文 | 花小花Posy
小伙伴们,好久不见呀,小花又回来了!
最近关注对比学习,所以ACL21的论文列表出来后,小花就搜罗了一波,好奇NLPers们都用对比学习干了什么?都是怎么用的呀?效果怎样呀?
接收列表中有21篇论文题目包含了关键词“contrastive”。下图是题目的词云,其中最显著的是使用对比学习去学习表示或者帮助语义理解,还有机翻、摘要、关系抽取。

小花选择了10篇有意思的论文跟大家分享,方向包括句子表示[1-3],自然语言理解[4-6], 生成式摘要[7],意图检测[8],多模态理解[9], 机器翻译[10]。当然还有其它的,比如用于事件抽取[12]、QA[13]等等,大家感兴趣可以自行补充!
为了大家快速get到跟对比学习最相关的部分,主要涉及论文中哪里用了对比,对比的对象是谁。
对比学习最重要的原料就是正例和负例的对比,以及在不同的应用场景下应该如何构造合理的正例和负例,如何设计对比损失函数。正负例的构造,可以分为利用显式的数据增强方式构造正负例[3-5,8-10],或者通过在语义空间/模型层面采样/生成正负例[1-2,6]。从对比损失函数的使用上来讲,可以分为与原始的MLM损失加和一起进行joint训练[1,5,10],或者进行pipeline训练[7-8]。
下面有请今天的主角们登场,大家开心食用!

从BERT中提取出句子向量的easy模式,想必大家都超熟了,使用[CLS]的表示或者使用不同的pooling操作。但这就够了嘛?当然不够!
从预训练语言模型中提取出句子表示的最优方法是什么,仍是研究者们在不断探索的问题。除了之前推送过的强者SimCSE以外,下面前三篇的主题都是如何利用对比学习去学习到更好的句子/文本片段表示。
[1] 自我引导的对比学习(一个BERT不够,那就两个)
Self-Guided Contrastive Learning for BERT Sentence Representations
https://arxiv.org/pdf/2106.07345.pdf
来自首尔大学,讨论的问题是如何在不引入外部资源或者显示的数据增强的情况下,利用BERT自身的信息去进行对比,从而获得更高质量的句子表示?
文中对比的是:BERT的中间层表示和最后的CLS的表示。模型包含两个BERT,一个BERT的参数是固定的,用于计算中间层的表示,其计算分两步:(1) 使用MAX-pooling获取每一层的句子向量表示 (2)使用均匀采样的方式从N层中采样一个表示;另一个BERT是要fine-tune的,用于计算句子CLS的表示。同一个句子的通过两个BERT获得两个表示,从而形成正例,负例则是另一个句子的中间层的表示或者最后的CLS的表示。
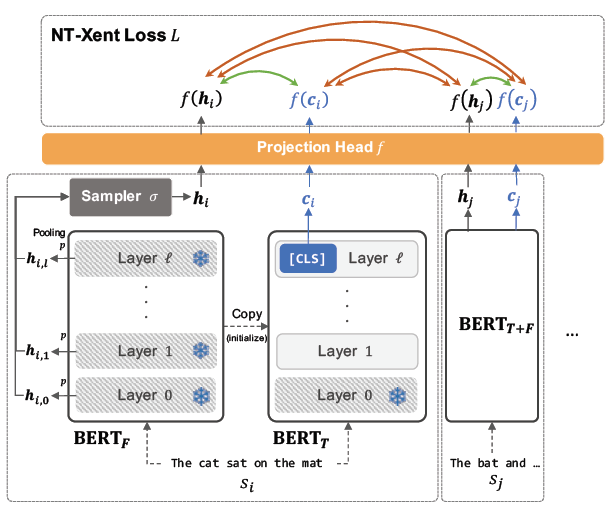
文中还对比了不同负例组合的方式,最后发现只保留CLS的表示和隐藏层的表示之间的对比,忽略CLS和CLS以及中间层和中间层之间的对比是最优的,即保留(1)(3)。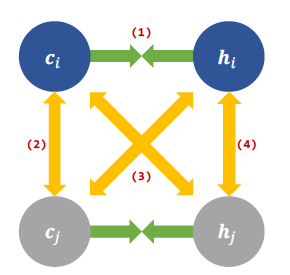
这篇论文没有选择直接从底层数据增强角度出发,是稍微偏模型方法的改进的,侧重挖掘模型内部的信息。主实验是在STS和SentEval任务上测试的,从结果来看的话,仍然是SimCSE要好很多,而且SimCSE操作起来是更简单的。不过本文也是提供了一个不一样的思路。
[2] 花式数据增强
ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
