文章目录
- 作业1:快乐房子 - 人脸识别
- 0. 朴素人脸验证
- 1. 编码人脸图片
- 1.1 使用卷积网络编码
- 1.2 Triplet 损失
- 2. 加载训练过的模型
- 3. 使用模型
- 3.1 人脸验证
- 3.2 人脸识别
- 作业2:神经风格转换
- 1. 问题背景
- 2. 迁移学习
- 3. 神经风格转换
- 3.1 计算内容损失
- 3.2 计算风格损失
- 3.2.1 风格矩阵
- 3.2.2 风格损失
- 3.2.3 风格权重
- 3.3 总的损失
- 4. 优化求解
- 5. 用自己的照片测试
测试题:参考博文
笔记:W4.特殊应用:人脸识别和神经风格转换
作业1:快乐房子 - 人脸识别
背景:04 W2 作业:Keras教程+ResNets残差网络 里的快乐的房子问题
作业里很多想法来源于 FaceNet(https://arxiv.org/pdf/1503.03832.pdf)
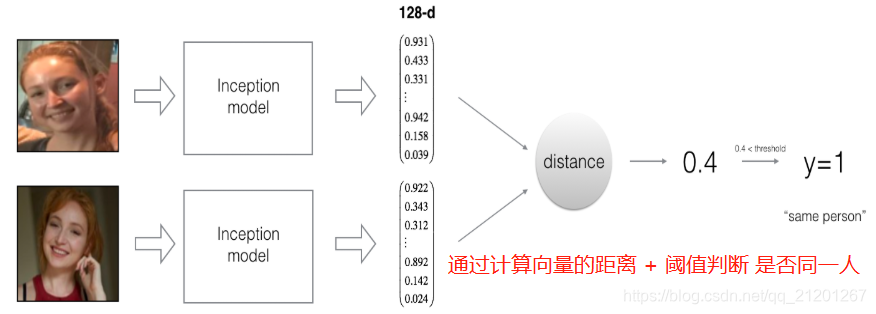
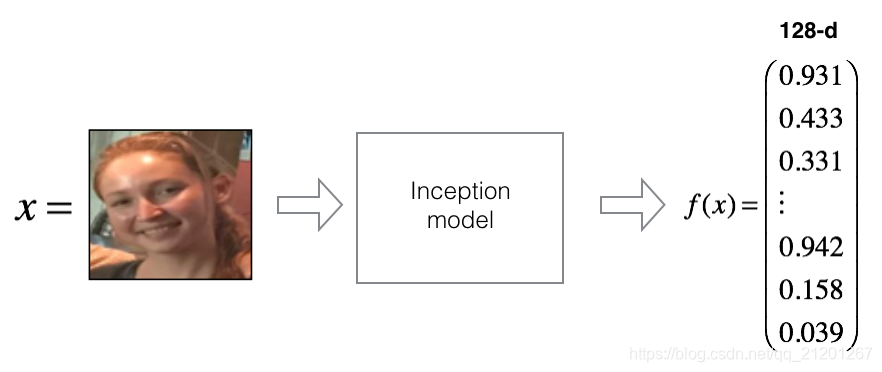
FaceNet 学习了神经网络,可以把一个脸部图像编码成一个128个数的向量,通过比较两个这样的向量,判断这两个图片是不是同一个人
- 导入一些包
from keras.models import Sequential
from keras.layers import Conv2D, ZeroPadding2D, Activation, Input, concatenate
from keras.models import Model
from keras.layers.normalization import BatchNormalization
from keras.layers.pooling import MaxPooling2D, AveragePooling2D
from keras.layers.merge import Concatenate
from keras.layers.core import Lambda, Flatten, Dense
from keras.initializers import glorot_uniform
from keras.engine.topology import Layer
from keras import backend as K
K.set_image_data_format('channels_first')
# 数据格式,通道数在前 (𝑚,𝑛𝐶,𝑛𝐻,𝑛𝑊)
import cv2
import os
import numpy as np
from numpy import genfromtxt
import pandas as pd
import tensorflow as tf
from fr_utils import *
from inception_blocks_v2 import *%matplotlib inline
%load_ext autoreload
%autoreload 2np.set_printoptions(threshold=np.inf)
0. 朴素人脸验证
给定两张人脸照片,最简单的方法:逐个比较每个像素,如果距离小于某个阈值,则判断是同一个人

