
来源:人工智能头条
编译 | AI100
第一次接触长短期记忆神经网络(LSTM)时,我惊呆了。
原来,LSTM是神经网络的扩展,非常简单。深度学习在过去的几年里取得了许多惊人的成果,均与LSTM息息相关。因此,在本篇文章中我会用尽可能直观的方式为大家介绍LSTM——方便大家日后自己进行相关的探索。
首先,请看下图:

LSTM是不是很漂亮?
注意:如果你对神经网络和LSTM很熟悉,请直接跳到本文的中间部分——前半部分相当于入门教程。
神经网络
假设我们从某部电影中截取出了一系列的图像,并且我们想对每张图像进行标记,使其成为某个事件(是打斗吗?演员们在说话吗?演员们在吃东西吗?)
我们该怎么做?
其中一种方法就是,在忽视图像连续属性的情况下构建一个单独处理各个图像的单图像分类器。例如,提供足够多的图像和标签:
我们的算法首先可能需要学习检测低级图形,如形状和棱边等。
在数据变多的情况下,算法可能会学习将这些图形与更为复杂的形式结合在一起,如人脸(一个椭圆形的东西的上方是一个三角形,三角形上有两个圆形)或猫。
如果数据量进一步增多的话,算法可能会学习将这些高级图样映射至活动本身(包含嘴、肉排和餐叉的场景可能就是在用餐)
这就是一个深度神经网络:输入一张图像而后输出相应的事件——这与我们在对犬类一无所知的情况下仍可能会通过幼犬行为学习检测其各种特征是一样的(在观察了足够多的柯基犬后,我们发现它们有一些共同特征,如蓬松的臀部和短小的四肢等;接下来,我们继续学习更加高级的特性,如排泄行为等)——在这两个步骤之间,算法通过隐含图层的向量表示来学习描述图像。
数学表达
虽然大家可能对基本的神经网络已经非常熟悉,但是此处我们仍快速地回顾一下:
单隐含层的神经网络将向量x作为输入,我们可以将其视作为一组神经元。
算法通过一组学习后的权重将每个输入神经元连接至神经元的一个隐含层。
第j个隐层神经元输出为
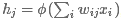 ,其中ϕϕ是激活函数。
,其中ϕϕ是激活函数。隐含层与输出层完全连接在一起,第j个输出神经元输出为
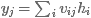 ,如果需要知道其概率的话,我们可以借助softmax函数对输出层进行转换。
,如果需要知道其概率的话,我们可以借助softmax函数对输出层进行转换。
用矩阵符号表示为:
h=ϕ(Wx)h=ϕ(Wx)
y=Vhy=Vh
其中
matchx 是输入向量
W是连接输入层和隐含层的权重矩阵
V是连接隐含层和输出层的权重矩阵
ϕ 的激活函数通常为双弯曲函数(sigmoid function) σ(x) ,它将数字缩小到 (0, 1)区间内;双曲线函数(hyperbolic tangent)tanh(x),它将数字缩小至(-1, 1)区间内,修正线性单位 ReLU(x)=max(0,x)。
下图为图形视图:
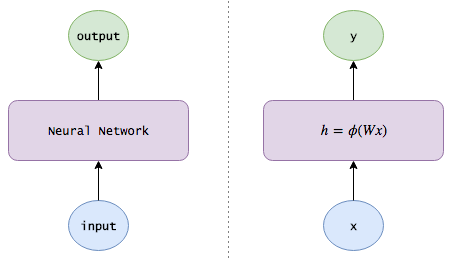
注意:为了使符号更加简洁些,我假设x和h各包含一个额外的偏差神经元,偏差设置为1固定不变,方便学习偏差权重。
利用RNN记忆信息
忽视电影图像的连续属性像是ML 101的做法。如果我们看到一个沙滩的场景,我们应该在接下来的帧数中增强沙滩活动:如果图像中的人在海水中,那么这个图像可能会被标记为“游泳”;如果图像中的人闭着眼睛躺在沙滩上,那么这个图像可能会被标记为“日光浴”。如果如果我们能够记得Bob刚刚抵达一家超市的话,那么即使没有任何特别的超市特征,Bob手拿一块培根的图像都可能会被标记为“购物”而不是“烹饪”。
