编译:集智翻译组
来源:distill.pub
作者:Shan Carter,Michael Nielsen
原题:Using Artificial Intelligence to Augment Human Intelligence
摘要:计算机不仅可以是解决数学问题的工具,还可以是拥有实时交互能力,协助人类解决问题,甚至完成创造性工作的辅助系统。具有可交互界面的的机器学习工具,可以帮助人类更高效地设计字体、制作图片,甚至创造出艺术作品。人工智能可以大大增强人类智能,本文详细介绍了这方面的一些探索。
一、计算机可以被用来做什么?
在历史上,这个问题的不同答案——即对计算的不同见解——有助于启发和确立最终建立的人性化计算系统。早期的电子计算机 ENIAC,是世界上第一台通用电子计算机,它的目的是为美国军队计算火炮射击表。其他早期的计算机也被用于解决数值问题,如模拟原子弹爆炸、预测天气、规划火箭的运动。在批处理模式下运行的机器,使用粗糙的输入和输出设备,而且没有任何实时的交互。这种观点把计算机看作是数值处理机器,用于加速在之前要花费数周、数月或需要一个团队人力才能完成的计算任务。
在20世纪50年代,对计算机用来做什么的另一个不同的观点开始发展起来。在1962年,当 Douglas Engelbart 提出计算机可以被看作一种增强人类智能[1]的方式时,这个观点开始变得明确起来。在这种观点下,计算机不是主要解决数值计算问题的工具,而是实时交互的系统,有着丰富的输入和输出,使得人类可以一起工作来支持和扩展他们自己解决问题的过程。
这种智能增强(Intelligence Augmentation,简称IA)的观点深深地影响了很多其他人,包括研究员如施乐帕克研究中心(Xerox PARC 的 Alan Kay 和企业家如苹果的 Steve Jobs,而且导致了很多现代计算系统的关键想法的产生。这个观点同样深深地影响了数字艺术与音乐,还有交互设计、数据可视化、计算创造力和人机交互等领域。
IA领域的研究经常和人工智能(Artificial Intelligence,简称AI)的研究相互竞争:在研究经费上的竞争,吸引有才能的研究员上的竞争。尽管这两个领域之间总是存在着交叉,但是IA通常专注于构建系统使人类和机器可以共同协作,而AI则专注于将智能任务完全外包给机器。尤其是,AI的问题通常专注于匹配或者超过人类水平:在象棋或围棋上打败人类;学会像人类一样识别语音和图像或翻译语言;等等。
本文描述了一个新的领域,这个领域来自于AI和IA的综合。我们建议将这个领域命名为人工智能增强(artificial intelligence augmentation,简称AIA):使用AI系统帮助开发智能增强(IA)的新方法。这个新领域引入了新的重要的基础问题,这些问题无法关联到任何的父领域中。我们相信 AIA 的原理和系统将会与大多数存在的系统完全不同。
我们的文章开始于对近期技术工作的调查,这些工作隐含了人工智能增强技术,包括生成式界面(generative interfaces)的工作——可用于探索和可视化生成机器学习模型。这样的模型发展出一种生成模型的制图学,使人们可以用于去探索模型以及从模型中构建意义,并且融合模型知道的信息到他们创造性的工作中。
本文不仅仅是技术工作的综述。我们相信这是个好的时间点,在这个新领域的建立中识别出一些广泛而根本的问题。这些新工具能够多大程度激发创造力?他们能被用于生成令人惊讶的新的想法吗?还是说这些想法只是陈词滥调,是基于现存想法的无价值的再结合?这样的系统能被用于发展出基础性的新的接口基元吗?这些新的基元将会如何改变和扩大人类思考的方式呢?
二、使用生成模型产生有意义的创意操作
让我们看一个例子,机器学习模型使一类新的接口成为可能。为了理解接口,想象你是一个字体设计师,正在创造一种新的字体。在描述了一些最初的设计后,你希望用粗体、斜体和压缩的变体进行试验。让我们看看一个工具,能从初始设计中生成和探索这些变体。结果的质量是相当粗糙的,我们将在稍后解释具体原因,请谅解。
当然,变化粗度(如重量)、斜度和宽度只是变化字体的三种方法。想象一下不是构造特定的工具,而是用户可以仅仅通过选择现存的字体样例来构造他们自己的工具。比如,假设你想变化字体的衬线的程度。在下面,请在顶部的盒中,选择5至10个无衬线字体,然后拖到左边的盒子;接着选择5至10个衬线字体,拖到右边的盒子。当你在操作时,运行在浏览器中的机器学习模型将会自动从这些例子中,推测出如何在衬线或无衬线的方向上对初始字体进行调整:

原文中的控件1截图(可点击 阅读原文 操作)
实际上,我们使用这个相同的技术构造了上面的粗体、斜体和浓缩工具。为了实现工具,我们使用了下面的例子:粗体和非粗体、斜体和非斜体、浓缩和非浓缩字体:

为了构建这些工具,我们使用了生成模型(generative model),具体使用的是James Wexler[2] 训练的模型。为了理解生成模型的用法,想象一下描绘一个字体原本似乎需要大量的数据。比如,如果字体是 64x64 的像素,那么我们需要 64x64=4096 个参数去描述单个字形。但是我们可以使用生成模型找到一个更简单的描述。
我们通过构建一个神经网络来实现,它只使用了少量的输入变量,叫隐变量(latent variable),来产生整个的字形输出。在我们使用的模型中,隐变量空间维度是40维,并将其映射到4096维可以描述所有字形像素的空间中。换句话说,这个想法是将一个低维的空间映射到一个高维空间:
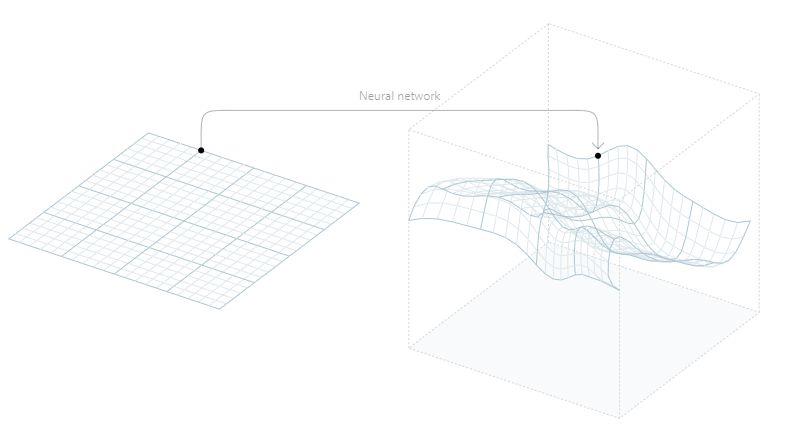
我们使用的生成模型是一类叫做变分自编码器(variational autoencoder, VAE)[3]的神经网络。对我们的目的来说,生成模型的细节并不是很重要。重要的是,通过改变作为输入的隐变量,能够得到不同的字体作为输出。所以隐变量的一种选择将会产生一种字体,然而另一种选择将会产生另一个不同的字体:
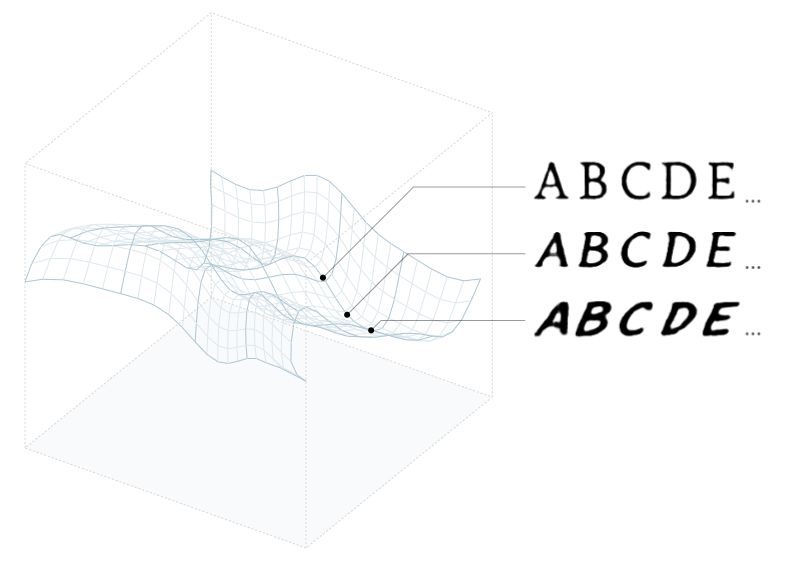
你可以把隐变量看成是一种紧凑的、高层次的字体表示。神经网络输入高层次表示,并且转化成全像素数据。值得注意的是,我们只需要40个数字就能捕捉一个字形的表面复杂性,而最初需要4096个变量。
我们使用的生成模型是从 Bernhardsson[4] 在公开网页收集的超过5万个字体的训练集中学习到的。在训练中,网络的权重和偏置被调整,只要隐变量被恰当地选择,就能使得网络输出对任意训练集字体的近似。在某种程度上,模型在学习一个所有训练集字体的高度压缩的表示。
实际上,模型不仅重现了训练字体,而且能泛化、产生训练集中没有的字体。通过被强制寻找训练样本的一个紧凑描述,神经网络学习到了一个抽象的、更高层次的字体表征模型。更高层次的模型使得在已知的训练样本上的泛化成为可能,能产生具有真实感的字体。
理想情况下,一个好的生成模型在面对少量训练样本时,能够利用它泛化到所有可能的人类可识别的字体的空间。对任意可能的字体——已经存在的或可能在未来可想象的——我们可能找到正好对应那个字体的隐变量。当然我们使用的模型还远达不到理想的效果——一个非常严重的失败是很多模型生成的字体遗漏了大写字母“Q”的尾部(你可以在上面的例子中看到)。然而,记住一个理想的生成模型能做什么还是有用的。
在某些方式上,这些生成模型类似于科学理论的作用方式。科学理论经常极大地简化对出现的复杂现象的描述,把大量的变量减少为仅仅很少的变量,并从中可以推导出系统行为的很多方面。而且,好的科学理论有时能够被一般化来发现新的现象。
作为一个例子,考虑普通的物体。这些物体有着物理学家称为相(phase)的东西——它们可能是液态、固态、气态或有时可能更奇异,像超导体或波尔-爱因斯坦凝聚态。起初,这样的系统看起来极其复杂,涉及到10^23或更多的分子。但是热力学定律和统计力学使我们找到一个更简单的描述,把复杂性减少为仅仅几个变量(温度、压力等等),但是包含了系统的大量行为。
而且,有时可能被一般化来预测意想不到的新的相态。例如,在1924年,物理学家使用热力学和统计力学预测了一个显著的新的相态,波尔-爱因斯坦凝聚态,其中所有原子可能全部处于相同的量子状态,导致惊人的大规模量子干涉效应。稍后我们在关于创造性和生成模型的讨论中会回到这种预测能力上的话题上来。
回到生成模型的具体细节上来,我们如何使用这种模型做基于样例的推理,像上述工具所展示的?让我们考虑粗体工具的情形,在那个例子中,我们分别对所有用户指定的粗体字体和非粗体字体取均值。然后,我们计算这两个均值向量的差:
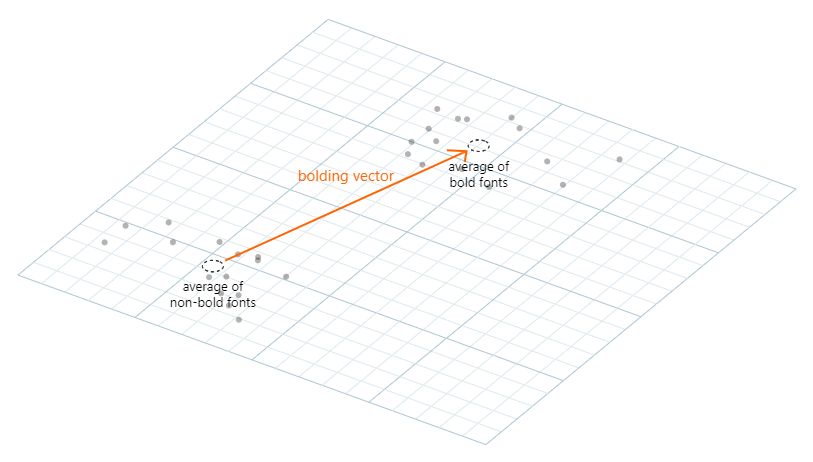
我们把它成为称为粗体向量(bolding vector),为了使给定的字体变粗,我们简单地加入一点粗体向量到相关的隐变量中,加入粗体向量的量控制着结果的粗度:
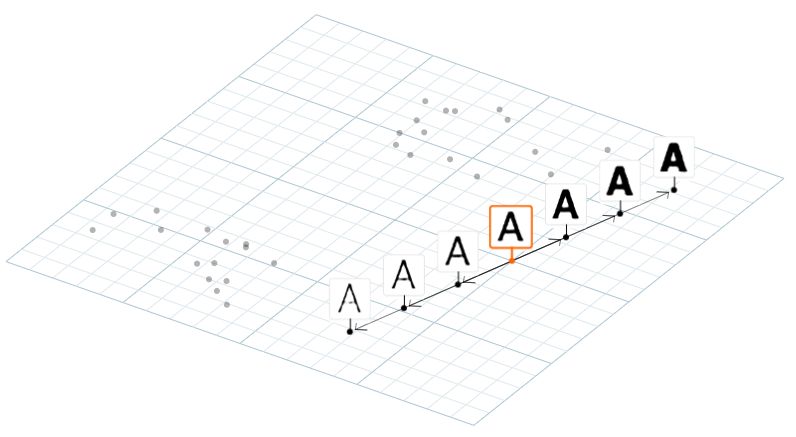
