简介: 近日,智能数据库和DAS团队研发的智能调参ResTune系统论文被SIGMOD 2021录用,SIGMOD是数据库三大顶会之首,是三大顶会中唯一一个Double Blind Review的,其权威性毋庸置疑。
近日,智能数据库和DAS团队研发的智能调参ResTune系统论文被SIGMOD 2021录用,SIGMOD是数据库三大顶会之首,是三大顶会中唯一一个Double Blind Review的,其权威性毋庸置疑。
ResTune论文的录用,说明了我们在智能化数据库管控方向的技术积累和深度,也是阿里云自治数据库和智能化运维里程碑式的一步。目前,智能调参功能已经在数据库自治服务(DAS)上落地,是业界第一个正式上线的数据库配置参数智能调参功能,进一步说明了阿里云自治数据库方向的技术领先性。
1. 概述
调参服务在阿里丰富的业务场景中有着广泛的应用,如数据库系统的性能与配置参数优化、机器学习模型/深度神经网络的超参选择、推荐系统和云调度系统中参数的自适应调节、工业控制和供应链中的仿真优化和参数优化等。如何在生产环境中支持客户实际需求,是学术界AI for system的一个研究热点。
今年,由达摩院-数据库与存储实验室-智能数据库团队研发的ResTune智能调参工作(ResTune: Resource Oriented Tuning Boosted by Meta-Learning for Cloud Databases,地址:
https://dl.acm.org/doi/pdf/10.1145/3448016.3457291),主要针对OLTP数据库系统的性能参数进行调优,涉及RDS MySQL、RDS PostgreSQL、PolarDB MySQL、PolarDB-O等数据库系统,该工作发表在数据库领域的顶级会议SIGMOD2021(Research Track),并在阿里云数据库自治服务DAS产品中技术落地。
2. 背景
数据库系统如MySQL提供200多个配置参数,不同的参数组合与不断变化的业务负载特征,共同决定着数据库系统的性能和资源使用。针对集团内的业务,通常DBA会根据不同的业务,按人工经验手动选择一组适合的参数。随着数据库上云的加速,业务越来越多样化,仅仅依赖于DBA人工调参遇到水平扩展的瓶颈制约。同时,由于DBA经验的差异性,很难对多种多样的业务负载都找出最优参数。云厂商要做到“客户第一”,自动化的调参功能至关重要:在不同的实例环境下对时间上不断变化的多样业务负载,自适应的提供个性化的优化参数。
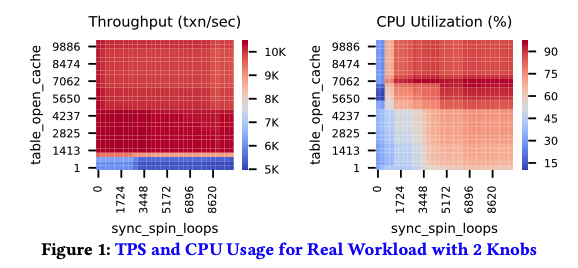
数据库系统调参需要同时考虑性能(如Transactions per second/TPS、Latency)和资源使用(CPU、Memory、IO)的情况。性能优化固然重要,但真实负载的TPS往往受用户的request rate所限,很难达到峰值性能。图1是两个参数下不同取值的TPS和CPU利用率,可以看到,在TPS最高的红色区域对应的CPU利用率变化较大,从15%到75%。而在TPS相同的情况下,资源利用率有很大优化空间。从成本角度,TCO(Total Cost of Ownership)是云数据库的重要指标,也是云数据库的主要优势。
