简介: Delta Lake 和 Hudi 是流行的开放格式的存储层,为数据湖同时提供流式和批处理的操作,这允许我们在数据湖上直接运行 BI 等应用,让数据分析师可以即时查询新的实时数据,从而对您的业务产生即时的洞察。MaxCompute 在湖仓一体架构中,通过支持 Delta Lake 和 Hudi 在数据湖中提供数据仓库性能。
本文作者 孟硕 阿里云智能 产品专家
直播视频请点击 直播观看
一、最佳实践背景
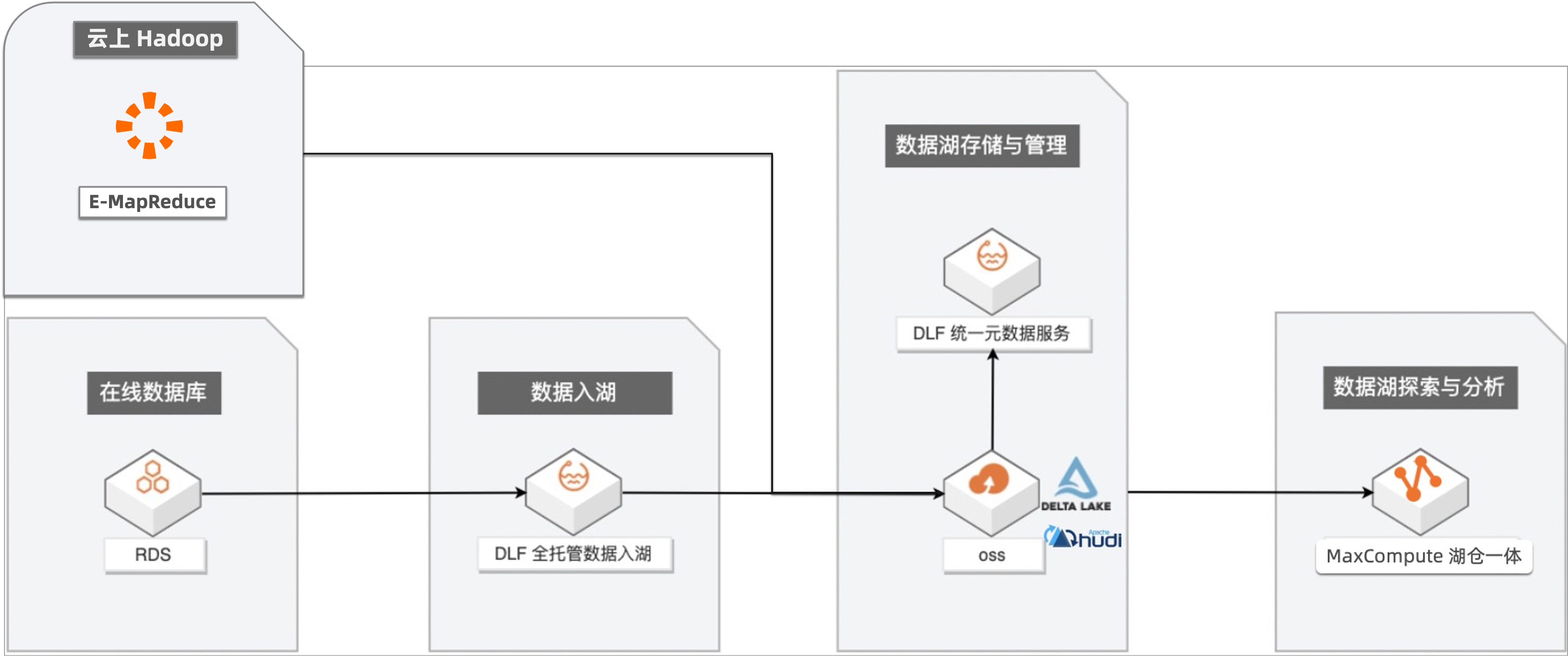
整个最佳实践是基于MaxCompute的湖仓一体架构,模拟公司使用场景。比如公司 A 使用云上关系型数据库 RDS 作为自己的业务库,同时使用阿里云 EMR 系统做日志数据采集。将数据汇集到云上对象存储 OSS 上,引入了数据湖常会用的存储机制 Delta Lake 和 Hudi 为数据湖提供流处理、批处理能力。通过 MaxCompute 查询到实时数据,即时洞察业务数据变化。 整个场景demo的架构是,云上EMR产生的实时变化的数据,包括在线数据库RDS,通过数据入湖,然后实时的把数据变化体现在归档的OSS 上。同时MaxCompute跟其他引擎一起分析OSS上的数据。
湖仓一体架构:异构数据平台融合
因为企业内部会有很多业务线,不同的部门,因为本身业务的需求及员工的技术栈几个方面的原因,导致采用的数据架构不一样,数据平台也不一样。技术架构有Hadoop技术体系,也有云上全托管架构,所以造成不同的部门对技术架构,使用的技术平台不一样,也造成了数据割裂的情况。