开源大数据社区 & 阿里云 EMR 系列直播 第六期
主题:EMR spark on ACK 产品演示及最佳实践
讲师:石磊,阿里云 EMR 团队技术专家
内容框架:
- 云原生化挑战及阿里实践
- Spark 容器化方案
- 产品介绍和演示
直播回放:扫描文章底部二维码加入钉群观看回放,或进入链接https://developer.aliyun.com/live/246868
一、云原生化挑战及阿里实践
大数据技术发展趋势

云原生化面临挑战
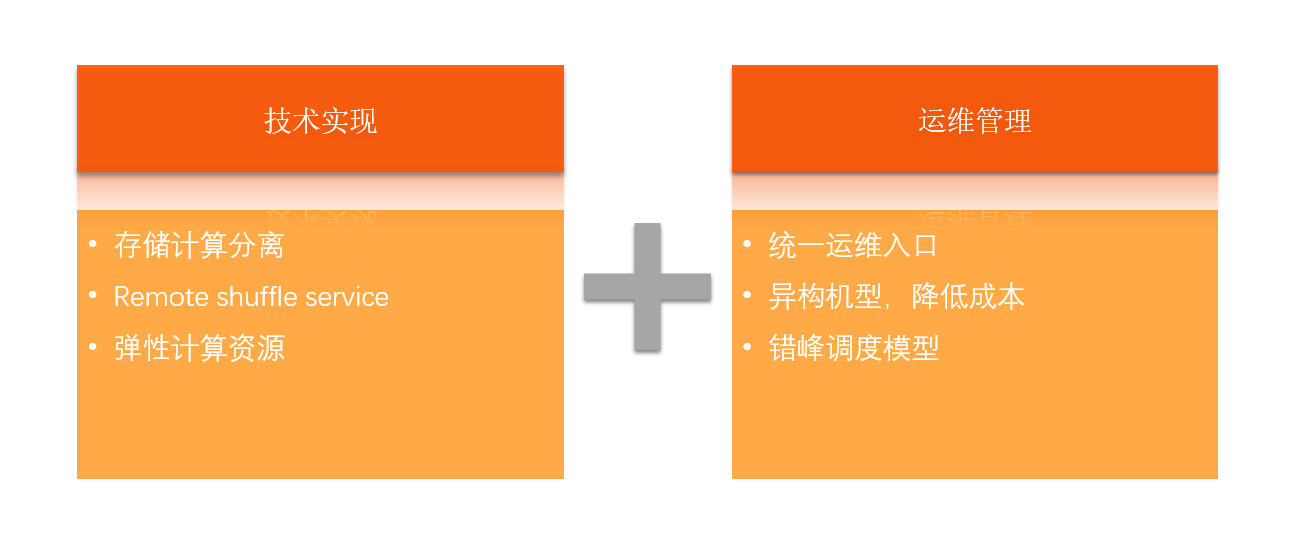
计算与存储分离
如何构建以对象存储为底座的 HCFS 文件系统
