
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦!

🤖 高效提示词的4大经典框架:ICIO、CRISPE、BROKE、RASCEF


ICIO 框架
Intruction (任务) :你希望AI去做的任务,比如翻译或者写一段文字
Context (背景) :给AI更多的背景信息,引导模型做出更贴合需求的回复,比如你要他写的这段文字用在什么场景的、达到什么目的的
Input Data (输入数据) :告诉AI你这次你要他处理的数据。比如你要他翻译那么你每次要他翻译的句子就是「输入数据」
Output Indicator (输出格式) :告诉AI他输出的时候要用什么格式、风格、类型,如果你无所谓什么它输出时候的格式,也可以不写
CRISPE 框架
Capacity and Role (角色) :告诉AI你要他扮演的角色,比如老师、翻译官等等
Insight (背景) :告诉AI你让他扮演这个角色的背景,比如扮演老师是要教自己10岁的儿子等等
Statement (任务) :告诉AI你要他做什么任务
Personality (格式) :告诉AI用什么风格、方式、格式来回答
Experiment (实验) :请求AI为你回复多个示例 (如果不需要,可无)
BROKE 框架
Background (背景) :说明背景,提供充足信息
Role (角色) :你要AI扮演的角色是什么
Objectives (目标/任务) :你要AI做的事情的一个描述
Key Result (关键结果) :对于AI输出的回答,在风格、格式、内容等方面的要求
Evolve (改进) :在AI给出回答以后,三种调整、改进方法
RASCEF 框架
Role (角色) :这就是AI假装的人,它可以是电子邮件营销人员、项目经理、厨师或您能想到的任何其他角色
Action (行动) :这是人工智能需要做的,例如编写项目执行计划
Script (步骤) :这些是 A 完成操作应遵循的步骤
Content (上下文) :这是背景信息或情况
Example (示例) :这些是说明这一点的特定实例,它们帮助人工智能理解语气和思维/写作风格
Format (格式) :这是AI应该呈现其答案的方式,它可以是段落、列表、对话或任何其他格式 ⋙ 即刻 @东风阁主