优化资源使用对减少云数据库的TCO,提高成本优势有着重要意义。事实上,我们发现云上大多数实例都存在Over-Provision的情况。此外,资源使用过高可能会造成云数据库的异常和资源争抢带来的性能下降;优化数据库的资源使用能够有效减少甚至避免此类情况引发的故障,提高稳定性。
3. 挑战
我们分析了调参的目标是同时考虑优化资源使用率和性能,上文也提到性能如TPS往往会被客户端的request rate所限而达不到峰值性能。因此,我们需要找出资源利用率最小的数据库配置参数,并且满足SLA的要求。
另一方面,调参本身需要尽可能快(不然违背了降低资源使用),通常的调参系统需要上百步迭代来找出好的配置,每一步迭代约3-5分钟回放workload,这样通常需要天级别的时间进行调参训练。但如果想解决在线troubleshoot的需求,往往需要在1个小时内找出问题,进行恢复。作为云厂商,我们基于已有业务负载调参的历史数据,采用知识迁移学习,可有效加速调参过程,从而尽可能快地找出好的数据库参数配置。
4. 相关工作
数据库调参是最近研究相对热门的领域,在过去几年中有不少工作发表。这些工作按照技术思路主要可以分为三大类:基于搜索的启发式方法、基于贝叶斯优化的方法、基于强化学习(Reinforcement Learning)模型的方法。
- 基于搜索的启发式方法:该类方法通常基于启发式思路,通过给定的规则算法进行搜索来找出优化参数,这一工作的代表是BestConfig[3]系统。这类方法依赖于对workload以及参数对性能影响的先验假设,但在实际中特别是云场景,往往很难为每个workload进行特殊优化和特征工程。这类方法在搜索一组新参数的时候,没有考虑到之前采样到数据的分布,因此效率不高。
- 基于贝叶斯优化的方法:该类方法的代表是iTuned[4]和CMU的Andy Pavlo实验室的SIGMOD17工作OtterTune[5]。贝叶斯优化将调参看作是一个黑盒优化问题,通过代理函数模拟参数和目标间的函数,并设计采集函数来最小化采样步数。这类方法没有考虑以优化资源为目标的调参,只考虑了优化峰值性能。在实际中,除了压测和大促的极端场景,通常用户对TPS是无感的,TPS往往达不到峰值,因此仅考虑性能作为目标还不够。OtterTune系统还提出了基于Internel Metric(数据库状态表的指标)的mapping的方案来利用已有数据,这种mapping方法利用来自同一硬件类型的历史数据,没有充分利用云厂商丰富的数据资源。另一方面,这种方式依赖于预测出来的Internel Metric的相似性计算,在数据点较少的情况下容易不准确。
- 基于强化学习的方法:这类方法是最近数据库调参的热门方向,主要包括SIGMOD18的工作CDBTune[6]和VLDB19的QTune[7]工作。通过将Internal Metrics(state)到Knobs(action)的关系抽象成一个policy neural network和一个value network来反馈,将数据库调参问题转化成一个马尔科夫决策过程,不断地自我训练,学习出最优参数。一方面,这类工作没有考虑优化资源。另一方面,更重要的是调参问题并不是一个带状态的马尔科夫决策过程,因为参数直接决定了数据库性能,不需要复杂的状态空间, 不同于强化学习需要通过解bellman equation来优化模型累计获得的Reward。在这些工作中,往往需要上千步迭代找出好的参数,这难以满足我们在生产环境中进行调参的要求。