当然,该算法的性能非常差,因为像素值会因光线变化、人脸方位变化、甚至头部位置的微小变化等而发生显著变化
可以学习编码 f(img)f(img)f(img),对图片编码进行比较,更准确地判断两张图片是否属于同一个人
1. 编码人脸图片
1.1 使用卷积网络编码
练习采用预训练好的权重,网络结构来源于 Inception 网络模型
Inception网络模型 参考博文
一些关键点:
- 网络使用 96x96 的3通道图片,维度(𝑚,𝑛𝐶,𝑛𝐻,𝑛𝑊)= (𝑚,3,96,96)
- 网络输出图片的编码:矩阵,他的维度(𝑚,128)
定义模型:
FRmodel = faceRecoModel(input_shape=(3, 96, 96))
1.2 Triplet 损失
三元组损失函数 试图将同一个人的两个图像(Anchor & Positive)的编码“推”得更近,同时将不同人物(Anchor & Negative)的两个图像的编码“拉”得更远
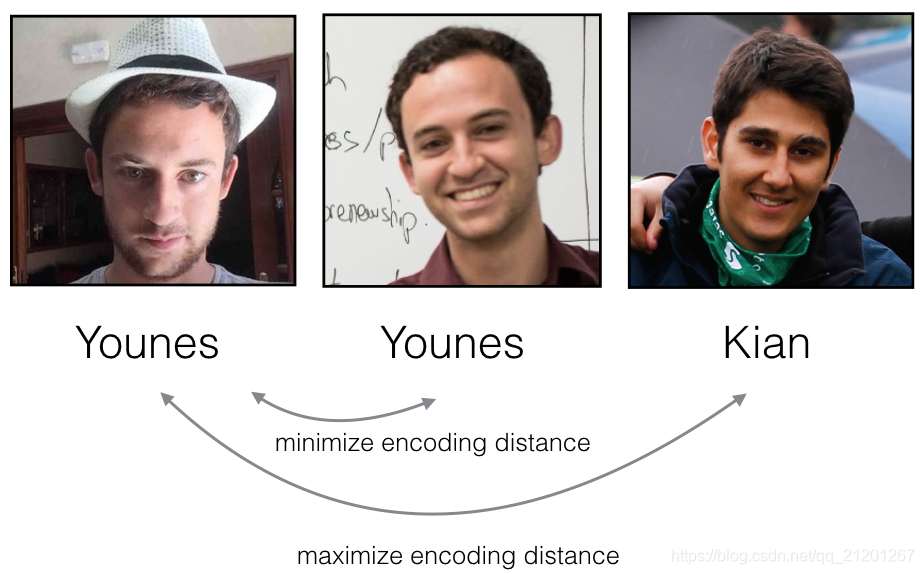
J=∑i=1m[∣∣f(A(i))−f(P(i))∣∣22⏟(1)−∣∣f(A(i))−f(N(i))∣∣22⏟(2)+α]+\mathcal{J} = \sum^{m}_{i=1} \large[ \small \underbrace{\mid \mid f(A^{(i)}) - f(P^{(i)}) \mid \mid_2^2}_\text{(1)} - \underbrace{\mid \mid f(A^{(i)}) - f(N^{(i)}) \mid \mid_2^2}_\text{(2)} + \alpha \large ] \small_+ J=i=1∑m[(1)∣∣f(A(i))−f(P(i))∣∣22−(2)∣∣f(A(i))−f(N(i))∣∣22+α]+
(A(i),P(i),N(i))(A^{(i)}, P^{(i)}, N^{(i)})(A(i),P(i),N(i)) 表示第 i 个训练样本,"[z]+[z]_+[z]+" 表示 max(z,0)\max(z,0)max(z,0),α\alphaα 是间隔,常取0.2
可以使用函数:tf.reduce_sum(), tf.square(), tf.subtract(), tf.add(), tf.maximum()
# GRADED FUNCTION: triplet_lossdef triplet_loss(y_true, y_pred, alpha = 0.2):"""Implementation of the triplet loss as defined by formula (3)Arguments:y_true -- true labels, required when you define a loss in Keras, you don't need it in this function.y_pred -- python list containing three objects:anchor -- the encodings for the anchor images, of shape (None, 128)positive -- the encodings for the positive images, of shape (None, 128)negative -- the encodings for the negative images, of shape (None, 128)Returns:loss -- real number, value of the loss"""anchor, positive, negative = y_pred[0], y_pred[1], y_pred[2]### START CODE HERE ### (≈ 4 lines)# Step 1: Compute the (encoding) distance between the anchor and the positive, # you will need to sum over axis=-1pos_dist = tf.reduce_sum(tf.square(tf.subtract(anchor, positive)),axis=-1)# Step 2: Compute the (encoding) distance between the anchor and the negative, # you will need to sum over axis=-1neg_dist = tf.reduce_sum(tf.square(tf.subtract(anchor, negative)),axis=-1)# Step 3: subtract the two previous distances and add alpha.basic_loss = tf.subtract(pos_dist, neg_dist)+alpha# Step 4: Take the maximum of basic_loss and 0.0. Sum over the training examples.loss = tf.reduce_sum(tf.maximum(basic_loss, 0))### END CODE HERE ###return loss
2. 加载训练过的模型
