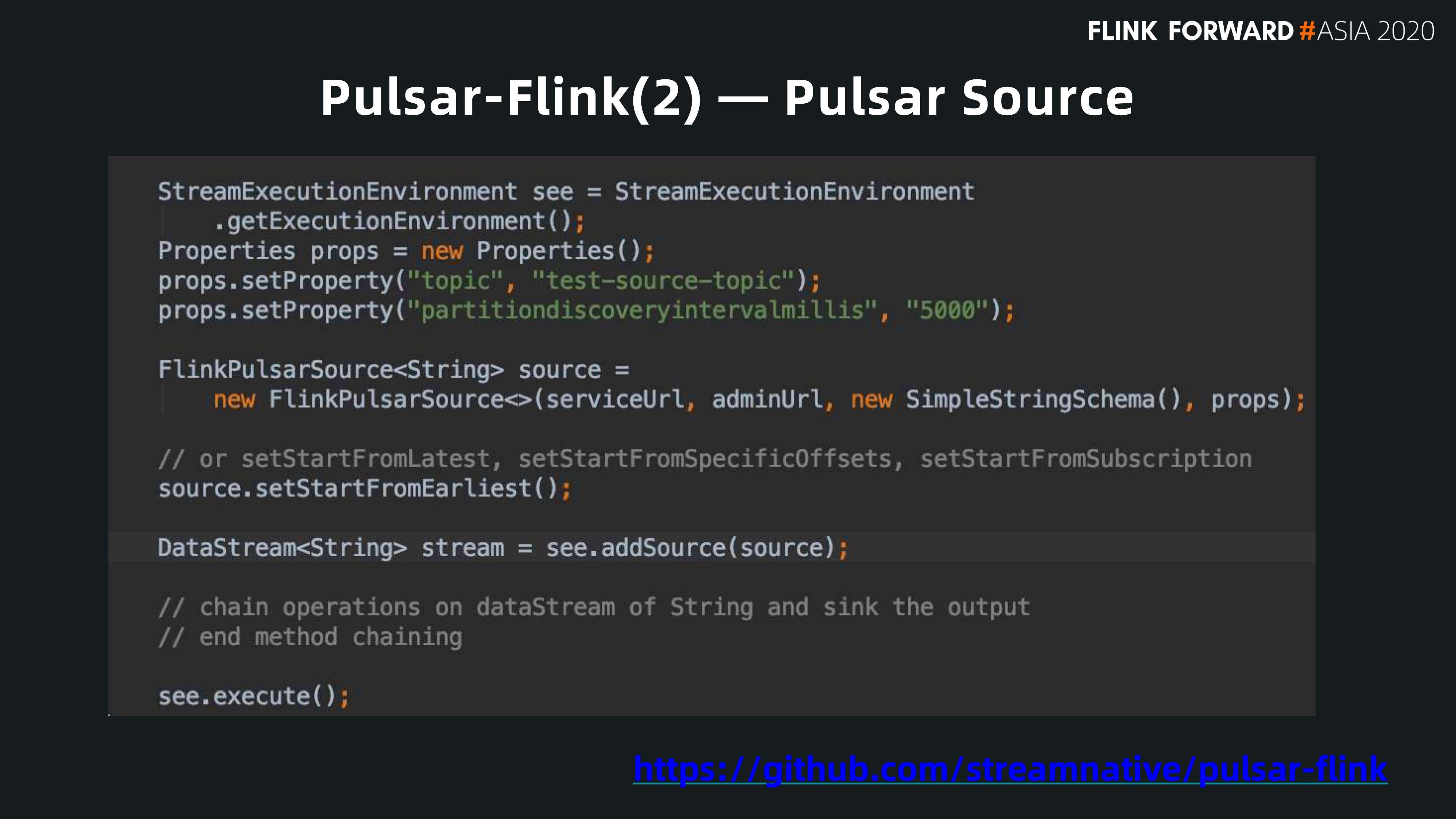
Pulsar Sink
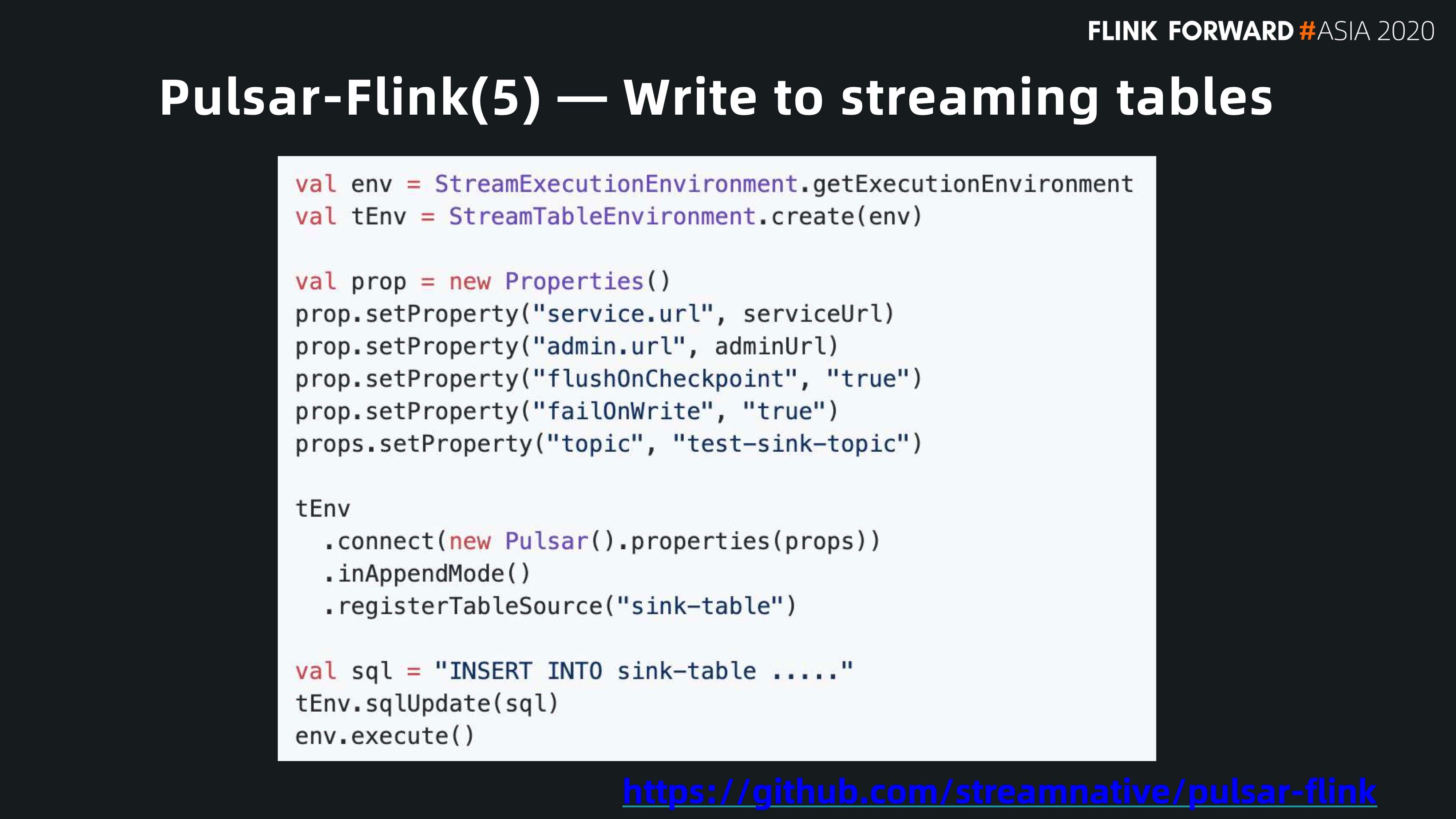
我们也可以把在 Flink 中的计算结果返回给 Pulsar 把它做为 Sink。

Streaming Tables
有了 Sink 和 Source 的支持,我们就可以把 Flink table 直接暴露给用户。用户可以很简单的把 Pulsar 作为 Flink 的一个 table,查找数据。
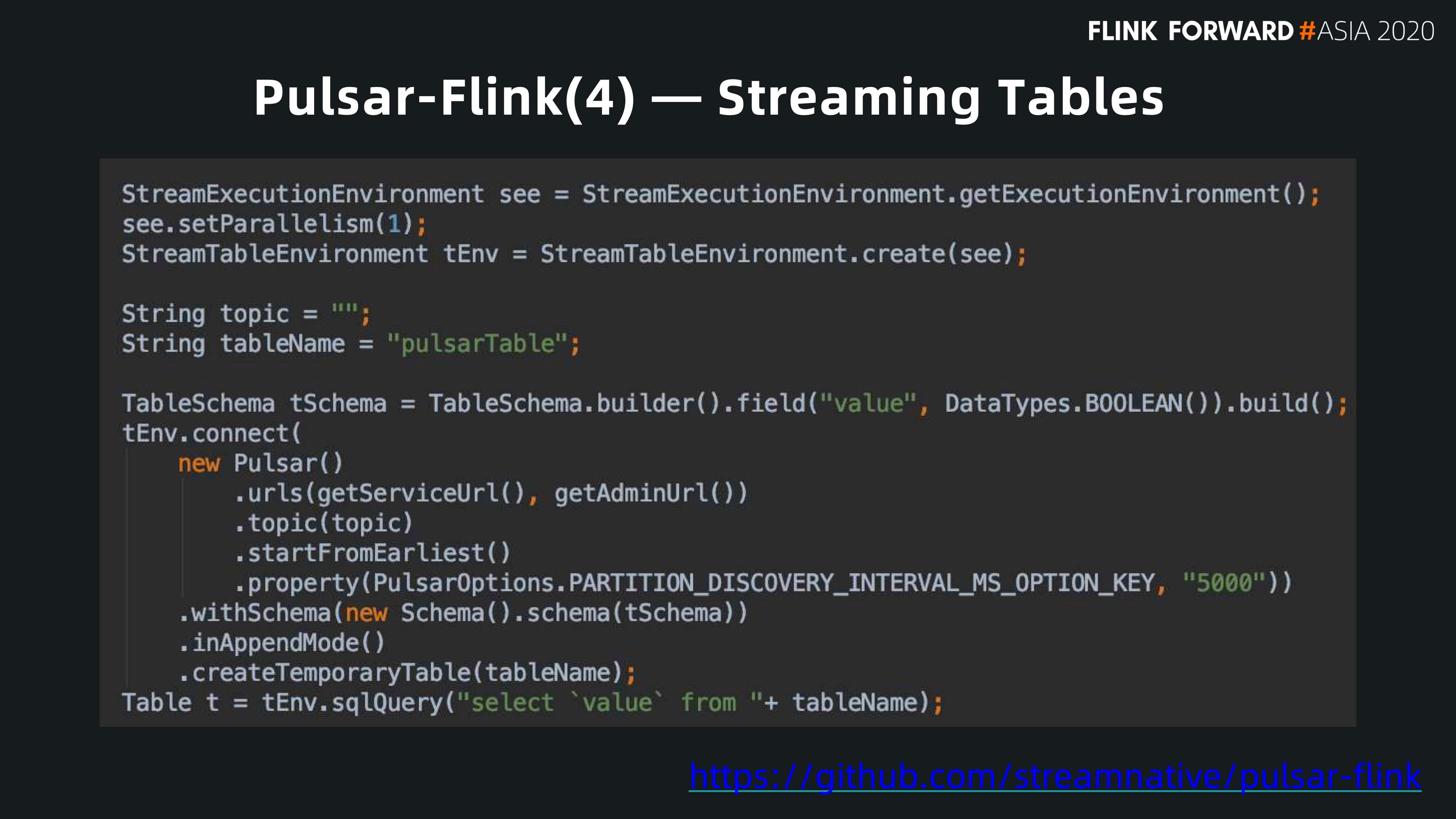
write to straming tables
下图展示如何把计算结果或数据写到 Pulsar 的 Topic 中去。