因此,我们希望让我们的模型能够跟踪世界上的各种状态:
在检测完每个图像后,模型会输出一个标签,同时模型对世界的认识也会有所更新。例如,模型可能会学习自主地去发现并跟踪相关的信息,如位置信息(场景发生的地点是在家中还是在沙滩上?)、时间(如果场景中包含月亮的图像,模型应该记住该场景发生在晚上)和电影进度(这个图像是第一帧还是第100帧?)。重要的是,正如神经元在未收到隐含图像(如棱边、图形和脸等)的情况下可以自动地去发现这些图像,我们的模型本身可以自动发现有用的信息。
在向模型输入新的图像时,模型应该结合它收集到的信息,更加出色地完成任务。
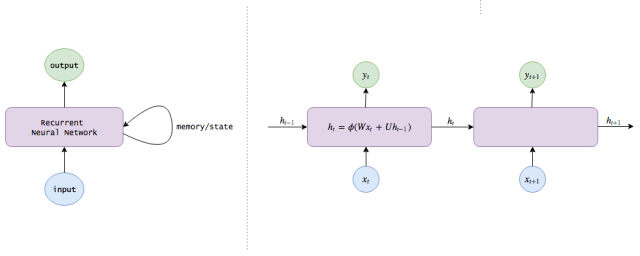
这就是递归神经网络(RNN),它不仅能够完成简单地图像输入和事件输出行为,还能保持对世界的记忆(给不同信息分配的权重),以帮助改进自己的分类功能。
数学表达
接下来,让我们把内部知识的概念添加到方程式中,我们可以将其视为神经网络长久以来保存下的记忆或者信息。
非常简单:我们知道神经网络的隐含层已经对关于输入的有用信息进行了编码,因此,为什么不把这些隐含层作为记忆来使用呢?这一想法使我们得到了下面的RNN方程式:
ht=ϕ(Wxt+Uht−1)
yt=Vht
注意:在时间t处计算得出的隐状态(ht为我们的内部知识)在下个时间步长内会被反馈给神经网络。(另外,我会在本文中交替使用隐状态、知识、记忆和认识等概念来描述ht)
利用LSTM实现更长久的记忆
让我们思考一下我们的模型是如何更新它对世界的认识的。到目前为止,我们并未对其更新过程施加任何限制措施,因此该认识更新过程可能十分混乱:在某一帧,模型可能会认为其中的人物是在美国;到了下一帧,当它观察到人物在吃寿司时,便会认为这些人在日本;而在下一帧,当它观察到北极熊时,便认为他们是在伊德拉岛 ( Hydra island )。也有可能,模型收集到的大量信息表明Alice是一名投资分析师,但是在看到她进行烹饪时又断定她是一名职业杀手。
这种混乱意味着信息会快速地改变并消失,模型很难保存长期记忆。因此,我们希望神经网络能学会如何更新自己的认识(也就是说,没有Bob的场景不应该改变所有与Bob相关的信息,有Alice的场景就应该专注于收集关于她的信息),这样神经网络就可以相对缓慢地更新它对世界的认识。
数学表达
让我们用数学表达式来描述LSTM的添加机制。
在时间t时,我们收到一个新的输入xt。我们还将长期记忆和工作记忆从前两个时间步ltmt−1和wmt−1(两者都为n-长度向量)传递到当前时间步,进行更新。
我们先处理长期记忆。首先,我们需要知道哪些长期记忆需要继续记忆,并且需要知道哪些长期记忆需要舍弃。因此,我们使用新的输入和工作记忆来学习0和1之间n个数字的记忆门,各个记忆门决定某长期记忆元素需要保留的程度。(1表示保存,0表示完全遗忘)。
我们可以使用一个小型神经网络来学习这个时间门:
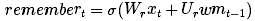
(请注意它与先前网络方程式相似的地方;这只是一个浅层神经网络。另外,我们之所以使用S形激活函数是因为我们所需要的数字介于0至1之间。)
接下来,我们需要计算可以从xt中学习的信息,也就是长期记忆的候选添加记忆:
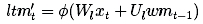