湖仓一体就是帮助企业把异构数据平台做一个打通,底层数据可以相互访问,中间元数据层也可以做到互相透视,数据可以做到自由流动。数据湖部分不只是支持EMR,也支持ESC Hadoop和云下IDC Hadoop。其中MaxCompute数据仓库也可以和数据湖EMR做一个数据打通,在用MaxCompute跟联播数据源做一个联播查询,这样可以把所有的数据在MaxCompute中做一个汇总。比如有三张表,在RDS和Hive中,同事MaxCompute里有大量事实表,如果需求是对这个三个表做一个联合查询,通过这个架构,可以很方便的做到这一点。
更快的业务洞察
- DataWorks 自助开通湖仓一体:5分钟打通异构数据平台(Hadoop/ DLF+OSS )
更广泛的生态对接
- 支持对接阿里云云原生数据湖构建(DLF)
- 支持查询 DeltaLake、Hudi 格式
- 支持对接更多外部联邦数据源 Hologres (RDS、HBaseUpcoming! )
更高的性能
- 智能 Cache 实现 OSS/ HDFS 数据访问加速
- 湖数据查询加速
更好的综合数据开发与治理
- 跨引擎开发和调度
- 统一湖/仓数据开发体验
- 统一湖/仓全局资产管理
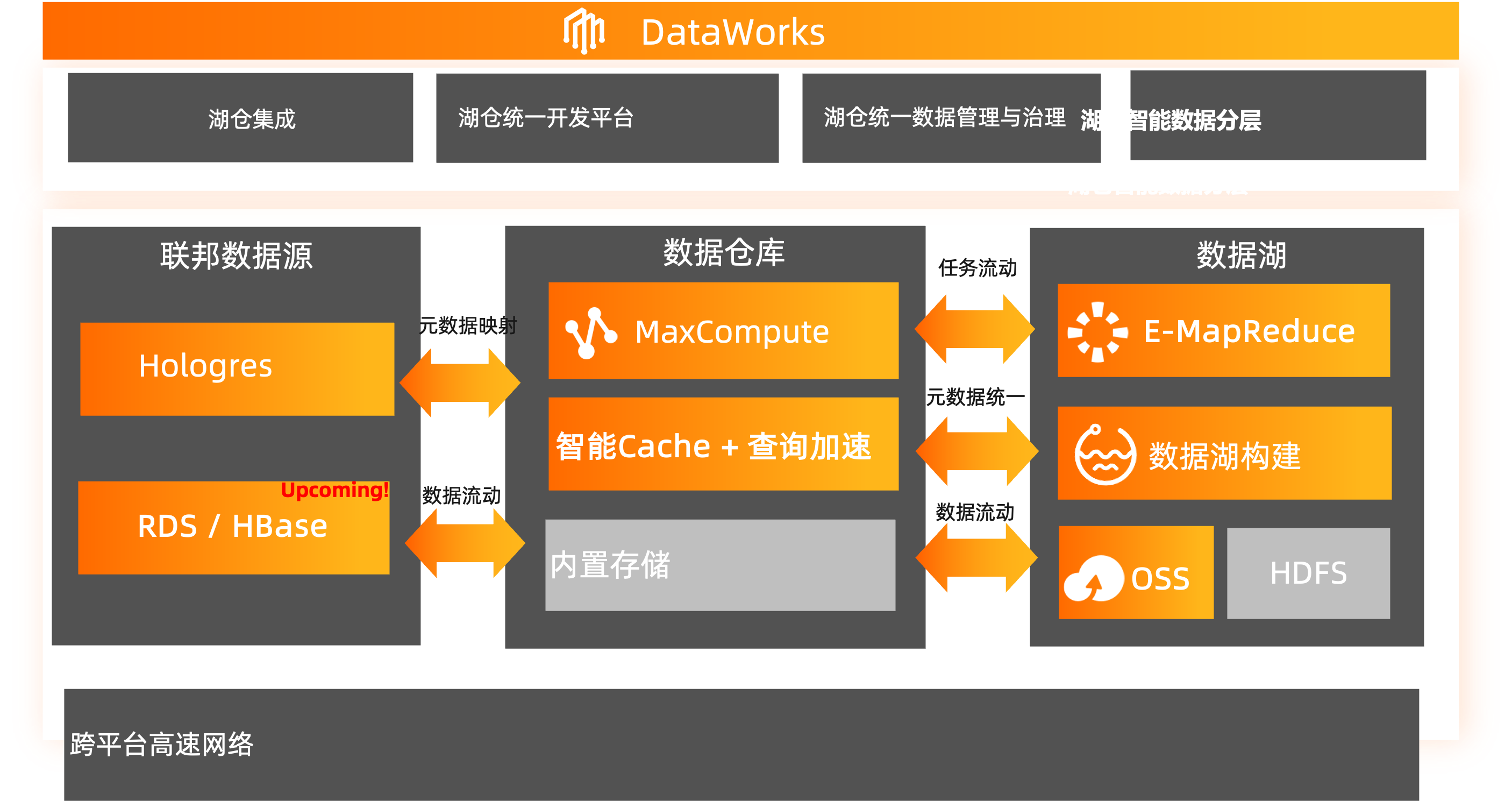
湖仓一体的架构