这个技术是由 Larsen 等人[5]提出的,类似粗体向量的向量有时叫做属性向量(attribute vectors)。相同的想法被用于所有上述的工具的实现中。于是,我们利用样例字体产生一个粗体向量、一个斜体向量、一个压缩向量和一个用户自定义的衬线向量。所以,这个界面提供了在这四个方向上隐空间的一个探索方法。
我们展示的工具有很多的不足。比如,我们从中间的样例字体开始,分别向右或向左,增加或减小字体的粗度:
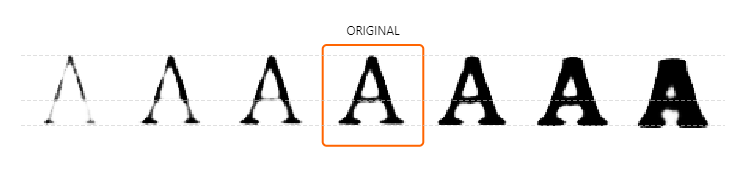
检查在左边和右边的字体,我们看到很多不幸的变形。尤其最右边的字体,边缘开始变得粗糙,衬线开始消失。一个更好的生成模型会减少这些变形。这是一个好的长期的研究项目,它展现了很多有趣的问题。但是即使是当前的模型,生成模型的使用同样有着引人注目的优势。
为了理解这些优势,考虑一种简单的加粗方法,我们简单地加入一些额外的像素在字体的边缘,使其变厚。尽管这种加厚可能符合一种非专家的思考字体设计的方式,但是专家会做更多深入的事情。下面,我们展示了这种简单加厚程序结果和 Georgia 和 Helveticade 所做的字体的比较:

正如看到的,简单的加粗方法在两种情形下都产生了相当不同的结果。例如,在 Georgia 的结果中,左边笔画只加粗改变了一点点,而右边的笔画极大地被增大,但是只在一边。在两种字体中,加粗不会改变字体的高度,然而这种简单的方法会改变。
如这些例子展现的,好的加粗方法不是一个简单的加厚字体的过程。专业的字体设计师有很多关于粗体的启发式,这些启发是从很多过去的实验中和历史样例的仔细研究中推断出来。在传统程序中捕捉这些启发是个繁重的工作。使用生成模型的好处是它可以自动学习很多的启发。
例如,一个简单的粗体工具会在字母“A”的封闭的上部区域,快速地填充封闭的负空间。字体工具不会这样做,它会保留封闭的负空间,向下移动"A"的横杆,相比于外部更加缓慢地填充内部笔画。在上述例子中,这个原则是明显的,尤其对 Helvetica ,它也被看成是字体工具的操作:

保留封闭负空间的启发不是一个明显的先验直觉,然而,它在很多专业的字体设计中被采用。如果检查上面的例子,你会容易知道为什么:它提高了清晰度。在训练中,我们的生成模型从它看过的样例中自动推测出这个原则,而且我们的加粗界面将其提供给用户。
实际上,模型捕捉到很多其他的启发。比如,在上面的例子中,字体的高度是几乎不变的,这是专业字体设计中的规范。同样,粗体操作不仅仅是将字体的加粗,而是应用了一个从生成模型推测出的更微妙的启发。这些启发式可以被用于创造带有属性的字体,而这些属性是之前用户几乎不可能想到的。所以,这个工具扩展了普通人类在有意义的字体空间中的探索能力。
字体工具是认知技术的一个例子。尤其,它包含的基本操作能够内化为用户思考方式一部分。在这里,它类似于一个 Photoshop 或3D图形软件。它们都提供了一组新奇的界面基元,这些基本元素能被用户内化为他们思考过程中基本的新元素。新元素内化是很多智能增强领域工作的基础。
字体工具中的想法可以扩展到其他领域。使用相同的接口,我们可以使用一个生成模型来操作人脸图像,如基于表情、性别或头发颜色等属性;或基于长度、讽刺或语气操作句子;或基于化学性质操作分子:
原文中的控件2操作演示
该生成接口提供了一种生成模型的绘图法,一种人类使用生成模型探索和创造意义的方法。
我们之前看到字体模型自动地推理出关于字体设计的相对深刻的原则,并提供给用户。然而这样的深刻原则能被推理出来是很好的,但是有时,模型推测出一些错误或令人不快的东西。例如,White 指出[6]一些脸部模型中微笑向量的加入将会使脸部不仅仅出现更多微笑,而且变得更女性化。为什么呢?因为在训练数据中,微笑的女性比微笑的男性更多。所以,这些模型不仅仅学习到关于世界的深刻事实,而且同时内化了偏见或错误的信仰。一旦偏差被知道,通常它是可能被纠正的。但是为了找到那些偏见需要对模型进行仔细的审核,而且迄今我们仍不清楚如何保证这些审核是彻底的。
更广泛地说,我们可以问为什么属性向量有作用,它们什么时候起作用,什么时候不起作用?现在,我们对这些问题的答案了解甚少。
为了使属性工作,我们需要输入任意开始字体,通过在隐空间中加入相同向量来构造相关的粗体版本。然后,我们知道,没有理由使用单个常量向量的移动才会工作,也许我们应该用很多不同的移动方法。比如,用于粗体衬线和无衬线字体的启发是相当不同的,所以似乎应该使用非常不同的移动方法:
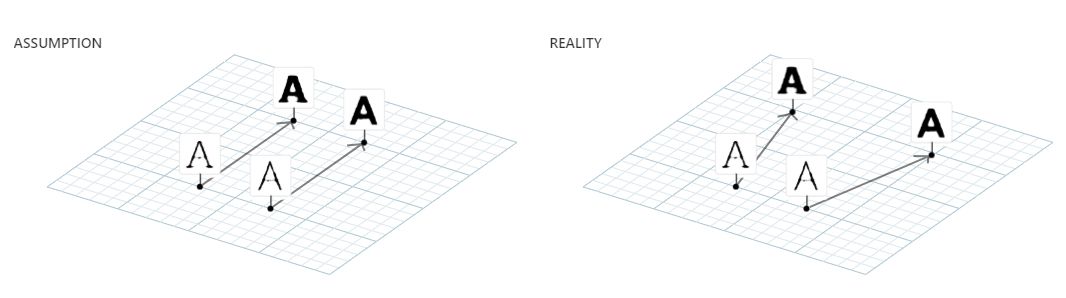
当然,我们可以做比使用单个常量属性向量更复杂的事情。给定一对样例字体(非粗体,粗体),我们能够训练一个机器学习算法,输入非粗体版本的隐向量,输出粗体版本的隐向量。给出更多字体权重的训练数据,机器学习算法能学习生成任意权重的字体。属性向量只是一种实现这类操作的极其简单的方法。
由于这些原因,属性向量将不太可能作为一种最终的操作高层次特征的方法。在未来几年,更好的方法将会发展出来。然而,我们仍能够期望接口能够提供广泛地类似于上面描述的操作,能够操作高层次的和潜在的用户定义的概念。接口模式不再依赖于属性向量的技术细节。
三、交互生成对抗模型
让我们看另一个使用机器学习模型增强人类创造力的例子。它是2016年,Zhu等人[9]提出的交互生成对抗网络(interactive generative adversarial networks)或iGAN。
这篇文章中的一个例子是在一个接口中使用 iGAN 生成消费品的图片,如鞋子。传统上,这个接口需要程序员编写一个包含大量鞋子相关知识的程序:鞋底、鞋带、鞋跟等等。Zhu 等人没有这样做,而是使用从 Zappos 下载的5万张鞋子的图片,训练了一个生成模型。然后他们使用这个生成模型构建了一个界面让用户可以大概地描述鞋子的形状、鞋底、鞋带等等:
视觉效果并不是太好,部分因为 Zhu 等人使用的生成模型在现代(2017)的标准中是过时的——使用更现代的模型,视觉效果会更好。
但是视觉效果不是重点。在这个原型中,很多有趣的事情正在发生。比如,注意当鞋底被填满时,鞋子的整体形状会如何显著地变化——它变得更窄和更光滑。很多小的细节被填满,像白色鞋底上方的黑条,和鞋子上部到处填满的红色。这些和其他的事实是自动从底层的生成模型中推断出来的,我们将会简单描述该方法。
相同的界面可能被用于描述风景。唯一的区别是背后的生成模型使用的是风景图片来训练,而不是鞋子的图片。在这种情形下,只描述和风景相关的颜色变得可能。例如,这是用户在描述一些绿色的草、山的轮廓、一些蓝天和山上的雪:
在这些接口中使用的生成模型不同于我们的字体模型,不是使用变分自编码器,而是基于生成对抗网络(generative adversarial networks, GANs)。但是背后的想法仍然是找到一个低维的隐空间,能够表示所有的风景图片,并且将该隐空间映射到相关的图片中。同样,我们可以认为隐空间中的点是描述风景图片的一种紧凑的方法。
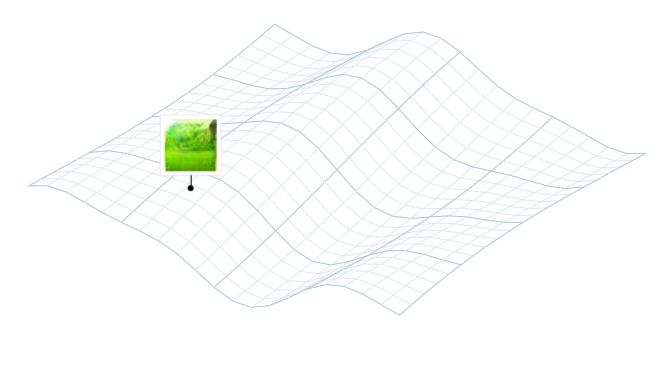
大概来说,iGAN 的工作方式如下所示。不论当前的图片是什么,它关联到隐空间中的一些点:
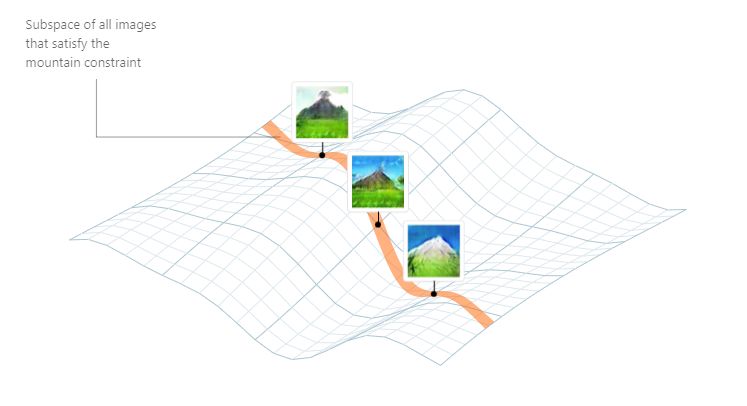
假设,如之前视频中发生的,用户现在用笔划描述山的形状轮廓。我们可以认为笔划是图片上的一个约束,在隐空间中选择一个子空间,该子空间由匹配轮廓的图片的所有隐空间中的点组成:
接口工作的方法是找到隐空间中一个距离当前图片最近的点,所以图片不仅变化很大,同时也接近满足强制的约束。这是通过优化一个目标函数实现的,该目标结合了到每个强制约束的距离和偏移当前点的距离。如果只有单个约束,比如,关于山的笔划,它看起来如下图:
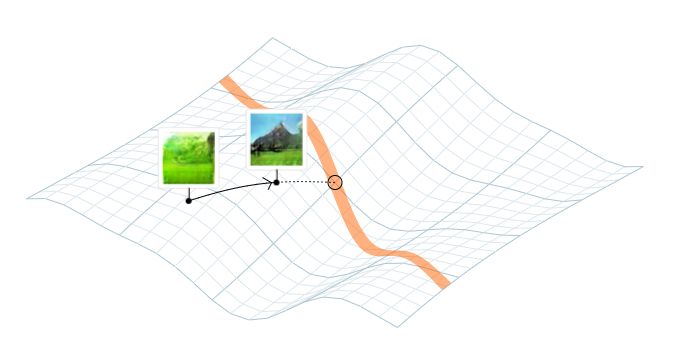
然后,我们可以把它看作是一种应用对隐空间的约束,用有意义的方式移动图片。
iGAN 和我们之前展示的字体工具有很多共同点。它们的操作都编码了很多关于世界的精细的知识,比如当它学习理解山看起来是什么或加粗字体时,推测出封闭负空间应该保留。iGAN 和字体工具都提供了理解和在高维空间导航的方法,使我们保持在字体、鞋子或风景的自然空间中。
如 Zhu 等人提到的:
对我们大多数人,Photoshop 中简单的图片处理呈现了不可逾越的困难。任何不那么完美的编辑立刻使图片看起来完全不真实。换另一种方式,传统的视觉操作范式不会防止用户“脱落”自然图片的流形。
像字体工具一样,iGAN 是一种认知技术。用户可以内化界面的操作为他们思考中的新的基本元素。比如,在鞋子的例子中,他们可以学习用他们想要应用的差异来思考,如加入鞋跟或更高的顶部或特别的高亮。这比传统方式中非专家对鞋子的思考(“尺码 11, 黑色”等等)更加丰富。