5. 问题定义和算法概述
我们将问题定义成带限制的优化问题如下,其中限制条件常数可通过设定为默认配置参数下的TPS和Latency值。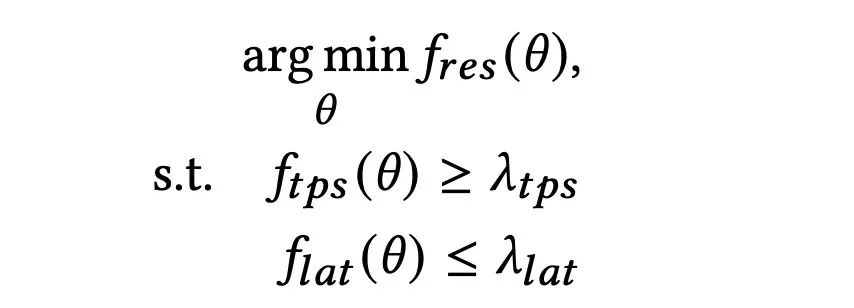
ResTune将最优化资源使用并满足SLA转化成带限制的优化 (Constrained Bayesian Optimization) 问题。相比于传统的贝叶斯优化算法,这里采用了带限制的 EI 函数 (Constrained EI, CEI),我们将限制信息加入了常用的 EI 效用函数(Acqusition Function)。详见论文的第五章内容。
另一方面,为了更好地利用已有数据,ResTune还设计了静态权重和动态权重相结合的高斯加权模型。通过ensemble历史的高斯过程模型,加权平均出目标workload的surrogate函数。这里最核心的问题是如何定义权重。
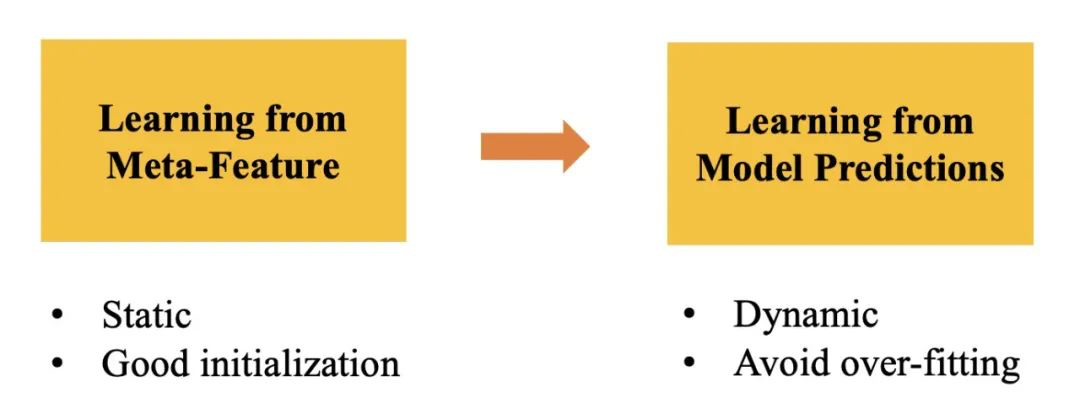
在冷启动时(没有观察数据时),静态权重学习会根据任务工作负载的 meta-feature 距离分配权重。meta-feature 的计算需要通过工作负载的分析,得到工作负载特征向量。
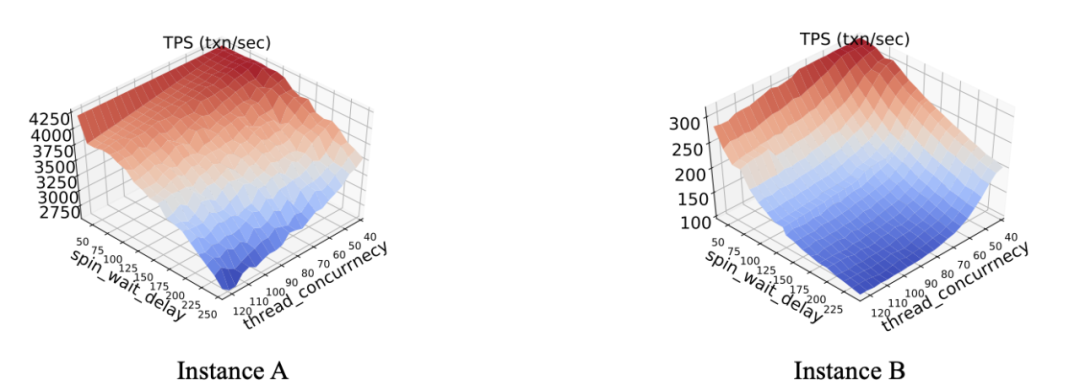
当积累了一定数据(如10条数据)后,ResTune使用动态权重学习策略,通过偏序关系(如下图所示,尽管TPS绝对值不同,但是曲面趋势相同,因此偏序关系也类似),比较历史学习器的预测与目标任务的真实观察结果之间的相似程度。使用动态分配策略,权重会随着对目标工作负载的观察次数的增加而动态更新。通过这两种策略,ResTune最终得到了一个元学习器(Meta-Learner),它可以作为经验丰富的代理模型,更多的细节可以参考论文的第六章内容。
6. ResTune系统设计
ResTune将调参问题抽象成带限制的优化问题,即最小化资源使用率,同时满足SLA的限制。下图给出了ResTune的系统架构设计。ResTune 系统包括两个主要部分:ResTune Client 和 ResTune Server。
- ResTune Client 运行在用户VPC环境中,负责目标任务的预处理和推荐参数配置的执行,由 Meta-Data Processing 模块和 Target Workload Replay 模块组成。
- ResTune Server 运行在后端调参集群中,负责在每次训练迭代中推荐参数配置,包括 Knowledge Extraction 模块和 Knobs Recommendation 模块。
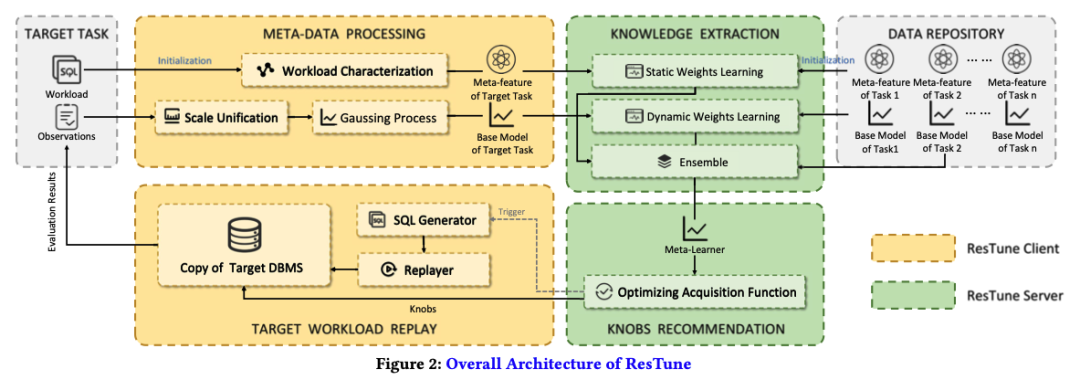
一次调参任务中的一个迭代步流程如下:当一个调参任务开始后,系统首先对目标数据库进行拷贝,并收集一段时间内的目标工作负载到用户环境用于未来的回放。
在每一轮迭代中,目标任务首先通过 Meta-Data Processing 模块得到 meta-feature 与 base model,作为 Knowledge Extraction 模块的输入;Knowledge Extraction 模块负责计算当前任务与历史任务 base model 集成时的静态与动态权重,并对 base models 进行加权求和得到 meta model;在 Knobs Recommendation 模块根据 Meta Learner 推荐一组参数配置;Target Workload Replay 模块对推荐参数进行验证,并将结果写入目标任务的历史观察数据。
