记得刚读研究生的时候,学习的第一个算法就是meanshift算法,所以一直记忆犹新,今天和大家分享一下Meanshift算法,如有错误,请在线交流。
Mean Shift算法,一般是指一个迭代的步骤,即先算出当前点的偏移均值,移动该点到其偏移均值,然后以此为新的起始点,继续移动,直到满足一定的条件结束.
1. Meanshift推导
给定d维空间Rd的n个样本点 ,i=1,…,n,在空间中任选一点x,那么Mean Shift向量的基本形式定义为:
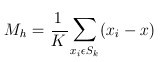
Sk是一个半径为h的高维球区域,满足以下关系的y点的集合,
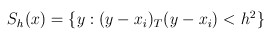
k表示在这n个样本点xi中,有k个点落入Sk区域中.
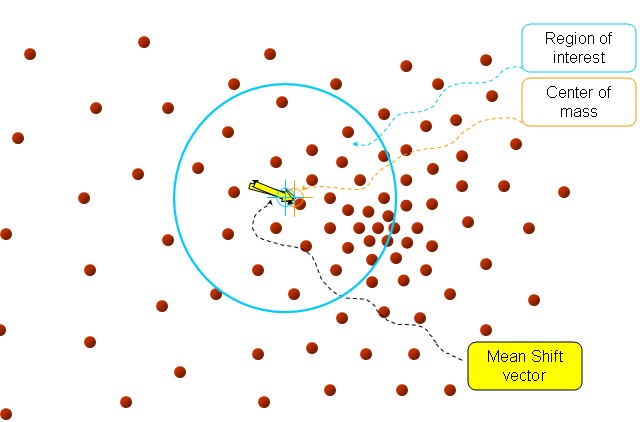
以上是官方的说法,即书上的定义,我的理解就是,在d维空间中,任选一个点,然后以这个点为圆心,h为半径做一个高维球,因为有d维,d可能大于2,所以是高维球。落在这个球内的所有点和圆心都会产生一个向量,向量是以圆心为起点落在球内的点位终点。然后把这些向量都相加。相加的结果就是Meanshift向量。
如图所以。其中黄色箭头就是Mh(meanshift向量)。
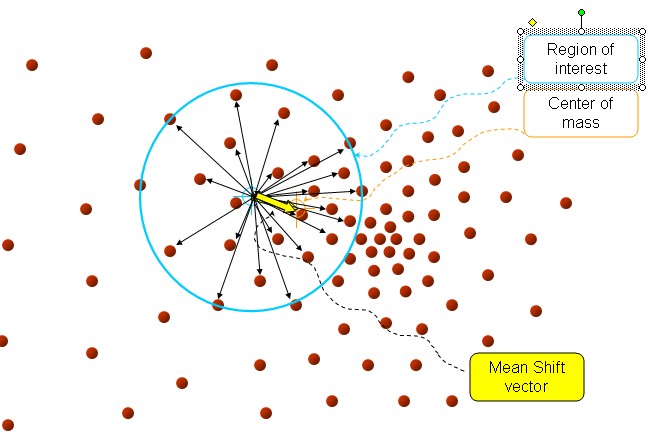
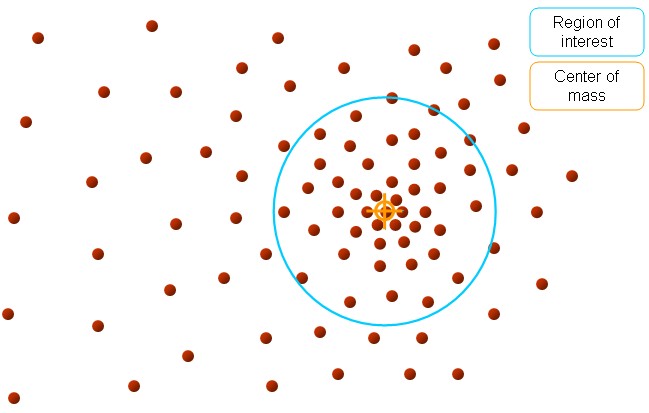
再以meanshift向量的终点为圆心,再做一个高维的球。如下图所以,重复以上步骤,就可得到一个meanshift向量。如此重复下去,meanshift算法可以收敛到概率密度最大得地方。也就是最稠密的地方。
最终的结果如下:
Meanshift推导:
那么,meanshift算法变形为
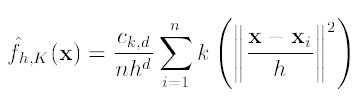
(1)
解释一下K()核函数,h为半径,Ck,d/nhd为单位密度,要使得上式f得到最大,最容易想到的就是对上式进行求导,的确meanshift就是对上式进行求导.