- 完全兼容现有的 HDFS
- 性能对标 HDFS,成本降低
shuffle 存算分离
如何解决 ACK 混合异构机型
- 异构机型没有本地盘
- 社区 [Spark-25299] 讨论,支持 Spark 动态资源,成为业界共识
缓存方案
如何有效支持跨机房、跨专线混合云
- 需要在容器内支持缓存系统
ACK 调度
如何解决调度性能瓶颈
- 性能对标 Yarn
- 多级队列管理
其他
- 错峰调度
- Yarnon ACK 节点资源相互感知
阿里实践 - EMR on ACK
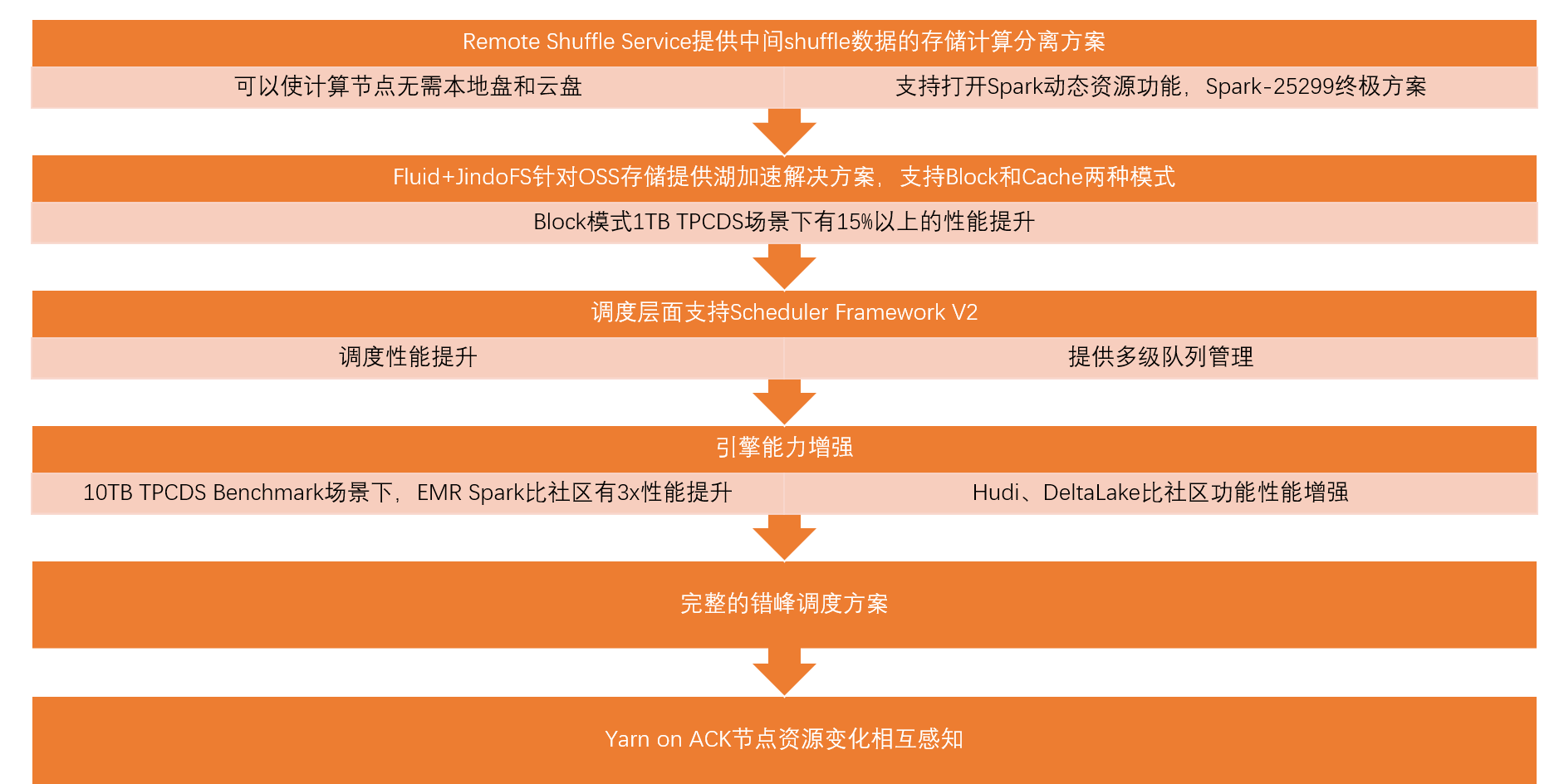
整体方案介绍