以上训练过程重复若干迭代步,当达到最大训练步或提升效果收敛时终止。目标任务训练结束后,ResTune会当前任务的 meta-feature 与观察数据收集到 Data Repository 作为历史数据。
每个模块的具体功能如下:
- Meta-Data Processing: 在调参任务初始启动时,元数据处理模块分析目标任务的工作负载,使用 TF-IDF 方法统计 SQL 保留字作为目标任务的特征向量 (meta-feature);在每轮迭代中,元数据处理模块以历史观察数据为输入,经过归一化处理后,对资源(CPU, memory, IO等)利用率、TPS、Latency 拟合高斯模型,作为目标任务的基模型。
- Knowledge Extraction: 为了提取与利用历史知识,我们提出了采用高斯模型加权求和的集成方式,即元模型 M 的关键参数 u由基模型加权计算得到。在计算基模型权重时采用了静态与动态两种方式。在初始化时,权重的计算采取静态方式,以特征向量作为输入,通过预训练的随机森林,得到资源利用率的概率分布向量,最终以据概率分布向量之间的距离作为任务相似性,决定静态权重。当数据量充足后,ResTune使用动态权重学习策略,比较基学习器的预测与目标任务的真实观察结果之间的相似程度。 使用动态分配策略,权重会随着对目标工作负载的观察次数的增加而更新。通过这两种策略,我们最终得到元学习器,它可以作为经验丰富的代理模型。
- Knobs Recommendation: 参数推荐模块根据元模型推荐一组参数配置;采集函数我们使用了带限制的 EI 函数 (Constrained EI, CEI),其根据限制情况重写了 EI 的效用函数:当参数不满足 SLA 限制时效用置0,且当前最佳参数定义为满足 SLA 限制的最佳参数。CEI 采集函数能够更好的引导探索满足限制的最优区域。
- Target Workload Replay: 目标工作负载回放模块首先推荐参数应用在备份数据库上,并触发工作负载的回放,经过一段时间的运行验证后,验证结果(包括资源利用率、TPS、latency)与推荐参数将一起写入目标任务的观察历史。
7. 实验评测
我们在多个场景下对比了 ResTune 和其它 SOTA (state-of-the-art)系统的性能与速度。
7.1. 单任务场景
首先,在单任务场景下,我们选定CPU利用率作为优化目标,验证了 ResTune 解决带 SLA 限制的优化问题的效果。这里我们测试了Sysbench、Twitter、TPC-C和两个真实的workload:Hotel Booking和Sales。可以看出,ResTune方法在所有负载上都可以得到最佳效果与最佳效率。

7.2. 迁移场景
由于云数据库上存在大量用户各种实例,因此我们提出的方法能否在不同工作负载、不同硬件之间迁移至关重要。同样以CPU利用率作为优化目标,我们测试了不同机器硬件之间的迁移效果,可以看到我们提出的元学习算法带来了显著的训练速度提升和训练效果提升。使得整个ResTune的调参过程能在30-50步左右完成,而非迁移场景通常需要几百个迭代步。
