多模态(文本、图片)数据融合模型(含公开数据集、文献及开源代码汇总)
- <center>多模态模型的应用
- 跑代码普遍存在的问题
- <center>多模态公开数据集
- <center>文献及开源代码
多模态模型的应用
多模态模型的应用按照大的分类主要分为分类和预测。这里重点介绍多模态数据融合模型在分类细分领域中的应用。
- 谣言检测
- [1]蒋保洋,但志平,董方敏等.基于双预训练Transformer和交叉注意力的多模态谣言检测[J].国外电子测量技术,2023,42(04):149-157.
- 强子珊,顾益军.基于多模态异质图的社交媒体谣言检测模型[J/OL].数据分析与知识发现:1-16[2023-08-23].
- 垃圾邮件检测
- 虚假新闻检测
- [1]周昊玮,刘勇,玄萍.基于预训练和多模态融合的假新闻检测[J/OL].计算机工程:1-9[2023-08-23].
- 反讽识别
- 张继东,蒋丽萍.基于多模态深度学习的旅游评论反讽识别研究[J].情报理论与实践,2022,45(07):158-164.
- 事件分类
- 陈宏,钱胜胜,李章明等.基于多模态掩码Transformer网络的社会事件分类[J/OL].北京航空航天大学学报:1-11[2023-08-23].
跑代码普遍存在的问题
- 版本问题
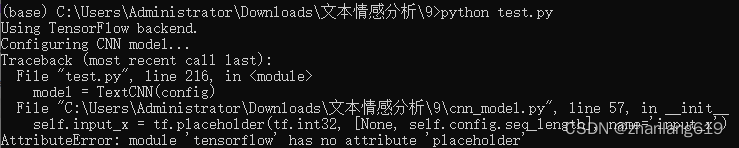
解决办法:
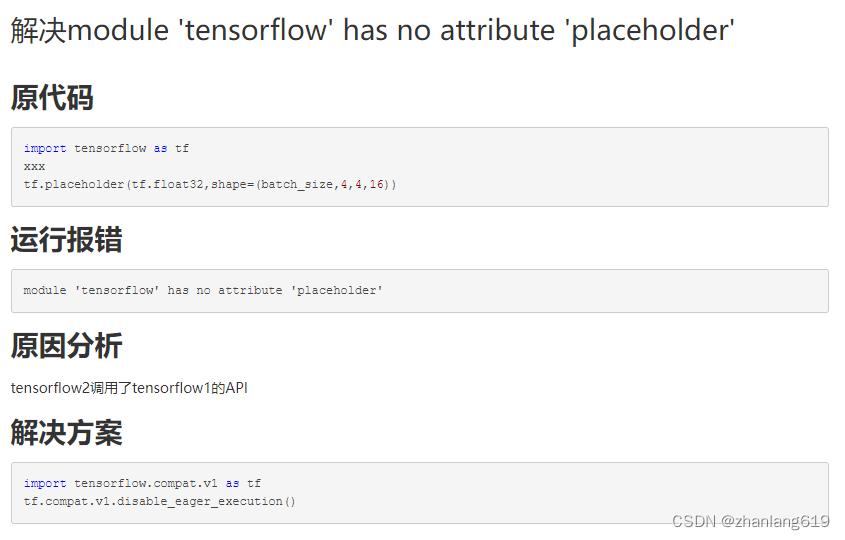

以下是几个微博、Twitter多模态数据集的官方下载链接:
多模态公开数据集
Weibo Image and Text Dataset: http://noisy-text.github.io/2016/weibo-ranking-icwsm.html
Chinese Multimodal Microblog Dataset: http://59.108.48.12/mipl/tencent_multiModal_dataset/index.html
MediaEval Emotional Impact of Movies Dataset: http://www.cs.virginia.edu/~hw5x/datasets/MediaEval18/MediaEval18-Emotion.html
Sarcasm Detection Dataset: https://github.com/Cyvhee/Sarcasm-Detection-Dataset-Twitter-and-Youtube
The NIST TREC Microblog Track: http://trec.nist.gov/data/microblog.html
文献及开源代码
[1]Lu J, Yang J, Batra D, et al. Hierarchical question-image co-attention for visual question answering[J]. Advances in neural information processing systems, 2016, 29.
开源代码:https://github.com/jiasenlu/HieCoAttenVQA(缺少部分代码,需要额外补全)
[2]Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3431-3440.(全卷积网络模型代码)
开源代码:https://github.com/shelhamer/fcn.berkeleyvision.org
[3]Zhang Q, Fu J, Liu X, et al. Adaptive co-attention network for named entity recognition in tweets[C]//Proceedings of the AAAI conference on artificial intelligence. 2018, 32(1).(协同注意力机制)
开源代码:https://github/monologg/NER-Multimodal-pytorch
 让LED灯 亮)






(6.3) 自动任务中的相机控制)

字符串)
)
)
(更新:纹理贴图))
)

)


![[golang gin框架] 46.Gin商城项目-微服务实战之后台Rbac客户端调用微服务权限验证以及Rbac微服务数据库抽离](http://pic.xiahunao.cn/[golang gin框架] 46.Gin商城项目-微服务实战之后台Rbac客户端调用微服务权限验证以及Rbac微服务数据库抽离)