FaceNet 已经使用 Triplet 损失训练过了,我们直接加载训练好的模型
FRmodel.compile(optimizer = 'adam', loss = triplet_loss, metrics = ['accuracy'])
load_weights_from_FaceNet(FRmodel)
3. 使用模型
你不想让所有的人都可以进入快乐房子,只允许在名单里的人才能进入,你需要刷卡,以便系统读取你的人名身份
3.1 人脸验证
对每个允许进入的人创建编码向量的数据库,使用img_to_encoding(image_path, model)函数,输入图片,运行前向传播
- 创建数据库(字典),人名:编码向量
database = {}
database["danielle"] = img_to_encoding("images/danielle.png", FRmodel)
database["younes"] = img_to_encoding("images/younes.jpg", FRmodel)
database["tian"] = img_to_encoding("images/tian.jpg", FRmodel)
database["andrew"] = img_to_encoding("images/andrew.jpg", FRmodel)
database["kian"] = img_to_encoding("images/kian.jpg", FRmodel)
database["dan"] = img_to_encoding("images/dan.jpg", FRmodel)
database["sebastiano"] = img_to_encoding("images/sebastiano.jpg", FRmodel)
database["bertrand"] = img_to_encoding("images/bertrand.jpg", FRmodel)
database["kevin"] = img_to_encoding("images/kevin.jpg", FRmodel)
database["felix"] = img_to_encoding("images/felix.jpg", FRmodel)
database["benoit"] = img_to_encoding("images/benoit.jpg", FRmodel)
database["arnaud"] = img_to_encoding("images/arnaud.jpg", FRmodel)
- 验证,计算图片编码,与数据库编码的距离,如果 < 0.7 则开门
# GRADED FUNCTION: verifydef verify(image_path, identity, database, model):"""Function that verifies if the person on the "image_path" image is "identity".Arguments:image_path -- path to an imageidentity -- string, name of the person you'd like to verify the identity. Has to be a resident of the Happy house.database -- python dictionary mapping names of allowed people's names (strings) to their encodings (vectors).model -- your Inception model instance in KerasReturns:dist -- distance between the image_path and the image of "identity" in the database.door_open -- True, if the door should open. False otherwise."""### START CODE HERE #### Step 1: Compute the encoding for the image. Use img_to_encoding() see example above. (≈ 1 line)encoding = img_to_encoding(image_path, model)# Step 2: Compute distance with identity's image (≈ 1 line)dist = np.linalg.norm(database[identity]-encoding)# Step 3: Open the door if dist < 0.7, else don't open (≈ 3 lines)if dist < 0.7:print("It's " + str(identity) + ", welcome home!")door_open = Trueelse:print("It's not " + str(identity) + ", please go away")door_open = False### END CODE HERE ###return dist, door_open

