摘要:2021云栖大会云原生企业级数据湖专场,阿里云智能资深技术专家、对象存储 OSS 负责人罗庆超为我们带来《云湖共生-释放企业数据价值》的分享。本文主要从数据湖存储演进之路、数据湖存储3.0 进化亮点等方面分享了云湖共生带来的企业价值。
摘要:2021云栖大会云原生企业级数据湖专场,阿里云智能资深技术专家、对象存储 OSS 负责人罗庆超为我们带来《云湖共生-释放企业数据价值》的分享。

本文主要从数据湖存储演进之路、数据湖存储3.0 进化亮点等方面分享了云湖共生带来的企业价值。
以下是精彩视频内容整理:
数据湖存储演进之路
众所周知,数据湖是一个存算分离的架构。这个架构带来的好处是存储和计算是解耦地部署及扩展的,从而实现整体系统的弹性能力。我回忆了一下数据湖存储1.0时一个客户的情况。他有一个很大的 HDFS 集群,里面存了大量的历史数据,这时候想扩计算了,但是发现计算不能直接 run 在上面,因为会影响到现有集群的稳定性。就要单独扩额外的机器来做计算的集群,扩的时候集群又变庞大了,对运维的稳定性又带来了挑战。所以当时客户就选择了存算分离的数据湖技术。好处就是把所有的数据都放到分离的对象存储上面,就可以继续跑计算集群,run Hadoop 的计算生态。为了兼容对象存储的接口和传统 Hadoop 应用的 HDFS 接口的要求,他还会部署一个 HDFS 的集群,来支撑这样的一个应用。那这个集群,就可以把传统的应用很好的 run 起来,而且他还可以提供性能优化的能力,这是数据湖1.0解决的一个问题。
随着数据湖1.0大量客户的使用,可以看到上面的应用越来越多。从 Hadoop 的应用到计算引擎,不同的计算引擎再到 AI,上面的计算生态越来越多,对存储容量的扩展性就有了更高的要求。基于这个要求,我们要解决数据的管理能力。就需要把数据全部存到对象存储上,跟1.0相比可以看到,所有的冷热数据,都会存到对象存储里,对象存储就要支持大规模高性能的能力,同样也有一个老的问题要解决。 HDFS 一些专有的接口支撑能力,还需要外部的元数据服务,run 一个元数据服务比如 JindoFS,来把传统应用支撑起来,这样就解决1.0里面的一些问题。
基于2.0我们深入的使用,也发现了一些痛点,比如要运维一个外部的元数据集群,同时对于一些存量的数据,你还要做数据导入导出的工作,为此我们提出了数据湖3.0。这里面存储架构就发生了一个质的变化。把外置的一个元数据集群,内置到对象存储里,把它做成一个服务化,无需占用客户的资源,通过 SDK 就能够访问,这样可以减少运维的难题。而且我们整个元数据统一之后,可以将历史上就已存到对象存储上面的数据快速迁移过来,不需要做数据的拷贝。因此数据湖3.0,我们实现了以对象存储为中心,全兼容、多协议、统一元数据的服务。

数据湖存储3.0 进化亮点
基于数据湖3.0,我们可以看到他有如下一些亮点:
- 多协议接口,访问相同存储空间
如图所示,它是一个多协议接口访问的池子。这个协议可以访问相同的数据,这样就能降低应用的门槛,直接对接接口就好,对运维是一个好处
- 性能加速器,服务端、客户端灵活选择使用
可以在客户端,服务端选择不同的加速器来提高性能
- 全服务化形态,降低客户运维难度
通过服务化的形态部署,降低了计算机器上面部署更多软件的开销,降低了运维的代价,可以让客户更好的使用
- 元数据互通,存量数据无缝迁移
底层让对象存储这种平坦的元数据,和基于 HDFS 目录的元数据,相互之间可以互相理解,从而在做存量数据移动的时候,只做元数据的映射修改,而数据是不用移动的,这样就可以平滑应用。
- 冷热分层,极致性价比优化
数据湖1.0里面有热数据在 HDFS 里面,冷数据在对象存储里面,现在我们完全可以利用对象存储自身提供的,不同规格的存储类型,来实现应用的冷热分层,从而提供极致的性价比
- 一份数据,多维的元数据描述,零数据拷贝