🤖 YouTube 测试用AI生成视频摘要,用技术改善用户体验

8月1日,YouTube 开始在搜索和观看页面测试AI生成的视频摘要,帮助用户更快地获取视频核心内容,提高浏览效率。不过此次测试只面向英文用户且范围有限。
YouTube 表示,这是进一步利用AI技术改善用户体验的尝试,并将在之后将AI生成技术应用到更广泛的视频创意、标题等领域。不过!这并不意味着内容创作者的工作将被机器取代,相反,创作者编写的视频描述仍然是用户获取视频信息的重要来源 ⋙ Search Engine Land
🤖 阿里云宣布「通义千问」开源,国内首个商用开源的大厂模型
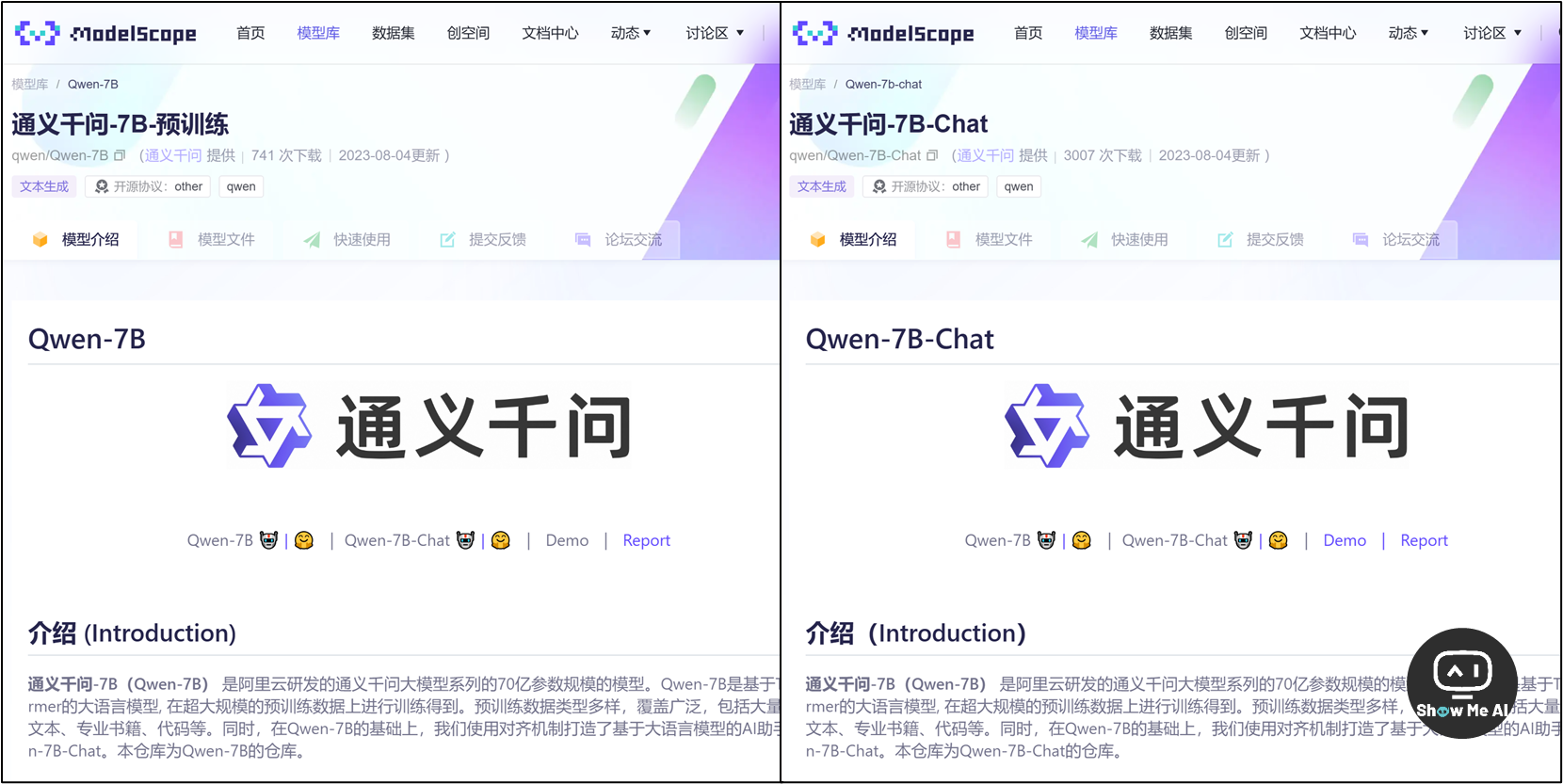
8月4日,阿里云官方公众号宣布通义千问70亿参数通用模型Qwen-7B和对话模型Qwen-7B-Chat上架魔搭,两款模型均开源、免费、可商用。此举让阿里云成为国内首个加入大模型开源行列的大型科技企业。
Qwen-7B 是支持中、英等多种语言的基座模型,Qwen-7B-Chat 是基于基座模型的中英文对话模型,在许多测基准上都取得了良好的表现。
用户目前已经可以从魔搭社区直接下载模型,也可通过阿里云灵积平台访问和调用这些模型,而通过开源代码,用户可以很方便地在消费级显卡上部署和运行模型 ⋙ 通义千问-7B-预训练 | 通义千问-7B-Chat

