一、前提
刚开始接触C++/Qt是需要一个项目练练手,当时听说过OJ并且网络不好,就想着把数据获取下来随时使用。
后来代码写多了之后听说Python写爬虫更方便,可惜坑已经跳下去了,就一条路走到黑了。
这是我代码之路的第一个完整实现完整功能的项目,以示纪念。
github地址如下
https://github.com/JackeyLea/BlackWidow.gitgithub.com二、开发流程
1. 读取配置文件(数据库位置、皮肤名称)
2. 读取数据文件(网站名称列表)
3. 显示界面
4. 开启题库
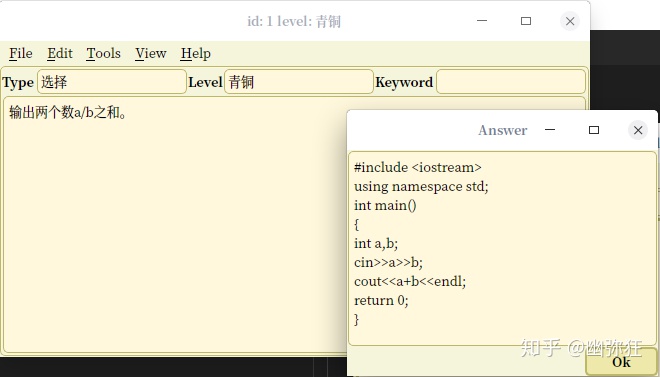
5. 从第1题开始显示题目数据(题目ID、题目名称、提交人数、通过人数、题目)
6. 点击“显示提示”
7. 在提示文本框显示提示
8. 点击“显示答案”
9. 在答案文本框显示答案
10. 点击“下一题”
11. 如果大于max ID就显示显示第1题,否则显示下一题
12. 点击“上一题”
13. 如果小于1就显示最大ID的题目,否则显示上一题
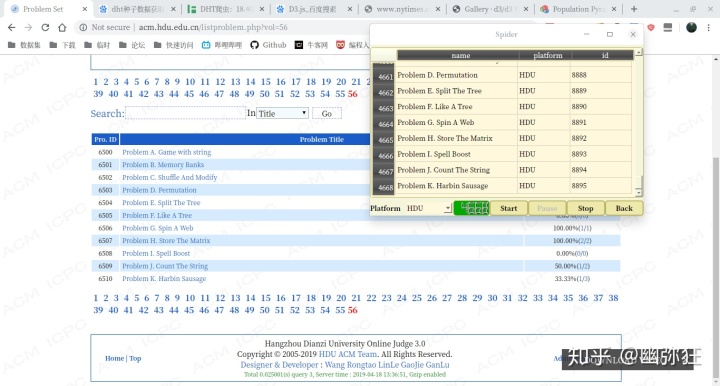
14. 点击“爬虫”
15. 显示爬虫界面
16. 点击“网站名”下拉文本框,选择一个网站名
17. 清空爬虫界面数据
18. 点击“start”按扭
19. 加载json文件中其他数据(网址、开始ID、题目数据正则表达式、提交人数正则等、结束标志等)
20. 开始爬虫
21. 是否正常,是否结束等等,如果结束则跳转到35,否则继续
22. 拼接网址和ID,生成完整的当前网址
23. 获取网址的网页数据
24. 判断网页数据是否正常,如果包含结束保证则清空,如果是200之外的返回码则清空
25. 获取网页数据中的编码值,并重新编码网页文本
26. 如果网页数据为空则
27. 根据19中的数据进行文本解析
28. 获取题目数据中最长的一句话,并计算MD5值
29. 查询数据库,此MD5值是否存在,如果存在则跳转到32,否则继续
30. 将此MD5值插入MD5表
31. 将其他的数据插入data表
32. 在爬虫界面更新题目名、位置名、ID,同时更新已获取的数量值
33. ID+1,正常数量+1,等等
34. 跳转到21
35. 提示结束
36. 跳转到15
三、界面
四、问题
1、使用题目最长一句话计算MD5进行相似度判断,发现效果并不好。
2、使用json格式进行配置文件读写发现知识水平不够,只能进行第一层数据读写
3、主线程和爬虫线程交互有点问题
4、poj题目太多,加上反爬虫的耗时,考虑使用多线程等等
5、练手项目,最近在学Java、Python,熟练之后在用Java、Python重写。

![php添加填空,PHP之preg_replace_callback(),将填空题的[[]]替换成______](http://pic.xiahunao.cn/php添加填空,PHP之preg_replace_callback(),将填空题的[[]]替换成______)



进程,线程的初步了解-阿里云开发者社区...)