首先看右侧部分,是跟OSS和DLF侧的打通,因为在OSS 上我们归档大量的半结构化和结构化的数据。有关系型数据库,有nosql数据库,可以通过DLF组件把OSS上的元数据爬取出来。相比于在MaxCompute上创建OSS外表访问OSS数据,现在通过DLF统一自动识别OSS schema,MaxCompute直接映射这种方式,会更方便一些。一些数据的更新,schema的变更,DLF也可以自动识别到。同时DLF里面有用户权限管理,后续会陆续上线。也就是说对于OSS对接的引擎,统一的数据访问权限会收敛到DLF里。
左侧是对Hadoop生态系统的打通,Hadoop包括阿里云半托管的EMR,开源的on ECS和IDC Hadoop,也包含主流的发行版CDH,也都可以做打通。下方再加上联邦数据源。通过MaxCompute可以连接到各种各样的云上数据源,通过上传DataWorks做统一的开发和管理,以及数据治理。 这样就有一个全域数据资产视图,开发工作数据也能联通,元数据也能投射到DataWorks之上。这就是整个湖仓一体的架构。

二、相关产品介绍
数据湖构建DataLakeForamtion
DLF主要是针对OSS数据,做一个托管,上层对接其他引擎如EMR、Databricks、Datalnsight、PAI、MaxCompute、Hologres。这些引擎可以共享一份元数据在DLF上。后续企业可以根据不同部门,不同业务场景随意切换引擎。后期我们也会逐渐完善访问控制,以及一些企业级能力,比如安全,包括数据分层等。

数据入湖
- 支持多种数据源入湖,MySQL、SLS、OTS、Kafka等
- 离线/实时入湖,支持Delta/Hudi等多种数据湖格式
- 数据入湖预处理,支持字段mapping/转换/自定义udf操作