在非专家用更复杂的方式思考的范围——“使顶部更高点或更光滑”——他们在这种思考方式下得到的经验很少,或很难看到他们选择的结果。像这样的界面使探索、发展风格的能力、规划的能力、和朋友交换想法等等都更简单。
四、计算的两种模型
让我们重新审视本文开始的问题,计算机可以被用来做什么?它和智能增强有什么关系。
计算机的一个常见概念是——它们是解决问题的机器:“计算机,在这样或者那样的风向下(等等情况)下发射炮弹的结果是什么?”;“计算机,在未来5天东京的最高温度是多少?”;“计算机,当围棋棋盘处于这个位置时,最好的选择是什么?”;“计算机,这个图片该如何分类?”等等。
在计算机作为数字运算机器的早期看法中,还有大量AI上的工作中,在历史和今天的看法中,这是一个很常见的概念。这个模型是计算机作为一种外包认知的方法。在AI未来的可能推测上,这种外包认知模型在AI的视角下经常作为预言家出现,能够以比人类更好的水平解决一些大类问题。
但是对于计算机为了什么这个问题,一个非常不同的概念是可能的,一个和智能增强的工作更一致的概念。
为了理解另一个观点,考虑我们对于思考的主观经验。对很多人,这个经验是口头上的:他们用语言思考,在头脑中形成单词链,类似于演讲或写在纸上的句子。对于另一些人,思考是一个更加视觉的体验,处理像图和地图的表示。仍然有些人混合了数学到他们的思考中,使用代数表示或图表技术,比如费曼图和彭罗斯图。
在每种情形下,我们都使用了别人发明的表示来思考:单词、图、地图、代数、数学图表等等。随着成长,我们内化了这些认知技术,并且使用它们作为我们思考的一种基底。
在大多数历史中,可获取的认知技术的范围是缓慢、逐渐变化的。一个新的单词或一个新的数学符号将被引入。更少见的,一个激进的新的认知技术将会被发展。例如,在1637年,笛卡尔发表了他的《方法论》,解释了用代数表示几何观点,反之亦然:
这使得我们在对代数和几何的思考方式发生了根本上的改变和扩展。
历史上,持久的认知技术很少被发明出来。但是现代计算机是元-媒介(meta-medium),使得很多新的认知技术被快速发明出来。考虑一个相对平常的例子,例如Photoshop,精于 Photoshop 的用户经常出现之前不可能有的想法比如:“让我们对这个的层应用克隆图章”。这是一个更一般的思考类型的例子:“计算机,【新型动作】这个【新设想的对象类的新型表示】”。当它发生时,我们在使用电脑扩展我们可以思考的想法范围。
这种认知转换模型(cognitive transformation model)成为了大量智能增强领域中那些深入工作的基础。不仅仅是外包认知,它改变了我们用于思考的操作和表示;它改变了思想本身的基底。而且虽然认知外包很重要,这种认知转换观点提供了一种对智能增强更有意义的模型。在这种观点下,计算机是改变和扩大人类思想的工具。
历史上,认知技术是人类发明家发展出来的,从在苏美尔和中美洲的写作的发明,到现代界面的设计,如Douglas Engelbart,Alan Kay和其他设计师。
本文描述的例子表明,AI系统推动了新的认知技术的发明。字体工具不仅仅是当你需要一个新字体时可以咨询的预言家。而且,它们可以被用于探索和发现,提供新的表示和操作,能够被内化为用户思考的一部分。虽然这些例子只处于早期阶段,但是它们预示着AI不仅仅是关于认知外包。对于AI的一个不同观点是,它帮助我们发明新的认知技术,转换我们思考的方式。
本文中,我们集中于少量例子,更多涉及隐空间的探索。有很多其他人工智能增强的例子,举一些,但不全面:sketch-rnn system[11],用神经网络辅助画画;Wekinator[12],使用户快速建立新的乐器和艺术系统;TopoSketch[13],通过探索隐空间生成动画;机器学习模型设计整个印刷排版[15];生产模型能在乐句间插值[15]。在每种情形下,系统使用机器学习把新的元素整合到用户的思考中。更广泛地,人工智能增强将会开拓像计算创造性[16]和交互机器学习[17]这样的领域。
五、寻找强大的思想新基元
我们认为机器学习系统能有助于创造表示和操作,作为人类思考中的新基元。在这些新基元中我们应该寻找什么样的性质?这是一个太大的问题,无法在一篇短文中全面地回答。但是我们将会简略地探索一下。
历史上,重要的新媒介形式刚引入时通常看起来很奇怪。很多这样的故事传到流行文化中:“斯特拉文斯基 Stravinsky 和尼金斯基 Nijinksy 的《春之祭》的首映礼的暴乱”;”早期立体画派引起的恐慌,纽约时报对其评论:‘他们在表达什么?这些画的作者是否失去理智?这是艺术还是疯狂?谁知道呢?’”。