🤖 和 AI 一起做动画,将AI融入动画工作流的案例和实践经验

这是一篇超长的实践经验分享文章!作者 @海辛 总结了「使用AI制作动画」的不同路径和技术实现方式,并附上了动画视频和推荐的免费系列教程!
这应该是目前覆盖最全面的、最硬核的教程啦!非常值得放进收藏夹~
🔔 一、根据参考视频进行风格迁移
1. Runway Gen-1
提供原视频和参考图像,基于风格迁移生成新的视频
无法完全按参考图风格迁移,难以应用于实际项目,仍停留在玩具水准
2. Stable Diffusion + EbSynth
使用 Stable Diffusion 绘制关键帧,再用 EbSynth 根据原视频+关键帧将其余帧补齐
当画面引入全新的信息时,就要新建一个关键帧;还可以结合传统的影视抠像工具进行叠加,从而指定 AI 仅对画面部分内容进行风格迁移
兼顾生成效果和计算效率,可控性强,是当前最优方案之一
3. Rerender
自动判断关键帧,保证关键帧间信息连贯一致,避免了上个方案中人工调整关键帧间的信息连续性问题
代码未开源但值得期待
4. AI + AE
AI工具与AE转场、PR剪辑等影视工具结合,发挥两者优势
AI 动画特效做得好的人,大多数都是影视/游戏/特效的背景,他们知道如何将 AI 生成的画面结合到其他管线的工具中,从而提升画面效果
🔔 二、AI生长类动画
1. Disco Diffusion、Stable Diffusion Deforum
用传统 AI 生成图像工具,进行画面的批量生成,通过指定不同关键帧上的画面内容,和关键帧上的镜头运动,从而使得 AI 能生成连续的动画
控制 AI 生成的参数和影视镜头语言其实呈现一定的映射关系
Youtube 频道主 DoodleChaos 给 Resonate 的歌曲《Canvas》 做的动画音乐视频,代表此类动画的最高水准之作
🔔 三、根据静态图生成动画
1. 让肖像画说话
D-ID、Movio、Artflow 等工具基于First Order Motion算法,可以让一张静态的肖像画动起来说话的功能
算法成熟,可广泛应用于各类创意内容
2. 让静态图 (随机) 动起来
Pika Labs、Gen-2 等工具的底层技术类似 Animatediff,支持根据单张图输入其随机动态效果
可用于概念预览,但可控性有限,对于目前工业界的帮助还不是很显著 ⋙ 海辛