ϕ是一个激活函数,通常被选作为tanh。在将候选记忆添加到长期记忆中之前,我们想要学习候选记忆的哪部分值得使用和保存:
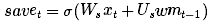
(想象一下你在阅读网页时发生的事情。当新的新闻可能包含关于希拉里的信息时,如果该信息来自布莱巴特(Breitbart)网站,那么你就应该忽视它。)
现在让我们把所有这些步骤结合起来。在忘记我们认为不再需要的记忆并保存输入信息的有用部分后,我们就会得到更新后的长期记忆:
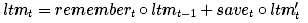
其中∘表示以元素为单元 (Element-wise)的乘法。
接下来,让我们更新一下工作记忆。我们想要学习如何将我们的长期记忆聚焦到能立刻发挥作用的信息上。(换句话说,我们想要学习需要将哪些数据从外接硬盘中转移到用于工作的笔记本上)。因此,此处我们来学习一下关注/注意向量(focus/attention vector):
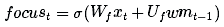
我们的工作记忆为:
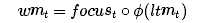
换言之,我们注意关注向量为1的元素,忽视关注向量为0的元素。
我们完成了!希望你也将这些步骤记到了你的的长期记忆中。
总结来说,普通的RNN只利用一个方程式来更新它的隐状态/记忆:
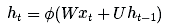
而 LSTM 则会利用数个方程式:
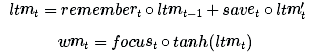
其中的每个记忆/注意子机制只是它自己的一个迷你大脑:
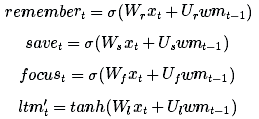
(注意:我使用的术语和变量名称与常规文章中的用法不同。以下是标准名称,我从此处起将会交替使用这些名称:
长期记忆ltmt通常被称为cell状态,表示为ct。
工作记忆wmt通常被称为隐状态,表示为ht。它与普通RNN中的隐状态类似
记忆向量remembert通常被称为记忆门(尽管记忆门中的1仍表示保留记忆,0仍表示忘记),表示为ft。
保存向量savet通常被称为输入门(因为它决定输入信息中需要保存到cell状态中的程度),表示为it。
关注向量focust通常被称为输出门,表示为ot。)
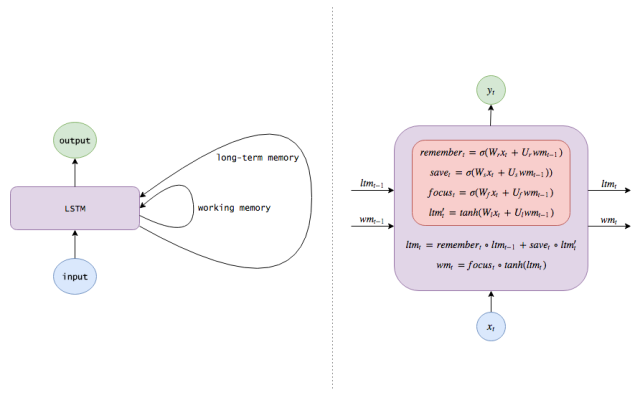
Snorlax
写这篇文章的时间我本来可以捉到一百只Pidgey的!下面Pidgey的卡通图像。
神经网络
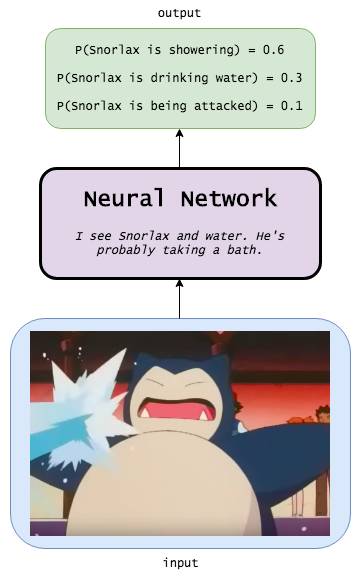
递归神经网络
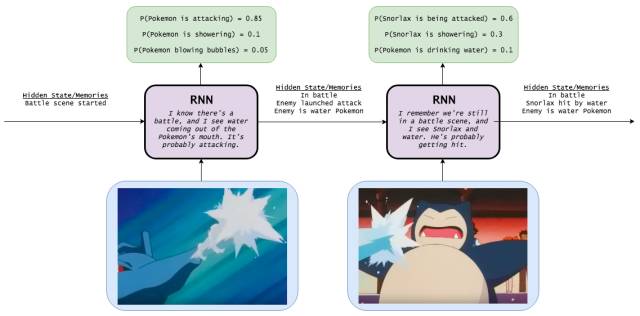
长短期记忆网络
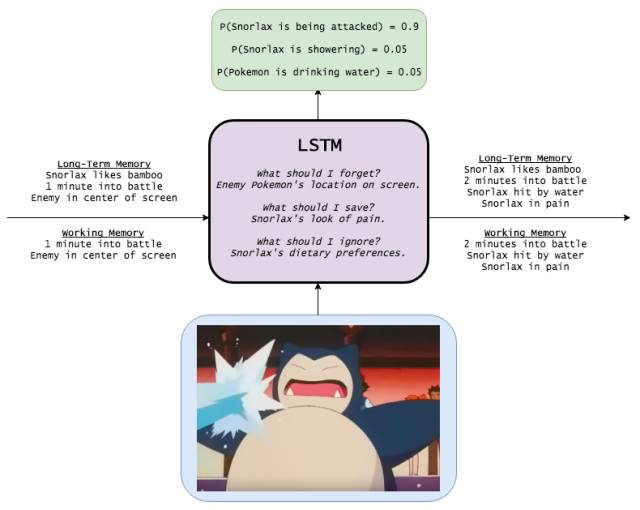
学习如何编码
让我们看几个LSTM发挥作用的例子。效仿Andrej Karpathy的文章,我将使用字符级别的LSTM模型,我给模型输入字符序列并对其进行训练,使它能够预测序列中的下个字符。
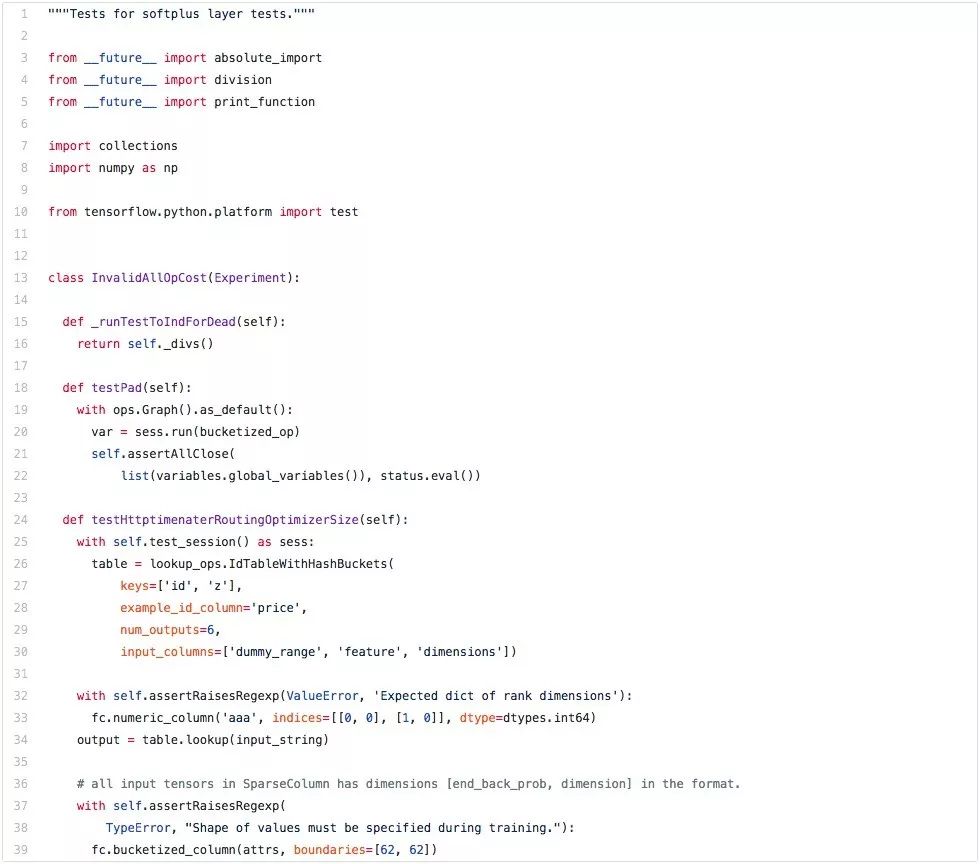
首先我启动了一个EC2 p2.xlarge竞价实例(spot instance),在Apache Commons Lang codebase上训练了一个3层LSTM。这是该LSTM在数小时后生成的一个程序。

