来源:AI科技评论
作者:Mr Bear、杏花
编辑:青暮
经典的「没有免费午餐定理」表明:如果某种学习算法在某些方面比另一种学习算法更优,则肯定会在其它某些方面弱于另一种学习算法。
也就是说,对于任何一个学习问题,没有最优的算法,只有最合适的算法。
而在这项最新研究中,作者向我们揭示了这一现象背后的数学原理:每个神经网络,都是一个高维向量。
在高维向量空间中,不存在单调的大小比较。如果两个向量A、B是垂直的,则内积为零,通常也反映两者更加不相关,比如作用在物体运动方向的垂直方向的力就不做功。
类似地,如果两个神经网络对应的向量内积为零,则反映它们的相似程度更低。
在拟合第三个向量C,也就是通过数据进行训练和学习时,如果A和C内积更大,则表示A更容易学习C,也反映B更不容易学习C。
另一方面,当A通过训练变得更加接近C时,与C垂直的另一个神经网络D也会因此和A更加不相关,也就是A变得更加难以学习D。
此即本文提出的「没有免费午餐定理」加强版。
利用这个数学描述,我们就可以量化神经网络的泛化能力。
该研究主要基于宽神经网络,而表示神经网络的高维空间的每一个维度,都是由神经正切核的特征向量构成的。
神经正切核与宽神经网络的联系,在之前的文章中已有介绍,参见:深度学习为何泛化的那么好?秘密或许隐藏在内核机中
同时,作者也指出,该发现在宽度较小的网络中也成立。
在高维空间中,神经网络泛化性的非单调数学关系一览无余。
长期以来,探寻神经网络泛化性能的量化方法一直是深度学习研究的核心目标。
尽管深度学习在许多任务上取得了巨大的成功,但是从根本上说,我们还无法很好地解释神经网络学习的函数为什么可以很好地泛化到未曾见过的数据上。
从传统的统计学习理论的直觉出发,过参数化的神经网络难以获得如此好的泛化效果,我们也很难得到有用的泛化界。
因此,研究人员试图寻找一种新的方法来解释神经网络的泛化能力。
近日,加州大学伯克利分校的研究者于 Arxiv 上在线发表了一篇题为「NEURAL TANGENT KERNEL EIGENVALUES ACCURATELY PREDICT GENERALIZATION」的论文,指出「神经正切核」的特征值可以准确地预测神经网络的泛化性能。
「神经正切核」是近年来神经网络优化理论研究的热点概念,研究表明:通过梯度下降以无穷小的步长(也称为梯度流)训练的经过适当随机初始化的足够宽的神经网络,等效于使用称为神经正切核(NTK)的核回归预测器。
在本文中,作者指出:通过研究神经网络的神经正切核的特征系统,我们可以预测该神经网络在学习任意函数时的泛化性能。具体而言,作者提出的理论不仅可以准确地预测测试的均方误差,还可以预测学习到的函数的所有一阶和二阶统计量。
此外,通过使用量化给定目标函数的「可学习性」的度量标准,本文作者提出了一种加强版的「没有免费午餐定理」,该定理指出,对于宽的神经网络而言:提升其对于给定目标函数的泛化性能,必定会弱化其对于正交函数的泛化性能。
最后,作者将本文提出的理论与宽度有限(宽度仅为 20)的网络进行对比,发现本文提出的理论在这些宽度较小的网络中也成立,这表明它不仅适用于标准的 NTK,事实上也能正确预测真实神经网络的泛化性能。

论文地址:
https://arxiv.org/pdf/2110.03922.pdf
1
问题定义及研究背景
作者首先将上述问题形式化定义为:从第一性原理出发,对于特定的目标函数,我们是否高效地预测给定的神经网络架构利用有限的个训练样本学习到的函数的泛化性能?
