链接:https://ac.nowcoder.com/acm/problem/16589
来源:牛客网
时间限制:C/C++ 1秒,其他语言2秒
空间限制:C/C++ 131072K,其他语言262144K
64bit IO Format: %lld
题目描述
小晨的电脑上安装了一个机器翻译软件,他经常用这个软件来翻译英语文章。
这个翻译软件的原理很简单,它只是从头到尾,依次将每个英文单词用对应的中文含义来替换。对于每个英文单词,软件会先在内存中查找这个单词的中文含义,如果内存中有,软件就会用它进行翻译;如果内存中没有,软件就会在外存中的词典内查找,查出单词的中文含义然后翻译,并将这个单词和译义放入内存,以备后续的查找和翻译。
假设内存中有 M 个单元,每单元能存放一个单词和译义。每当软件将一个新单词存入内存前,如果当前内存中已存入的单词数不超过 M−1,软件会将新单词存入一个未使用的内存单元;若内存中已存入M 个单词,软件会清空最早进入内存的那个单词,腾出单元来,存放新单词。
假设一篇英语文章的长度为N 个单词。给定这篇待译文章,翻译软件需要去外存查找多少次词典?假设在翻译开始前,内存中没有任何单词。
输入描述:
输入共2 行。每行中两个数之间用一个空格隔开。
第一行为两个正整数M 和N,代表内存容量和文章的长度。
第二行为 N 个非负整数,按照文章的顺序,每个数(大小不超过 1000)代表一个英文单词。文章中两个单词是同一个单词,当且仅当它们对应的非负整数相同。
输出描述:
共1 行,包含一个整数,为软件需要查词典的次数。
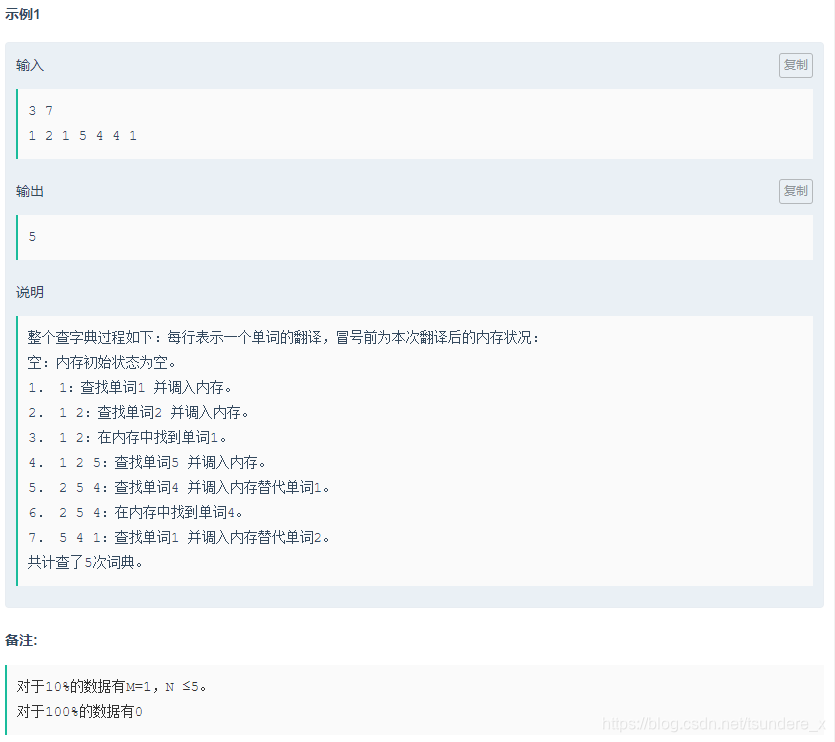
M, N = list(map(int, input().split()))
words = list(map(int, input().split()))
t = []
res = 0
for i in range(M):t.append(-1)
#print(words)
j = 0
if N <= M:print(len(set(words)))
else:for i in range(N):if words[i] in t:continuet[j%M] = words[i]j += 1res += 1else:print(res)











)