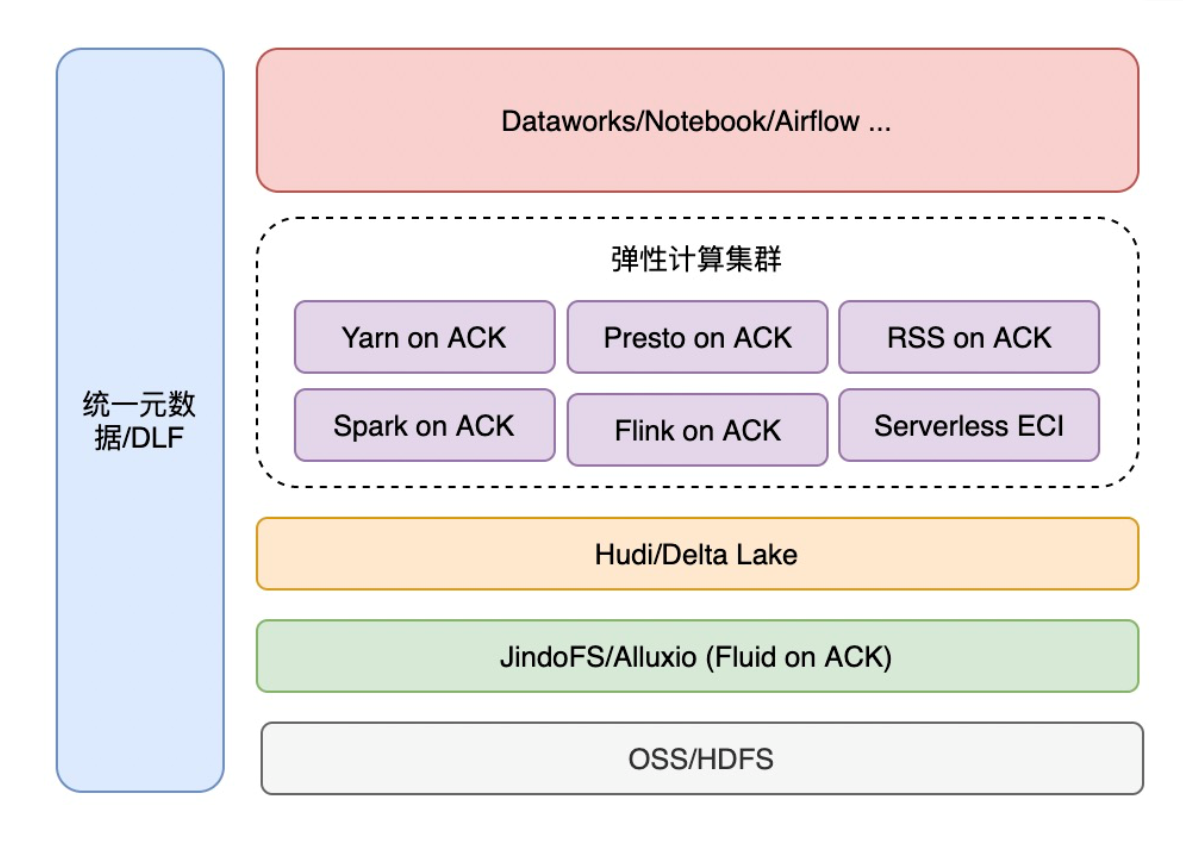
- 通过数据开发集群/调度平台提交到不同的执行平台
- 错峰调度,根据业务高峰低峰策略调整
- 云原生数据湖架构,ACK 弹性扩缩容能力强
- 通过专线,云上云下混合调度
- ACK 管理异构机型集群,灵活性好
二、Spark 容器化方案
方案介绍
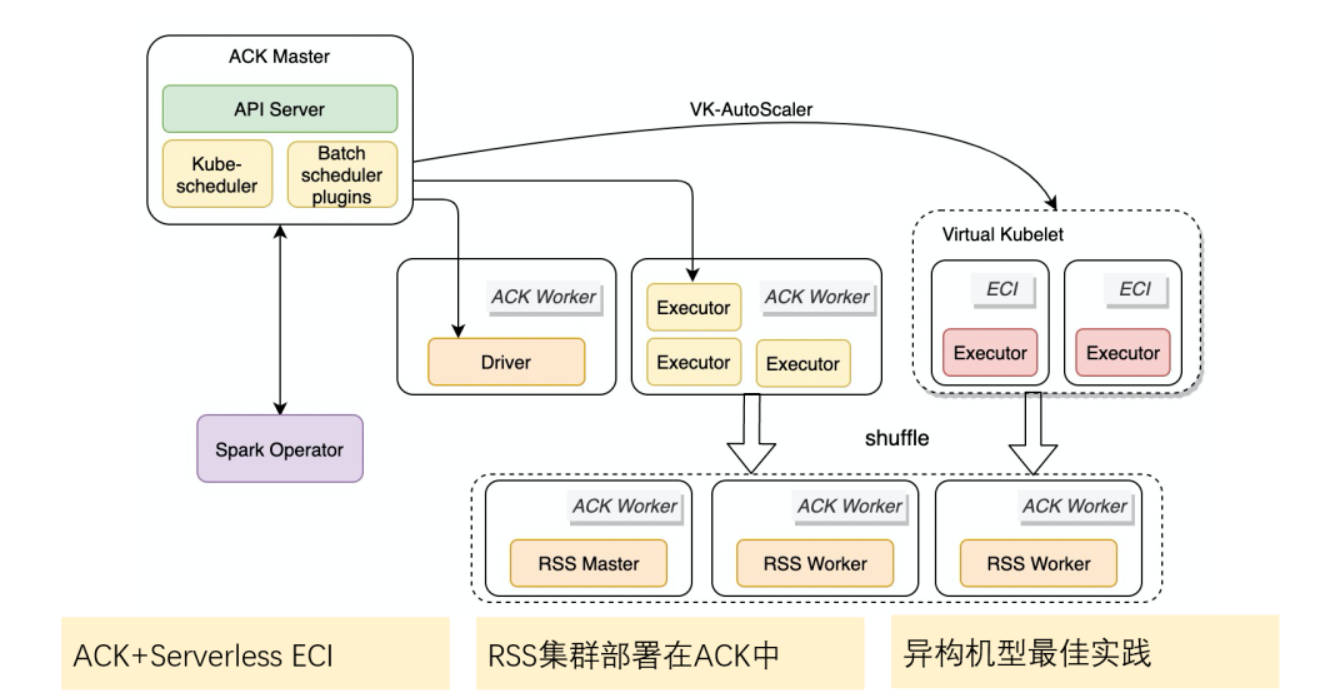
RSS Q&A
1、为什么需要 Remote Shuffle Service?
- RSS 使得 Spark 作业不需要 Executor Pod 挂载云盘。挂载云盘非常不利于扩展性和大规模的生产实践。