另一个例子来自物理学。在20世纪40年代,量子电动力学的理论构想独立地由物理学家朱利安·施温格 Julian Schwinger、朝永振一郎 Shin’ichirō Tomonaga 和理查德·费曼 Richard Feynman 发展出来。在他们的工作中,施温格和振一郎使用传统代数的方法,沿着其他物理学家相似的路线。而费曼使用一个更激进的方法,基于现在有名的费曼图,用于描述光和物质的交互:
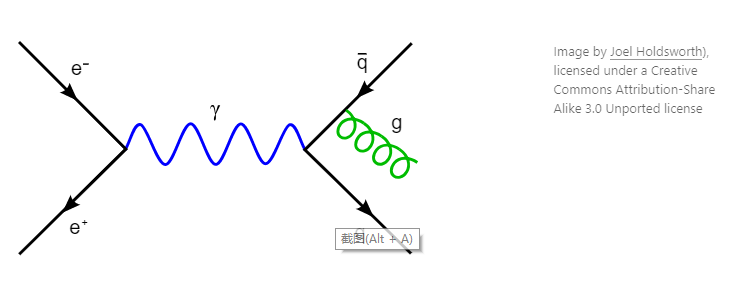
最初,施温格和振一郎的方法更容易被其他物理学家理解。当费曼和施温格在1948年讨论会上展示他们的工作时,施温格立刻受到赞扬。相反,费曼的工作使观众感到困惑。
如 James Cleick 在他的费曼传记[19]中写到:
这打击了费曼,每个人都有一个喜欢的原理或定理,他当时全部违背了它们...费曼知道他失败了。当时,他极其痛苦。后来,他简单地说:“我的东西太多了,我的机器来自太遥远的地方。”
当然,仅仅是因为奇怪的奇怪是没有用的。但是,这些例子暗示了在表示上的重大突破在一开始经常显得奇怪。还有其他正确的潜在原因吗?
部分原因是因为如果一些表示是非常新的,那么它看起来会和你之前见到的事情不同。费曼图、毕加索的画、斯特拉文斯基的音乐都揭示了真正的有意义的新方法。好的表示能让你敏锐地洞察事物,帮助使熟悉的事物尽可能生动地展现出新事物。但是因为对不熟悉的强调,表示会看起来很奇怪:它展示了你之前从未见过的关系。在某种程度上,设计师的任务是识别出关键的奇特,然后尽可能地放大它。
奇特的表示经常是难以理解的。开始,物理学家们喜欢施温格-振一郎的方法甚于费曼的。但是,随着费曼的方法慢慢被物理学家理解,他们意识到虽然施温格-振一郎的方法和费曼的在数学上是等价的,费曼的方法更加强大。
如 Gleick 所说:
施温格的学生们在哈佛处于竞争的劣势,一如别处的同僚们与之而言,同僚们怀疑他们是不是在偷偷地使用着费曼图。这有时是正确的,默里盖尔曼之后花了一个学期待在施温格的家里,后来喜欢说他已经搜索了费曼图的每个地方,他没有找到什么,除了一个已经被锁上的门...
这些想法不仅对历史上的表示是正确的,对计算机的接口同样是。然而我们对奇怪的主张违反了很多传统界面的智慧,特别是被广泛持有的信念,它们应该是"用户友好"的,如简单、初学者能立刻使用。
这经常意味着界面是陈旧的,是用传统元素以标准的方法构造而成。然而虽然使用陈旧的界面可能是简单和有趣的,它轻松的像阅读一部公式化的浪漫小说。它意味着界面没有揭示任何关于主题区域的真正新奇的东西。所以它几乎不能加深用户的理解,或改变他们思考的方式。对一般的任务是没问题的,但是对更深刻的任务,在更长期上,你想要一个更好的接口。
理想上,界面能展示主题下的更深的原则,向用户揭示一个新的世界。当你学会这个界面,你能内化这些原则,拥有更强大的对世界的推理能力。这些原则是你理解中的扩散器,它们是你真正想看见的全部,其他都是处于最好的支持或最坏的不重要的碎渣。最好的界面的目的在浅层意义上不是用户友好的,它是更强意义上的用户友好,是具体化有关世界的原则[20],使它们成为用户生活和创造的工作环境。在那时,一旦看起来奇怪的反而变得舒服和熟悉,变成思考模式的一部分。
在智能增强上使用 AI 模型意味着什么?
我们希望,如我们看到的,我们的机器学习模型将会帮助我们构建接口,用对用户有意义的方式使深刻原则具体化。为了实现它,模型必须发现关于世界的深刻原则、识别出这些原则、而且尽可能用一种用户理解的方式,生动地在接口中表现出来。
当然,这是离谱的要求,我们展示的例子仅仅只是一个开始。确实我们的模型有时能发现深刻的原则,像在加粗字体时对封闭负空间的保留,但是这仅仅隐藏在模型中。然而,我们已经构建了能利用这些原则的工具,如果模型能自动地推测出重要的原则,并找到方法明确地表现出这些原则(鼓励过程朝着 infoGAN[21] 的结果前进,它使用了信息论的想法找到隐空间的结构),这就更好了。理想地,这样的模型开始得到真正的解释,不只是静态的形式,还有动态的形式,用户可以操作的。但是我们离那一点还有很长的路要走。
六、这些交互界面会抑制创造力吗?
怀疑我们已经描述的界面的表达丰富性,是件诱人的事情。如果一个界面约束我们只探索图片的自然空间,是否意味着我们只在做被期望的事情呢?是否意味着这些接口只能被用于生成视觉的陈词滥调呢?它会阻止我们生成真正新的东西、做真正有创造性的工作吗?