元数据管理
- 统一元数据管理,解决元数据多引擎一致性问题
- 兼容开源生态API
- 自动生成元数据,降低使用成本
访问控制
- 集中数据访问权限控制,多引擎统一集中式赋权
- 数据访问日志审计,统计数据访问信息
三、最佳实践Demo
整体架构
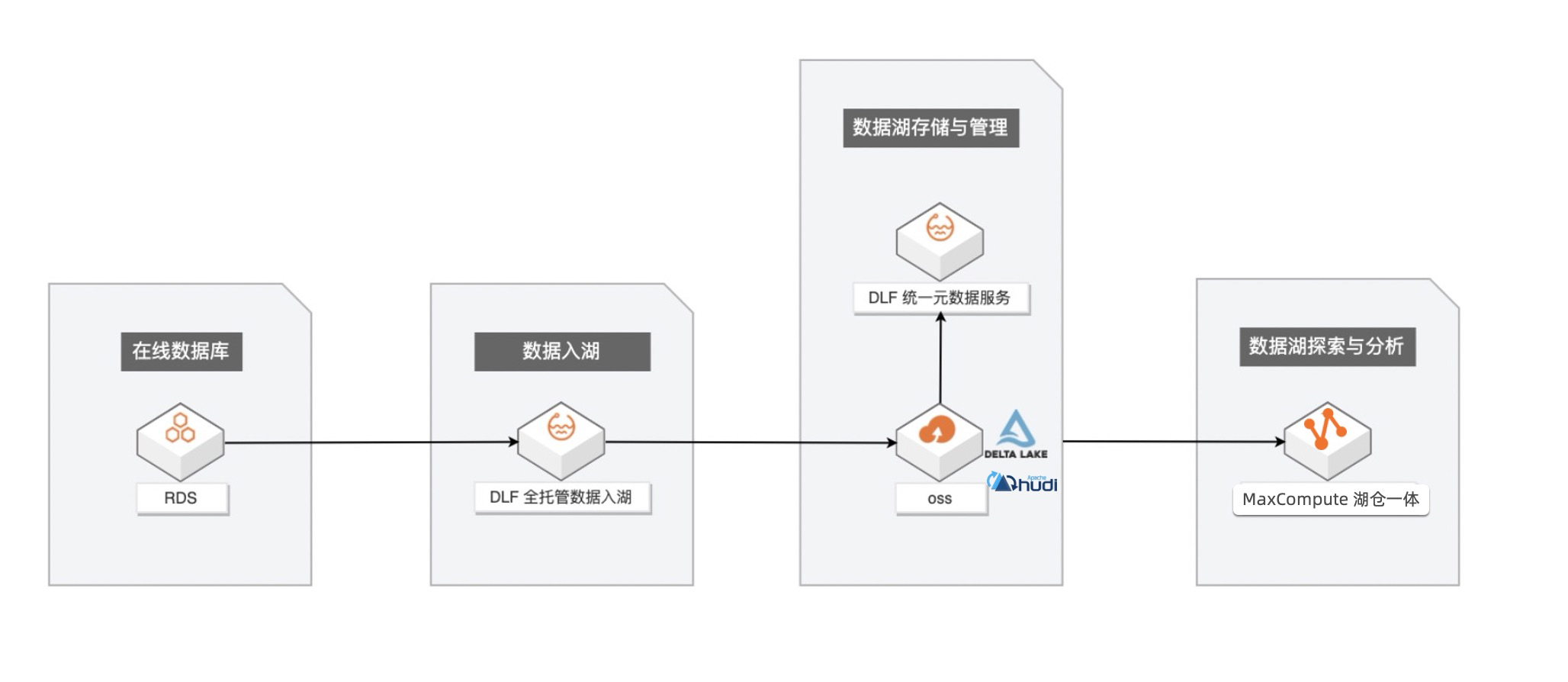
企业构建和应用数据湖一般需要经历数据入湖、数据湖存储与管理、数据探索与分析等几个过程。主要介绍基于阿里云 MaxCompute、数据湖构建(DLF)+ 对象存储(OSS)构建一站式的数据入湖与分析实战。其主要数据链路如下:
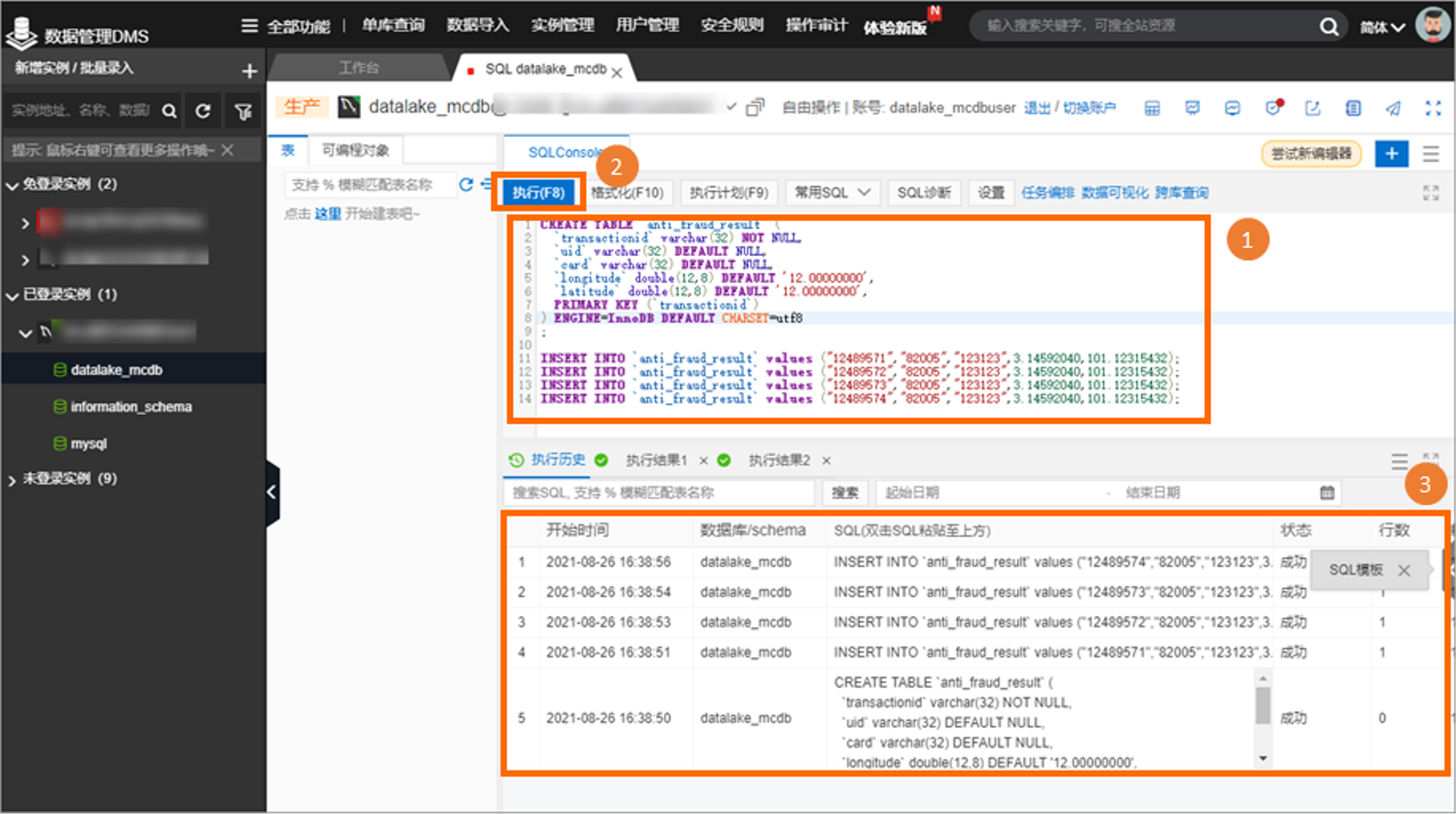
第一步:RDS数据准备
RDS 数据准备,在 RDS 中创建数据库 academy_db。在账户中心创建能够读取 employees 数据库的用户账号。通过DMS登录数据库,运行一下语句创建 anti_fraud_result 表,及插入少量数据。
CREATE TABLE `anti_fraud_result` (`transactionid` varchar(32) NOT NULL,`uid` varchar(32) DEFAULT NULL,`card` varchar(32) DEFAULT NULL,`longitude` double(12,8) DEFAULT '12.00000000',`latitude` double(12,8) DEFAULT '12.00000000',PRIMARY KEY (`transactionid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
