
来源:CSDN
移动互联网“早古”时期,普通人因为收入差距问题而无法做到人手一部智能手机,从而导致数字鸿沟。同样,在当前这个AI,也就是人工智能扮演越来越关键作用的时代,企业也站在了类似的抉择交接线上——是否有足够的实力或能力拥抱智能化?而这个问题的成本,可就不是一个小小的智能手机了。因缺少AI人才、技术积累或财力支持而难以靠自身力量完成AI基础设施建设的企业,在智能化转型的过程中正将面临这样的智能化鸿沟,能否破解,很可能会关乎新十年中它们的命运走向。

如何消除智能化鸿沟?
要解决问题,就要先精确定位问题所在。
一方面,构建AI能力对于普通企业来说,IT基础设施维护、AI框架搭建、训练和推理、硬件和软件、人才和巨额算力成本等这些“夯地基”的事情需要从零做起,然而大部分企业,尤其是传统行业企业并没有相关经验;另一方面,智能化转型又迫在眉睫,企业需要快速让自己具备AI能力,才能赶上不断变化的需求。
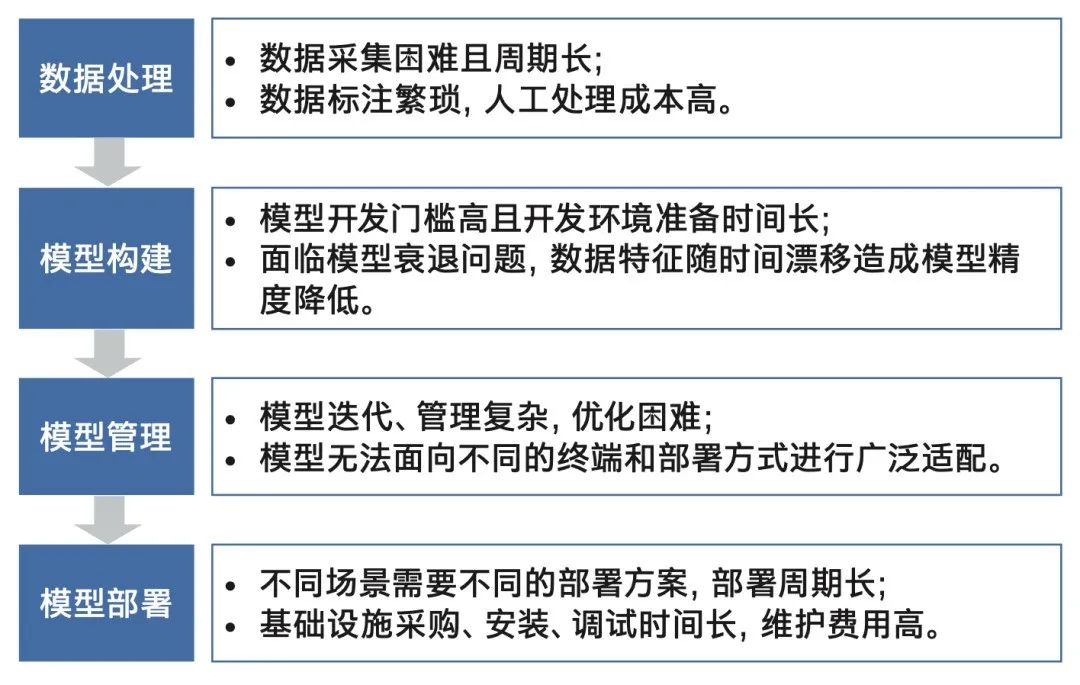
企业在AI应用开发和使用各阶段可能遇到的挑战,
虽然不全,但已足够“挑战”
包括那些有一定的AI人才、技术积累与创新能力,但仍不足以支撑自身智能化转型的企业在内,大家都在寻找一种功能全面、部署便捷且性价比高的法子,来帮助它们快速完成AI能力的构建和部署。
这就给了云服务提供商大展身手的机会,通过输出快捷、高效、实惠的AI云服务,帮助条件和实力不足的企业快速部署和实践AI应用,它们可以做到既惠人,又利已。

