购买阿里云服务器
到[阿里云官网],选择轻量应用服务器, 步骤如图所示:


地域随便选择哪一个,镜像的话,对比了CentOS,Debian,Ubuntu,我最终选择了CentOS,因为流行嘛~配置的话,看项目本身了,我这里选择的是1G内存,20G硬盘最小配置,也够用了。
配置python环境
进入服务器
选择好服务器并付费之后,点击阿里云的控制台-云计算基础服务-轻量应用服务器:
点击CentOS服务器,进入后,点击右上角的远程连接,如图所示:
安装python3并与python2共存
CentOS 7.3 默认安装了python2.7.5 因为一些命令要用它比如yum 它使用的是python2.7.5。当我们在命令行里输入
python -V就可以看到版本为2.7.5。
安装python3
因为我们要安装python3版本,所以python要指向python3才行,目前还没有安装python3,先备份,备份之前先安装相关包,用于下载编译python3
yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make这几个包必须得安装,否则安装python3时可能会出现各种错误.
运行下面两个命令,进行备份
cd /usr/bin
mv python python.bak安装
wget https://www.python.org/ftp/python/3.6.3/Python-3.6.3.tar.xz
解压
tar -xvJf Python-3.6.3.tar.xz
切换进入
cd Python-3.6.3编译安装
./configure prefix=/usr/local/python3