尽管该编码肯定不算完美,但是也比许多我认识的数据科学家编得好。我们可以看出,LSTM学到了很多有趣(并且正确!)的编码行为:
它知道如何构造类别:先是证书,然后是程序包和输入,再是评论和类别定义,最后是变量和方法。同样,它懂得如何创造方法:正确指令后跟装饰符(先是描述,然后是@param,再是@return等),正确放置装饰符,返回值非空的方法以合适的返回语句结尾。至关重要的是,这种行为贯穿长串长串的代码!
它还能跟踪子程序和嵌套层数:语句的缩进始终正确,并且Loop循环结构始终关闭。
它甚至知道如何生成测试。
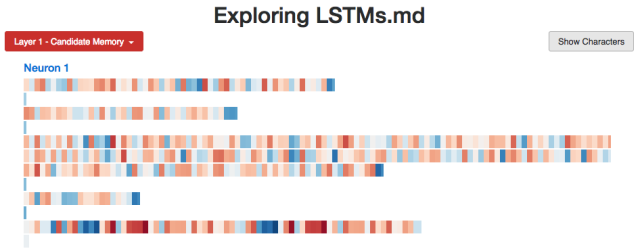
模型是如何做到的呢?让我们观察几个隐状态。
这是一个似乎是用来跟踪代码缩进外层的神经元(当模型读取字符作为输入时,代码的状态会决定字符的颜色,也就是当模型试图生成下个字符时;红色cell为否定,蓝色cell为肯定):