;INSERT INTO `anti_fraud_result` values ("12489571","82005","123123",3.14592040,101.12315432);
INSERT INTO `anti_fraud_result` values ("12489572","82005","123123",3.14592040,101.12315432);
INSERT INTO `anti_fraud_result` values ("12489573","82005","123123",3.14592040,101.12315432);
INSERT INTO `anti_fraud_result` values ("12489574","82005","123123",3.14592040,101.12315432);
第二部:DLF数据入湖
- 进入DLF控制台界面:阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台,点击菜单 数据入湖 -> 数据源管理-> 新建数据源。输入数据库相关连接信息
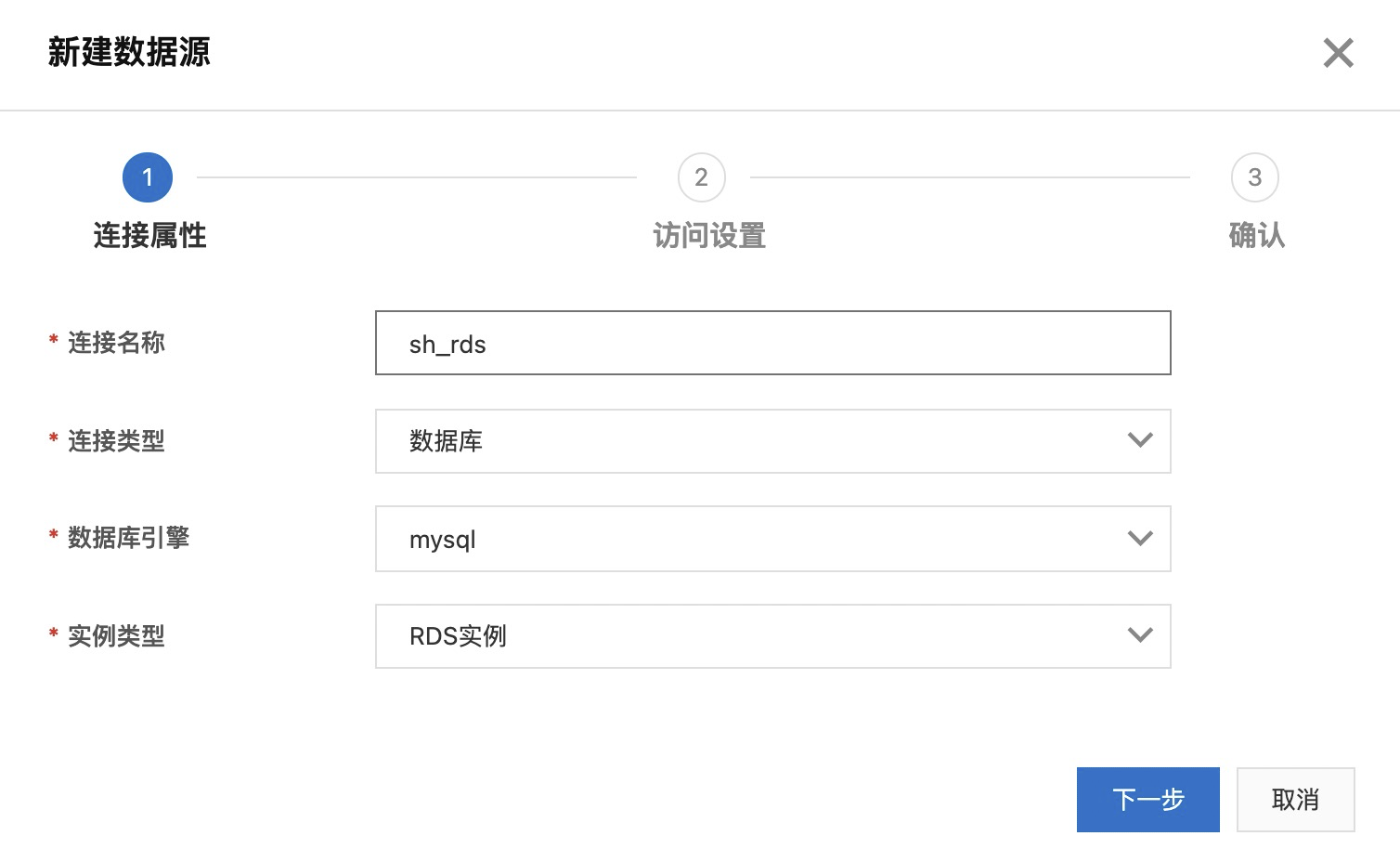
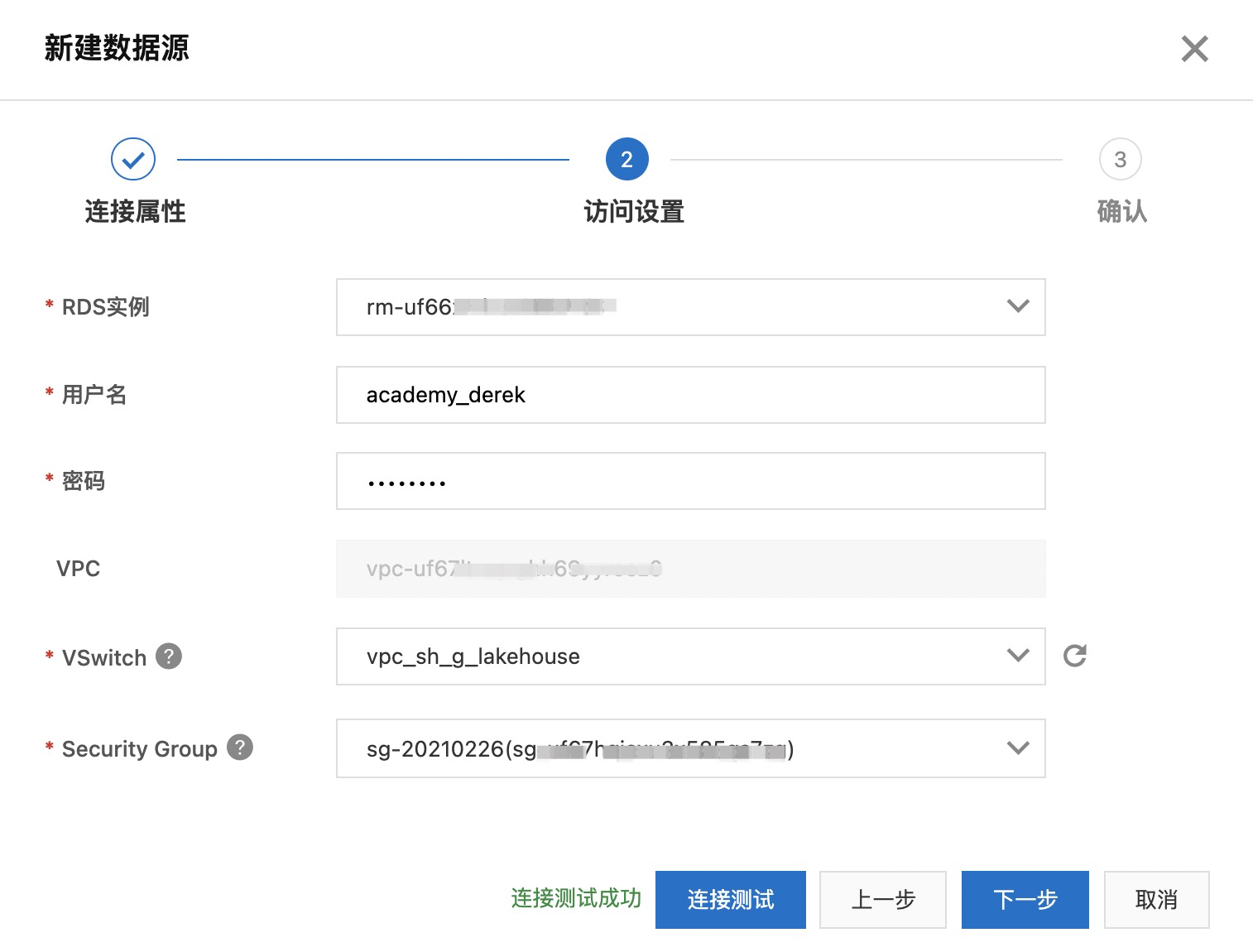