为了回答这些问题,识别出创新的两种不同的模式是有帮助的。这两种模式的模型是过于简化的:创造力并不能很好地分为这两类。尽管如此,这个模型还是澄清了在创造性工作中新接口的角色。
创造的第一个模式是一个工匠每天从事工作的创造性。比如,一个字体设计师的大量工作是由最好的现存经验重新组合而成。这样的工作通常是许多创造性的选择,以满足预期的设计目标,而不是开发关键的新的内在原则。
对于这样的工作,我们一直讨论的生成接口是有前景的。虽然它们目前有很多局限性,但未来的研究将发现并解决许多不足。这在GAN身上发生得很快:最初的GAN有很多限制[10],但很快又出现了更适合图片的模型[22],改进了分辨率,减少了工件等等。有了足够的迭代,这些生成界面将成为工艺工作的强大工具。
第二种创造模式的目的是发展新的原则,从根本上改变创造性表达的范围。人们可以在毕加索或莫奈等艺术家的作品中看到这一点,他们违反了现存的绘画原则,发展出新的原则,使人们能够以新的方式看到事物。
在使用生成接口时,是否有可能做这样的创造性工作呢?这样的接口会不会限制我们在自然图片或自然字体的空间,因此阻止了我们积极地在创造性工作中探索有趣的方向?
情况比这更复杂。
在某种程度上,这是一个关于我们的生成模型的能力的问题。在某些情况下,模型只能够生成现存想法的重新组合。这是理想的 GAN 模型的限制,因为一个经过完美训练的 GAN 生成器将复制训练数据的分布。这样的模型不能创造一个新的基本原则来直接生成图片,因为这样的图片没法从在训练数据中得来。
像 Mario Klingemann 和 Mike Tyka 这样的艺术家现在用GAN来创作有趣的艺术品。他们使用的是“不完美的” GAN 模型,他们似乎能用来探索有趣的新原则;也许不好的GAN比理想的 GAN 模型在艺术上更有趣。此外,没有说接口只能帮我们探索隐空间。也许可以添加一些操作,故意将我们带出隐空间,或者减少自然图片空间的可能性(以及更令人惊奇的)部分。
当然,GAN 不是唯一的生成模型。在一个足够强大的生成模型中,模型发现的概括可能包含了超越人类发现的思想。在这种情况下,对隐空间的探索可能使我们能够发现新的基本原则。模型会比人类专家发现更强的抽象。想象一下,在立体画派出现之前,一个专门研究绘画的生成模型;也许通过探索这个模型,我们就有可能发现立体主义吗?正如本文之前所讨论的,这将是类似于对波尔-爱因斯坦凝聚态预测的类比。这种发明超越了当今的生成模型,但似乎是对未来模型的一种有价值的渴望。
到目前为止,我们的例子都是基于生成模型的,但是有一些启发性的例子不是基于生成模型的。考虑由 Isola 等人[23]提出的 pix2pix 系统这个系统训练成对的图片,例如表现猫的边缘和实际的猫。一旦经过训练,就可以显示一组边缘,并要求它为生成实际对应的猫的图片,它经常表现得很好:

在不寻常的限制条件下,pix2pix 可以产生惊人的图片:
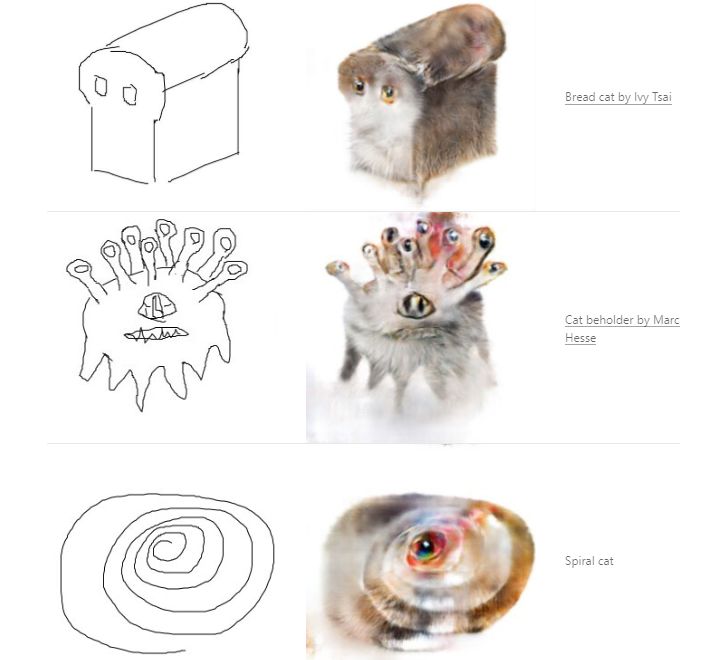
这也许不是毕加索式的高级创造力,但仍是惊人的。这当然不像我们大多数人以前见过的图片。pix2pix 和它的用户是如何达到这种效果的呢?