这是一个倒数tab间空格数的神经元:

这是一个与众不同的3层LSTM,在TensorFlow的代码库中训练得出,供您试玩:
链接:http://karpathy.github.io/2015/05/21/rnn-effectiveness/
如果想查看更多的实例,你可以在网络上找到许多其他有趣的实例。
探究LSTM内部结构
让我们研究得更深一些。我们在上一节中探讨了几个隐状态的实例,但是我还想使用LSTM的cell状态以及其他记忆机制。它们会如我们预期的那样被激活吗?或者说,是否存在令人意想不到的模式呢?
计数
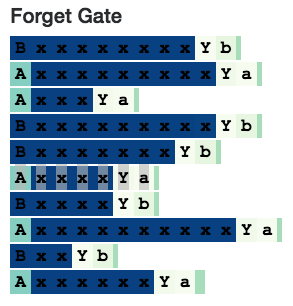
为了进行研究,让我们先教LSTM进行计数。(记住Java和Python语言下的LSTM是如何生成正确的缩进的!)因此,我生成了这种形式的序列

(N个"a"后跟着一个分隔符X,X后跟着N个"b"字符,其中1 <= N <= 10),并且训练了一个带有10个隐层神经元的单层LSTM。
不出所料,LSTM在它的训练范围内学习得非常好——它甚至在超出范围后还能类推几步。(但是当我们试着使它数到19时,它便开始出现错误。)

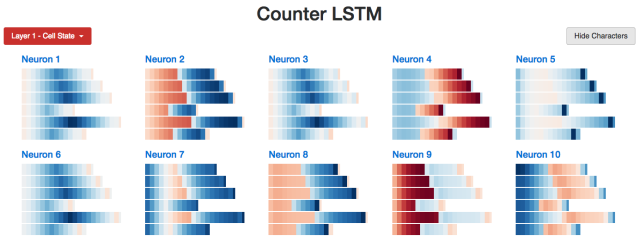
研究模型的内部,我们期望找到一个能够计算a's数量的隐层神经元。我们也确实找到了一个:
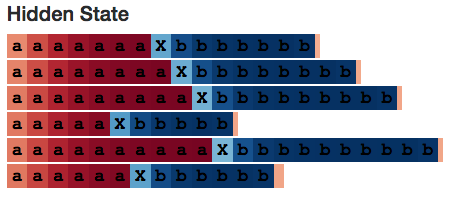
Neuron #2 隐藏状态
我用LSTM开发了一个小的网页应用(http://blog.echen.me/lstm-explorer),Neuron #2计数的似乎是它所能看到的a's和b's的总数。(记住根据神经元的激活状态对Cell进行上色,颜色在暗红色 [-1] 到暗蓝色 [+1]之间变化。)
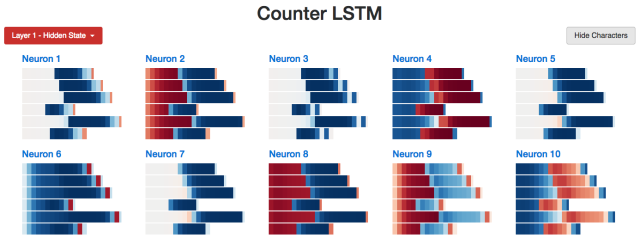
Cell状态呢?它的表现类似:
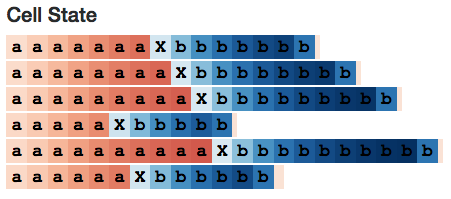
Neuron #2 Cell状态
有趣的是,工作记忆看起来像是“更加清晰”的长期记忆。是不是整体都存在这种现象呢?
确实存在。(这和我们的预期完全相同,因为tanh激活函数压缩了长期记忆,同时输出门会对记忆做出限制。)例如,以下是对所有10个cell状态节点的快速概览。我们看到许多浅色的cell,它们代表的是接近于0的数值。
LSTM Cell状态的统计
相比之下,10个工作记忆神经元的表现非常集中。神经元1、3、5、7在序列的前半部分甚至完全处于0的状态。
让我们再看看神经元#2。图片中是候选记忆和输出门,它们在各半个序列中都相对较为稳定——似乎神经元每一步计算的都是a += 1或者b += 1。