填写 RDS 实例、登录信息以及网络和安全组信息后,点击“连接测试”
- 在 OSS 中新建 Bucket 和目录,如 bucket: rtcompute,目录:oss://rtcompute/csvfile/
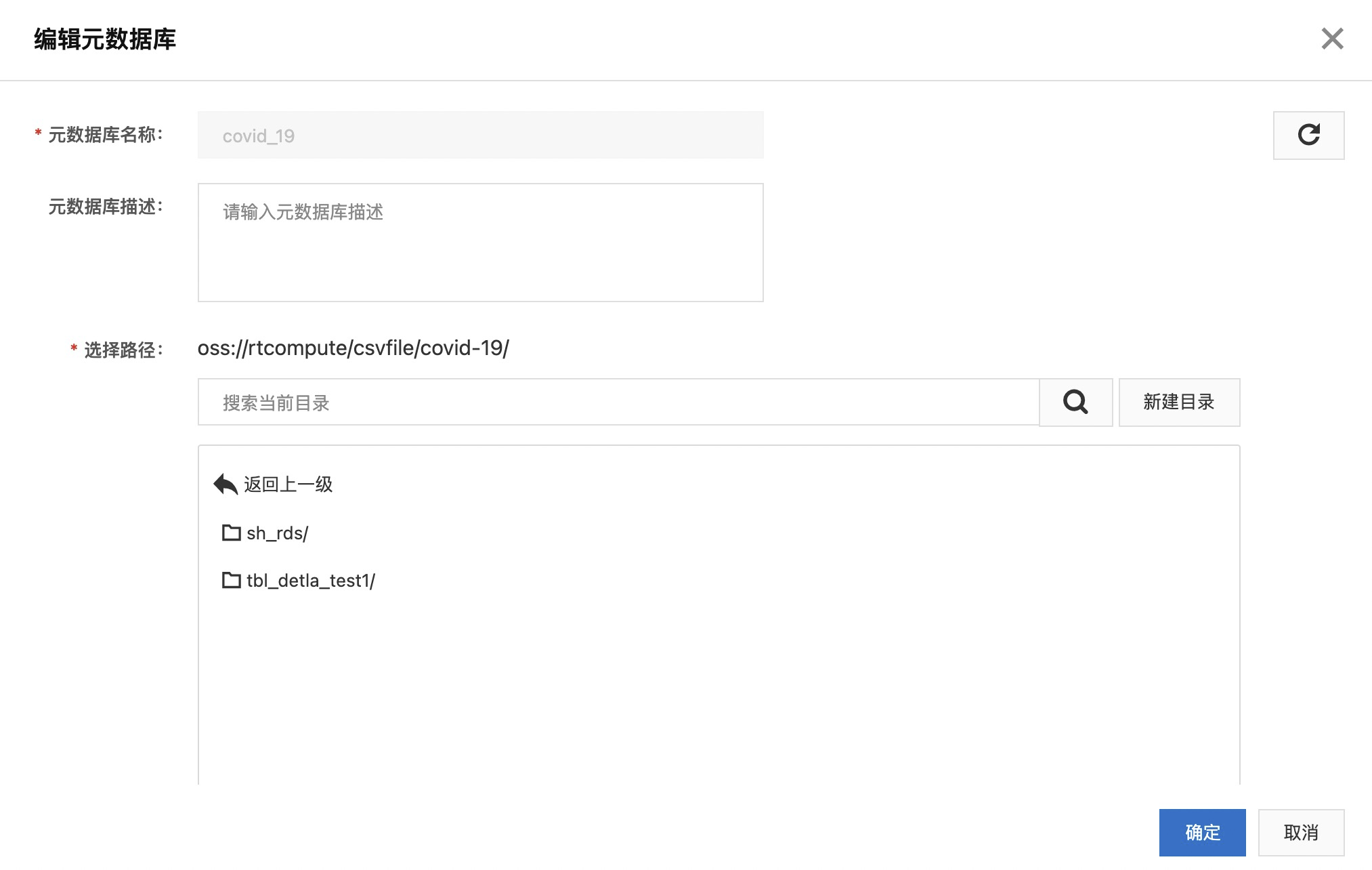
- 在 DLF 控制台界面点击左侧菜单“元数据管理”->“元数据库”,点击“新建元数据库”。填写名称 covid-19,新建目录并选择。
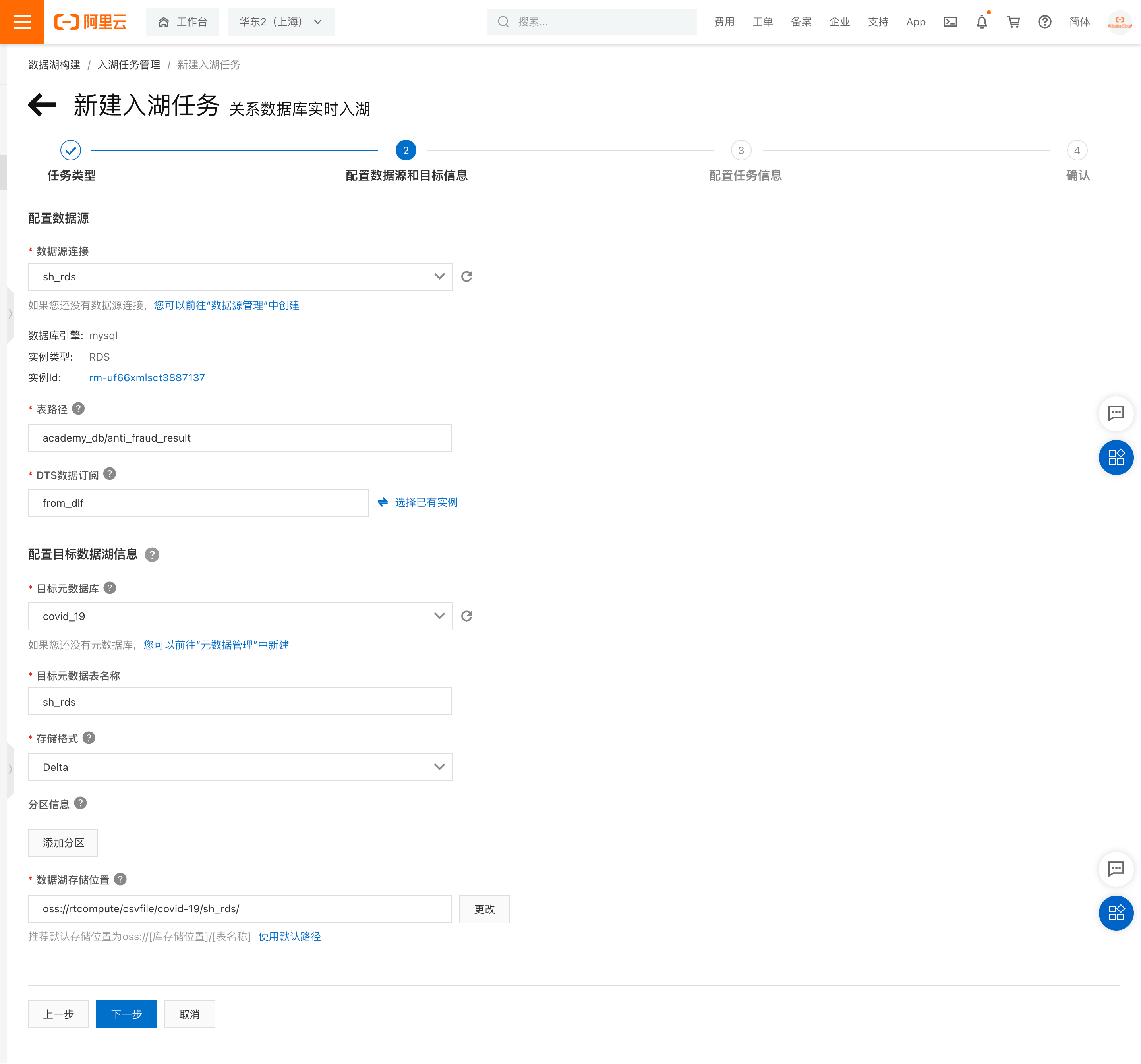
- 创建入湖任务:
a. DLF 控制台中点击菜单“数据入湖”->“入户任务管理”,点击“新建入湖任务” -> 选择“关系数据库实时入湖”,按照下图的信息填写数据源、目标数据湖、任务配置等信息。并保存。
如果是 Hudi 格式,在“存储格式”中可以选择 Hudi:
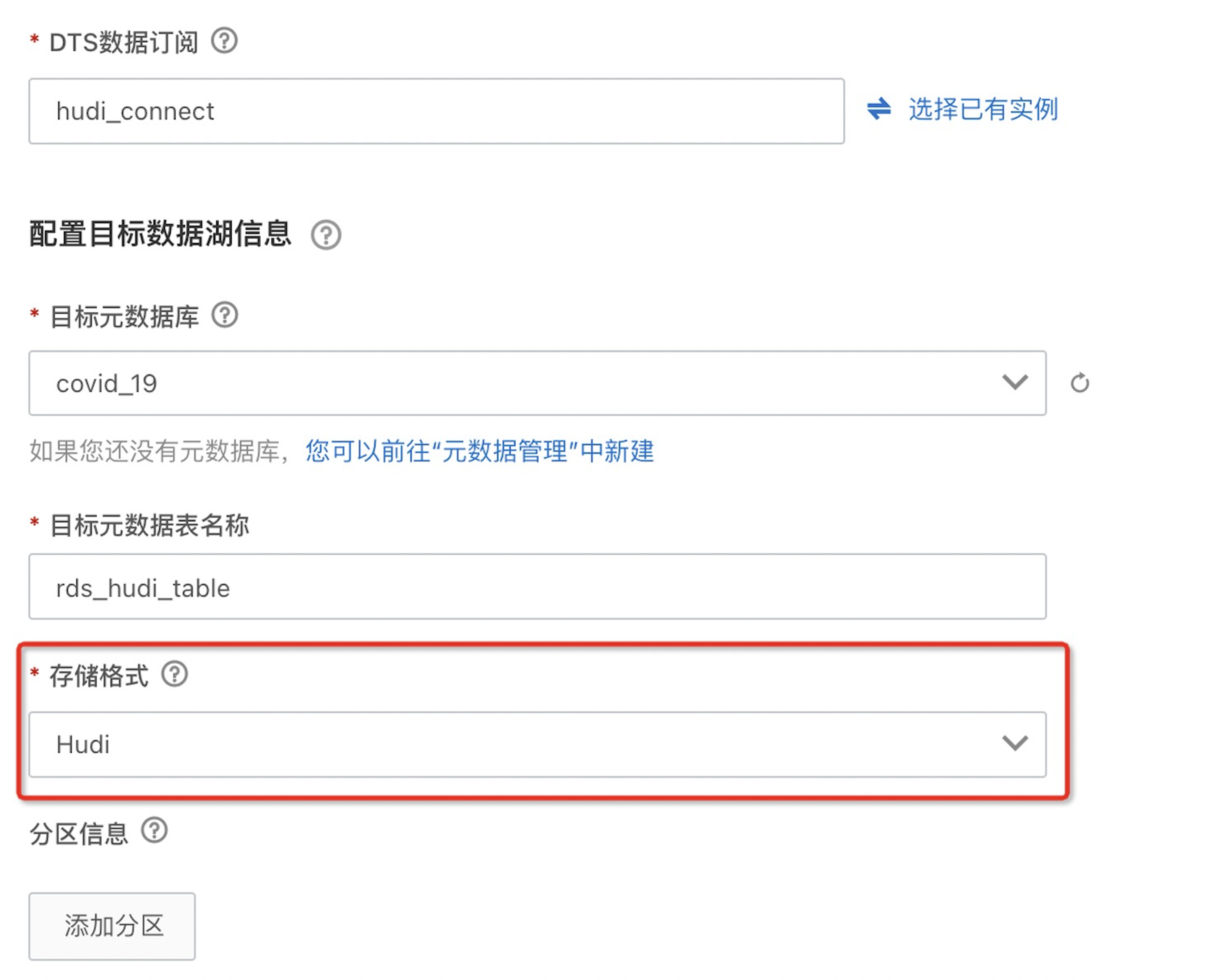
b. 下一步输入任务实例名称,RAM角色以及最大资源使用量,点击下一步确认信息
c. 在 DLF 控制台“入户任务管理” 界面中,找到刚创建的入湖任务列表,点击“运行”启动入湖作业;该数据入湖任务,属于全量+增量入湖,大约3至5分钟后,全量数据会完成导入,随后自动进入实时监听状态。如果有数据更新,则会自动更新至 Delta Lake 或 Hudi 数据格式中。
第三步:MaxCompute中查询数据
开通 DataWorks 与 MaxCompute (快速启动请参考 文档),并进入 DataWorks 临时查询界面(请参考文档)