与前面的例子不同,pix2pix 不是生成模型。这意味着它没有隐空间,也没有对应的自然图片空间。而是一个神经网络,令人困惑地被称为生成器——这与我们早期的生成模型并不同——它以约束的图片作为输入,并生成填充的图片。
生产器的训练和判别器网络的训练是对抗的,判别器的工作是区分出从真实数据中生成的图片组和由生成器生成的图片组。
虽然这听起来很像传统的 GAN,但是有一个关键的区别:生成器中没有隐向量输入,相反,这里只有一个输入约束。当人输入一种与训练数据不一样的约束时,网络就被迫即兴发挥,尽其所能地根据之前所学的规则来解释这个约束。创造力是由训练数据推断出的知识与用户提供的约束一起作用的结果。因此,即使是相对简单的想法——比如面包或眼睛猫——也能产生引人注目的新型图片,这些图片并不在我们之前认为的自然图片的空间中。
七、总结
传统观念认为人工智能将改变我们与计算机交互方式。不幸的是,人工智能社区中的许多人大大低估了接口设计的深度,往往将其视为一个简单的问题,主要是关注于如何使事物变得漂亮或易于使用。从这个角度来说,接口设计是一个交给别人的问题,而繁重的工作是训练一些机器学习系统。
这种观点是不正确的,接口设计最深层的含义是开发人类思考和创造的基本要素。这个问题的知识起源可以追溯到字母表的发明者、制图学的发明者、音乐符号的发明者以及现代的巨人如笛卡尔、普莱菲尔、费曼、恩格尔巴特和凯。这是人类所面临的最困难、最重要、最根本的问题之一。
如前所述,在人工智能的一个普遍观点中,我们的计算机将继续在解决问题方面做得更好,但人类基本保持不变。在第二种常见的观点中,人类将在硬件层面进行修改,可能直接通过神经接口,或者间接通过全脑模拟。
我们描述了第三种观点,AI实际上改变了人类,帮助我们发明了新的认知技术,扩展了人类思维的范围。或许有一天,这些认知技术将反过来加速AI的发展,形成良性循环:
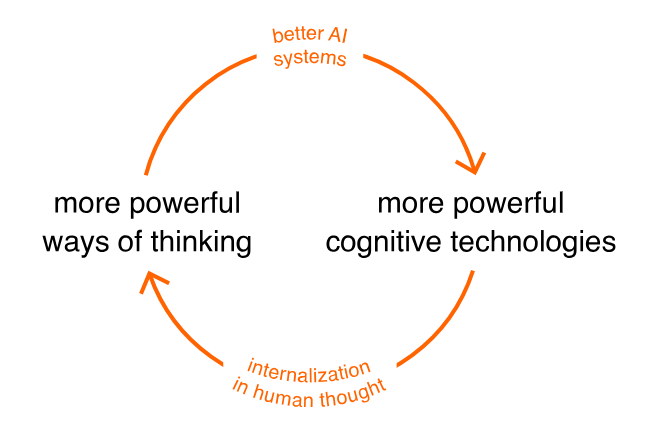
它不会是机器中的奇点,相反,它将是人类思维中的一个奇点。当然,这个循环目前仅仅只是一个推测。我们所描述的系统可以帮助开发更强大的思维方式,但至多有一种间接的感觉,即这些思维方式被用来开发新的AI系统。
当然,从长期来看,机器在所有或大部分认知任务上都有可能超过人类。即便如此,认知转换仍将是一个有价值的目标,值得我们自己去追求。学习下象棋或围棋是有趣和有价值的,即使机器做得更好。而在诸如讲故事之类的活动中,益处往往更多地来自建构故事和人物关系这一过程,而非最终的产物。个人的改变和成长还具有内在的价值,除了工具性利益以外。
我们讨论的面向接口的工作超出了用来评价 AI 中大多数现有工作的叙述。它不涉及击败某个分类或回归问题的基准。它无需非得在譬如围棋这样的比赛中,击败人类的冠军。相反,它涉及一个更为主观和难以衡量的标准:它是否有助于人类以新的方式思考和创造?
这给这类工作带来了困难,尤其是在研究环境中。比如,这应该发表在哪里呢?它属于什么社区呢?应该用什么标准来评判这样的工作呢?好的工作和坏工作的区别是什么?
我们相信,在未来几年内,将出现一个能够回答这些问题的社区。它将举办研讨会和会议。它将在类似 Distill 等地方发表工作。它的标准将来自许多不同的社区:有艺术社区和音乐社区的探讨;有数学社区的对抽象的品味及“好”的定义;以及现有的 AI 和 IA 社区(包括计算创造力和人机交互的工作)。
对成功的长期测试将是开发被创造者广泛使用的工具。艺术家们是否在使用这些工具来开发不同寻常的新风格?其他领域的科学家是否用它们来发展用其他方法不可能获得的理解?这些都是伟大的理想,需要一种建立在传统人工智能上的方法之上,但也包含了非常不同的规范。
八、参考文献
[1] Augmenting Human Intellect: A Conceptual Framework Engelbart, D.C., 1962.
[2] deeplearn.js font demo [link] Wexler, J., 2017.
[3] Auto-encoding variational Bayes Kingma, D.P. and Welling, M., 2014. ICLR.
[4] Analyzing 50k fonts using deep neural networks [HTML] Bernhardsson, E., 2016.
[5] Autoencoding beyond pixels using a learned similarity metric Larsen, A.B.L., Sønderby, S.K., Larochelle, H. and Winther, O., 2016. ICML.
[6] Sampling Generative Networks [PDF] White, T., 2016.
[7] Writing with the Machine [link] Sloan, R., 2017. Eyeo.
[8] Automatic chemical design using a data-driven continuous representation of molecules [PDF] Gómez-Bombarelli, R., Duvenaud, D., Hernández-Lobato, J.M., Aguilera-Iparraguirre, J., Hirzel, T.D., Adams, R.P. and Aspuru-Guzik, A., 2016.
[9] Generative visual manipulation on the natural image manifold Zhu, J., Krähenbühl, P., Schechtman, E. and Efros, A.A., 2016. European Conference on Computer Vision (ECCV).
[10] Generative adversarial nets Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A. and Bengio, Y., 2014. Advances in Neural Information Processing Systems (NIPS), pp. 2672-2680.
[11] A Neural Representation of Sketch Drawings [PDF] Ha, D. and Eck, D., 2017.
[12] Real-time human interaction with supervised learning algorithms for music composition and performance. Fiebrink, R., 2011. Princeton University PhD Thesis.
[13] TopoSketch: Drawing in Latent Space
Loh, I. and White, T., 2017. NIPS Workshop on Machine Learning for Creativity and Design.
[14] Taking The Robots To Design School, Part 1 [link] Gold, J., 2016.
[15] Hierarchical Variational Autoencoders for Music [PDF] Roberts, A., Engel, J. and Eck, D., 2017. NIPS Workshop on Machine Learning for Creativity and Design.
[16] Computational creativity: the final frontier? Colton, S. and Wiggins, G.A., 2012. ECAI.
[17] Interactive machine learning: letting users build classifiers Ware, M., Frank, E., Holmes, G., Hall, M. and Witten, I.H., 2001. International Journal of Human-Computer Studies, Vol 55, pp. 281-292.
[18] Eccentric School of Painting Increased Its Vogue in the Current Art Exhibition — What Its Followers Attempt to Do [link] 1911. The New York Times.
[19] Genius: The Life and Science of Richard Feynman Gleick, J., 1992. Vintage Books.
[20] Thought as a Technology [HTML] Nielsen, M., 2016.
[21] InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever, I. and Abbeel, P., 2016. NIPS.
[22] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks [PDF] Radford, A., Metz, L. and Chintala, S., 2016. ICLR.
[23] Image-to-Image Translation with Conditional Adversarial Networks [PDF] Isola, P., Zhu, J., Zhou, T. and Efros, A.A., 2017.
原文地址:https://distill.pub/2017/aia/
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”