Pulsar Catalog
Pulsar 自带了很多企业流的特性。Pulsar 的 topic(e.g. persistent://tenant_name/namespace_name/topic_name)不是一个平铺的概念,而是分很多级别。有 tenant 级别,还有 namespace 级别。这样可以很容易得与 Flink 常用的 Catalog 概念结合。
如下图所示,定义了一个 Pulsar Catalog,database 是 tn/ns,这是一个路径表达,先是 tenant,然后是 namespace,最后再挂一个 topic。这样就可以把Pulsar 的 namespace 当作 Flink 的 Catalog,namespace 下面会有很多 topic,每个 topic 都可以是 Catalog 的 table。这就可以很容易地跟 Flink Cataglog 做很好的对应。在下图中,上方的是 Catalog 的定义,下方则演示如何使用这个 Catalog。不过,这里还需要进一步完善,后边也有计划做 partition 的支持。

FLIP-27
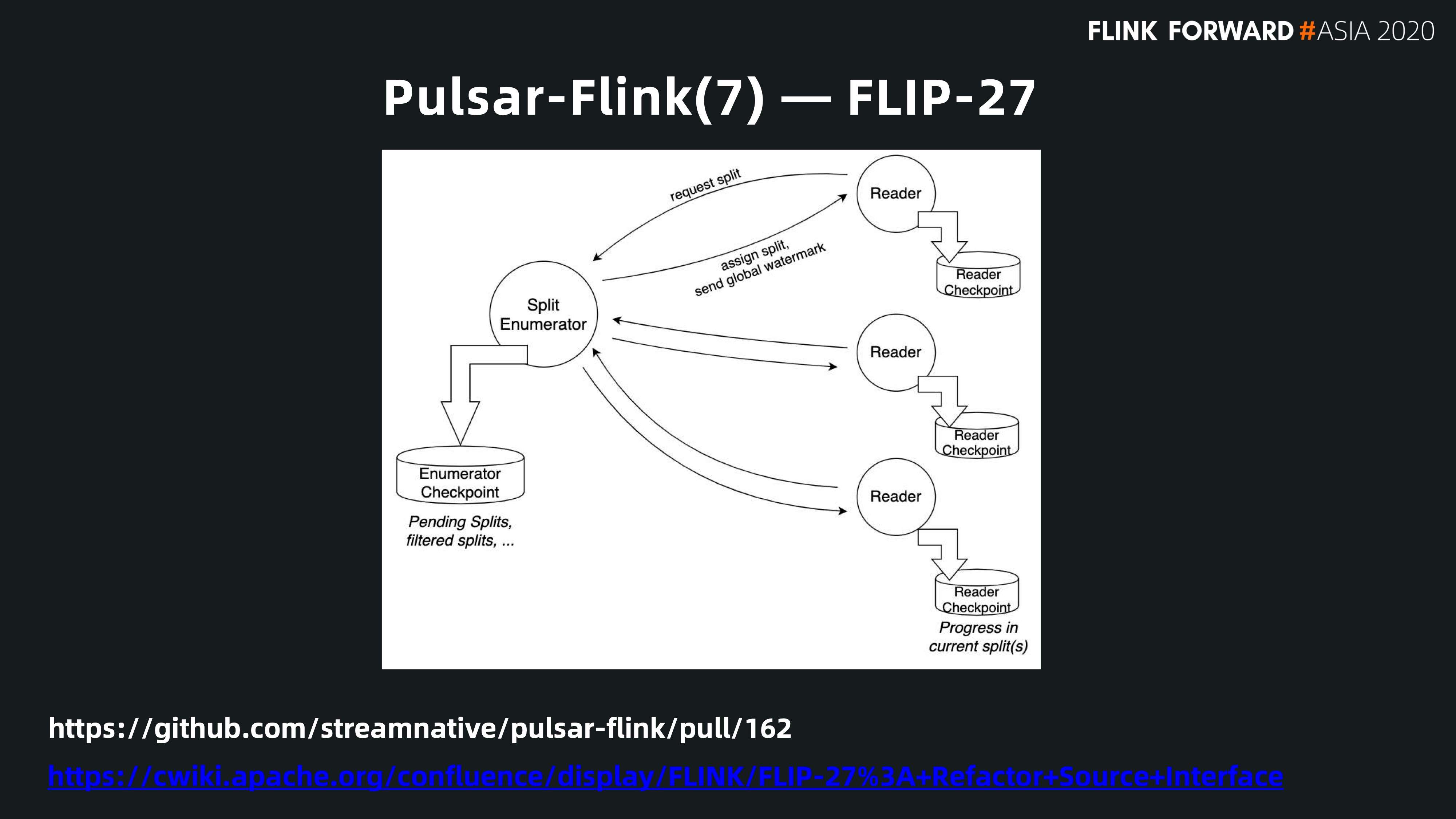
FLIP-27 是 Pulsar - Flink 批流融合的一个代表。前面介绍了 Pulsar 提供统一的视图,管理所有 topic 的 metadata。在这个视图中,根据 metadata 标记每个分片的信息,再依靠 FLIP-27 的 framework 达到批流融合的目的。FLIP-27 中有两个概念:Splitter 和 reader。