意外!CPU成AI云服务热门选择
紧迫的需求,已经在过去数年催生了众多针对AI的云服务和产品,IaaS和PaaS级别的服务是主流,例如AIaaS (AI as a Service)、AI 在线服务、增强型 IaaS、企业级AI一体机,深度学习云平台等等,硬件搭配也是多种多样,例如基于CPU、GPU、TPU、NPU、FPGA等等,都在为企业AI转型提供包括基础设施构建及优化、AI应用开发和部署,以及AI 模型训练与推理效能优化在内的多种支持。
有趣的是,CPU作为通用处理器,在AI云服务的抢眼程度,并不亚于专用的AI加速芯片。通过实际应用分析,我们不难发现,如果不是专注于AI算法模型训练和开发的企业,大多数企业使用AI时其实更偏推理型的应用。对他们来说,基于CPU平台的云服务,特别是集成了可加速AI应用的AVX-512技术和深度学习加速技术的英特尔至强平台的AI云服务,其实在很多应用场景中都足以应对实战需求,且不论对于他们,还是云服务提供商而言,部署都更快、更便捷,上手门槛也低。
就这样,可能与大家的印象相悖,CPU成为了很多云服务提供商输出,以及企业采用AI云服务时的热门选择,这使得以CPU为基础设施的AI云服务异军突起。

用CPU做AI云服务,集成AI加速是前提
如前文提到,基于CPU的云服务要受欢迎,并不是仅仅做好通用计算任务就够了,首先就要针对AI应用在硬件上集成特定的加速能力。
作为老牌CPU厂商的英特尔,早在2017年就于第一代至强可扩展处理器上导入了可以加速浮点运算(涵盖AI运算)的AVX-512技术;而后又在2019年推出的第二代至强可扩展处理器上集成了可以加速INT8的英特尔深度学习加速技术,专攻推理优化;2020年和今年,分别面向多路和单、双路服务器的第三代至强可扩展处理器依次亮相,后者靠INT8加速主攻推理,前者则通过同时支持INT8和BF16加速,兼顾了CPU上的AI训练和推理任务。

2021年面向单路和双路服务器的全新第三代至强可扩展处理器的主要优势,包括再次提升AI推理性能
CPU有了AI加速能力,用它来构建AI云服务的根基就已奠定。但为了充分发挥出这些硬件AI加速能力,英特尔还同步提供了一系列开源AI软件优化工具,包括基础性能优化工具oneDNN,可帮助AI模型充分量化利用CPU加速能力、预置了大量预优化模型并能简化它们在CPU平台上部署操作的OpenVINO,以及可以在现有大数据平台上开展深度学习应用,从而无缝对接大数据平台与AI应用的Analytics Zoo等。英特尔还将oneDNN融入了TensorFlow、Pytorch等主流AI框架,将它们改造成面向英特尔架构优化的AI框架。
通过这些举措,英特尔架构CPU平台加速AI应用的软硬两种能力就有了“双剑合璧”的效果。而英特尔和云服务提供商合作伙伴的实践,也正是基于此展开的。

CPU AI云服务第一式,软硬打包上手快
得益于英特尔提供的全面AI加速软硬件组合,多数云服务提供商无需做更多调整和优化,就可迅速打造出针对AI的基础设施即服务或AI云主机产品。简单来说,就是将集成AI加速能力的至强可扩展平台与我们提到的软件工具,例如oneDNN或面向英特尔架构优化的AI框架软硬打包,就可快速形成易于部署和扩展的AI云主机镜像。
国内有云服务提供商早在2017年就进行了类似的尝试,通过使用英特尔优化软件,它激活了至强平台的AI加速潜能,并在部分应用场景实现了可与GPU相媲美的推理性能。
如果仅有性能优化还不够,还需要更快的模型部署能力,那就可以像CDS首云一样导入OpenVINO。它通过至强可扩展平台、高性能 K8S 容器平台和OpenVINO Model Server这三者的组合大幅简化了AI模型的部署、维护和扩展。性能实测结果也表明,OpenVINO不仅在用户并发接入能力上优于首云此前采用的AI框架,在推理应用的时延等关键性能指标上也有良好表现。
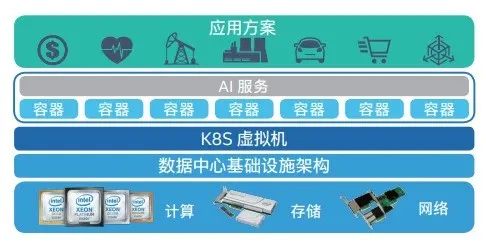
CDS首云AI云服务方案架构