输入门
最后,这是对所有神经元2的内部的概览。

如果你想要研究不同的计数神经元,你可以使用这里提供的观察器(visualizer)。
链接:http://blog.echen.me/lstm-explorer/#/network?file=counter
Count von Count
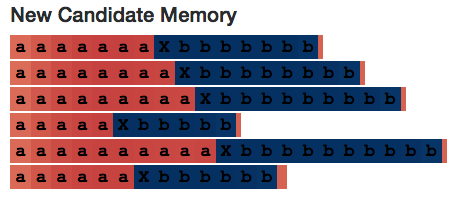
让我们看一个稍微复杂些的计数器。这次我生成了这种形式的序列:

(N个a's 中随机夹杂几个X's,然后加一个分隔符Y,Y后再跟N个b's)。LSTM仍需计算a's的数量,但是这次它需要忽视X's。
这是完整的LSTM(http://blog.echen.me/lstm-explorer/#/network?file=selective_counter)。我们预期看到一个计数神经元,但是当神经元观测到X时,输入门为零。的确是这样!

上图为Neuron 20的cell状态。该状态在读到分隔符Y之前一直在增加,之后便一直减少至序列结尾——就如计算num_bs_left_to_print变量一样,该变量在读到a's时增加,读到b's时减小)。
如果观察它的输入门,它的确在忽视X's :

有趣的是,候选记忆在读到不相关的X's时完全激活——这表明了设置输入门的必要性。(但是,如果该输入门不是模型结构的一部分,那么该神经网络则很可能会通过其他方法学会如何忽视X's,至少在当下简单的实例中是这样的。)
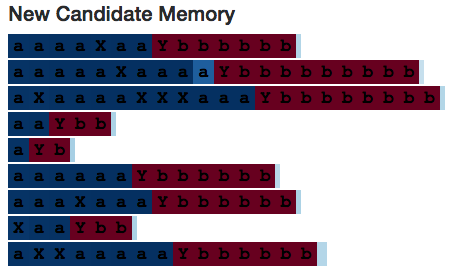
让我们再看看Neuron 10。

这个神经元很有趣,因为它只有在读取到分隔符"Y"时才会激活——但它仍能成功编码出序列中a's的数量。(也许从图片中很难看出来,但是当读取到序列中的Y's和a's数量相同时,所有cell状态的值要么完全相同,要么彼此间的误差不超过0.1%。你可以看到,a's较少的Y's比其他a's较多的Y's颜色更浅。)也许某些其他神经元看到神经元10偷懒便帮了它一下。