https://arxiv.org/pdf/2105.11741.pdf
来自北邮的工作,也是研究如何在无监督的模式下,学习更好的句子表示。该工作主要对比了使用4种不同的数据增强方式进行对比对句子表示的作用。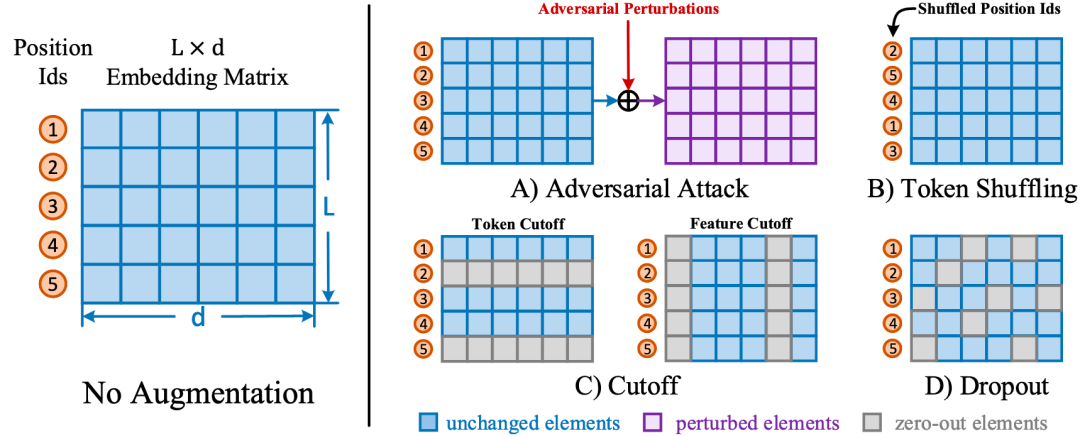
模型是在STS任务上进行评估的。和SimCSE一样也用了NLI做监督,整体性能比SimCSE低1-2个点。
[3] 无监督文本表示
DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations
https://arxiv.org/pdf/2006.03659.pdf
DeCLUTR来自多伦多大学,是NLP领域使用对比学习中较早的一篇,去年6月份就放到arxiv上面了。
文章研究的问题同样是:如何利对比学习从大量无标注数据学习更好的通用句子表示?文中的对比体现在两个方面:
对比来自不同文档的文本片段(span)的语义。如果两个文本片段(span)来自同一个文档,那么他们的语义表示的距离应该相对较近,否则距离远;
对比来自同一文档的文本span。当两个文本片段都来自同一个文档,如果他们在文档中的位置距离比较近,他们的语义表示距离近,否则远。
在采样正例的时候有些讲究。具体来讲是先从一个文档中采样N(>=1)个原始文本片段 (锚点span),然后从每个锚点span周围采样,作为正例 span。采样规则是正例span可以与锚点span交叠、相邻、从属。负例是从一个batch中随机采样得到的。对比学习的损失函数是InfoNCE。模型整体的损失函数是InfoNCE和MLM的加和。
实验是在SenEval benchmark(28个数据集)上进行测试的,包含有/半监督任务和无监督任务。有/半监督任务的baseline有InferSent,Universal Sentence Encoder和Sentence Transformers;无监督任务的baseline有QuickThoughts。最显著的实验结果是DeCLUTR在大部分的数据集上取得了SOTA,并且在无监督任务上取得了和有监督任务相当的结果。
接下来两篇文章是关于如何利用对比学习提升自然语言理解任务的性能。
[4] 论负例对对比学习的重要性
CLINE: Contrastive Learning with Semantic Negative Examples for Natural Language Understanding
https://arxiv.org/pdf/2107.00440.pdf
来自清华大学,文章探讨的是如何利用对比学习提高模型的鲁棒性。在初步实验中发现用探针对句子语义进行轻微扰动,模型就会预测错误。之前的对抗训练确实能够从扰动的样本中学习,但是主要侧重于语义相似的扰动,忽略了语义不同或者相反的扰动。这样的语义改变无法被对抗学习无法检测到。本文提出CLINE,使用无监督的方法构造负样本。通过同时利用语义相似和相反的样例和原始样例进行对比,模型可以侦测到扰动导致的语义的改变。
正负例的构造:
正例是将句子中的词(名词、动词、形容词)替换为其同义词. 负例是将句子中的词替换为其反义词或者随机选择的词。
文中的损失函数由三部分构成:掩码语言模型的MLM损失 + 检测当前词是否是被替换的词 的损失RTD + InfoNCE对比正例和负例。有个小细节不太一样的是对比InfoNCE中并没有引入温度参数τ。