CPU AI云服务第二式,深度优化收益多
仅仅是导入英特尔已经就绪的AI软硬件组合,就已能输出令人满足的AI云服务了,那么如果是和英特尔在AI云服务的算法及模型上进行更深入的优化,又会有什么惊喜呢?像阿里云这样的头部云服务提供商就通过实战给出了答案。
以阿里云为例,其机器学习平台PAI在与英特尔的合作中,利用了第三代英特尔至强可扩展处理器支持的bfloat16加速,来主攻PAI之上BERT性能的调优,具体来说就是以经过优化的Float32 Bert模型为基准,利用BF16加速能力优化了该模型的MatMul算子,以降低延迟。测试结果表明:与优化后的FP32 Bert模型相比,至强平台BF16加速能力能在不降低准确率的情况下,将BERT模型推理性能提升达1.83倍。
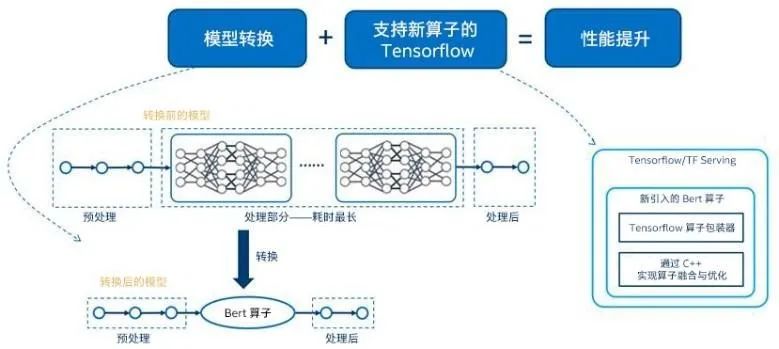
阿里云PAI BERT 模型优化方案

CPU AI云服务第三式 扎根框架打根基
如果说从提供软硬协同的基础平台到定向深度优化算法,算是AI云服务在优化程度上的迈进,或者说云服务提供商与英特尔在AI云服务构建和优化上的深化合作的话,那么如果有云服务提供商能在深度学习框架这个AI基石上与英特尔开展合作,那是不是会更具意义呢?
为这个问题输出答案的是百度,它的开源深度学习平台“飞桨”先后结合第二代和第三代至强可扩展处理器在计算、内存、架构和通信等多层面进行了基础性的优化。其结果也是普惠性的——优化后的飞桨框架能够充分调动深度学习加速技术,可将众多AI模型,特别是图像分类、语音识别、语音翻译、对象检测类的模型从FP32瘦身到INT8,在不影响准确度的情况下,大幅提升它们的推理速度。

英特尔深度学习加速技术可通过1条指令执行8位乘法和32位累加,INT8 OP理论算力峰值增益为FP32 OP的4倍
例如在图像分类模型ResNet50的测试中,飞桨搭配英特尔今年发布的全新第三代至强可扩展处理器对其进行INT8量化后,其推理吞吐量可达FP32的3.56倍之多。
如此性能增幅,再加上CPU易于获取、利用和开发部署的优势,让飞桨的开发者们可借助AI框架层面的优化,更加快速、便捷地创建自己可用CPU加速的深度学习应用。而为了给企业开发者们提供更多便利,百度还推出了EasyDL和BML(Baidu Machine Learning)全功能AI开发平台,通过飞桨基于全新第三代至强可扩展处理器的优化加速,来为企业提供一站式AI开发服务。

百度飞桨开源深度学习平台与飞桨企业版

展望未来,跨越智能化鸿沟不仅靠算力
前文CDS首云、阿里云和百度的实例,可以说是充分反映了用CPU做AI云服务的现状,而这些云服务也正是为当前希望跨越智能化鸿沟的企业设计的。当然,它们也会持续演进,比如说随着未来AI技术的进一步发展,特别是大数据与AI融合带来的新需求,不论是用CPU还是专用加速器,不论是企业自建AI基础设施和应用,还是云服务提供商输出的AI云服务,都会在数据存储而非算力上面临越来越多的挑战。
毕竟,算力、算法和数据是并驾齐驱的“三驾马车”,随着数据规模进一步暴增,数据存储也将对AI的部署和应用带来更多挑战。
好消息是,国内的云服务提供商也早已和英特尔就此展开了前瞻创新,例如百度智能云早在2019年就推出了ABC(AI、Big Data、Cloud)高性能对象存储解决方案,能利用英特尔傲腾固态盘的高性能、低时延和高稳定来满足AI训练对数据的高并发迭代吞吐需求。
值得一提的是,英特尔在今年发布全新第三代至强可扩展处理器时,也带来了与其搭档的英特尔傲腾持久内存200系列和傲腾固态盘P5800X。

与全新第三代至强可扩展处理器搭配使用的傲腾持久内存和固态盘新品
相信未来会有更多专攻AI应用场景的存储系统导入这些新品,把更多数据存放在更靠近CPU或其他加速器的地方,从数据就绪或“供给”层面提升AI推理和训练的性能。而提供这些AI优化型存储系统或服务的,多数也很可能是技术实力雄厚的云服务提供商们,这样一来,用户就不用担心在应对智能化鸿沟时再遇到大数据和AI对接的难题了。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

![[js] 渲染树构建、布局及绘制](http://pic.xiahunao.cn/[js] 渲染树构建、布局及绘制)




)


------事务管理)










)