- 创建 MaxCompute 外部 Project 映射 DLF 元数据:
create externalproject -source dlf -name ext_dlf_delta-ref ms_proj1-comment "DLF"-region "cn-shanghai"-db covid_19-endpoint "dlf-share.cn-shanghai.aliyuncs.com"-ossEndpoint "oss-cn-shanghai-internal.aliyuncs.com";-- 显示映射表信息 show tables in ext_dlf_delta;
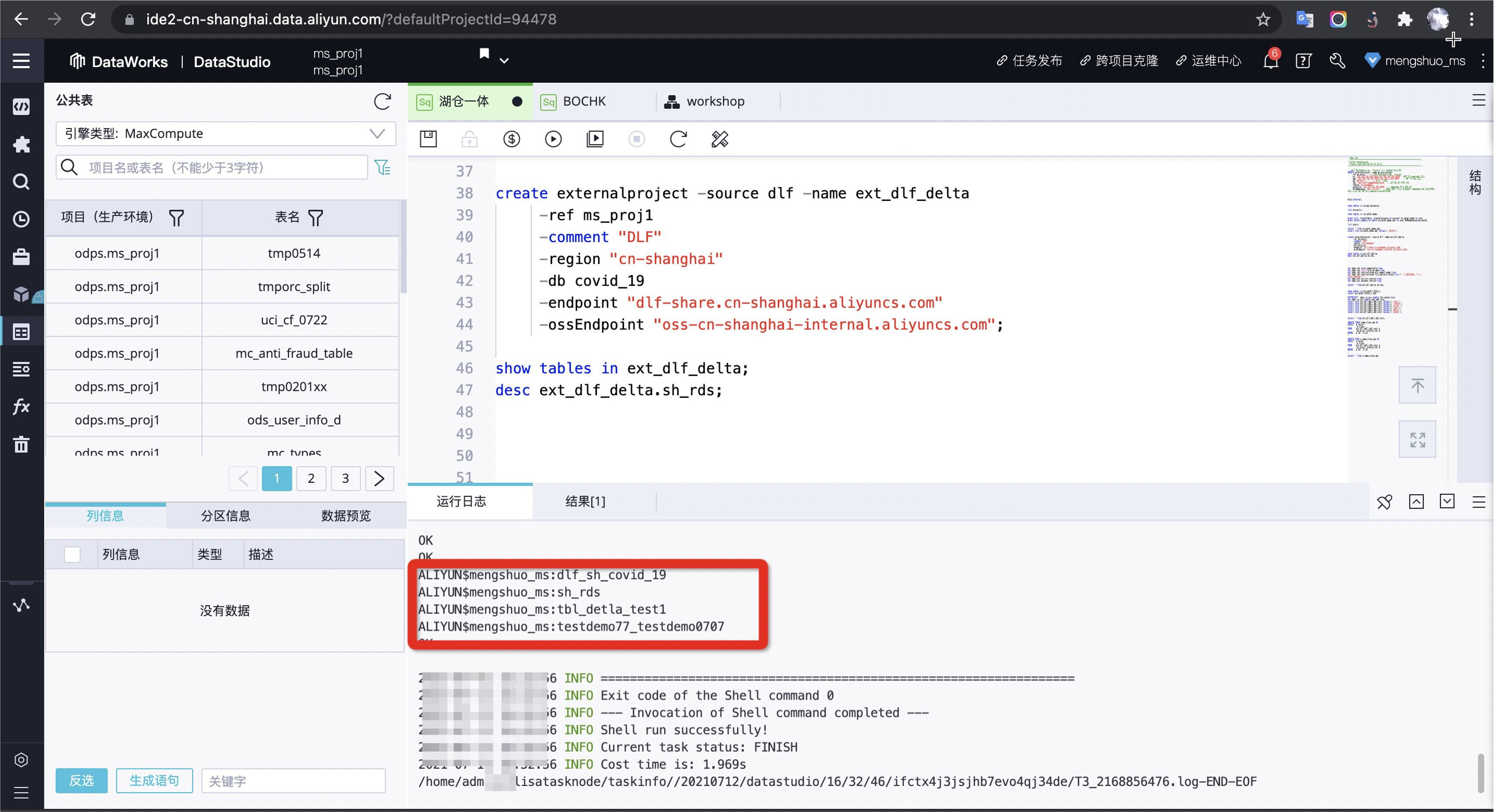
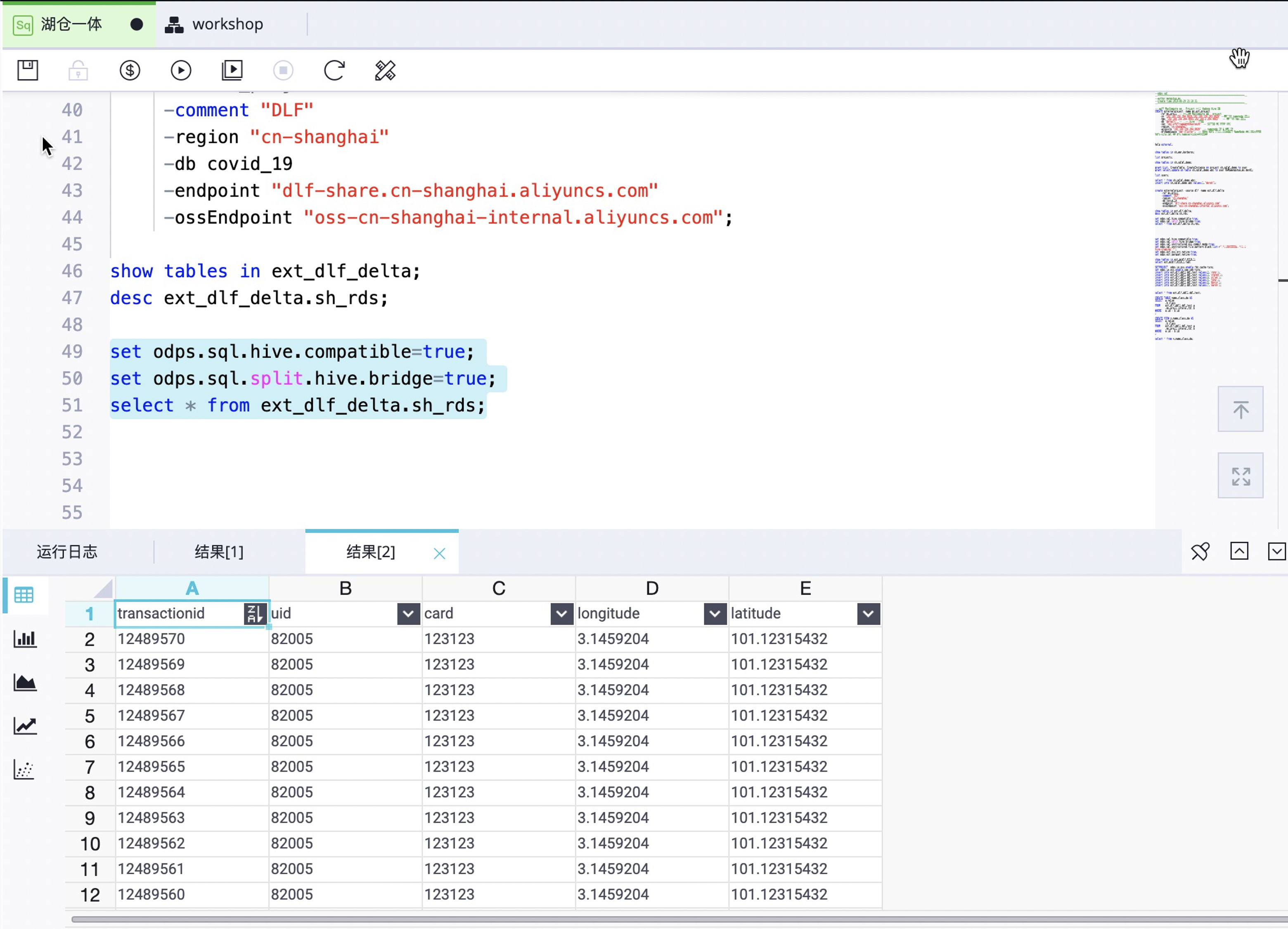
- 查询数据:
set odps.sql.hive.compatible=true; set odps.sql.split.hive.bridge=true; select * from ext_dlf_delta.sh_rds;
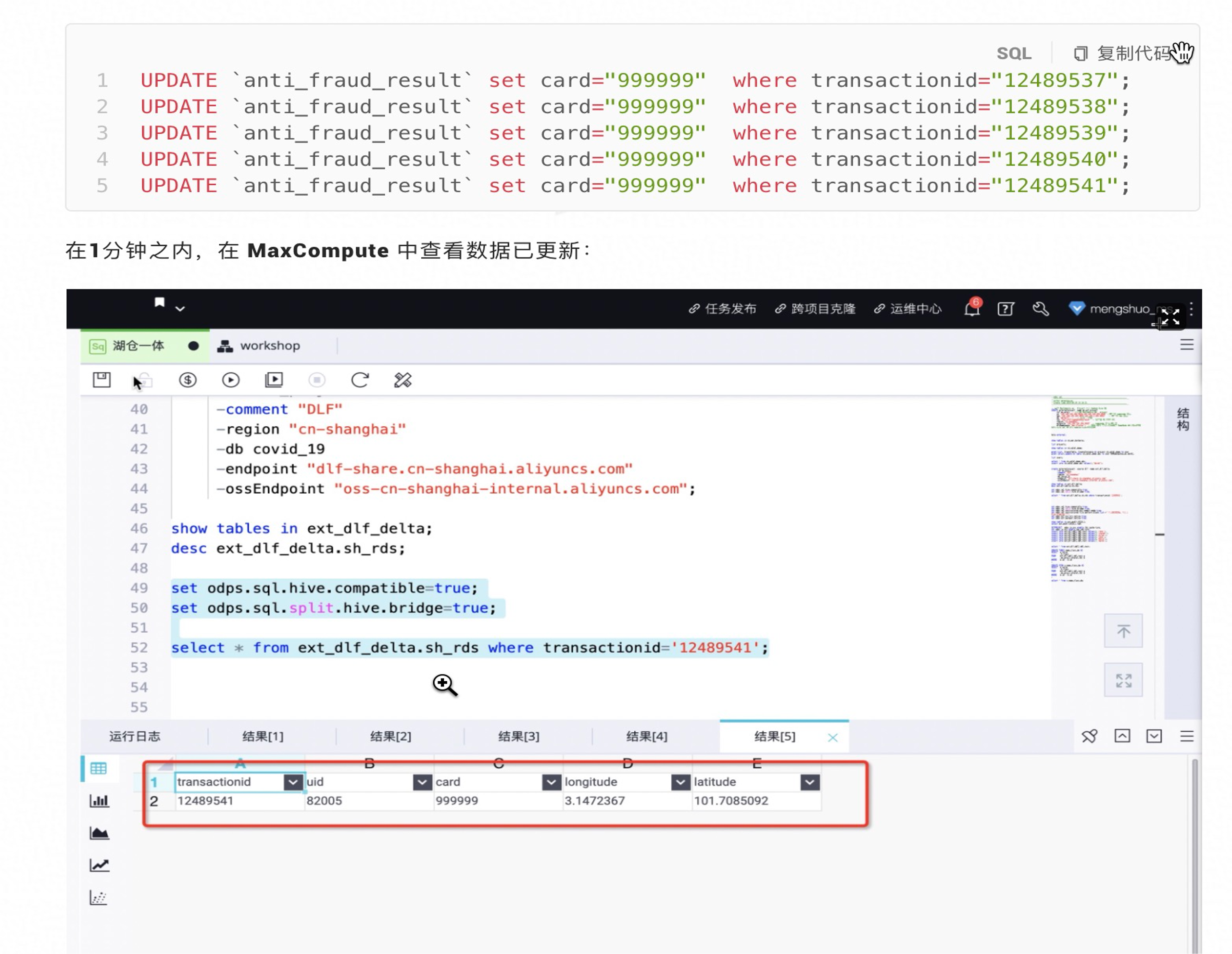
第四部:RDS中新增数据
INSERT INTO `anti_fraud_result` values ("12489575","82005","123123",3.14592040,101.12315432);