verify("images/camera_0.jpg", "younes", database, FRmodel)
输出:
It's younes, welcome home!
(0.67100716, True)

verify("images/camera_2.jpg", "kian", database, FRmodel)
输出:
It's not kian, please go away
(0.85800135, False)
再试下詹姆斯的头像试试:

database["james"] = img_to_encoding("images/james.png", FRmodel)
verify("images/james_no.png", "james", database, FRmodel)
It's not james, please go away
(0.84896624, False) # 回答正确
verify("images/james_yes.png", "james", database, FRmodel)
It's james, welcome home!
(0.57764035, True) # 回答正确
verify("images/james_yes1.png", "james", database, FRmodel)
It's not james, please go away
(0.87970865, False) # 回答错误
3.2 人脸识别
但是你的卡丢了,就不能进门了,所以需要改造为识别系统,授权人员只需要走到摄像头跟前,门就会为他打开(我们不再需要刷卡)
# GRADED FUNCTION: who_is_itdef who_is_it(image_path, database, model):"""Implements face recognition for the happy house by finding who is the person on the image_path image.Arguments:image_path -- path to an imagedatabase -- database containing image encodings along with the name of the person on the imagemodel -- your Inception model instance in KerasReturns:min_dist -- the minimum distance between image_path encoding and the encodings from the databaseidentity -- string, the name prediction for the person on image_path"""### START CODE HERE ### ## Step 1: Compute the target "encoding" for the image. Use img_to_encoding() see example above. ## (≈ 1 line)encoding = img_to_encoding(image_path, model)## Step 2: Find the closest encoding ### Initialize "min_dist" to a large value, say 100 (≈1 line)min_dist = np.inf# Loop over the database dictionary's names and encodings.for (name, db_enc) in database.items():# Compute L2 distance between the target "encoding" and the current "emb" from the database. (≈ 1 line)dist = np.linalg.norm(encoding - db_enc)# If this distance is less than the min_dist, then set min_dist to dist, and identity to name. (≈ 3 lines)if dist < min_dist:min_dist = distidentity = name### END CODE HERE ###if min_dist > 0.7:print("Not in the database.")else:print ("it's " + str(identity) + ", the distance is " + str(min_dist))return min_dist, identity
who_is_it("images/camera_0.jpg", database, FRmodel)
it's younes, the distance is 0.67100716
(0.67100716, 'younes')
who_is_it("images/james_yes.png", database, FRmodel)
it's james, the distance is 0.57764035
(0.57764035, 'james')
who_is_it("images/james_yes1.png", database, FRmodel)
it's andrew, the distance is 0.66093665
(0.66093665, 'andrew')
what ??? 詹姆斯 很像 NG老师?哈哈

您现在已经了解了最先进的人脸识别系统是如何工作的。
有一些方法可以进一步改进算法:
-
把每个人的更多照片(在不同的光照条件下,在不同的日子,等等)放入数据库。然后给出一个新的图像,将新的面孔与该人的多张照片进行比较。这将提高准确性。
-
裁剪图像,使其只包含脸部,而不包含脸部周围的
“边界”区域。去除了人脸周围一些不相关的像素点,使算法更加健壮。
作业2:神经风格转换
大多数算法都会优化成本函数以获得一组参数值。神经风格转换中,你将优化一个成本函数来获得像素值!
导入一些包
import os
import sys
import scipy.io
import scipy.misc
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
from PIL import Image
from nst_utils import *
import numpy as np
import tensorflow as tf%matplotlib inline
1. 问题背景
在本例中,您将生成巴黎卢浮宫博物馆的图像(内容图像 C),与印象派运动领袖克劳德·莫内(Claude Monet)的绘画混合(样式图像 S)

