什么是全链路灰度?
微服务体系架构中,服务之间的依赖关系错综复杂,有时某个功能发版依赖多个服务同时升级上线。我们希望可以对这些服务的新版本同时进行小流量灰度验证,这就是微服务架构中特有的全链路灰度场景,通过构建从网关到整个后端服务的环境隔离来对多个不同版本的服务进行灰度验证。
点击下方链接,查看直播教程:https://yqh.aliyun.com/live/detail/29004
在发布过程中,我们只需部署服务的灰度版本,流量在调用链路上流转时,由流经的网关、各个中间件以及各个微服务来识别灰度流量,并动态转发至对应服务的灰度版本。如下图:

上图可以很好展示这种方案的效果,我们用不同的颜色来表示不同版本的灰度流量,可以看出无论是微服务网关还是微服务本身都需要识别流量,根据治理规则做出动态决策。当服务版本发生变化时,这个调用链路的转发也会实时改变。相比于利用机器搭建的灰度环境,这种方案不仅可以节省大量的机器成本和运维人力,而且可以帮助开发者实时快速的对线上流量进行精细化的全链路控制。
OpenSergo[1] 流量路由标准
Q:OpenSergo是什么?
A:OpenSergo 是一套开放、通用的、面向分布式服务架构、覆盖全链路异构化生态的服务治理标准,基于业界服务治理场景与实践形成服务治理通用标准。OpenSergo 的最大特点是以统一的一套配置/DSL/协议定义服务治理规则,面向多语言异构化架构,做到全链路生态覆盖。无论微服务的语言是Java, Go, Node.js还是其它语言,无论是标准微服务还是 Mesh 接入,从网关到微服务,从数据库到缓存,从服务注册发现到配置,开发者都可以通过同一套OpenSergo CRD标准配置针对每一层进行统一的治理管控,而无需关注各框架、语言的差异点,降低异构化、全链路服务治理管控的复杂度
Q:为什么了解全链路灰度之前先给我介绍 OpenSergo?
A:OpenSergo 定义了一套统一的 YAML 配置方式来针对分布式架构进行全链路的服务治理的规范,介绍规范与标准的同时,我们可以了解其中的技术细节的实现,同时我们还可以将新的组件与 OpenSergo 的标准进行实现。
流量路由,顾名思义就是将具有某些属性特征的流量,路由到指定的目标。流量路由是流量治理中重要的一环,开发者可以基于流量路由标准来实现各种场景,如灰度发布、金丝雀发布、容灾路由、标签路由等。
全链路灰度示例:
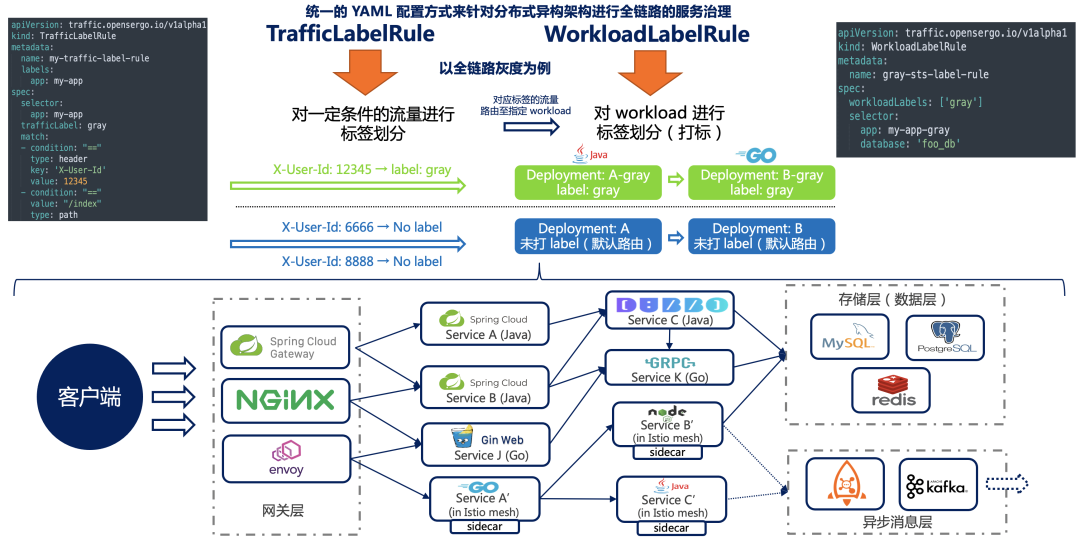
流量路由规则(v1alpha1) 主要分为三部分:
- Workload 标签规则 (WorkloadLabelRule):将某一组 workload 打上对应的标签,这一块可以理解为是为应用或者对应存储层的话就是数据库负载(数据库、表)打上对应的标签
- 流量标签规则 (TrafficLabelRule):将具有某些属性特征的流量,打上对应的标签
- 按照 Workload 标签和流量标签来做匹配路由,将带有指定标签的流量路由到匹配的 workload 中
给流量打标:
需要将具有某些属性特征的流量,打上对应的标签。
假设现在需要将深圳地域的用户灰度到新版主页,测试用户 location=cn-shenzhen,cn-shenzhen 位于 location header 中:
apiVersion: traffic.opensergo.io/v1alpha1
kind: TrafficLabelRule
metadata:name: my-traffic-label-rulelabels:app: spring-cloud-zuul