INSERT INTO `anti_fraud_result` values ("12489576","82005","123123",3.14592040,101.12315432);
INSERT INTO `anti_fraud_result` values ("12489577","82005","123123",3.14592040,101.12315432);
INSERT INTO `anti_fraud_result` values ("12489578","82005","123123",3.14592040,101.12315432);
INSERT INTO `anti_fraud_result` values ("12489579","82005","123123",3.14592040,101.12315432);
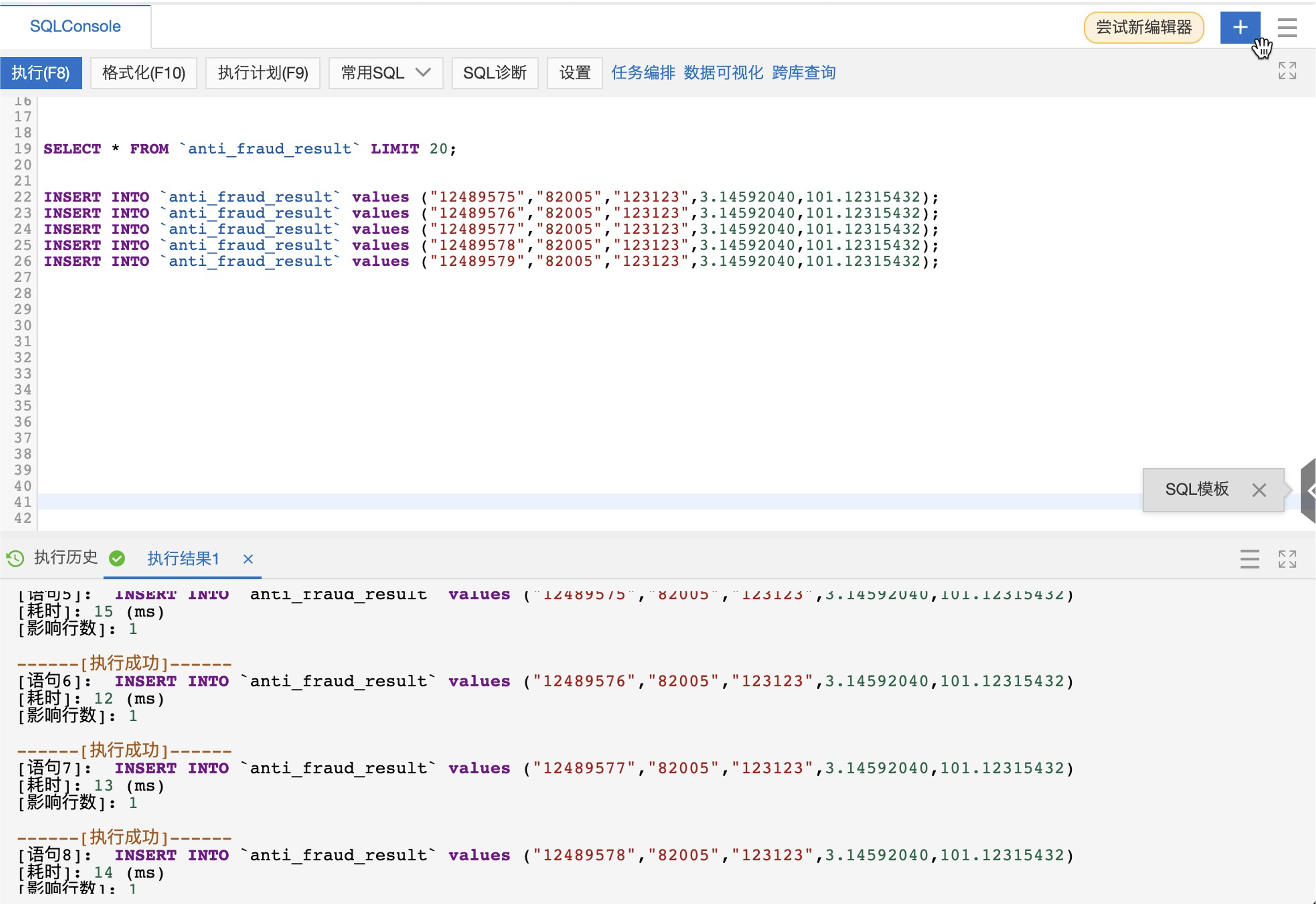
MaxCompute中校验数据
set odps.sql.hive.compatible=true; set odps.sql.split.hive.bridge=true; select * from ext_dlf_delta.sh_rds;
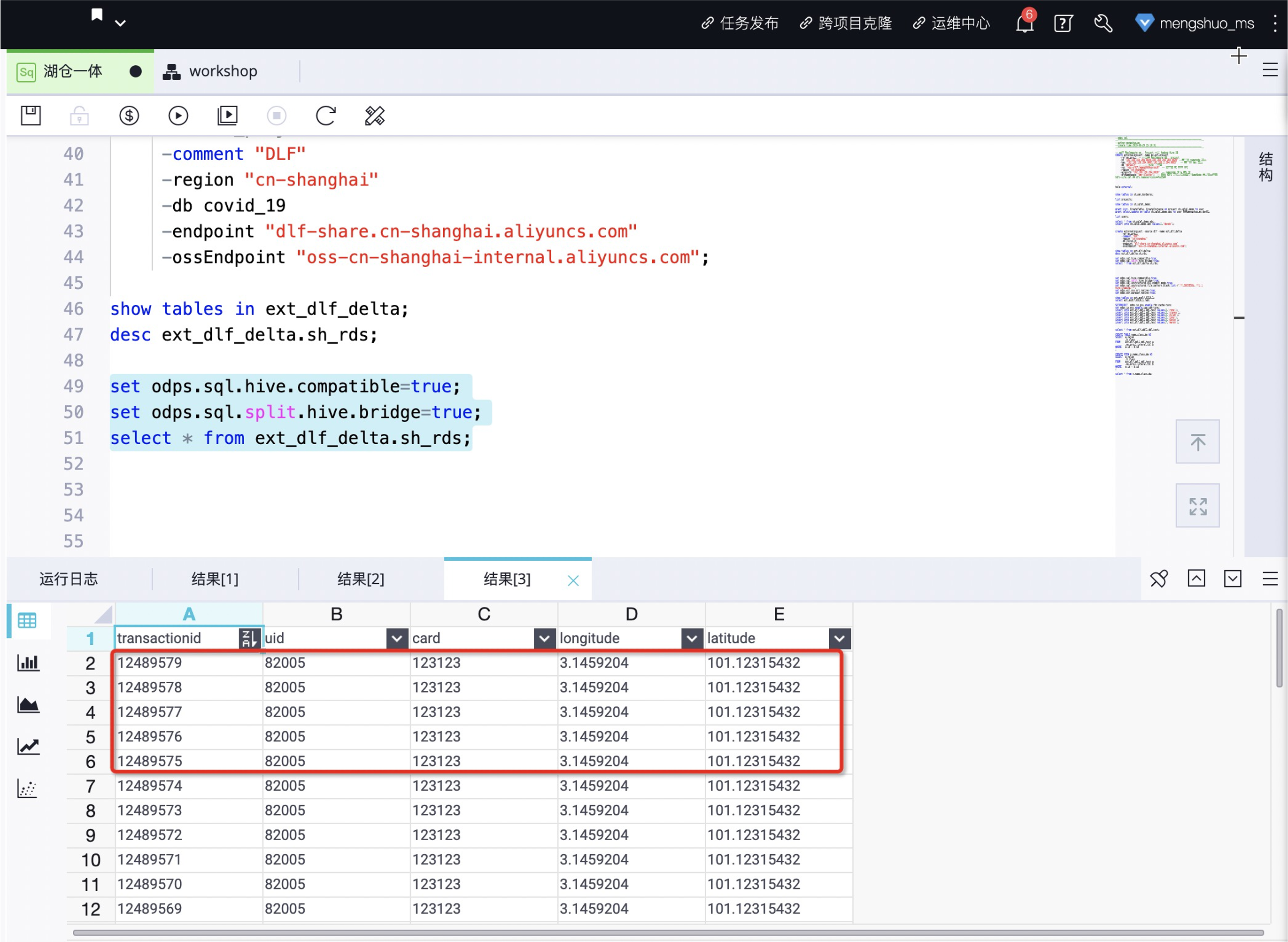
在1分钟之内,在 MaxCompute 中查看数据已更新:
原文链接
本文为阿里云原创内容,未经允许不得转载。
)



)





)






如何为客户业务的确定性、连续性保驾护航)