2. 迁移学习
Neural Style Transfer (NST) 使用先前训练过的卷积网络,并在此基础上构建。使用一个在不同任务上训练的网络并将其应用于新任务的想法称为迁移学习。
遵循NST原始论文(https://arxiv.org/abs/1508.06576),我们将使用VGG网络。使用VGG-19,VGG网络的19层版本。这个模型已经在非常大的 ImageNet数据库上进行了训练,因此学会了识别各种低级特征(在浅层)和高级特征(在深层)。
- 加载模型
model = load_vgg_model("pretrained-model/imagenet-vgg-verydeep-19.mat")
print(model)
{'input': <tf.Variable 'Variable:0' shape=(1, 300, 400, 3) dtype=float32_ref>, 'conv1_1': <tf.Tensor 'Relu:0' shape=(1, 300, 400, 64) dtype=float32>, 'conv1_2': <tf.Tensor 'Relu_1:0' shape=(1, 300, 400, 64) dtype=float32>, 'avgpool1': <tf.Tensor 'AvgPool:0' shape=(1, 150, 200, 64) dtype=float32>, 'conv2_1': <tf.Tensor 'Relu_2:0' shape=(1, 150, 200, 128) dtype=float32>, 'conv2_2': <tf.Tensor 'Relu_3:0' shape=(1, 150, 200, 128) dtype=float32>, 'avgpool2': <tf.Tensor 'AvgPool_1:0' shape=(1, 75, 100, 128) dtype=float32>, 'conv3_1': <tf.Tensor 'Relu_4:0' shape=(1, 75, 100, 256) dtype=float32>, 'conv3_2': <tf.Tensor 'Relu_5:0' shape=(1, 75, 100, 256) dtype=float32>, 'conv3_3': <tf.Tensor 'Relu_6:0' shape=(1, 75, 100, 256) dtype=float32>, 'conv3_4': <tf.Tensor 'Relu_7:0' shape=(1, 75, 100, 256) dtype=float32>, 'avgpool3': <tf.Tensor 'AvgPool_2:0' shape=(1, 38, 50, 256) dtype=float32>, 'conv4_1': <tf.Tensor 'Relu_8:0' shape=(1, 38, 50, 512) dtype=float32>, 'conv4_2': <tf.Tensor 'Relu_9:0' shape=(1, 38, 50, 512) dtype=float32>, 'conv4_3': <tf.Tensor 'Relu_10:0' shape=(1, 38, 50, 512) dtype=float32>, 'conv4_4': <tf.Tensor 'Relu_11:0' shape=(1, 38, 50, 512) dtype=float32>, 'avgpool4': <tf.Tensor 'AvgPool_3:0' shape=(1, 19, 25, 512) dtype=float32>, 'conv5_1': <tf.Tensor 'Relu_12:0' shape=(1, 19, 25, 512) dtype=float32>, 'conv5_2': <tf.Tensor 'Relu_13:0' shape=(1, 19, 25, 512) dtype=float32>, 'conv5_3': <tf.Tensor 'Relu_14:0' shape=(1, 19, 25, 512) dtype=float32>, 'conv5_4': <tf.Tensor 'Relu_15:0' shape=(1, 19, 25, 512) dtype=float32>, 'avgpool5': <tf.Tensor 'AvgPool_4:0' shape=(1, 10, 13, 512) dtype=float32>}
模型存储在python字典中,其中每个变量名是键,对应的值是包含该变量值的张量。要通过这个网络运行图像,只需将图像喂给模型。在TensorFlow中,可以使用tf.assign函数:model["input"].assign(image)
要获取指定层的激活值可以使用:sess.run(model["conv4_2"])
3. 神经风格转换
3.1 计算内容损失
读取内容图片 C
import imageio
content_image = imageio.imread("images/louvre.jpg")
imshow(content_image)

ConvNet的早期(较浅)层倾向于检测较低层次的特征,如边缘和简单纹理
后面(较深)层则倾向于检测更高级的特征,如更复杂的纹理以及对象类。
我们希望“生成的”图像G与输入图像C具有相似的内容。实际上,如果选择网络中间的一个层(既不太浅也不太深),您将获得最令人满意的结果。(可以尝试使用不同的层,看看结果如何变化)
Jcontent(C,G)=14×nH×nW×nC∑all entries(a(C)−a(G))2J_{content}(C,G) = \frac{1}{4 \times n_H \times n_W \times n_C}\sum _{ \text{all entries}} (a^{(C)} - a^{(G)})^2Jcontent(C,G)=4×nH×nW×nC1all entries∑(a(C)−a(G))2
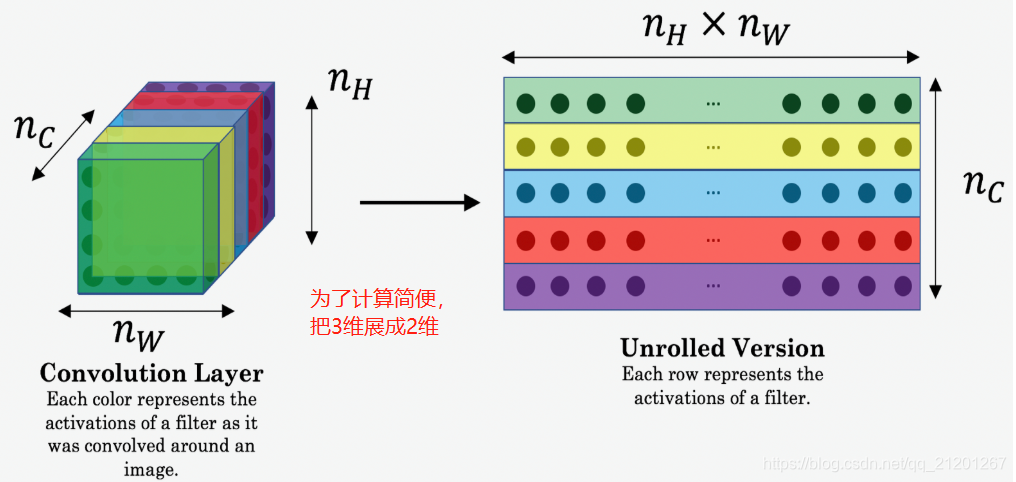
# GRADED FUNCTION: compute_content_costdef compute_content_cost(a_C, a_G):"""Computes the content costArguments:a_C -- tensor of dimension (1, n_H, n_W, n_C), hidden layer activations representing content of the image C a_G -- tensor of dimension (1, n_H, n_W, n_C), hidden layer activations representing content of the image GReturns: J_content -- scalar that you compute using equation 1 above."""### START CODE HERE #### Retrieve dimensions from a_G (≈1 line)m, n_H, n_W, n_C = a_G.get_shape().as_list()# Reshape a_C and a_G (≈2 lines)a_C_unrolled = tf.reshape(a_C, [-1, n_C])a_G_unrolled = tf.reshape(a_G, [-1, n_C])# compute the cost with tensorflow (≈1 line)J_content = tf.reduce_sum(tf.square(tf.subtract(a_C_unrolled, a_G_unrolled)))/(4*n_H*n_W*n_C)### END CODE HERE ###return J_content
3.2 计算风格损失
style_image = imageio.imread("images/monet_800600.jpg")
imshow(style_image)