该理论不仅可以解释为什么神经网络在某些函数上可以很好地泛化,而且还可以预测出给定的网络架构适合哪些函数,让我们可以从第一性原理出发为给定的问题挑选最合适的架构。
为此,本文作者进行了一系列近似,他们首先将真实的网络近似为理想化的宽度无限的网络,这与核回归是等价的。接着,作者针对核回归的泛化推导出了新的近似结果。这些近似的方程能够准确预测出原始网络的泛化性能。
本文的研究建立在无限宽网络理论的基础之上。该理论表明,随着网络宽度趋于无穷大,根据类似于中心极限定理的结果,常用的神经网络会有非常简单的解析形式。特别是,采用均方误差(MSE)损失的梯度下降训练的足够宽的网络等价于 NTK 核回归模型。利用这一结论,研究者们研究者们通过对核回归的泛化性能分析将相同的结论推广至了有限宽的网络。
Bordelon 等人于 2020 年发表的 ICML 论文「Spectrum dependent learning curves in kernel regression and wide neural networks」指出,当使用 NTK 作为核时,其表达式可以精准地预测学习任意函数的神经网络的 MSE。我们可以认为,当样本被添加到训练集中时,网络会在越来越大的输入空间中泛化得很好。这个可学习函数的子空间的自然基即为 NTK 的特征基,我们根据其特征值的降序来学习特征函数。
具体而言,本文作者首先形式化定义了目标函数的可学习性,该指标具备 MSE 所不具备的一些理想特性。接着,作者使用可学习性来证明了一个加强版的「没有免费午餐定理」,该定理描述了核对正交基下所有函数的归纳偏置的折中。该定理表明,较高的 NTK 本征模更容易学习,且这些本征模之间在给定的训练集大小下的学习能力存在零和竞争。作者进一步证明,对于任何的核或较宽的网络,这一折中必然会使某些函数的泛化性能差于预期。
2
特征值与特征向量
令A为n阶方阵,若存在数λ和非零向量x,使得Ax=λx,则λ称为A的特征值,x为A对应于特征值λ的特征向量。
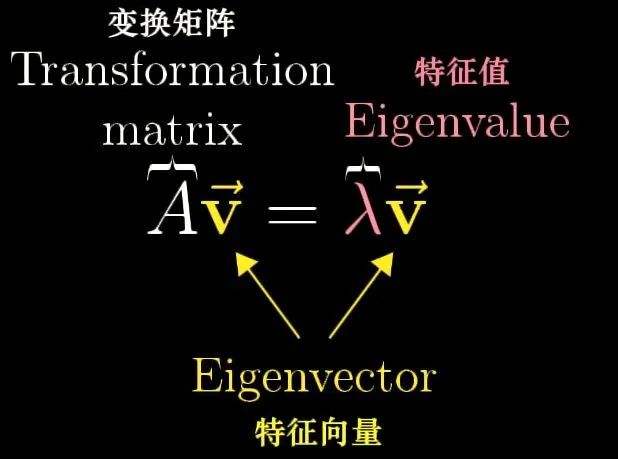
图 1:特征值与特征向量的定义
简而言之,由于λ为常量,矩阵A并不改变特征向量的方向,只是对特征向量进行了尺度为λ的伸缩变换:
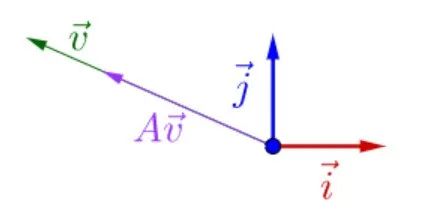
图 2:特征值与特征向量的几何意义
通过在特征向量为基构成的向量空间中将神经网络重新表示,我们得以将不同初始化的神经网络以及学习后的神经网络进行量化对比。
3
神经正切核
一个前馈神经网络可以代表下面的函数:
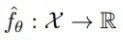
其中,θ是一个参数向量。令训练样本为x,目标值为y,测试数据点为x',假设我们以较小的学习率η执行一步梯度下降,MSE 损失为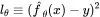 。则参数会以如下所示的方式更新:
。则参数会以如下所示的方式更新:
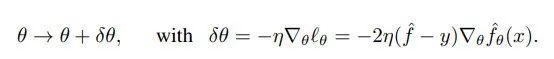
我们希望知道对于测试点而言,参数更新的变化有多大。为此,令θ线性变化,我们得到:
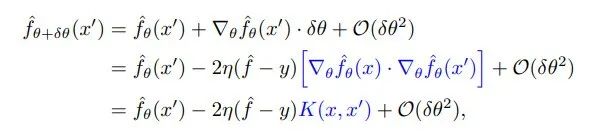
其中,我们将神经正切核 K 定义为:
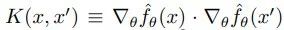