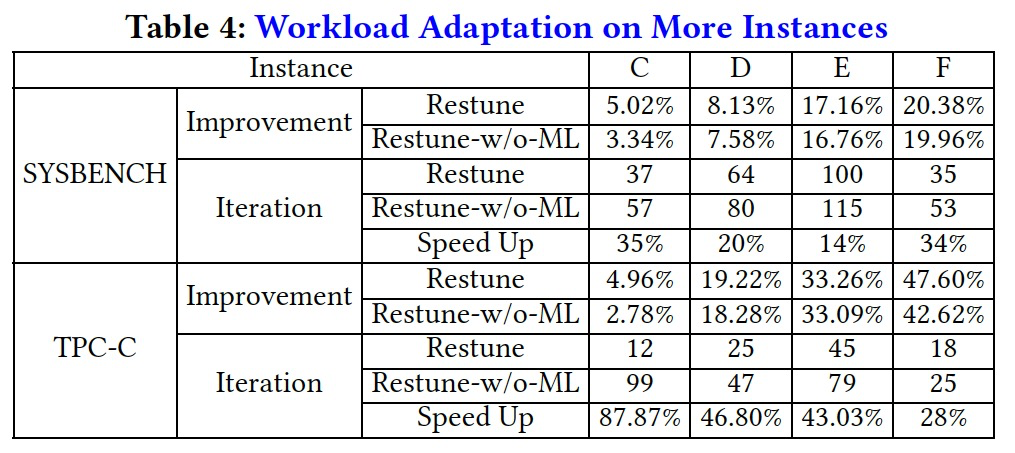
类似的,在不同工作负载之间的迁移实验中,我们的元学习方法也带来了显著的训练速度提升。

7.3. Memory和I/O资源优化
除CPU资源外,我们测试了内存资源、IO资源的调参优化效果。下图可以看出,对于IO资源优化调参任务,ResTune 降低了 84% - 90% IOPS;对于内存资源优化调参任务,ResTune 将内存利用从 22.5G 下降至 16.34G。我们在论文中还估算了TCO的成本减少。

8. DAS业务落地
智能调参技术在DAS(Database Autonomy Service)产品上进行了落地。我们分为不同阶段和细化功能进行上线。主要包括模板功能和基于压测的智能调参功能。阿里云是业界第一个上线调参功能的厂商,领先于腾讯和华为。
8.1. 模板参数功能
模板参数功能是我们一期上线的调参场景。在此之前,云上RDS MySQL数据库仅有一套统一的参数模板,这很难满足云上各不相同的用户业务负载。因此,我们选取了不同种类的benchmark,在用户使用最频繁的RDS Instance类型上调参的离线训练。
我们将用户负载分为典型的6种场景如交易、社交网络、压测等,通过离线训练我们给每一种典型场景训练出了最优配置,并提供给用户根据其业务特征进行选择。这样我们将之前的RDS的统一一套参数模板扩展到了多种典型的OLTP业务场景。
下表列出了我们离线调参训练的结果,在不同workload上有13%-50%的提升。这里我们以TPS性能作为优化目标。
| Workload名称 | RDS默认配置下的TPS | 调参后的TPS | 提升百分比 |
| TPCC(订单处理) | 620 | 940 | ↑52% |
| Smallbank(银行业务处理) | 17464 | 22109 | ↑26.6% |
| Sysbench(压力测试) | 7950 | 10017 | ↑26% |
| Twitter(社交网络) | 41031 | 48946 | ↑19.2% |
| TATP(通信) | 18155 | 21773 | ↑19% |
| YCSB(压力测试) | 41553 | 55696 | ↑34% |
| Wikipedia(知识百科) | 600 | 678 | ↑13% |
8.2. 基于压测的智能调参功能Cloudtune
以上基于模板参数功能验证了云上用户对智能调参功能的需求。事实上,除了特别专业的用户,大部分用户较难非常准确地把握其业务特征。因此,用户无法选出最合适其workload特点的一组参数模板。
为了解决用户痛点,我们在DAS上线了基于压测的智能调参功能。主要通过收集并回放用户真实workload(在用户VPC环境进行保证安全性),来针对用户业务负载,定制化地训练出性能最优的参数配置。这个功能我们叫做Cloudtune智能调参。
如前文ResTune的架构设计,我们首先需要在用户VPC环境准备一个用户数据库RDS目标实例,然后启动一个压测肉机进行用户环境真实workload的回放,并采集目标实例上的性能数据进行调参训练。DAS Master用户打通线上VPC环境和后端网络环境。后端DAS App负责调参的主控逻辑,主要操作在用户VPC环境的回放压测,从而获取相应Metric(资源使用率、TPS、Latency等),然后通过调用Cloudtune Microservice来进行迭代训练,Cloudtune Service通过算法模型给出下一个采样配置和目前为止找出的最好配置参数。