3.2.1 风格矩阵
又叫 Gram 矩阵,其项是 Gij=viTvj=np.dot(vi,vj)G_{ij} = v_i^Tv_j = np.dot(v_i, v_j)Gij=viTvj=np.dot(vi,vj),GijG_{ij}Gij 比较 viv_ivi与 vjv_jvj 的相似程度:如果它们高度相似,期望它们有一个大的点积
在NST中,可以通过将“展开”过滤器矩阵与其转置相乘来计算风格矩阵:
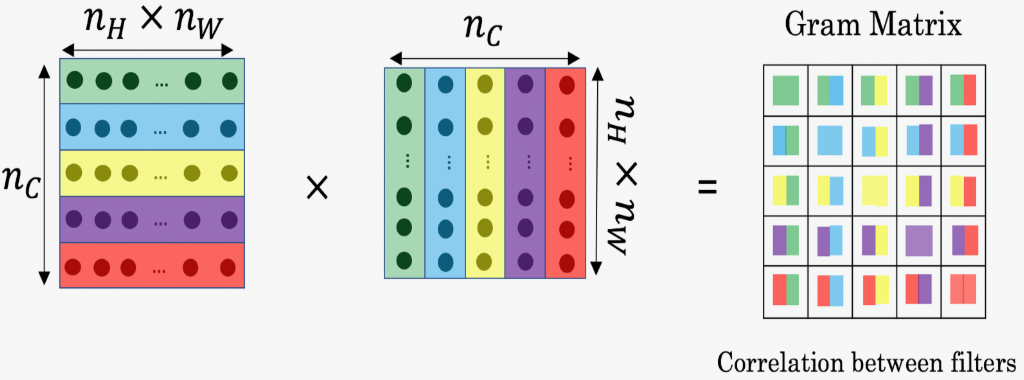
输出矩阵是 nc×ncn_c \times n_cnc×nc 的,ncn_cnc 是过滤器数量,GijG_{ij}Gij 测量了过滤器 i 和过滤器 j 的激活值有多少相似度
Gram 矩阵的一个重要部分是,对角线元素如 GiiG_{ii}Gii 表示过滤器 i 有多活跃。例如,假设过滤器 i 正在检测图像中的垂直纹理。然后,GiiG_{ii}Gii 衡量图像整体中垂直纹理的常见程度:如果 GiiG_{ii}Gii 很大,这意味着图像有很多垂直纹理。
通过捕捉不同类型的特征 GiiG_{ii}Gii,以及有多少不同的特征组合出现 GijG_{ij}Gij,样式矩阵 GGG 测量图像的样式
# GRADED FUNCTION: gram_matrixdef gram_matrix(A):"""Argument:A -- matrix of shape (n_C, n_H*n_W)Returns:GA -- Gram matrix of A, of shape (n_C, n_C)"""### START CODE HERE ### (≈1 line)GA = tf.matmul(A, tf.transpose(A))### END CODE HERE ###return GA
3.2.2 风格损失
Jstyle[l](S,G)=14×nC2×(nH×nW)2∑i=1nC∑j=1nC(Gij(S)−Gij(G))2J_{style}^{[l]}(S,G) = \frac{1}{4 \times {n_C}^2 \times (n_H \times n_W)^2} \sum _{i=1}^{n_C}\sum_{j=1}^{n_C}(G^{(S)}_{ij} - G^{(G)}_{ij})^2Jstyle[l](S,G)=4×nC2×(nH×nW)21i=1∑nCj=1∑nC(Gij(S)−Gij(G))2
# GRADED FUNCTION: compute_layer_style_costdef compute_layer_style_cost(a_S, a_G):"""Arguments:a_S -- tensor of dimension (1, n_H, n_W, n_C), hidden layer activations representing style of the image S a_G -- tensor of dimension (1, n_H, n_W, n_C), hidden layer activations representing style of the image GReturns: J_style_layer -- tensor representing a scalar value, style cost defined above by equation (2)"""### START CODE HERE #### Retrieve dimensions from a_G (≈1 line)m, n_H, n_W, n_C = a_G.get_shape().as_list()# Reshape the images to have them of shape (n_C, n_H*n_W) (≈2 lines)a_S = tf.reshape(a_S, [-1, n_C])a_G = tf.reshape(a_G, [-1, n_C])# Computing gram_matrices for both images S and G (≈2 lines)GS = gram_matrix(tf.transpose(a_S))GG = gram_matrix(tf.transpose(a_G))# Computing the loss (≈1 line)J_style_layer = tf.reduce_sum(tf.square(tf.subtract(GS, GG)))/(4*n_C**2*(n_H*n_W)**2)### END CODE HERE ###return J_style_layer
3.2.3 风格权重
给每一层的风格给定权重,可以更改,看看有什么效果变化
# 权重系数
STYLE_LAYERS = [('conv1_1', 0.2),('conv2_1', 0.2),('conv3_1', 0.2),('conv4_1', 0.2),('conv5_1', 0.2)]
Jstyle(S,G)=∑lλ[l]Jstyle[l](S,G)J_{style}(S,G) = \sum_{l} \lambda^{[l]} J^{[l]}_{style}(S,G)Jstyle(S,G)=l∑λ[l]Jstyle[l](S,G)