值得注意的是,随着网络宽度区域无穷大,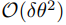 修正项可以忽略不计,且
修正项可以忽略不计,且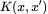 在任意的随机初始化后,在训练的任何时刻都是相同的,这极大简化了对网络训练的分析。可以证明,在对任意数据集上利用 MSE 损失进行无限时长的训练后,网络学习到的函数可以归纳如下:
在任意的随机初始化后,在训练的任何时刻都是相同的,这极大简化了对网络训练的分析。可以证明,在对任意数据集上利用 MSE 损失进行无限时长的训练后,网络学习到的函数可以归纳如下:
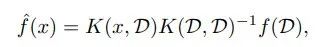
4
近似核回归的泛化
为了推导核回归的泛化性,我们将问题简化,仅仅观察核的特征基上的学习问题。我们将核看做线性操作,其特征值/向量对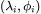 满足:
满足:
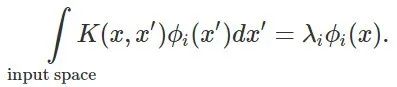
直观地说,核是一个相似函数,我们可以将它的高特征值特征函数解释为「相似」点到相似值的映射。在这里,我们的分析重点在于对泛化性的度量,我们将其称之为「可学习性」,它量化了标函数和预测函数的对齐程度:
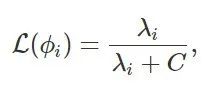
我们将初始化的神经网络f和学习目标函数f^分别用特征向量展开:
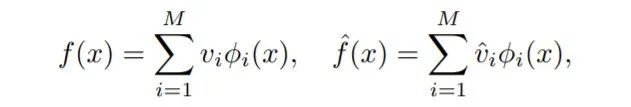
并以内积的形式提出可学习性的表达式:
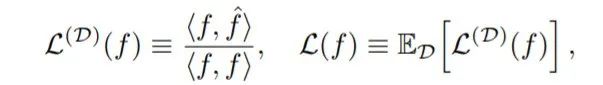
这样就可以计算f和f^之间的接近(可学习)程度。
作者还推导出了学习到的函数的所有一阶和二阶统计量的表达式,包括恢复之前的 MSE 表达式。如图 3 所示,这些表达式不仅对于核回归是相当准确的,而且也可以精准预测有限宽度的网络。
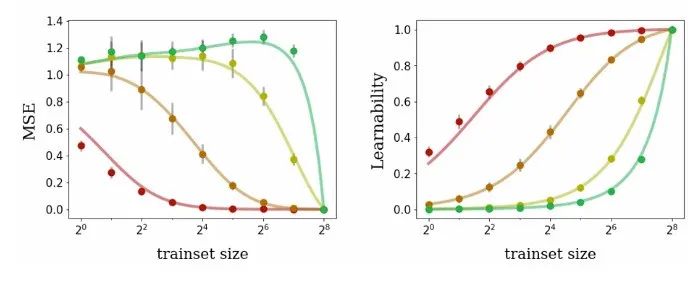
图 3:为四种训练集大小不同的布尔函数训练神经网络的泛化性能度量。无论是对 MSE 还是可学习性而言,理论预测结果(曲线)与真实性能(点)都能够很好地匹配。
5
核回归的没有免费午餐定理
除了对泛化性能的近似,本文作者还针对核回归问题提出了一种加强版的「没有免费午餐定理」。经典的「没有免费午餐定理」的结论是:由于对所有可能函数的相互补偿,最优化算法的性能是等价的。

图 4:经典的没有免费午餐定理(来源:《机器学习》,周志华)
简单地说,如果某种学习算法在某些方面比另一种学习算法更优,则肯定会在其它某些方面弱于另一种学习算法。具体而言,没有免费午餐定理表明:
1)对所有可能的的目标函数求平均,得到的所有学习算法的「非训练集误差」的期望值相同;
2)对任意固定的训练集,对所有的目标函数求平均,得到的所有学习算法的「非训练集误差」的期望值也相同;
3)对所有的先验知识求平均,得到的所有学习算法的「非训练集误差」的期望值也相同;
4)对任意固定的训练集,对所有的先验知识求平均,得到的所有学习算法的的「非训练集误差」的期望值也相同。
对于核回归问题而言,所有可能的目标函数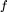 的期望满足:
的期望满足:

所有核特征函数的可学习性与训练集大小正相关。
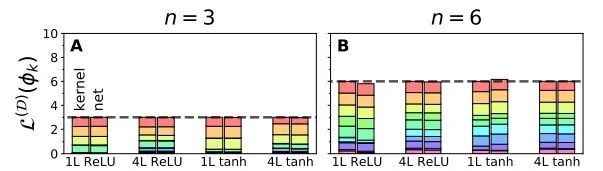
图 5:可学习性的特征函数之和始终为训练集的大小。
如图 5 所示,堆叠起来的柱状图显式了一个在十点域上的十个特征函数的随机 D 可学习性。堆叠起来的数据柱显示了十个特征函数的 D-可学习性,他们都来自相同的训练集 D,其中数据点个数为 3,我们将它们按照特征值的降序从上到下排列。每一组数据柱都代表了一种不同的网络架构。对于每个网络架构而言,每个数据柱的高度都近似等于 n。在图(A)中,对于每种学习情况而言,左侧的 NTK 回归的 D-可学习性之和恰好为 n,而右侧代表有限宽度网络的柱与左侧也十分接近。
6
实验结果
在本文中,作者通过一系列实验证明了对有限宽度网络和 NTK 回顾IDE所有理论预测。在实验过程中,所有的实验架构为带有 4 个隐藏层的全连接网络,使用的激活函数为 ReLU,网络宽度为 500。由于使用了全连接网络,因此其核为旋转不变性 NTK。实验使用了三个不同的输入空间x(离散的单位元、超立方体、超球面)。对于每个输入空间而言,x的特征模会被划分到k∈N的退化子集中,其中 k 越大则空间中的变化越快。在所有情况下,随着k的增大,特征值会减小,这与人们普遍认为的神经网络倾向于缓慢变化函数的「频谱偏置」(Spectral bias)是一致的。
神经核的谱分析结果
图 6:神经核的谱分析使我们可以准确地预测学习和泛化的关键度量指标。
图 6 中的图表展示了带有四个隐藏层、激活函数为 ReLU 的网络学习函数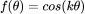 的泛化性能,其中训练数据点的个数为 n。理论预测结果与实验结果完美契合。
的泛化性能,其中训练数据点的个数为 n。理论预测结果与实验结果完美契合。
(A-F)经过完整 batch 的梯度下降训练后,模型学到的数据插值图。随着 n 增大,模型学到的函数
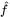 越来越接近真实函数。本文提出的理论正确地预测出:k=2 时学习的速率比 k=7 时更快,这是因为 k=2 时的特征值更大。
越来越接近真实函数。本文提出的理论正确地预测出:k=2 时学习的速率比 k=7 时更快,这是因为 k=2 时的特征值更大。(G,J)
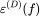 为目标函数和学习函数之间的 MSE,它是关于 n 的函数。图中的点代表均值,误差条代表对称的 1σ方差。曲线展示出了两盒的一致性,它们正确地预测了 k=2 时 MSE 下降地更快。
为目标函数和学习函数之间的 MSE,它是关于 n 的函数。图中的点代表均值,误差条代表对称的 1σ方差。曲线展示出了两盒的一致性,它们正确地预测了 k=2 时 MSE 下降地更快。(H,K)
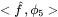 为伪本征模的傅里叶系数,
为伪本征模的傅里叶系数,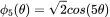 。由于 k=2 时的特征值更大,此时的傅里叶系数小于 k=7 时的情况。在这两种模式下,当