记住状态
接下来,我想看看LSTM是如何记住状态的。我生成了这种形式的序列:
(即一个"A" or "B",紧跟1-10个x's,再跟一个分隔符"Y",结尾是开头字符的小写形式)。在这种情况下,神经网络需要记住它是处于"A" 状态还是 "B"状态中。我们期望找到一个在记忆以"A"开头的序列时激活的神经元,以及一个在记忆以"B"开头的序列时激活的神经元。我们的确找到了。
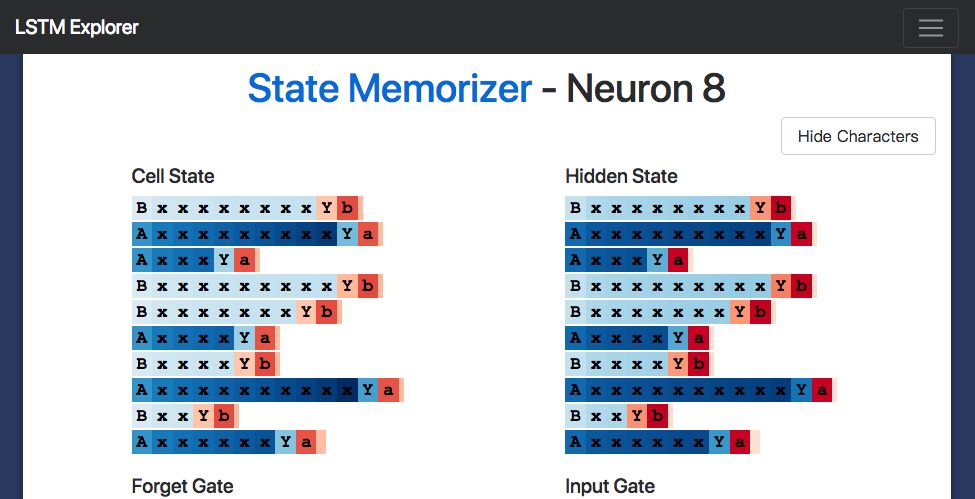
例如,下面是一个在读到"A"时会激活的"A"神经元,它在生成最后的字符之前会一直进行记忆。注意:输入门会忽视所有的"x"字符。
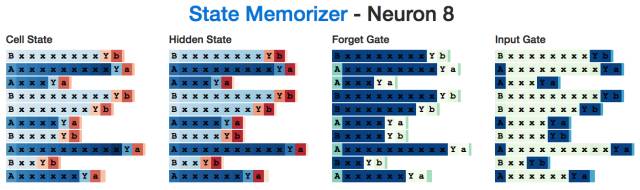
这是一个"B"神经元:
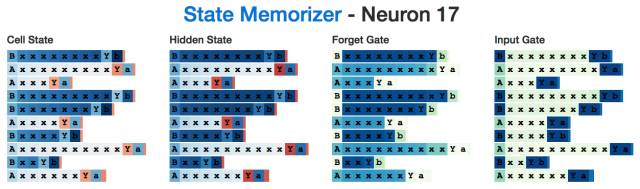
有趣的是,尽管在神经网络读到分隔符"Y" 之前,我们并不需要了解A状态与B状态的情况,但是隐状态在读取所有中间输入的整个过程中都处于激活状态。这似乎有些“效率低下”,或许是因为神经元在计算x's的数量时还在完成一些其他的任务。
复制任务
最后,让我们探究一下LSTM是如何学习复制信息的。(Java LSTM能够记忆和复制Apache许可证。)
为了完成复制任务,我在如下形式的序列上训练了一个小的2层LSTM。

(即先是一个由a's、b's和 c's组成的3字符序列,中间插一个分隔符"X",后半部分则组前半部分的序列相同)。
我不确定“复制神经元”长什么样,因此为了找到记忆初始序列部分元素的神经元,我在神经网络读取分隔符X时观察了它们的隐状态。由于神经网络需要对初始序列进行编码,它的状态应当根据学习的内容呈现出不同的模式。
在我看来,这个模式适用于整个神经网络——所有神经元似乎都在预测下一字符,而不是在记忆特定位置上的字符。例如,神经元5似乎就是“预测下一字符是‘c’”的神经元。
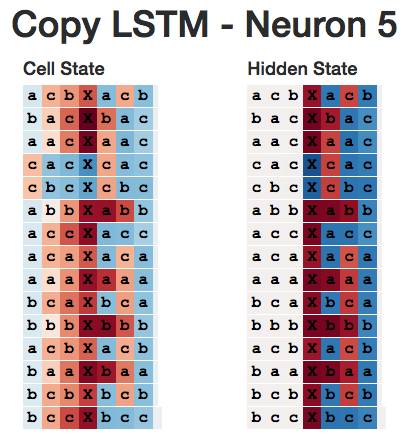
我不确定这是不是LSTM在复制信息时学习的默认行为,也不确定是否存在其他复制机制。