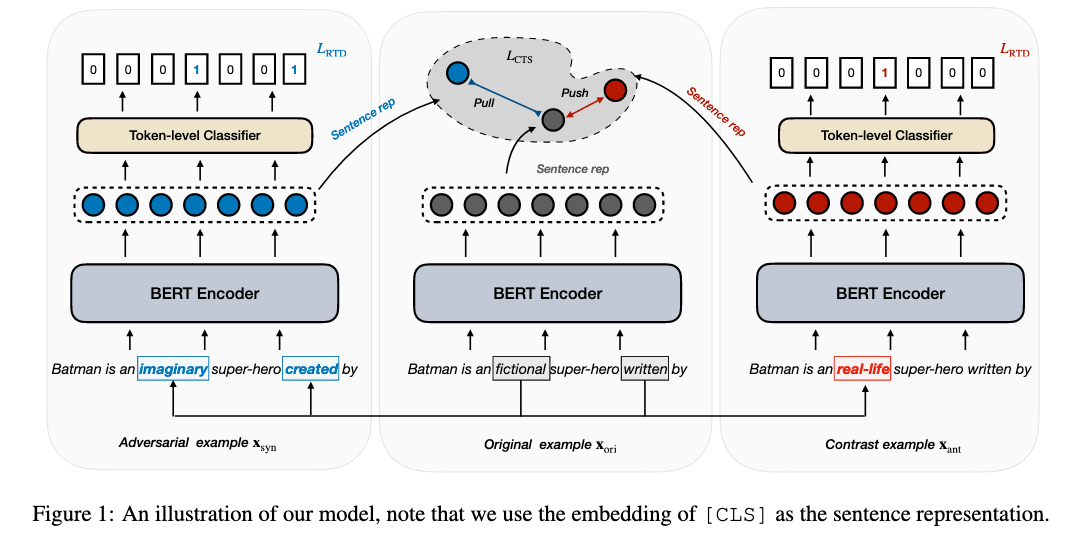 实验是在NLU任务上进行的,包括NLI(SNLI, PERSPECTRUM,) 情感分析(IMDB,MB) 阅读理解 (BoolQ), 新闻分类(AG)。实验结果表明使用CLINE训练的模型可以同时在对抗测试集和对比测试集上提升性能。
实验是在NLU任务上进行的,包括NLI(SNLI, PERSPECTRUM,) 情感分析(IMDB,MB) 阅读理解 (BoolQ), 新闻分类(AG)。实验结果表明使用CLINE训练的模型可以同时在对抗测试集和对比测试集上提升性能。
[5] 对比实例学习+远距离监督关系抽取
CIL: Contrastive Instance Learning Framework for Distantly Supervised Relation Extraction
https://arxiv.org/pdf/2106.10855.pdf
来自阿里巴巴-浙江大学前沿技术联合研究中心,研究如何利用对比学习提高远距离监督的关系抽取任务的性能。
从对比角度讲,正例是同一关系下的实例对,负例是不同关系的实例对。文中的重点是在有噪声的情况下,如何构造正负例。CIL的baseline是多实例对比学习,是将多个属于同一关系的实例放在一个bag中,一起训练得到一个关系的表示。每个实例都被假设是表达了一个实体对之间的关系。
正例:直觉上讲,对于一个实例的正例只要从同一个bag中随机sample一个就好,或者使用bag的整体表示。但因为是远距离监督,无法保证任意两个实例之间都一定表达了同一种关系,同样也无法保证样例和bag的整体表示一定关系相同。如果这样强行构造正负例的话,必然会引入噪声。文中采用的一种方式是,对于插入/替换掉中不重要的词语(还是数据增强)。
负例:同样因为是远距离监督,不能随便从一个别的bag中采样一个实例作为的负例,那样噪声会比较大。因此文中采用了使用整个别的bag的表示作为负例,能相对更好地降噪。
模型的损失函数是InfoNCE对比损失和MLM损失的加权和。CIL在NYT10,GDS和KBP三个数据集上取得较大提升。
[6] Post-training中使用对比学习
Bi-Granularity Contrastive Learning for Post-Training in Few-Shot Scene
https://arxiv.org/pdf/2106.02327
来自中山大学,本文主要针对样本量稀少的场景,如何使用对比学习先在无标注数据集进行post-training, 然后再在有标注数据集上fine-tuning。
对比方法:互补的mask方法,将一个输入进行多次mask,第一次的mask的比例是, 第二次mask的时候只针对第一次mask中没被选择的token以的比例进行mask,所以两个句子被mask的部分是互补的,第三次以此类推。 对比是在多个被mask的输入上进行的。这样做的好处是既可以避免太小时,两个句子太相似导致对比损失迅速降到0,也可以避免太大而导致模型无法恢复mask的内容。(和SimCSE的直接两次dropout相比复杂了点,但有异曲同工之妙)。
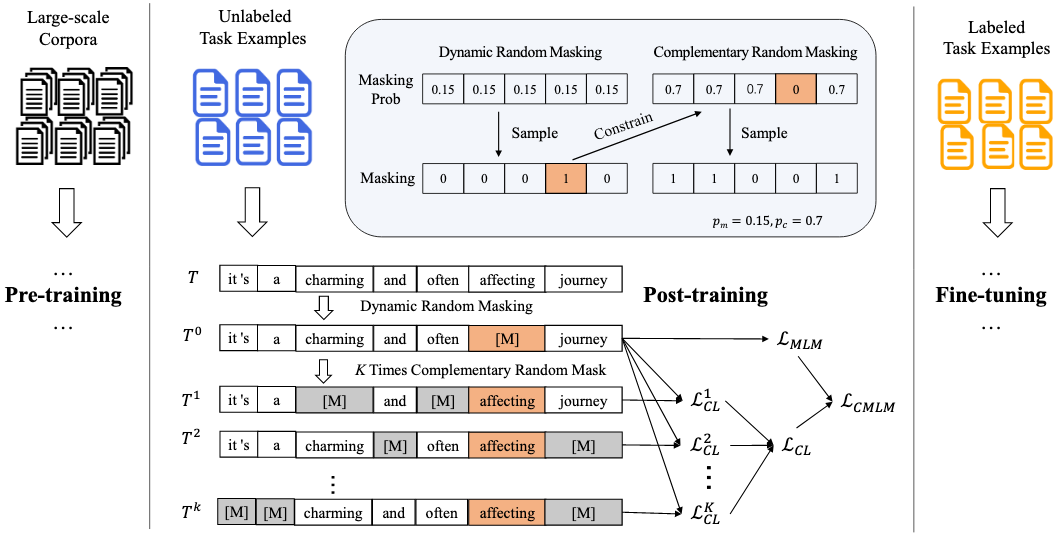
实验是在少样本GLUE上进行的,只有20个样例的时候提升不是很明显,样本100和1000的时候相比之前SOTA有轻微提升。
