我把Python里面非常有名的简洁,高效,方便的代码整理出来,让我们来一睹她的风采。其实每个主题展开讲都是很大的篇幅,今天我们先overview一下
看完之后,相信初学者会更快的喜欢上python.
1.列表推导
要说Python里面最简洁最神奇的代码,列表推导应该算排行第一。
这是一种非常精炼的写法,可以根据一份列表来制作另外一份。这种表达式称为list comprehension(列表推导)
例子1,利用一个列表生成一个新的列表

例子2,甚至可以过滤一些列表中的元素,列如:
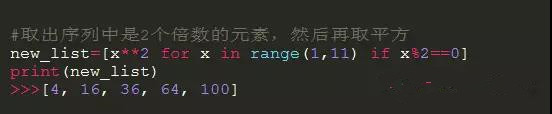
---------------------
例子3:若要需要对序列里面的内容进行循环处理时,也可以加一个函数进行组合完成
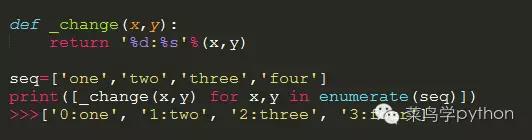
看完列表推导的用法,是不是觉得眼前一亮好很方便啊.
2.with用法
一般我们处理文件都是先打开->然后处理->然后关闭.比较麻烦,还需要防止异常保护try/finally,很多时候我们都把精力集中在如何处理文件这样会忘掉关闭文件.Python里面有一种非常简洁的方法:
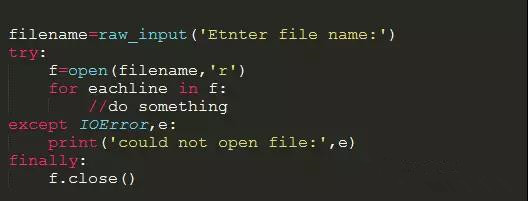
普通的打开,关闭文件处理:
用with语句,使用起来非常简单,有点像英语,用with语句能够保证当写操作执行完毕之后,自动关闭文件
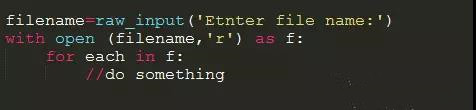
其实with的使用场景非常多,除了对于文件的处理关闭,在多线程的使用里面对锁的处理也是经常使用的 。以后的文章会讲python的多线程,多进程的使用,会展开讲.
with的用法体现了Python的一个精髓:把一些繁琐的事务交给语言本身,开发者只要focus放在处理问题的逻辑上就可以了.
3.匿名函数lambda
Python里面有一个"懒人专用的函数",叫做匿名函数(也就是没有函数名)的函数.我们在传入函数时,有些时候,不需要显式地定义函数,直接传入匿名函数更方便.
lambda(这个名字其实是借鉴了另外一个黑客非常喜欢的语言LISP),lambda一般的形式是关键字lambda 后面跟一个或者多个参数,后面紧跟一个冒号,之后是一个表达式:
lambda arg1,agr2,...agrN:express using arguments
以map()函数为例,若要计算一个列表里面的每个元素的平方,可以直接传入匿名函数:
>>> map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9])
[1, 4, 9, 16, 25, 36, 49, 64, 81]
通过对比可以看出,匿名函数lambda x: x * x实际上就是:
def f(x):
return x * x
用匿名函数的好处是显而易见的:
一方面是可以免去取名字的麻烦(因为高质量的代码对函数的取名是有一定的要求的)
而且不必担心函数名冲突
此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数:
4.生成器
生成器是python里面一个比较难理解的概念,也是Python中引入的两个强大的特性之一(猜猜另外一个特性是啥,对了就是装饰器)
今天我先来看一下它的一个简单例子,一个关于斐波那契数列的实现:
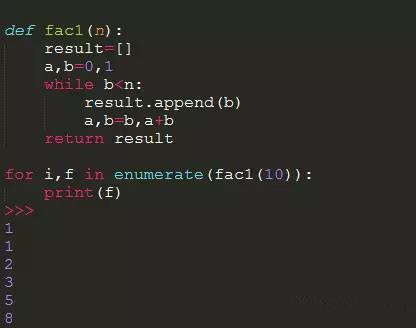
用了生成器的函数:
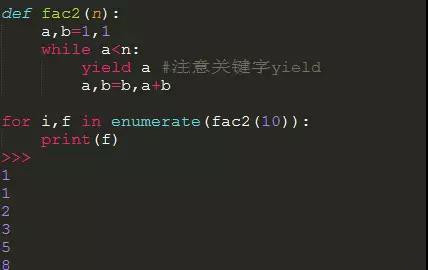
看第二种方法代码是不是简洁很多,这就是yield关键字的魅力.
如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个生成器函数,打印看一下.
print(fac2(10))
>>><generator object fac2 at 0x026958F0>
生成器函数和普通函数的执行流程非常不一样:
函数是顺序执行,遇到return语句或者最后一行函数语句就返回。
而变成生成器的函数,只会相应迭代操作时才运行,一般都是配合for使用(也有配合sum(),list())
在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
好了,以上几个就是Python中非常神奇的代码,不知道大家看完之后是不是对Python的喜爱又加深了一分,那就不枉我大半夜敲这么多字了(说实话敲的有点手疼),其实简洁高效就是python的代名词.好了最后说一下,若我写的对大家有帮助,麻烦大家支持一下,也是对我的一点鼓励和动力.
原文:https://blog.csdn.net/qq_41888542/article/details/79824293

)

