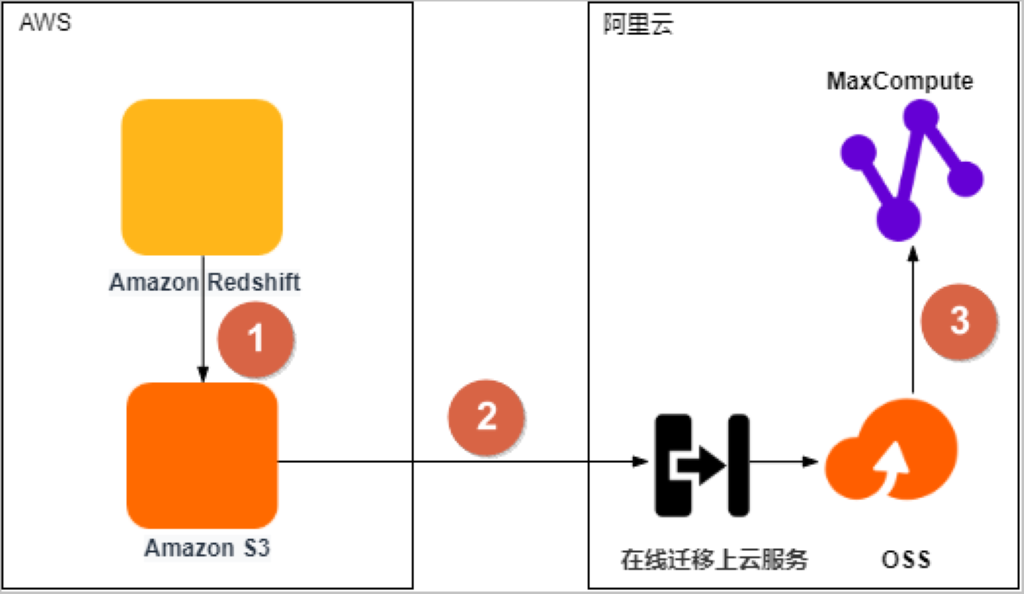
接口全兼容,快速完成自建HDFS迁移OSS数据湖存储
- 100%兼容 HDFS语义计算引擎无感
- HDFS/对象 一份数据 多协议访问,元数据互通
- 对象接口支持 毫秒级原子10亿级目录重命名
- 全服务化 降低运维难度,简单易用
我们实现了基于 OSS 构建的数据湖存储3.0.既然提供了百分之百兼容 HDFS 语义的能力,就可以很容易且快速完成自建HDFS迁移OSS数据湖存储。因为接口兼容了,我们可以通过一些工具、软件快速的把数据从自建的 HDFS 拷贝或者迁移到数据湖存储里面来,而且未来我们还会做,对于开源 HDFS NameNode 的一种格式解析方式。做了这个格式之后,我们可以在后台自动的做迁移,降低整个迁移的难度。那同时数据迁移到 OSS 之后,我们基于一些验证过的场景,比如一个目录下存放10亿的文件,我们也能提供对象存储级的目录操作的原子接口,可以实现秒级把这个目录完成重命名,大大的提高计算的效率,这个也是经过场景验证的。

OSS数据湖存储与CPFS数据流动,加速AI 业务创新
- 降低95%计算等待时间,大幅提升训练效率
- POSIX 语义兼容,业务应用天然适配
- CPFS 提供百GB吞吐,高性能共享访问
- 数据按需流动,多种更新模式,高效管理
建完湖之后就要修湖,修湖之后还要拉通、疏浚河道,这样才能够让水流到湖里面来。基于 OSS 构建的数据湖,也是同样的道理。我们完善了这个湖之外还打通了跟外部的存储之间的数据流动的通道。