make && make install
安装完毕,/usr/local/目录下就会有python3了
实现python3和python2的共存
添加python3的软链
rm /usr/bin/python
ln -s /usr/local/python3/bin/python3 /usr/bin/python 这时候在执行命令python -v和python2 -V,应该就能看到python3和python2的版本了。
这时候在执行命令python -v和python2 -V,应该就能看到python3和python2的版本了。
因为执行yum需要python2版本,所以我们还要修改yum的配置,执行:
vi /usr/bin/yum把#! /usr/bin/python修改为#! /usr/bin/python2 同理
vi /usr/libexec/urlgrabber-ext-down 文件里面的#! /usr/bin/python 也要修改为#! /usr/bin/python2
安装django项目中需要的python相关包
安装python相关包需要用到python中的pip命令,比如我项目中需要的包有:
pip install Django
pip install PyMySQL
pip install Scrapy
pip install beautifulsoup4
pip install bs4
pip install lxml
pip install numpy
pip install requests
pip install simplejson
pip install urllib3
注意:在执行命令pip install mysqlclient时会报错,这里需要特别强调下,不然在后面运行需要连mysql的django项目时,会报do you install mysqlclient?
解决方法如下:
sudo python -m pip install mysqlclient 此时python所有需要的包,都已经安装好
此时python所有需要的包,都已经安装好
安装mysql
下载mysql源安装包
wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm安装mysql源
yum localinstall mysql57-community-release-el7-8.noarch.rpm
yum install mysql-devel
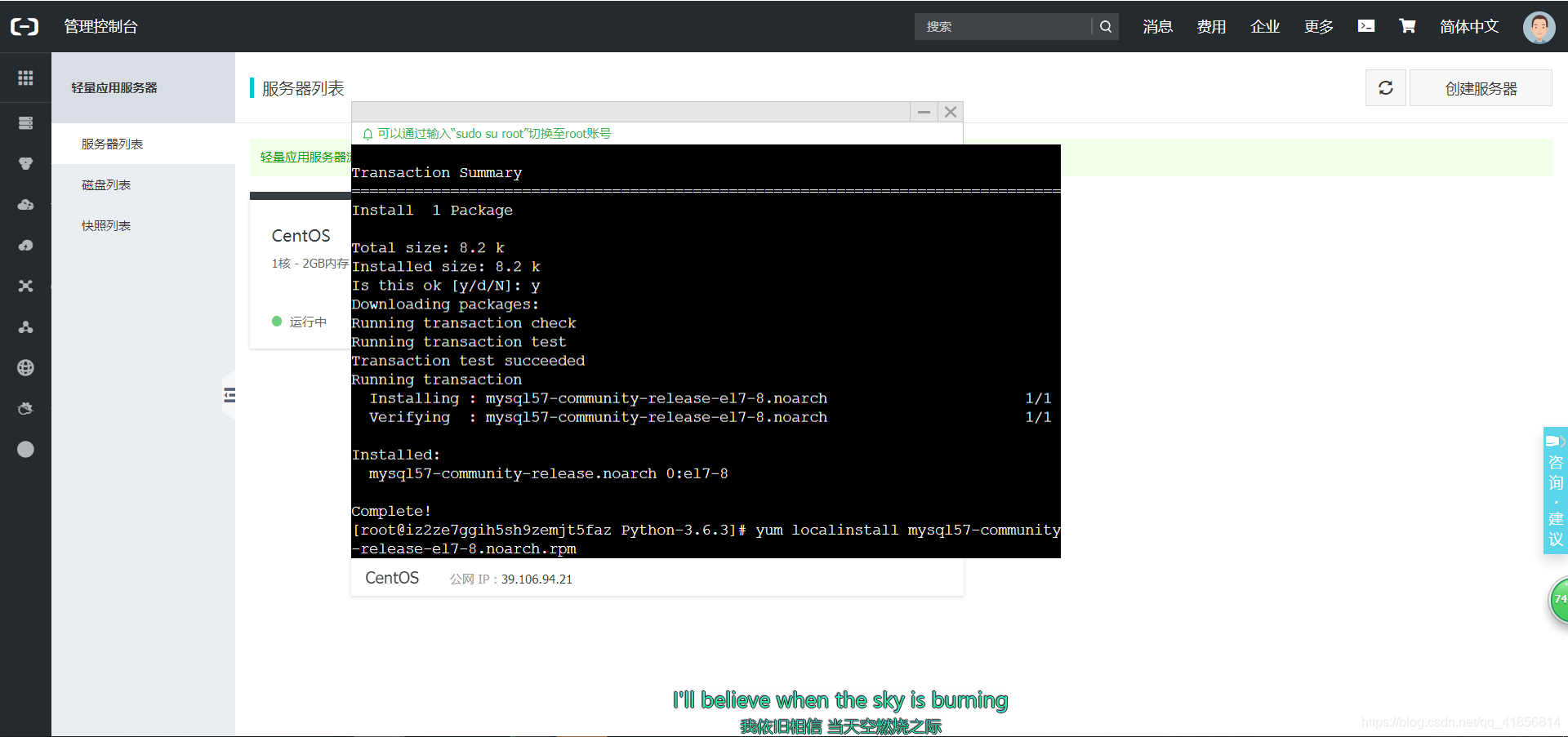
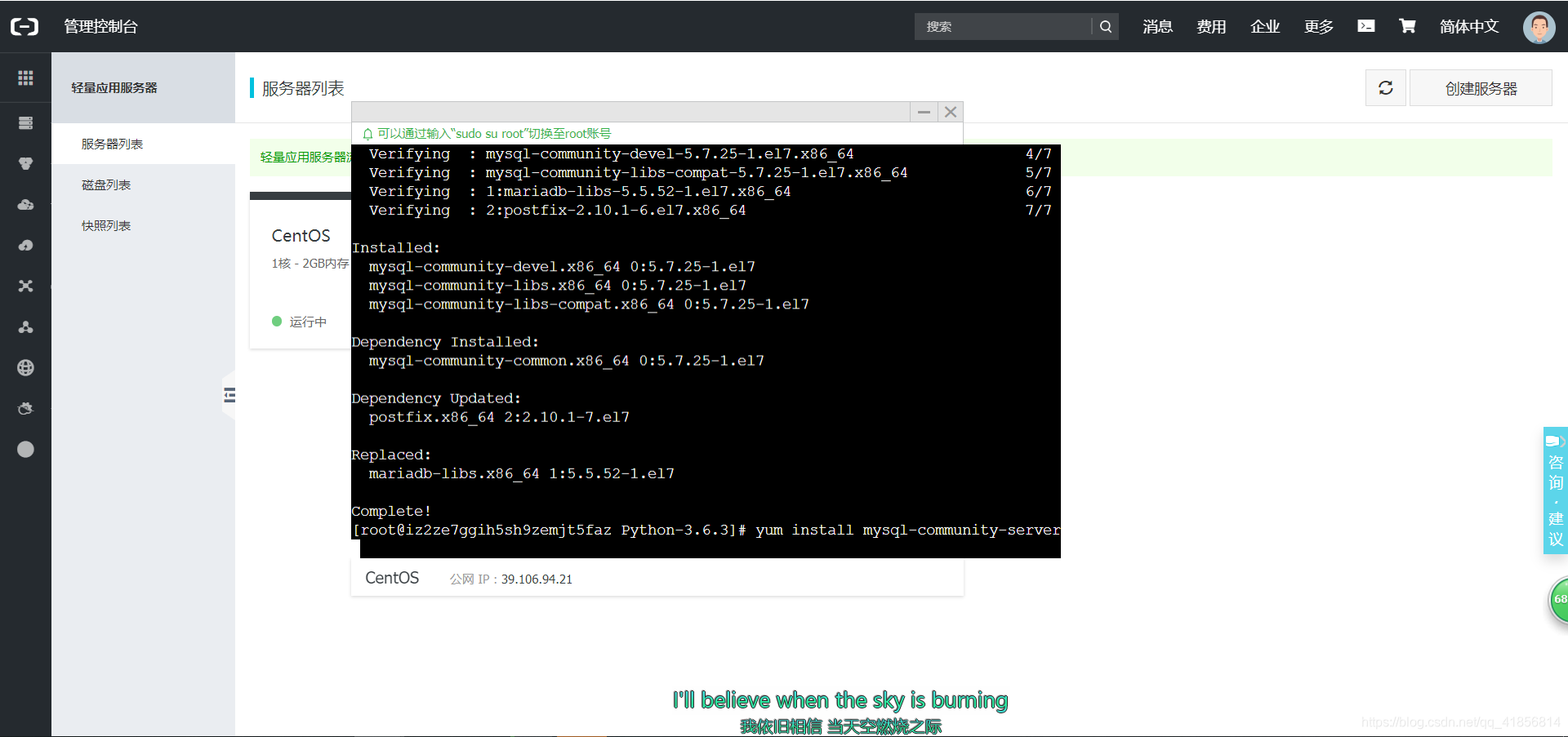 安装MySQL
安装MySQL
启动MySQL服务
systemctl start mysqld查看MySQL的启动状态
systemctl status mysqld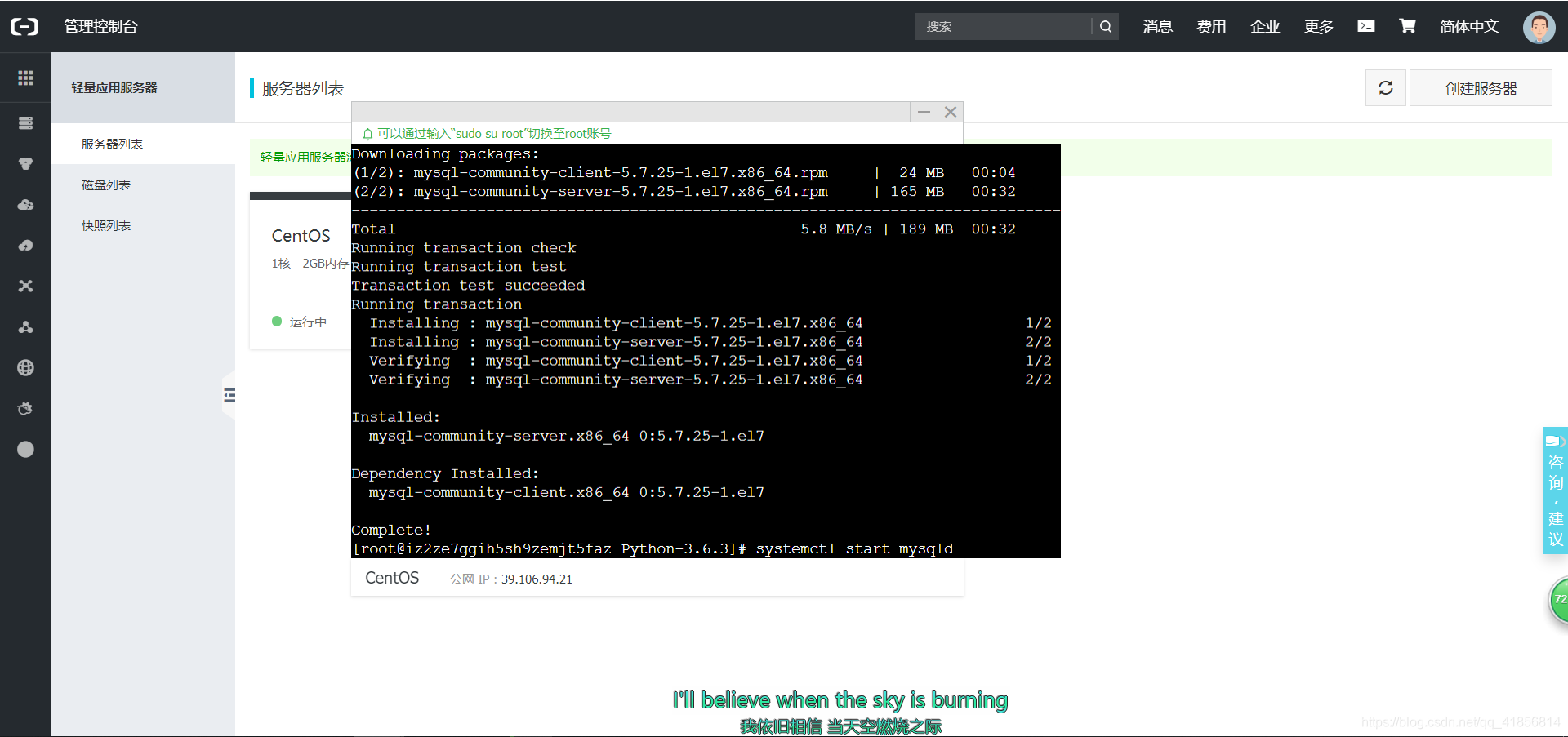
开机启动
systemctl enable mysqld修改root本地登录密码
grep 'temporary password' /var/log/mysqld.log
mysql -uroot -p
set password for 'root'@'localhost'=password('!2Qw32sd'); 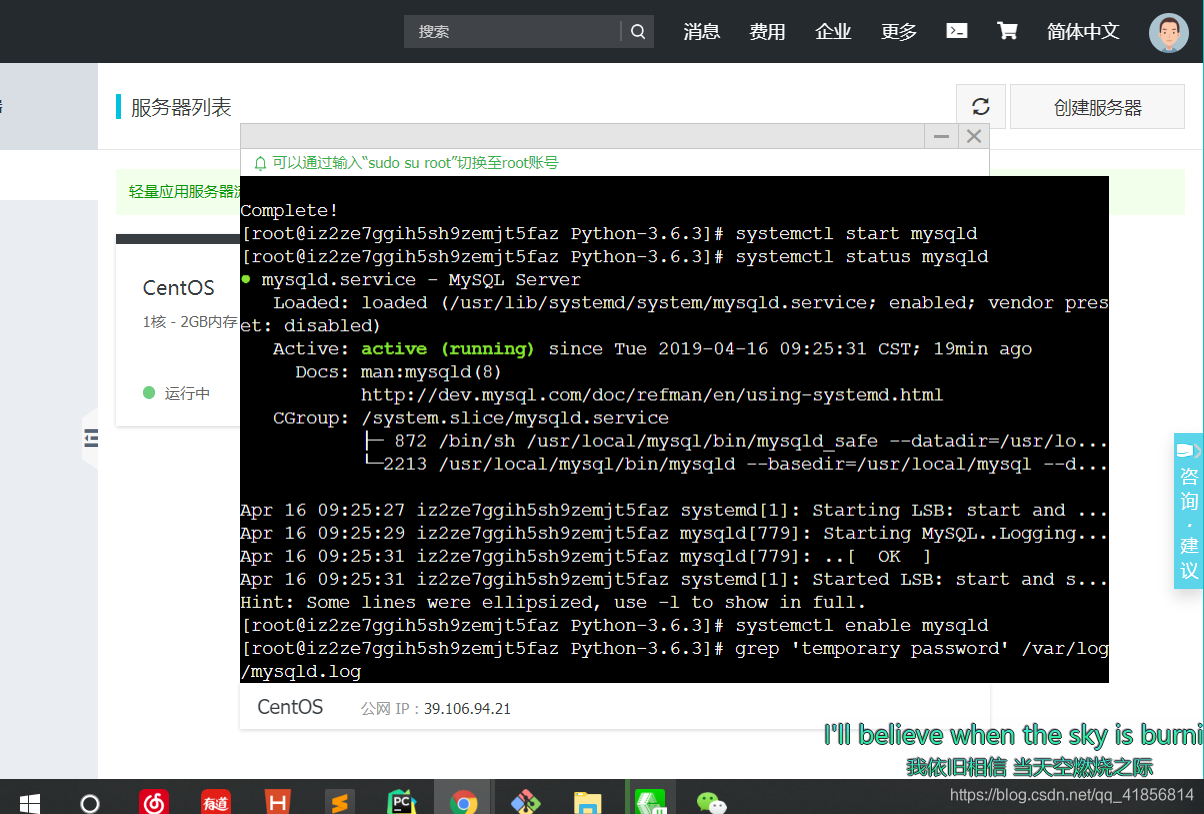
注意:mysql5.7默认安装了密码安全检查插件(validate_password),默认密码检查策略要求密码必须包含:大小写字母、数字和特殊符号,并且长度不能少于8位。否则会提示ERROR 1819 (HY000): Your password does not satisfy the current policy requirements错误
配置默认编码为utf8
修改/etc/my.cnf配置文件,在[mysqld]下添加编码配置,如下所示:
[mysqld]
character_set_server=utf8
init_connect='SET NAMES utf8'
导入django和mysql数据库
导入django项目
由于我项目放在码云上面,然后CentOS又自带git,我的数据库文件也比较小,所以也放在django项目中了,用git下载下来:
sudo su root
mkdir project
cd project
git clone https://gitee.com/dafeige/django-restframework-demo.git
导入sql数据库文件
进入数据库
mysql -u root -p
导入sql文件。。。
部署django工程
进入到工程中
python manage.py runserver 0.0.0.0:80 &
最后面的”&”,这符号表示在后台运行该进程。这里的IP地址如果用公网IP
会运行不了,而用0.0.0.0则外网和127.0.0.1都能够访问。
未完待续...


)





)





)



)