- 云盘的大小无法事前确定,大了浪费空间,小了 Shuffle 会失败。RSS 专门为存储计算分离场景设计。
- Executor 将 shuffle 数据写入了 RSS 系统,RSS 系统来负责管理 shuffle 数据,Executor 空闲后即可以回收。[SPARK-25299]
- 可以完美支持动态资源,避免数据倾斜的长尾任务拖住 Executor 资源不能释放。
2、RSS 性能如何,成本如何,扩展性如何?
- RSS 对于 shuffle 有很深的优化,专门为存储与计算分离场景、K8s 弹性场景而设计。
- 针对 Shufflefetch 阶段,可以将 reduce 阶段的随机读变为顺序读,大大提升了作业的稳定性和性能。
- 可以直接利用原有 K8s 集群中的磁盘进行部署,不需要加多余的云盘来进行 shuffle。性价比非常高,部署方式灵活。
Spark Shuffle
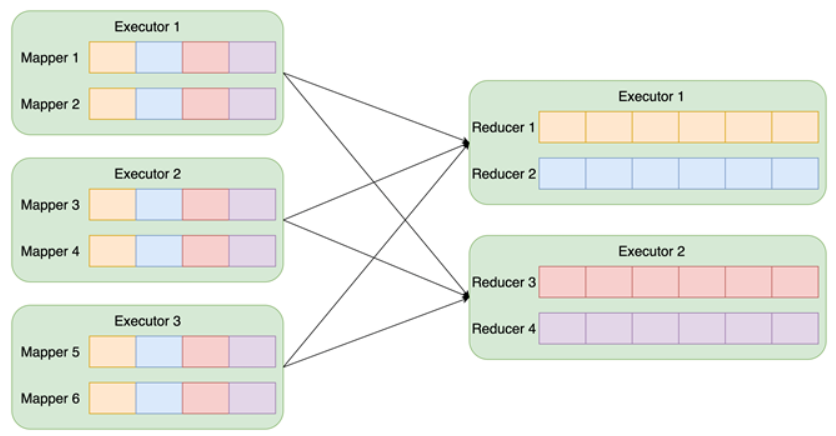
- 产生 numMapper * numReducer 个 block
- 顺序写、随机读
- 写时 Spill
- 单副本,丢数据需 stage 重算
EMR Remote Shuffle Service
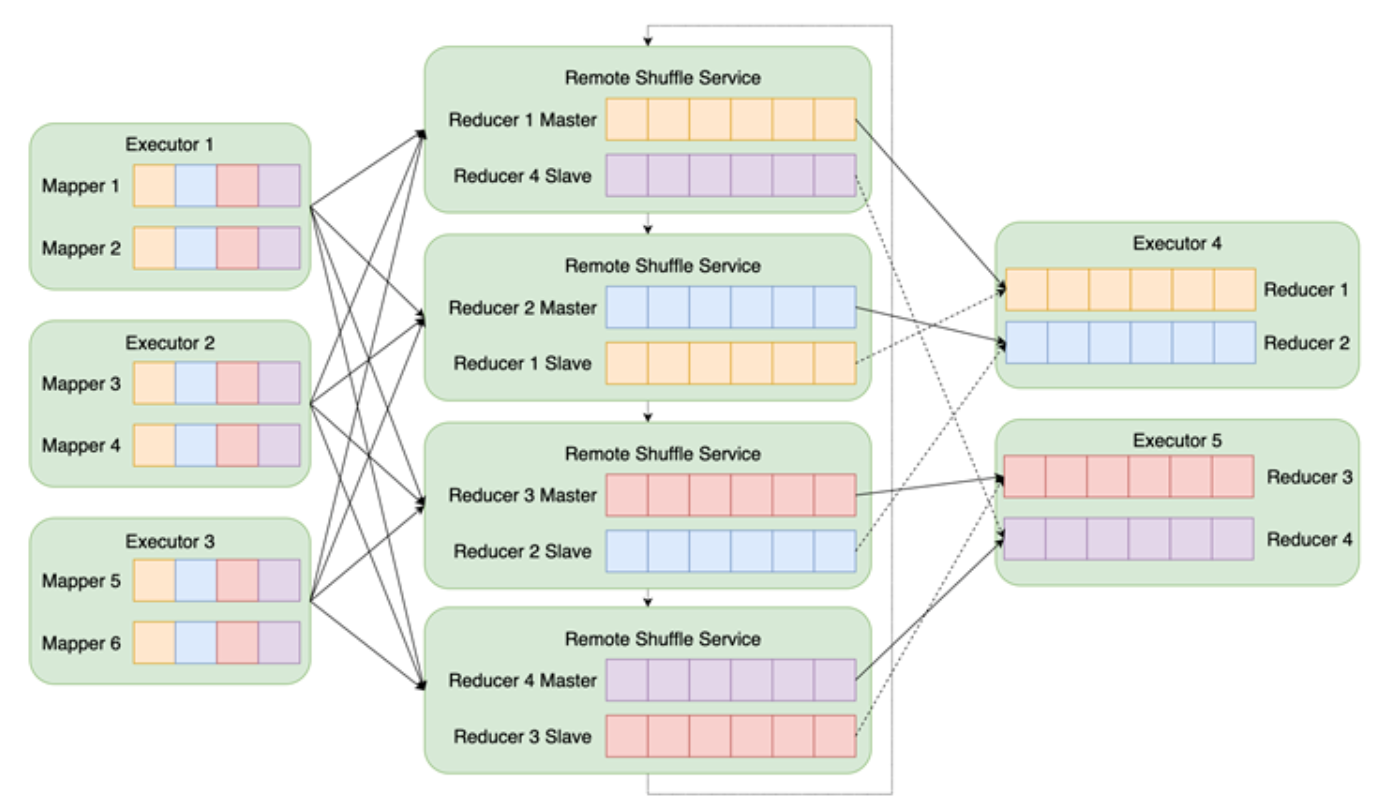