[7] 对比学习+生成式摘要
SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization
https://arxiv.org/pdf/2106.01890
来自CMU,蛮有意思的一篇文章。核心点是利用对比学习将文本生成看作是reference-free的评价问题。
生成式摘要典型的框架是Seq2Seq,之前也有工作将对比学习损失作为MLE损失的增强。不同的是,这篇文章将两个损失用在了不同的阶段。文中将摘要生成分解为两个过程:生成 和 评分+选择。从而提出了two-stage的框架,stage1是Seq2Seq模型,仍然利用MLE损失生成候选摘要,stage2引入对比学习,利用参数化的评估模型对stage1中生成的候选进行排序。两个阶段是分开优化的,都是有监督的。这里对比的是生成的候选摘要和原始文档。引入了一个raking loss, 希望预测值和真实值接近;希望每个候选值之间有差距。
[8] 对比学习 + 意图检测
Modeling Discriminative Representations for Out-of-Domain Detection with Supervised Contrastive Learning
https://arxiv.org/pdf/2105.14289.pdf
来自北邮模式识别实验室,研究的问题是:在Task-oriented的对话系统中,如何检测用户query中的跟task/domain不相关的问题。比如你问一个银行的app语音助手,我有多少余额,它检测该问题为in-domain (IND) 的问题,并给出回答;但你如果问它,我们一起健身的小伙伴都怎样呀?我们不希望模型“不懂装懂”,而是希望它可以检测该问题为out-of-domain (OOD),并引导用户提出domain相关的问题。下图是来自数据集[11]中的一个样例。

OOD的检测方法分为有监督和无监督的两种。有监督的方式在训练时已知哪些数据OOD的,所以在训练时可以将OOD的数据当成一个类型;无监督方式训练的时候只有标注的IND数据。常用的方法是先利用IND数据学习类别的特征 (分类器),然后使用检测算法计算IND样本和OOD样本的相似度。
本文的先验假设是:
一个OOD检测模型依赖于高质量IND类别表示模型。之前的IND分类器虽然在IND数据上表现好,应用到OOD时性能不高,原因是类别间的间隔很模糊。所以该工作的核心是利用对比学习减小类内距离,增大类间距离。更好的IND聚类促使更好的OOD分类。
本文主要针对的是无监督OOD进行训练,策略是先用有监督对比学习在IND数据上训练,然后用cross-entropy损失对分类器fine-tune,有监督对比学习的目标是拉近IND中属于拉近同一类别的意图,推远不同类别的意图。因此:
正例对来自同一个类别的数据 负例是不同类别的数据
文中也使用了对抗攻击生成hard正例来做数据增强。文中的实验是比较全面的,对比了不同scale的数据集,不同的encoder,不同的OOD检测算法。
小花觉得这篇有意思主要是因为OOD检测的思路,不仅可以用在意图检测领域,还可以直接扩展到别的领域,比如用于关系抽取中检测新的关系。
接下来的两篇论文都利用了任务本身的属性将对比扩展到了多对多上,同时包含单个模态/语言的对比和跨模态/跨语言的对比。
[9] 对比学习 + 多模态学习
UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