9. 未来工作
目前上线的调参功能是通过拉库回放的方式,对用户来说是一种离线的操作,且相对繁琐。我们正在为帮用户简化去这个过程进行在线动态调参。
在线动态调参技术的挑战和要求更高,首先,参数调节效果要求稳步提升,不能让系统运行时出现性能猛烈的下降,不能影响线上实时的服务;其次,为了保证线上稳定性和调节过程快速收敛,在线动态调参需要针对不同的workload自动选择关键的相关参数进行调节;最后,目前的工作假设用户负载变化不频繁,一旦用户负载变化就需要重新进行调参。为了提高用户体验,要结合workload的检测支持自适应的调参服务。
10. 智能数据库其他研究工作简介
智能数据库团队以数据库运维和内核智能化为主要方向,深度融合人工智能、机器学习和数据库专家经验,使数据库具备自治能力,实现自感知、自优化、自修复与自安全,保障服务的稳定、安全及高效。对外提供业内首个智能数据库管控平台Database Autonomy Service (DAS) 。
相关工作还包括异常SQL检测之大海捞针、一键智能压测与基于压缩感知的数据库生成、采样算法和SQL workload外置优化、图多模数据异常检测与根因诊断、索引推荐、冷热数据分离、基于实例知识图谱的智能调度、NLP2SQL人机交互接口、计算平台一体化、One-sided RDMA内存池化系统研发等。例如,DAS团队在VLDB2020上发表的工作Leaper[2]有效地进行数据预取和Cache淘汰,解决了LSM-Tree存储引擎架构的性能抖动,是学术界将机器学习模型集成到在OLTP数据库内核的重要尝试。
最近DAS基于统计与医疗数据分析中的生存分析设计了全新的冷热数据分层算法,集成至Polar X Engine中,测试显示性能提升10%,存储成本下降25%。同样在VLDB2020年发表的慢SQL诊断工作,DAS解决了海量SQL请求中近90%的CPU密集型的异常问题。
参考文献
[1] Zhang, Xinyi, Hong Wu, Zhuo Chang, Shuowei Jin, Jian Tan, Feifei Li, Tieying Zhang, and Bin Cui. "ResTune: Resource Oriented Tuning Boosted by Meta-Learning for Cloud Databases." In Proceedings of the 2021 International Conference on Management of Data, pp. 2102-2114. 2021.
[2] Yang, Lei, Hong Wu, Tieying Zhang, Xuntao Cheng, Feifei Li, Lei Zou, Yujie Wang, Rongyao Chen, Jianying Wang, and Gui Huang. "Leaper: a learned prefetcher for cache invalidation in LSM-tree based storage engines." Proceedings of the VLDB Endowment 13, no. 12 (2020): 1976-1989.