它的工作原理是这样的,首先会有一个 splitter 把数据源做切割,之后交给 reader 读取数据。对 Pulsar 来说,splitter 处理的还是 Pulsar 的一个 topic。抓到 Pulsar topic 的 metadata 之后,根据每个分片的元数据来判断这个分片存储在什么位置,再选最合适的 reader 进行访问。Pulsar 提供统一的存储层,Flink 根据 splitter 对每个分区的不同位置和格式的信息,选择不同的 reader 读取 Pulsar 中的数据。
Source 高并发
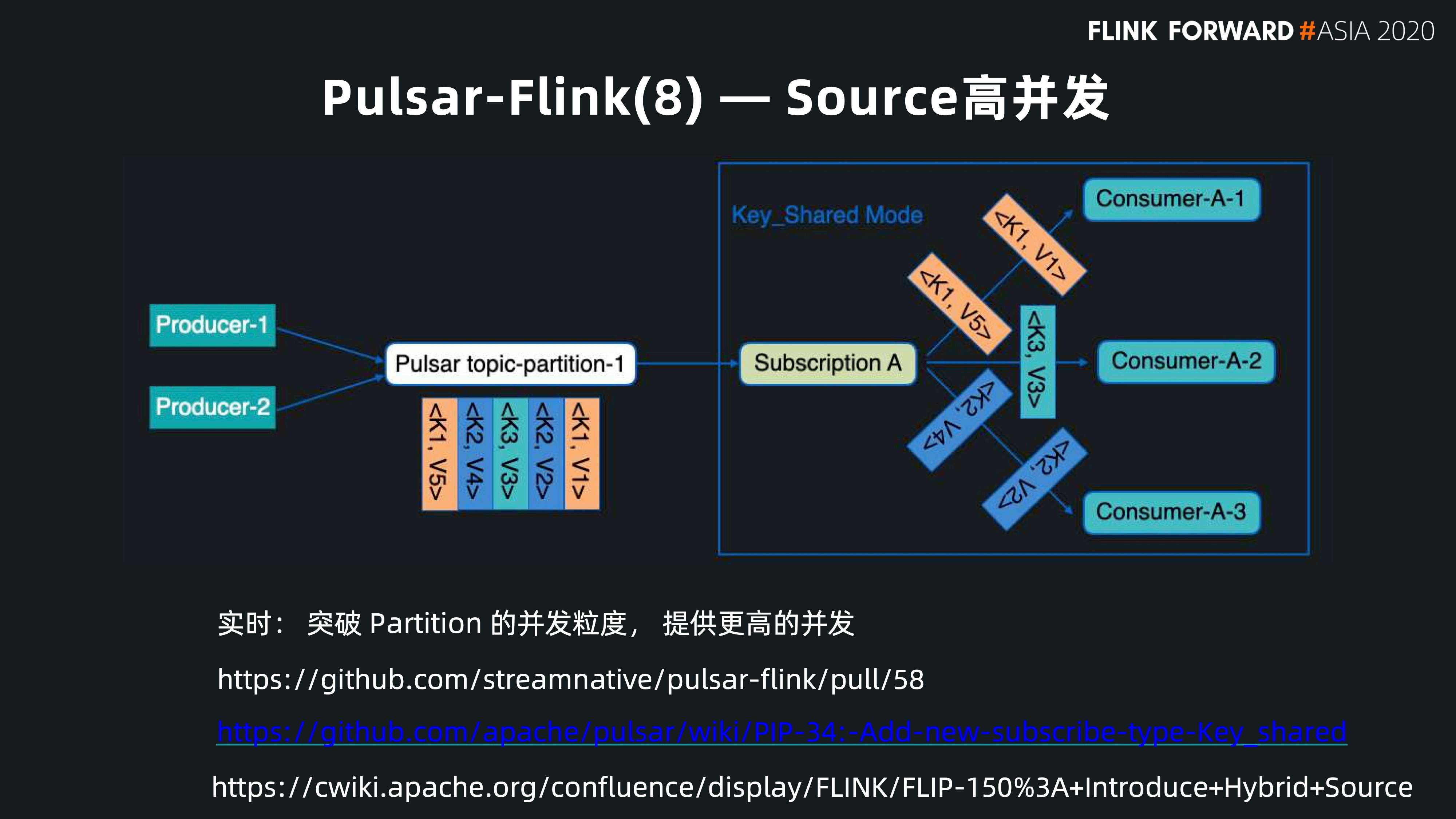