def compute_style_cost(model, STYLE_LAYERS):"""Computes the overall style cost from several chosen layersArguments:model -- our tensorflow modelSTYLE_LAYERS -- A python list containing:- the names of the layers we would like to extract style from- a coefficient for each of themReturns: J_style -- tensor representing a scalar value, style cost defined above by equation (2)"""# initialize the overall style costJ_style = 0for layer_name, coeff in STYLE_LAYERS:# Select the output tensor of the currently selected layerout = model[layer_name]# Set a_S to be the hidden layer activation from the layer we have selected, # by running the session on outa_S = sess.run(out)# Set a_G to be the hidden layer activation from same layer. Here, a_G references model[layer_name] # and isn't evaluated yet. Later in the code, we'll assign the image G as the model input, so that# when we run the session, this will be the activations drawn from the appropriate layer, with G as input.a_G = out# Compute style_cost for the current layerJ_style_layer = compute_layer_style_cost(a_S, a_G)# Add coeff * J_style_layer of this layer to overall style costJ_style += coeff * J_style_layerreturn J_style
注意:内循环 a_G 还没有评估,在后面 run TF 图的时候会评估和更新
图片风格可以用 一个隐藏层的激活值的 Gram 矩阵表示
为了得到更好的结果,我们综合所有的层的风格,这一点跟 内容损失不一样(内容损失只用1层靠中间的层)
3.3 总的损失
J(G)=αJcontent(C,G)+βJstyle(S,G)J(G) = \alpha J_{content}(C,G) + \beta J_{style}(S,G)J(G)=αJcontent(C,G)+βJstyle(S,G)
# GRADED FUNCTION: total_costdef total_cost(J_content, J_style, alpha = 10, beta = 40):"""Computes the total cost functionArguments:J_content -- content cost coded aboveJ_style -- style cost coded abovealpha -- hyperparameter weighting the importance of the content costbeta -- hyperparameter weighting the importance of the style costReturns:J -- total cost as defined by the formula above."""### START CODE HERE ### (≈1 line)J = alpha*J_content + beta*J_style### END CODE HERE ###return J
4. 优化求解
步骤:
- 创建 Interactive Session(相比常规 Session,可以简化代码)
- 加载内容图像
- 加载样式图像
- 随机初始化要生成的图像
- 加载VGG16模型
- 构建 TensorFlow 图:
- 在VGG16模型中运行内容图像并计算内容成本
- 在VGG16模型中运行样式图像并计算样式成本
- 计算总成本
- 定义优化器和学习率
- 初始化TensorFlow图并运行它,进行大量迭代,在每一步都更新生成的图像
- 创建 交互式Session
# Reset the graph
tf.reset_default_graph()# Start interactive session
sess = tf.InteractiveSession()
- 加载内容图片
content_image = imageio.imread("images/louvre_small.jpg")
content_image = reshape_and_normalize_image(content_image)
- 加载风格图片
style_image = imageio.imread("images/monet.jpg")
style_image = reshape_and_normalize_image(style_image)
- 随机生成噪声图片,为了加快速度,在内容图片上加了噪声
generated_image = generate_noise_image(content_image)
imshow(generated_image[0])