[3] Y.Zhu,J.Liu,MengyingGuo,YungangBao,WenlongMa,ZhuoyueLiu,Kunpeng Song, and Yingchun Yang. 2017. BestConfig: tapping the performance potential of systems via automatic configuration tuning. Proceedings of the 2017 Symposium on Cloud Computing (2017).
[4] SongyunDuan,VamsidharThummala,andShivnathBabu.2009.TuningDatabase Configuration Parameters with ITuned. Proc. VLDB Endow. 2, 1 (Aug. 2009), 1246–1257.
[5] Dana Van Aken, Andrew Pavlo, Geoffrey J. Gordon, and Bohan Zhang. 2017. Automatic Database Management System Tuning Through Large-scale Machine Learning. In Acm International Conference on Management of Data. 1009–1024.
[6] Ji Zhang, Yu Liu, Ke Zhou, Guoliang Li, Zhili Xiao, Bin Cheng, Jiashu Xing,
Yangtao Wang, Tianheng Cheng, Li Liu, Minwei Ran, and Zekang Li. 2019. An End-to-End Automatic Cloud Database Tuning System Using Deep Reinforce- ment Learning. In Proceedings of the 2019 International Conference on Management of Data (Amsterdam, Netherlands) (SIGMOD ’19). Association for Computing Ma- chinery, New York, NY, USA, 415–432.
[7] Guoliang Li, Xuanhe Zhou, Shifu Li, and Bo Gao. 2019. QTune. Proceedings of the Vldb Endowment (2019)
[8]Tan, J., Zhang, T., Li, F., Chen, J., Zheng, Q., Zhang, P., ... & Zhang, R. (2019). ibtune: Individualized buffer tuning for large-scale cloud databases. Proceedings of the VLDB Endowment, 12(10), 1221-1234.
原文链接
本文为阿里云原创内容,未经允许不得转载。











)
V2.0.3 去广告版...)