https://arxiv.org/pdf/2012.15409.pdf
来自百度的UNIMO,利用跨模态的对比学习将文本和视觉信息对齐到一个统一的语义空间。之前也有统一训练文本和视觉的模型,比如ViLBERT, VisualBERT,但是它们只能利用有限的文本-图像对齐的数据,且无法有效的适应到单模态的场景。本文要解决的是问题是:如何通过对比学习同时利用单模态和多模态的数据来实现更好的图像-文本对齐?
对比部分核心的点是,通过花式重写原始的caption来生成正例和负例。对于一对对齐的图像-文本数据,通过文本重写的方式构造多模态的正负例样本,同时通过文本/图像检索的方式构造单模态的正例样本。 正负例样本又分为多个level,包括句子级别、短语级别、词级别。比如句子级别的多模态的正例是通过back-translation生成的,负例是利用当前图片的字幕从其它图片的字幕中找相似的得到的。
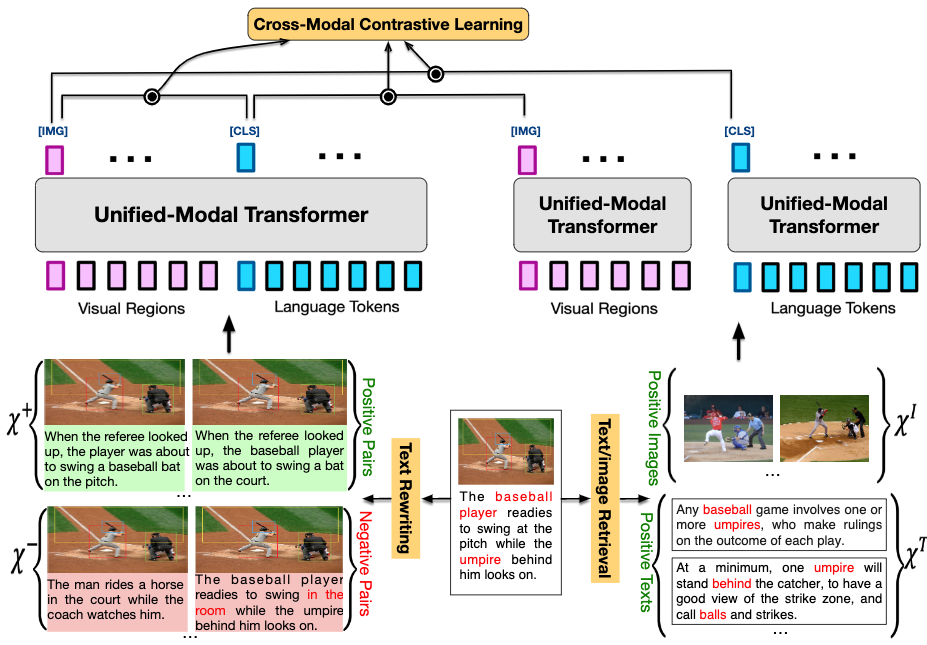
UNIMO的优势在于可以同时利用单模态数据和多模态对齐数据进行训练,测试时在单模态的理解和生成任务上都表现很好。
[10] 对比学习 + 机器翻译
Contrastive Learning for Many-to-many Multilingual Neural Machine Translation
https://arxiv.org/pdf/2105.09501.pdf
看到这篇文章的时候,脑子里想的是,“一生二,二生三,三生万物”。在对比学习中,只要存在一个对象,我们就可以给它找到或者造一个对比对象,让它们去自我对比,自己进化;当多个对象成立的时候,我们都不需要造了,只需要利用就好。
多对多机翻就是典型的例子。这篇文章来自字节跳动AI Lab,研究的问题是:如何学习更好的通用跨语言表示,来获得更好的多语言翻译效果?尤其是当源语言或者目标语言不是English的时候。
本文的先验假设是,如果两句话说的是同一个意思,即使它们使用的语言不相同,那么它们在语义空间中的表示也应该接近。所以本文的训练目标是:减少相似句子表示之间的距离,增大不相关句子表示之间的距离。文中使用了fancy的数据增强,同时使用单语和多语的数据进行对比。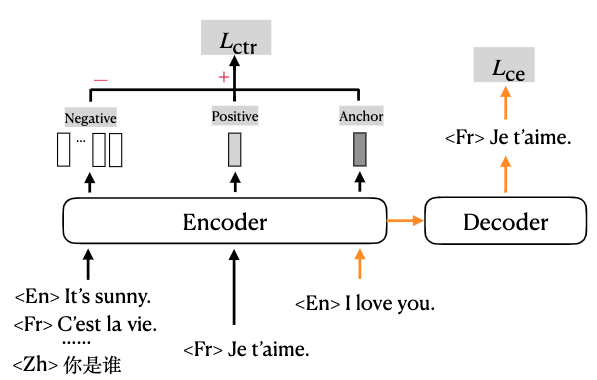
方法简单,效果好,实验solid,值得细品。
插播一个有趣的游戏
你玩过词联想的游戏嘛?什么?还没有?
来来来,奉上链接!
https://smallworldofwords.org/zh
萌屋作者:花小花Posy
目前在墨尔本大学NLP组读Ph.D.,主要感兴趣方向包括常识问答,知识图谱,低资源知识迁移。期待有生之年可见证机器真正理解常识的时刻! 知乎ID:花小花Posy
作品推荐:
1.丹琦女神新作:对比学习,简单到只需要Dropout两下
2.对比学习有多火?文本聚类都被刷爆了…
3.Facebook提出生成式实体链接、文档检索,大幅刷新SOTA
4.我拿乐谱训了个语言模型!
5.一句话超短摘要,速览752篇EMNLP论文
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!

[1] DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations https://arxiv.org/pdf/2006.03659.pdf