。由于 k=2 时的特征值更大,此时的傅里叶系数小于 k=7 时的情况。在这两种模式下,当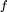 被充分学习时,傅里叶系数都会趋向于 0。实验结果表明理论预测的 1
被充分学习时,傅里叶系数都会趋向于 0。实验结果表明理论预测的 1 与实验数据完美契合。
与实验数据完美契合。(I,L)可学习性:对于目标函数和学习到的函数对齐程度的度量。随着 n 增大,
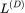 在[0,1]的区间内单调递增。由于 k=2 时的特征值更大,其可学习性也更高。
在[0,1]的区间内单调递增。由于 k=2 时的特征值更大,其可学习性也更高。
预测可学习性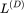
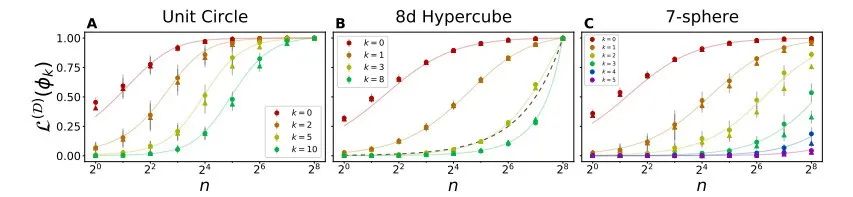
图 7:理论预测值与任意特征函数在多种输入空间上的真实的可学习性紧密匹配。每张图展示了关于训练集大小 n 的特征函数的可学习性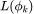 。NTK 回归和通过梯度下降训练的有限宽度网络的理论曲线完美匹配。误差条反映了1
。NTK 回归和通过梯度下降训练的有限宽度网络的理论曲线完美匹配。误差条反映了1 由于数据集的随机选择造成的方差。(A)单位圆上正弦特征函数的可学习性。作者将单位圆离散化为 M=2^8 个输入点,训练集包含所有的输入点,可以完美地预测所有的函数。(B)8d 超立方体顶点的子集对等函数的可学习性。k值较高的特征函数拥有较小的特征值,其学习速率较慢。当 n =2^8 时,所有函数的预测结果都很完美。虚线表示 L-n/m 时的情况,所有函数的可学习性都与一个随机模型相关。(C)超球谐函数的可学习性。具有较高 k 的特征函数有较小的特征值,学习速率较慢,在连续的输入空间中,可学习性没有严格达到 1。
由于数据集的随机选择造成的方差。(A)单位圆上正弦特征函数的可学习性。作者将单位圆离散化为 M=2^8 个输入点,训练集包含所有的输入点,可以完美地预测所有的函数。(B)8d 超立方体顶点的子集对等函数的可学习性。k值较高的特征函数拥有较小的特征值,其学习速率较慢。当 n =2^8 时,所有函数的预测结果都很完美。虚线表示 L-n/m 时的情况,所有函数的可学习性都与一个随机模型相关。(C)超球谐函数的可学习性。具有较高 k 的特征函数有较小的特征值,学习速率较慢,在连续的输入空间中,可学习性没有严格达到 1。
可学习性的统一形式
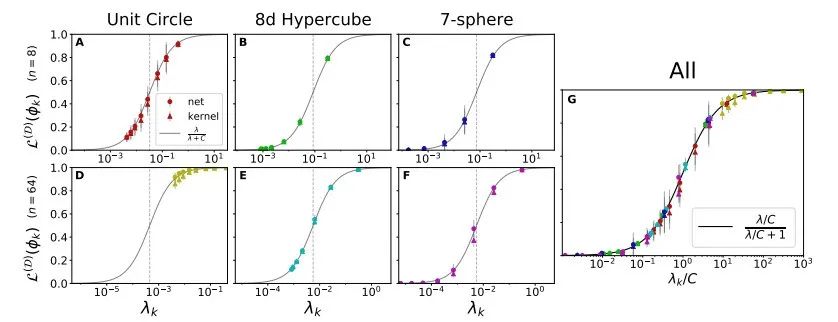
图 8:本征模的可学习性 vs. 特征值的统一函数形式。
对于任意的数据集大小和输入域而言,本征模的可学习性严格符合曲线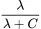 的形式,其中 C 为与问题无关的参数。理论曲线(实线)在每种情况下都是类似于 Sigmoid 函数的形状。NTK 回归和有限宽度网络的真实的本征模可学习性
的形式,其中 C 为与问题无关的参数。理论曲线(实线)在每种情况下都是类似于 Sigmoid 函数的形状。NTK 回归和有限宽度网络的真实的本征模可学习性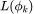 完美地契合。垂直的虚线代表每个学习问题下的 C 值。(A-C)可学习性 vs. 单位圆本征模的特征值。(D-F)n=64 时的可学习性曲线。此时每条曲线上的本征模都高于(A-C)中的情况,这说明由于 n 的增大导致可学习性也得以提升。(G)中的点来自(A-F),经过了放缩处理,放到了同一张图中。