状态和门
为了真正深入探讨和理解LSTM中不同状态和门的用途,让我们重复之前
状态和隐藏状态(记忆)cell.
我们原本将cell状态描述为长期记忆,将隐藏状态描述为在需要时取出并聚焦这些记忆的方法。
因此,当某段记忆当前不相干时,我们猜想隐藏状态会关闭——这正是这个序列复制神经元采取的行为。
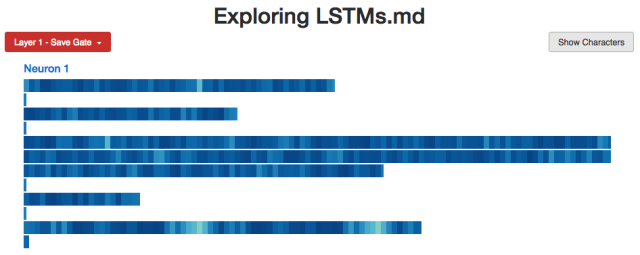
遗忘门
遗忘门舍弃cell状态的信息(0代表完全遗忘,1代表完全记住),因此我们猜想:遗忘门在需要准确记忆什么时会完全激活,而当不再需要已记住的信息时则会关闭。
我们认为这个"A"记忆神经元用的是同样的原理:当该神经元在读取x's时,记忆门完全激活,以记住这是一个"A"状态,当它准备生成最后一个"a"时,记忆门关闭。
输入门(保存门)
我们将输入门(我原理称其为“保存门“)的作用描述为决定是否保存来自某一新输入的信息。因此,在识别到无用的信息时,它会自动关闭。
这就是这个选择计数神经元的作用:它计算a's和b's的数量,但是忽略不相关的x's。
令人惊奇的是我们并未在LSTM方程式中明确规定输入(保存)、遗忘(记忆)和输出(注意)门的工作方式。神经网络自己学会了最好的工作方式。
扩展阅读
让我们重新概括一下如何独自认识LSTM。
首先,我们要解决的许多问题在某种程度上都是连续的或暂时的,因此我们应该将过去学到的知识整合到我们的模型中。但是我们知道,神经网络的隐层能编码有用的信息。因此,为什么不将这些隐层用作为记忆,从某一时间步传递到下一时间步呢?于是我们便得到RNN。
从自己的行为中我们可以知道,我们不能随心所欲地跟踪信息;但当我们阅读关于政策的新文章时,我们并不会立即相信它写内容并将其纳入我们对世界的认识中。我们会有选择地决定哪些信息需要进行保存、哪些信息需要舍弃以及下次阅读该新闻时需要使用哪些信息来作出决策。因此,我们想要学习如何收集、更新和使用信息——为什么不借助它们自己的迷你神经网络来学习这些东西呢?这样我们就得到了LSTM。
复兴神经网络
最后让我们再看一个实例,这个实例是用特朗普总统的推文训练出的2层LSTM。尽管这个数据集很小,但是足以学习很多模式。例如,下面是一个在话题标签、URL和@mentions中跟踪推文位置的神经元:

以下是一个正确的名词检测器(注意:它不只是在遇到大写单词时激活):
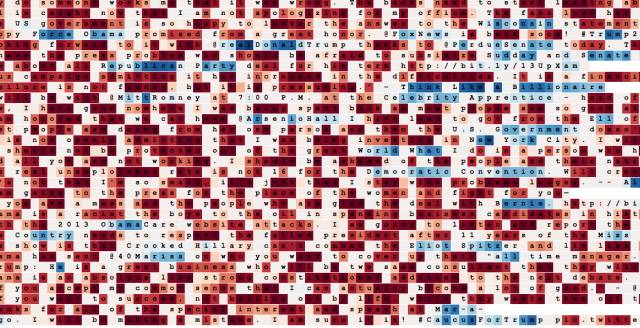
这是一个“辅助动词+ ‘to be’”的检测器(包括“will be”、“I've always been”、“has never been”等关键词)。

这是一个引用判定器:

甚至还有一个MSGA和大写神经元:

这是LSTM生成的相关声明(好吧,其中只有一篇是真的推文;猜猜看哪篇是真的推文吧!):


不幸的是,LSTM只学会了如何像疯子一样疯言疯语。
总结
总结一下,这就是你学到的内容:
这是你应该储存在记忆中的内容:
作者:Edwin Chen
原文链接:http://blog.echen.me/2017/05/30/exploring-lstms/
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。由互联网进化论作者,计算机博士刘锋与中国科学院虚拟经济与数据科学研究中心石勇、刘颖教授创建。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”


)



)



)




)
)
)