- 加载 VGG16 模型
model = load_vgg_model("pretrained-model/imagenet-vgg-verydeep-19.mat")
- 使用
conv4_2层计算内容损失
# Assign the content image to be the input of the VGG model.
sess.run(model['input'].assign(content_image))# Select the output tensor of layer conv4_2
out = model['conv4_2']# Set a_C to be the hidden layer activation from the layer we have selected
a_C = sess.run(out)# Set a_G to be the hidden layer activation from same layer. Here, a_G references model['conv4_2']
# and isn't evaluated yet. Later in the code, we'll assign the image G as the model input, so that
# when we run the session, this will be the activations drawn from the appropriate layer, with G as input.
a_G = out# Compute the content cost
J_content = compute_content_cost(a_C, a_G)
- 风格损失
# Assign the input of the model to be the "style" image
sess.run(model['input'].assign(style_image))# Compute the style cost
J_style = compute_style_cost(model, STYLE_LAYERS)
- 总体损失
### START CODE HERE ### (1 line)
J = total_cost(J_content, J_style, alpha=10, beta=40)
### END CODE HERE ###
- 定义优化器
# define optimizer (1 line)
optimizer = tf.train.AdamOptimizer(learning_rate=2.0)# define train_step (1 line)
train_step = optimizer.minimize(J)
- 完整模型
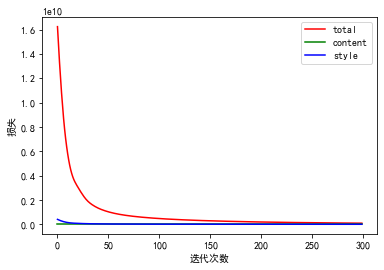
def model_nn(sess, input_image, num_iterations = 200):# Initialize global variables (you need to run the session on the initializer)### START CODE HERE ### (1 line)sess.run(tf.global_variables_initializer())### END CODE HERE #### Run the noisy input image (initial generated image) through the model. Use assign().### START CODE HERE ### (1 line)sess.run(model['input'].assign(input_image))### END CODE HERE ###total_cost = []content_cost = []style_cost = []iter = []for i in range(num_iterations):# Run the session on the train_step to minimize the total cost### START CODE HERE ### (1 line)sess.run(train_step)### END CODE HERE #### Compute the generated image by running the session on the current model['input']### START CODE HERE ### (1 line)generated_image = sess.run(model['input'])### END CODE HERE #### Print every 20 iteration.Jt, Jc, Js = sess.run([J, J_content, J_style])total_cost.append(Jt)content_cost.append(Jc)style_cost.append(Js)iter.append(i)if i%20 == 0:print("Iteration " + str(i) + " :")print("total cost = " + str(Jt))print("content cost = " + str(Jc))print("style cost = " + str(Js))# save current generated image in the "/output" directorysave_image("output/" + str(i) + ".png", generated_image)# save last generated imagesave_image('output/generated_image.jpg', generated_image)# plot costplt.rcParams["font.sans-serif"] = "SimHei"# 消除中文乱码plt.figure()plt.plot(iter, total_cost, 'r-', label='total')plt.plot(iter, content_cost, 'g-', label='content')plt.plot(iter, style_cost, 'b-', label='style')plt.legend()plt.xlabel('迭代次数')plt.ylabel('损失')return generated_image
- 运行模型
model_nn(sess, generated_image, num_iterations=300)
5. 用自己的照片测试
content 图片(400x300):

style 图片(400x300):



如有链接失效,请查看原文
本文地址:https://michael.blog.csdn.net/article/details/108803515
我的CSDN博客地址 https://michael.blog.csdn.net/
长按或扫码关注我的公众号(Michael阿明),一起加油、一起学习进步!


用Maven创建第一个web项目(1))

)




)

)


)

遇到的502 Bad Gateway错误)
备份及恢复)
)