完美地契合。垂直的虚线代表每个学习问题下的 C 值。(A-C)可学习性 vs. 单位圆本征模的特征值。(D-F)n=64 时的可学习性曲线。此时每条曲线上的本征模都高于(A-C)中的情况,这说明由于 n 的增大导致可学习性也得以提升。(G)中的点来自(A-F),经过了放缩处理,放到了同一张图中。
非均方误差曲线
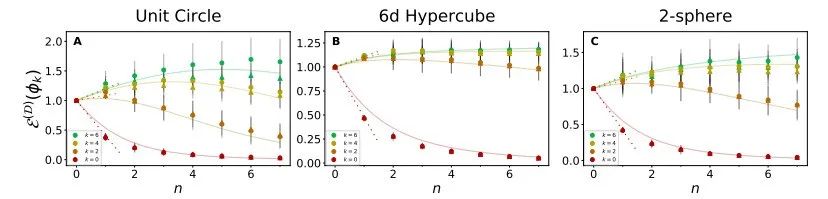
图 9:本文提出的理论可以正确预测,对于特征值较小的特征函数。
MSE会随着数据点被加入到较小的训练集中而增大。(A-C)在给定的 n 个训练点的 3 个不同域上分别学习 4 个不同特征模时,NTK 回归和有限网络的泛化 MSE。理论曲线与实验数据非常吻合。
宽度有限网络下的情况
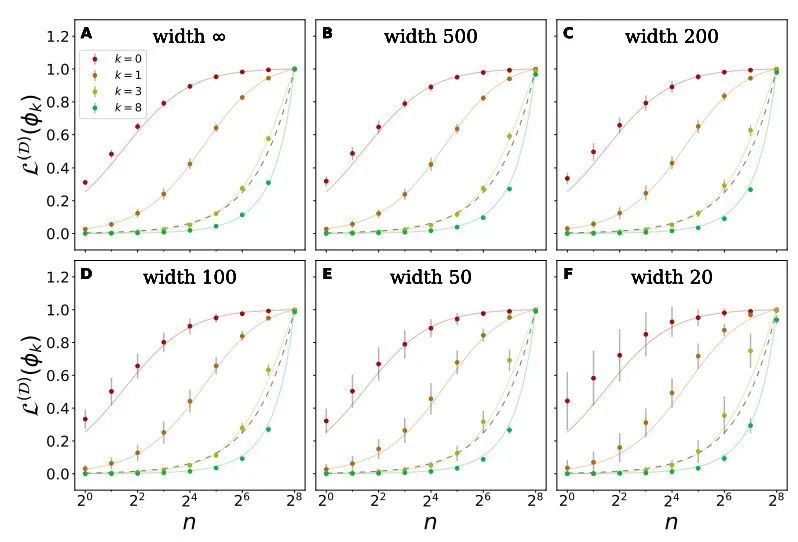
图 10:即使是对于宽度非常窄的网络,本文理论上对可学习性的预测仍然十分准确。
上图显式了 8d 超立方体上的四个特征模式的可学习性和训练集大小的关系,作者使用了一个包含 4 个隐藏层的网络进行学习,其网络宽度可变,激活函数为 ReLU。所有图表中的理论曲线都相同,虚线表示了朴素的、泛化性能极差的模型的可学习性。(A)严格的 NTK 回归下的可学习性(B-F)有限宽度网络的可学习性。随着宽度的减小,平均的可学习性微弱增大, 1σ误差增大。尽管如此,即使在宽度仅仅为 20 时,平均学习率也与理论预测值十分契合。
7
质疑
在reddit上,有人指出,这种量化计算的前提是要学习的函数f^是已知的,“但如何应用于学习函数完全未知的情况呢?”
对此,一作回应道:没错,我们的理论假设知道完整的目标学习函数 f^,而在实践中我们只能看到一个训练集。
“但从折中的角度来使用该理论也是可行的。假设我们知道目标学习函数属于少数可能函数之一。 该理论原则上包含足够的信息来优化内核,因此它在所有可能函数上都具有很高的平均性能。 当然,目标学习函数永远不会只是少数几个离散选项中的一个。但是如果拥有一些关于目标学习函数的先验——例如,自然图像可能服从某些统计。另外,或许也可以从数据-数据内核矩阵中获得足够的信息来使用该理论,我们以后可能会探索这个方向!”
8
结语
在本文中,作者提出了一种神经网络泛化的第一性原理,该理论能有效、准确地预测许多泛化性能指标。这一理论为神经网络的归纳偏置提供了新的视角,并为理解它们的学习行为提供了一个总体框架,为许多其他深度学习之谜的原理研究打开一扇崭新的大门。
参考链接:
https://www.reddit.com/r/MachineLearning/comments/qfy76l/r_neural_tangent_kernel_eigenvalues_accurately/
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

)








![[AH2017/HNOI2017] 大佬](http://pic.xiahunao.cn/[AH2017/HNOI2017] 大佬)