[2] Self-Guided Contrastive Learning for BERT Sentence Representations https://arxiv.org/pdf/2106.07345.pdf
[3] ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer https://arxiv.org/pdf/2105.11741.pdf
[4] CLINE: Contrastive Learning with Semantic Negative Examples for Natural Language Understanding https://arxiv.org/pdf/2107.00440.pdf
[5] CIL: Contrastive Instance Learning Framework for Distantly Supervised Relation Extraction https://arxiv.org/pdf/2106.10855.pdf
[6] Bi-Granularity Contrastive Learning for Post-Training in Few-Shot Scene https://arxiv.org/pdf/2106.02327
[7] SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization https://arxiv.org/pdf/2106.01890
[8] Modeling Discriminative Representations for Out-of-Domain Detection with Supervised Contrastive Learning https://arxiv.org/pdf/2105.14289
[9] UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning https://arxiv.org/pdf/2012.15409.pdf
[10] Contrastive Learning for Many-to-many Multilingual Neural Machine Translation https://arxiv.org/pdf/2105.09501.pdf
[11] An Evaluation Dataset for Intent Classificationand Out-of-Scope Prediction https://aclanthology.org/D19-1131.pdf
[12] CLEVE: Contrastive Pre-training for Event Extraction https://arxiv.org/pdf/2105.14485.pdf
[13] KACE: Generating Knowledge Aware Contrastive Explanations for Natural Language Inference (not public yet)
[14] xMoCo: Cross Momentum Contrastive Learning for Open-Domain Question Answering (not public yet)