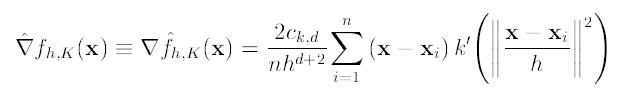
(2)
令:
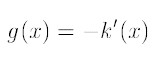
K(x)叫做g(x)的影子核,名字听上去听深奥的,也就是求导的负方向,那么上式可以表示
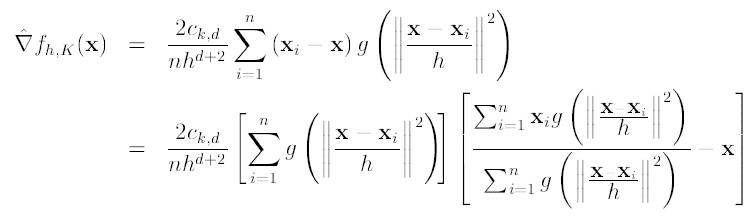
对于上式,如果才用高斯核,那么,第一项就等于fh,k
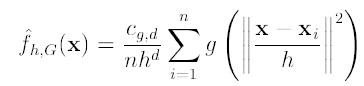
第二项就相当于一个meanshift向量的式子:
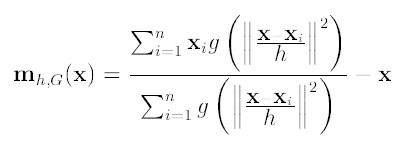
那么(2)就可以表示为
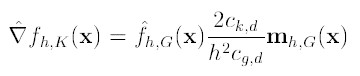
下图分析
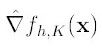 的构成,如图所以,可以很清晰的表达其构成。
的构成,如图所以,可以很清晰的表达其构成。
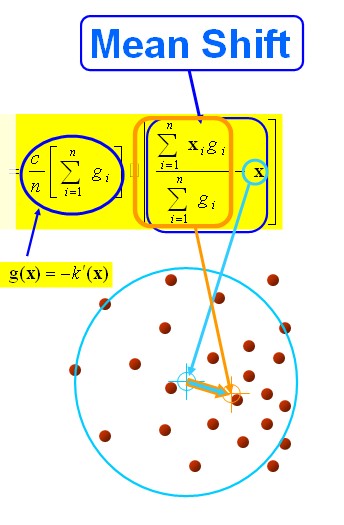
要使得
=0,当且仅当
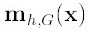 =0,可以得出新的圆心坐标:
=0,可以得出新的圆心坐标:
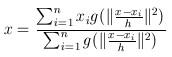
(3)
上面介绍了meanshift的流程,但是比较散,下面具体给出它的算法流程。
选择空间中x为圆心,以h为半径为半径,做一个高维球,落在所有球内的所有点xi
计算
,如果
>ε, 则利用(3)计算x,返回1.
2.meanshift在图像上的聚类:
真正大牛的人就能创造算法,例如像meanshift,em这个样的算法,这样的创新才能推动整个学科的发展。还有的人就是把算法运用的实际的运用中,推动整个工业进步,也就是技术的进步。下面介绍meashift算法怎样运用到图像上的聚类核跟踪。
一般一个图像就是个矩阵,像素点均匀的分布在图像上,就没有点的稠密性。所以怎样来定义点的概率密度,这才是最关键的。
如果我们就算点x的概率密度,采用的方法如下:以x为圆心,以h为半径。落在球内的点位xi定义二个模式规则。
(1)x像素点的颜色与xi像素点颜色越相近,我们定义概率密度越高。
(2)离x的位置越近的像素点xi,定义概率密度越高。
所以定义总的概率密度,是二个规则概率密度乘积的结果,可以(4)表示
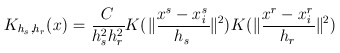
(4)
其中:
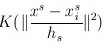 代表空间位置的信息,离远点越近,其值就越大,
代表空间位置的信息,离远点越近,其值就越大,
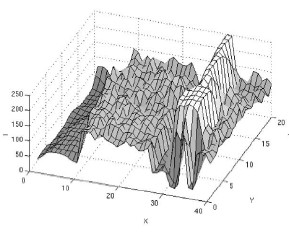
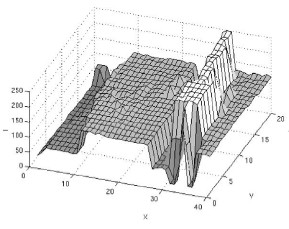
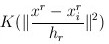 表示颜色信息,颜色越相似,其值越大。如图左上角图片,按照(4)计算的概率密度如图右上。利用meanshift对其聚类,可得到左下角的图。
表示颜色信息,颜色越相似,其值越大。如图左上角图片,按照(4)计算的概率密度如图右上。利用meanshift对其聚类,可得到左下角的图。


如有问题,可在线讨论。作者:BIGBIGBOAT/Liqizhou