什么是Hadoop?
搞什么东西之前,第一步是要知道What(是什么),然后是Why(为什么),最后才是How(怎么做)。但很多开发的朋友在做了多年项目以后,都习惯是先How,然后What,最后才是Why,这样只会让自己变得浮躁,同时往往会将技术误用于不适合的场景。
Hadoop框架中最核心的设计就是:MapReduce和HDFS。MapReduce的思想是由Google的一篇论文所提及而被广为流传的,简单的一句话解释MapReduce就是“任务的分解与结果的汇总”。HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写,为分布式计算存储提供了底层支持。
MapReduce从它名字上来看就大致可以看出个缘由,两个动词Map和Reduce,“Map(展开)”就是将一个任务分解成为多个任务,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。这不是什么新思想,其实在前面提到的多线程,多任务的设计就可以找到这种思想的影子。不论是现实社会,还是在程序设计中,一项工作往往可以被拆分成为多个任务,任务之间的关系可以分为两种:一种是不相关的任务,可以并行执行;另一种是任务之间有相互的依赖,先后顺序不能够颠倒,这类任务是无法并行处理的。回到大学时期,教授上课时让大家去分析关键路径,无非就是找最省时的任务分解执行方式。在分布式系统中,机器集群就可以看作硬件资源池,将并行的任务拆分,然后交由每一个空闲机器资源去处理,能够极大地提高计算效率,同时这种资源无关性,对于计算集群的扩展无疑提供了最好的设计保证。(其实我一直认为Hadoop的卡通图标不应该是一个小象,应该是蚂蚁,分布式计算就好比蚂蚁吃大象,廉价的机器群可以匹敌任何高性能的计算机,纵向扩展的曲线始终敌不过横向扩展的斜线)。任务分解处理以后,那就需要将处理以后的结果再汇总起来,这就是Reduce要做的工作。
Hadoop解决两个问题海量数据存储、海量数据分析
提供了一个可靠的共享存储和分析系统,HDFS(Hadoop Distributed File System)实现存储,MapReduce实现分析处理。这两块是Hadoop的核心。
Hadoop具有最大化利用内存、最大化利用磁盘、最大化利用CPU的特点。
Hbase:nosql数据库,最大化利用内存。
HDFS:架构设计原则(最大化利用磁盘):
Block(文件块):一个文件分块默认64M。
NameNode:保存文件系统的目录信息,读取信息。数据节点很多时,容易成为系统的瓶颈,避免这个问题,实现NameNode一般都保存到内存中,同事持久化一部分信息在磁盘上,以备数据丢失。
DataNode:用于存储Block。
HDFS的HA策略:2.x开始hadoop支持namenode的active-standy模式,宕机时standy切换成active模式为整个应用提供服务。

MapReduce:
最大化利用CPU,分析处理大规模的数据集
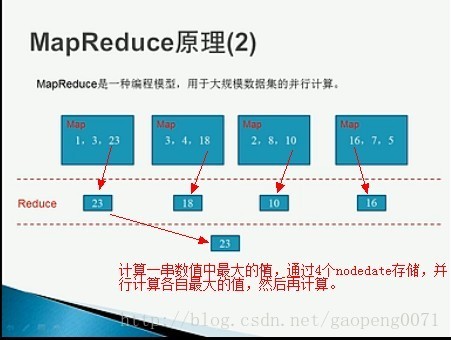
通过图片可以简单了解,将同一操作,放在相当于多台处理器上并行执行,每个处理器执行1部分执行后,在将结果汇总在一起,这样减少了很多的时间。










)
—完成项目含源代码)






)