这是典型的跟 CPFS 的一个通道,通过离线迁移的闪电立方数据迁移技术,把数据从线下,特别是在 AI 这样的场景下,把他的数据搬到云上,利用云上的技术把数据存起来。然后 CPFS 拉取需要的热数据跟 CPU 结合起来进行训练来满足高要求。比如 CPFS 可以提供百 GB 带宽的能力,快速的计算,可以降低95%的计算时间,充分发挥 CPFS 的能力。同时计算的结果又能回流归档回到 OSS 这个数据湖里面,在这个湖里面大量的数据,又会跟 EMR、MaxCompute 配合起来进行一些离线的训练,挖取更多的数据价值。所以我们会不断的去跟外部的存储系统,形成数据的流动,让湖跟外面的河连接起来,形成数据的水网。
基于 OSS 构建的数据湖存储3.0的特点
- 稳定
- 99.995%可用性SLA
- 12个9数据可靠性
- 数据不丢不错
- 安全
- 全链路数据加密
- 多种加密算法
- 一键开启Tb 级防攻击
- 敏感数据保护
- 弹性
- 数十 EB 级数据存储实战
- 单桶万亿级对象
- 目录原子操作接口
- 性价比高
- 久经验证Tbps 级带宽
- 稳定的读写时延
- 领先的冷归档成本降 90%
基于 OSS 构建的数据湖的稳定性是非常好的,99.995%的这个可用性 SLA , 这是非常高的。12个9的数据可靠性,数据基本上不会丢不会错,只有在极限的情况下,比如数据中心因为自然灾害等故障之后才可能引起异常,但我们通过3A 这样的技术可以进一步的缓解。我经常跟别人讲一个故事,阿里常说我们要活102年,我们希望在这一百年之期,你存进去的数据, 100多年以后去访问它还是一模一样的。不管后端的数据中心、硬盘、服务器发生任何代次的更换,数据始终在那。第二个就是我们的安全能力,基于对象存储 OSS 构建的数据湖,完整的继承了对象存储上面构建的安全能力,全链路的数据加密,丰富的加密算法,特别是一键开启 TB级的防攻击能力。昨天有一个客户还在跟我交流,他说他上云最担心的就是被攻击,那我们这一套防攻击体系是和阿里整个集团的防攻击体系一脉相承,一起共建出来,经受过双十一打磨的。所以安全这块在我们构建数据湖的时候,是可以放心的。至于弹性方面,我们提供了数十 EB 级的数据存储实战。而且对象存储里面的单桶,支持万亿级的存储能力,这个数据量是非常的庞大的。而且我们完善了对象存储上面的目录原子操作接口,通过这个目录原子操作可以让重命名变得更加的高效。我们跟 EMR 团队一起配合在一些场景下面,通过这个接口可以提升,整个计算30%的性能。然后性价比方面,久经验证的 Tbps 级带宽,做双十一大促也好,红包活动也好,都是支持的。大家如果用 OSS 就可以知道,我们写入的实验和读取的实验,抖动的曲线基本上没有波动,都是比较平稳的一条线,有了这个实验,大家做程序设计的时候,各种预期就比较好计算。今年我们还发布了领先的冷归档技术。通过冷规档技术,我们可以把成本降低90%。也就是说在数据湖里面,不用的数据可以沉淀下来,需要的时候再把它找回来,那成本是非常低廉的。就可以做好数据生命周期管理,支持你做好数据治理。
通过上面的这个技术介绍,我们相信基于 OSS 的数据湖存储3.0,就像哆啦A梦的百宝袋,你可以把各种数据都放进去,也许你放进去的是垃圾数据,但是你通过数据湖上面的分析,取出来的却是各种宝贝。
原文链接
本文为阿里云原创内容,未经允许不得转载。