另一个和 Pulsar 消费模式紧密相关的是。很多 Flink 用户面临的问题是如何让 Flink 更快地执行任务。例如,用户给了 10 个并发度,它会有 10 个 job 并发,但假如一个 Kafka 的 topic 只有 5 个分区,由于每个分区只能被一个 job 消费,就会有 5 个 Flink job 是空闲的。如果想要加快消费的并发度,只能跟业务方协调多开几个分区。这样的话,从消费端到生产端和后边的运维方都会觉得特别复杂。并且它很难做到实时的按需更新。
而 Pulsar 不仅支持 Kafka 这种每个分区只能被一个 active 的 consumer 消费的情况,也支持 Key-Shared 的模式,多个 consumer 可以共同对一个分区进行消费,同时保证每个 key 的消息只发给一个 consumer,这样就保证了 consumer 的并发,又同时保证了消息的有序。
对前面的场景,我们在 Pulsar Flink 里做了 Key-shared 消费模式的支持。同样是 5 个分区,10 个并发 Flink job。但是我可以把 key 的范围拆成 10 个。每一个 Flink 的子任务消费在 10 个 key 范围中的一个。这样从用户消费端来说,就可以很好解耦分区的数量和 Flink 并发度之间的关系,也可以更好提供数据的并发。
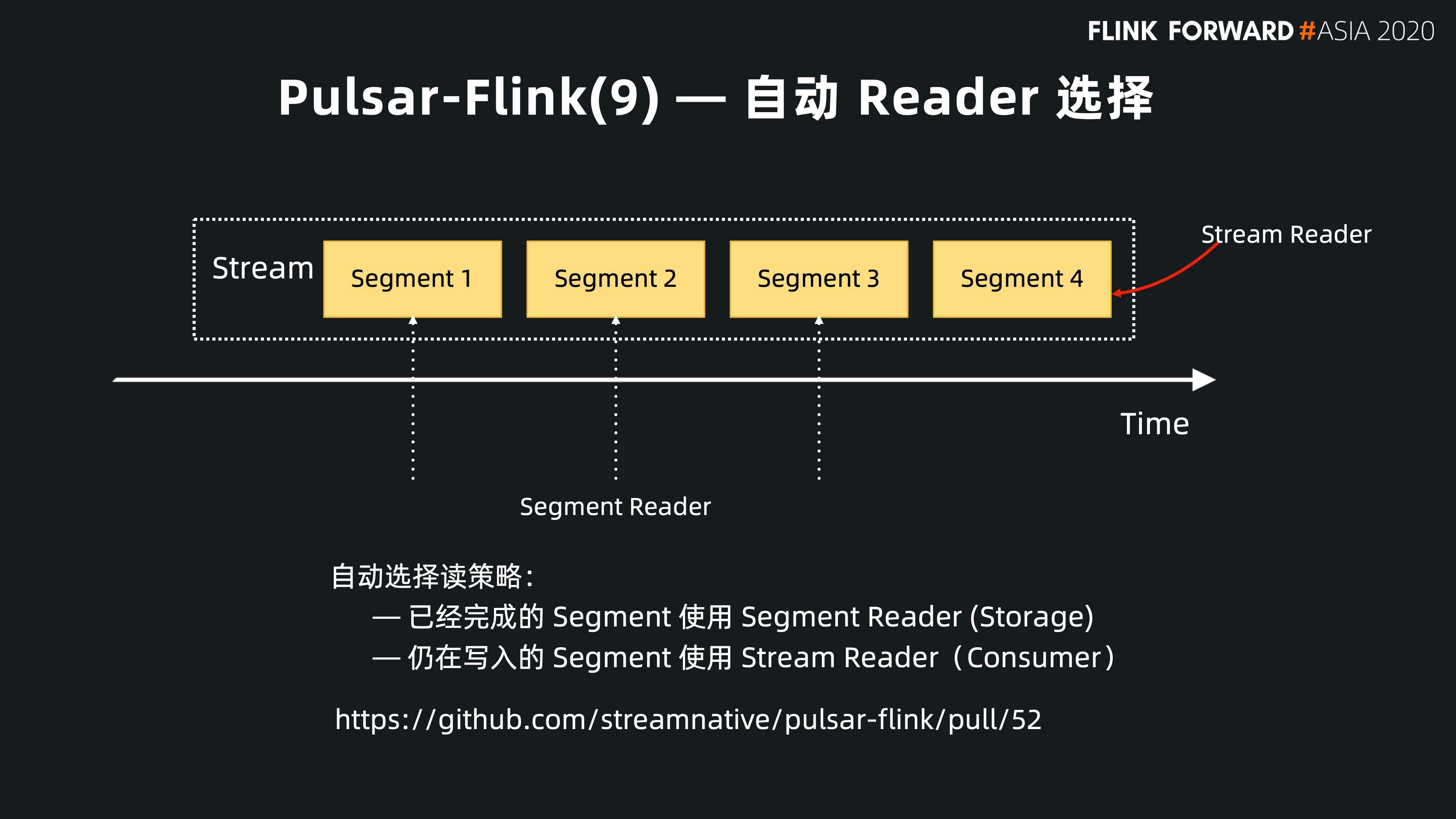
自动 Reader 选择
另外一个方向是上文提到的 Pulsar 已经有统一的存储基础。我们可以在这个基础上根据用户不同的 segment metadata 选择不同的 reader。目前,我们已经实现该功能。
近期工作
最近,我们也在做和 Flink 1.12 整合相关的工作。Pulsar-Flink 项目也在不停地做迭代,比如我们增加了对 Pulsar 2.7 中事务的支持,并且把端到端的 Exactly-Once 整合到 Pulsar Flink repo 中;另外的工作是如何读取 Parquet 格式的二级存储的列数据;以及使用 Pulsar 存储层做 Flink 的 state 存储等。

原文链接
本文为阿里云原创内容,未经允许不得转载。

![pythonplot绘图xrd_一种简化的截面动量组合测试[PythonMATLAB]](http://pic.xiahunao.cn/pythonplot绘图xrd_一种简化的截面动量组合测试[PythonMATLAB])







)