spec:selector:app: spring-cloud-zuultrafficLabel: graymatch:- condition: "==" # 匹配表达式type: header # 匹配属性类型key: 'location' # 参数名value: cn-shenzhen # 参数值通过上述配置,location header 为 cn-shenzhen 的 HTTP 流量,打上 gray 标,代表这个流量为灰度流量。
给 Workload 打标签:
在使用 Nacos 作为服务发现的业务系统中,一般是需要业务根据其使用的微服务框架来决定打标方式。如果 Java 应用使用的 Spring Cloud 微服务开发框架,我们可以为业务容器添加对应的环境变量来完成标签的添加操作。比如我们希望为节点添加版本灰度标,那么为业务容器添加 http://traffic.opensergo.io/label: gray ,这样框架向 Nacos 注册该节点时会为其添加一个 gray 标签。
对于一些复杂的 workload 打标场景(如数据库实例、缓存实例标签),我们可以利用 WorkloadLabelRule CRD 进行打标。示例:
apiVersion: traffic.opensergo.io/v1alpha1
kind: WorkloadLabelRule
metadata:name: gray-sts-label-rule
spec:workloadLabels: ['gray']selector:db: mse-demotable: mse_demo_table_gray全链路灰度在数据库上的常见方案
方案一:影子库
每个单独维护一套独立的库,假设基线环境的库的名称为 mse-demo,那么 gray 环境的流量可以映射到 mse-demo-gray 的库中,我们在同一个实例上建立对应环境流量的影子库,我们在业务中维护着各个库连接的连接池,根据不同的流量标选择对应的影子库的连接去访问,以此达到数据和基线环境库隔离的效果,从而避免了灰度环境流量产生的数据对基线环境库造成污染。
方案二:影子表
类似影子库方案,针对影子表方案,是在同一个实例上的同一个数据库上建立对应的影子表。我们在执行 SQL 的过程中,对灰度流量的 SQL 进行解析与修改,实现不同环境流量的 SQL 分别访问对应的表,假设基线环境的表的名称为 mse_demo_table,那么 gray 环境的流量可以映射到 mse_demo_table_gray 的表中。从而实现灰度数据和基线环境数据表隔离的效果。
MSE[2] 数据库全链路灰度能力
MSE 提供了一种数据隔离的方案,您可以在不需要修改任何业务代码的情况下,实现数据库层面全链路灰度。下面介绍 MSE 基于 Mysql 数据存储通过影子表的方案实现全链路灰度的能力。
前提条件
- 应用接入 MSE
- 部署 Demo 应用
在阿里云容器服务中部署 A、B、C 三个应用,每个应用分别部署⼀个 base 版本和⼀个 gray 版本;并部署⼀个 Nacos Server 应用,用于实现服务发现。具体可参考教程完成应用部署:部署 Demo 应用程序[3]。
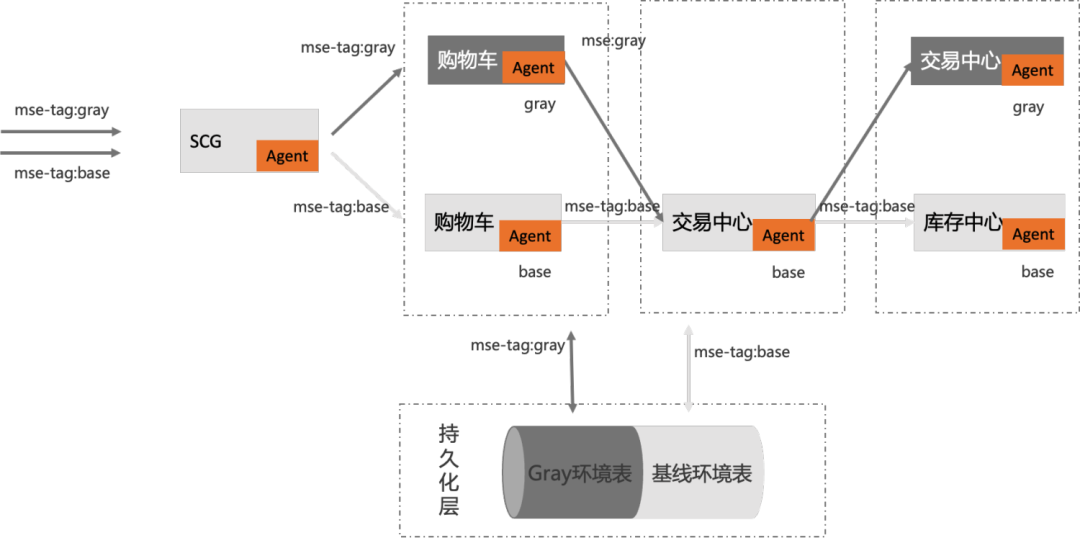
Demo 应用介绍,本 Demo 中的 C 应用会向数据库执行如下语句:
CREATE TABLE `mse_demo_table` (`id` int NOT NULL AUTO_INCREMENT,`location` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb3其中涉及到的数据库建表语句:
CREATE TABLE `mse_demo_table` (`id` int NOT NULL AUTO_INCREMENT,`location` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb3- 创建影子表,我们 Demo涉及到的数据库表有 mse_demo_table,因为我们需要创建灰度 gray 环境,因此我们需要提前创建 mse_demo_table_gray 表。
CREATE TABLE `mse_demo_table_gray` (`id` int NOT NULL AUTO_INCREMENT,`location` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb3
;第一步:配置全链路灰度规则
您需要配置完成 MSE 的全链路发布,具体操作细节可参考教程:配置全链路灰度[4]。
创建如下泳道规则:

第二步:配置数据库全链路灰度
- 我们需要配置以下环境变量来额外开启/配置数据库的全链路灰度能力

第三步:结果验证
我们发起灰度请求,发现流量请求均访问灰度环境:
curl -H "location: cn-shenzhen" http://106.14.XX.XX/a
Agray[172.18.XX.XX] -> Bgray[172.18.XX.XX] -> Cgray[172.18.XX.XX]%我们通过如下 SQL 查询影子表:
SELECT * FROM `mse_demo_table_gray`发现灰度环境的数据都插入至影子表。
不仅仅是全链路灰度
目前为止 MSE 服务治理全链路灰度能力已经支持了云原生网关、ALB、APISIX、Apache Dubbo、Spring Cloud、RocketMQ 以及数据库。在数据库层面我们通过影子表的方式实现了数据层面的流量隔离,下一步我们会将该能力进行进一步产品化,全链路灰度也会支持缓存层面的能力。
服务治理是微服务改造深入到一定阶段之后的必经之路,在这个过程中我们不断有新的问题出现。
- 除了全链路灰度,服务治理还有没其他能力?
- 服务治理能力有没一个标准的定义,服务治理能力包含哪些?
- 多语言场景下,有无全链路的最佳实践或者标准?
- 异构微服务如何可以统一治理?
当我们在探索服务治理的过程中,我们在对接其他微服务的时候,我们发现治理体系不同造成的困扰是巨大的,打通两套甚者是多套治理体系的成本也是巨大的。为此我们提出了 OpenSergo 项目。OpenSergo 要解决的是不同框架、不同语言在微服务治理上的概念碎片化、无法互通的问题。
参考链接:
[1] OpenSergo:
https://opensergo.io/zh-cn
[2] MSE 微服务引擎:
https://www.aliyun.com/product/aliware/mse
[3] 部署Demo 应用程序:
https://help.aliyun.com/document_detail/404845.html#h3-url-3
[4] 配置全链路灰度:
https://help.aliyun.com/document_detail/404845.html
原文链接
本文为阿里云原创内容,未经允许不得转载。



