- 追加写、顺序读
- 无写时 Spill
- 两副本;副本复制到内存后即完成
- 副本之间通过内网备份,无需公网带宽
RSS TeraSort Benchmark
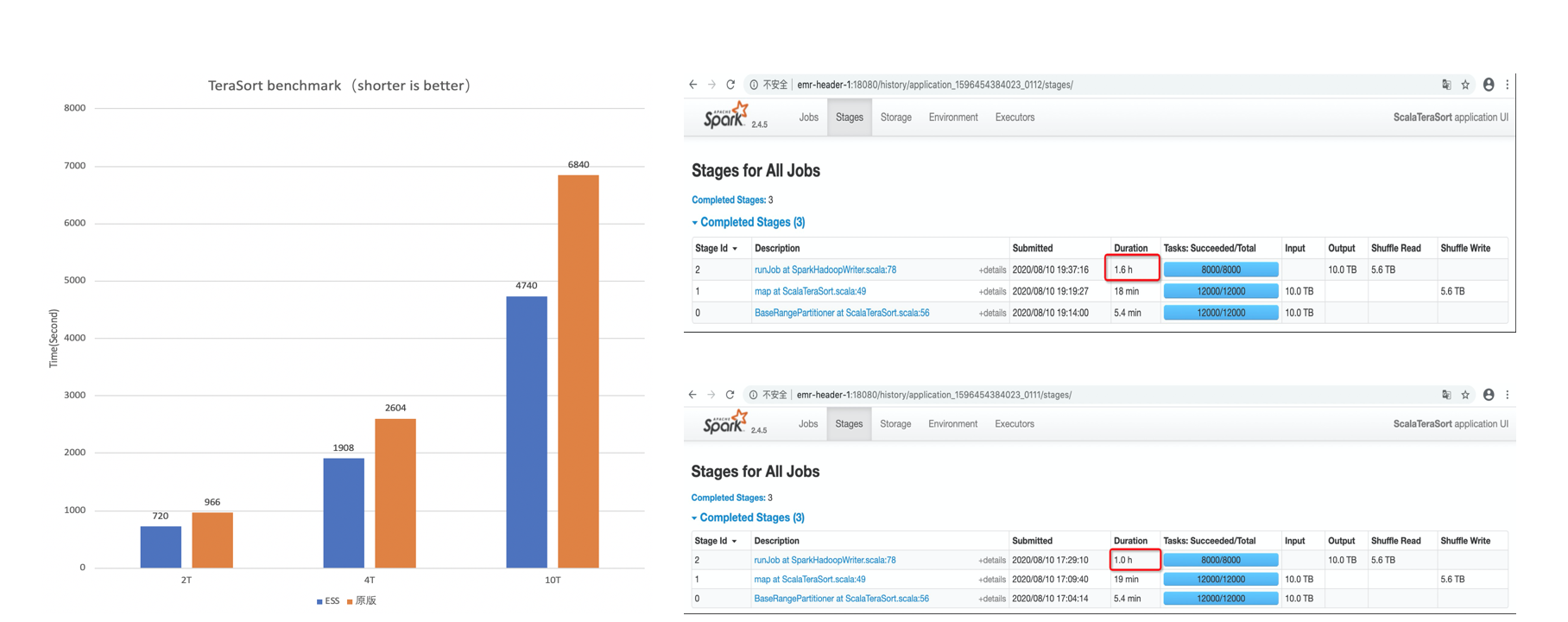
- 备注说明:以10T Terasort 为例,shuffle 量压缩后大约 5.6T。可以看出该量级的作业在 RSS 场景下,由于 shuffle read 变为顺序读,性能会有大幅提升。
Spark on ECI 效果

Summary
原文链接
本文为阿里云原创内容,未经允许不得转载。






)


)








知识点汇总!...)