🤖 构建基于LLM的系统和产品的模式
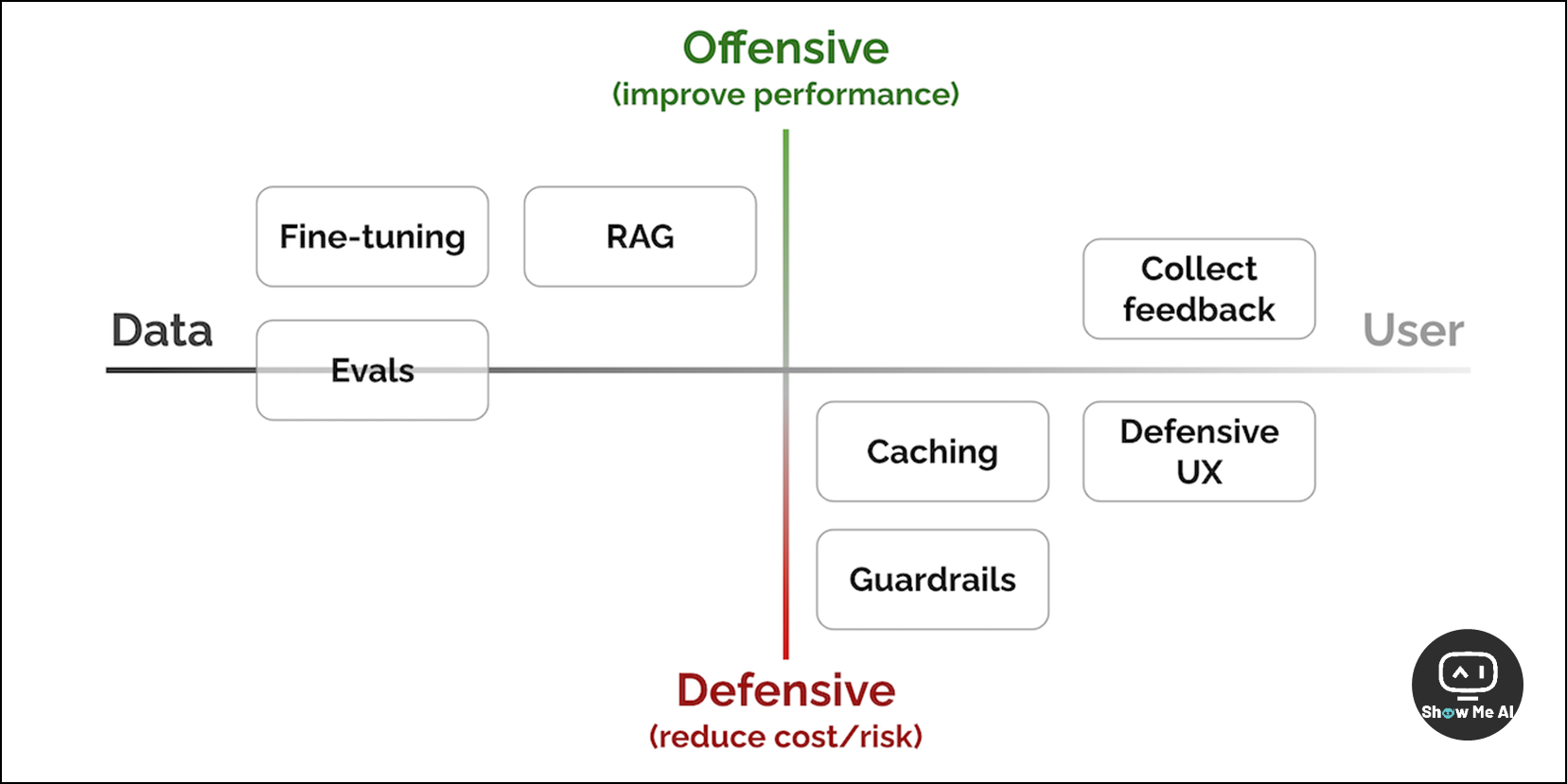
这篇长文探讨了一个非常实用的话题——在构建基于大语言模型的系统和产品时,需要注意的7个关键模式。
作者分享了自己宝贵经验和深度思考,覆盖了从从模型性能、成本控制到用户体验的各个方面,对于从业者来说是非常实用的指南。
1. Evals
What:评估,用于测量性能
Why:Evals 可以测量系统或产品的表现,检测任何回归;一个具代表性的 Evals 套件可以大规模测量系统变更;如果没有Evals 就会飞盲,或者必须通过视觉检查每个LLM输出来检测每一个变更
More about:Evals包括基准数据集和指标;一些知名基准有 MMLU、EleutherAI Eval、HELM 和 AlpacaEval 等;指标可分为与上下文相关或无关的两类,还需要注意常用指标的局限性
2. RAG
What:检索增强生成,用于添加外部知识
Why: RAG 可以减少 hallucination,基于检索出的上下文指导模型;相比持续预训练语言模型,使用检索索引更经济高效,也更易于提供最近的数据
More about:RAG 通常基于稠密向量检索 (例如 DPR),先 offline 构建文档索引,然后在线为每个查询检索出 Top K 个相关文档,并将其提供给语言模型作为上下文;一些变体包括 RAG-Sequence、RAG-Token、FiD 和 RETRO 等
3. Fine-tuning
What:微调,用于提高特定任务的性能
Why:Fine-tuning 可以提高开放域语言模型的性能,实现比第三方语言模型更好的效果,也让系统模块化
More about:Fine-tuning 通常在预训练模型的基础上进行,一些常见的 Fine-tuning 技术包括软提示调优、前缀调优、适配器和低秩适配等
4. Caching
What:缓存,用于降低延迟和成本
Why:缓存可以显著减少延迟和成本;对于某些不能容忍秒级延迟的用例,预计算和缓存可能是唯一的实现方式
More about:在语言模型中,常见做法是基于输入请求的 Embedding 来缓存响应;不过需要谨慎应用 (例如不要缓存可能过时的价格信息等)
5. Guardrails
What:防护栏,用于确保输出质量
Why:Guardrails 可以确保模型输出可靠统一到足以用于生产环境,例如可能需要确保输出符合特定 JSON 模式等
More about:Guardrails 通常通过验证语言模型的输出来实现,一些常见策略包括结构指导、语法验证、内容安全检查、语义验证等
6. Defensive UX
What:防御性UI,用于优雅地处理错误
Why:Defensive UX 承认语言模型可能出现不准确或 hallucination 的情况,并提前应对这些情况,主要通过引导用户行为、避免误用和优雅地处理错误
More about:一些常见模式包括设定正确的期望值、启用高效驳回、提供归因等,可以提高可访问性、信任度和体验质量
7. Collect user feedback
What:收集用户反馈,用于构建数据飞轮
Why:收集用户反馈可以了解用户喜好,帮助改进模型、适应个人喜好,并评估系统整体性能
More about:反馈可以是明确或隐式的,要方便用户提供反馈;隐式反馈也很有价值,可以提供大量用户行为偏好信息 ⋙ eugeneyan

🤖 为什么AI「智能涌现」对创业者、从业者、普通人都价值巨大
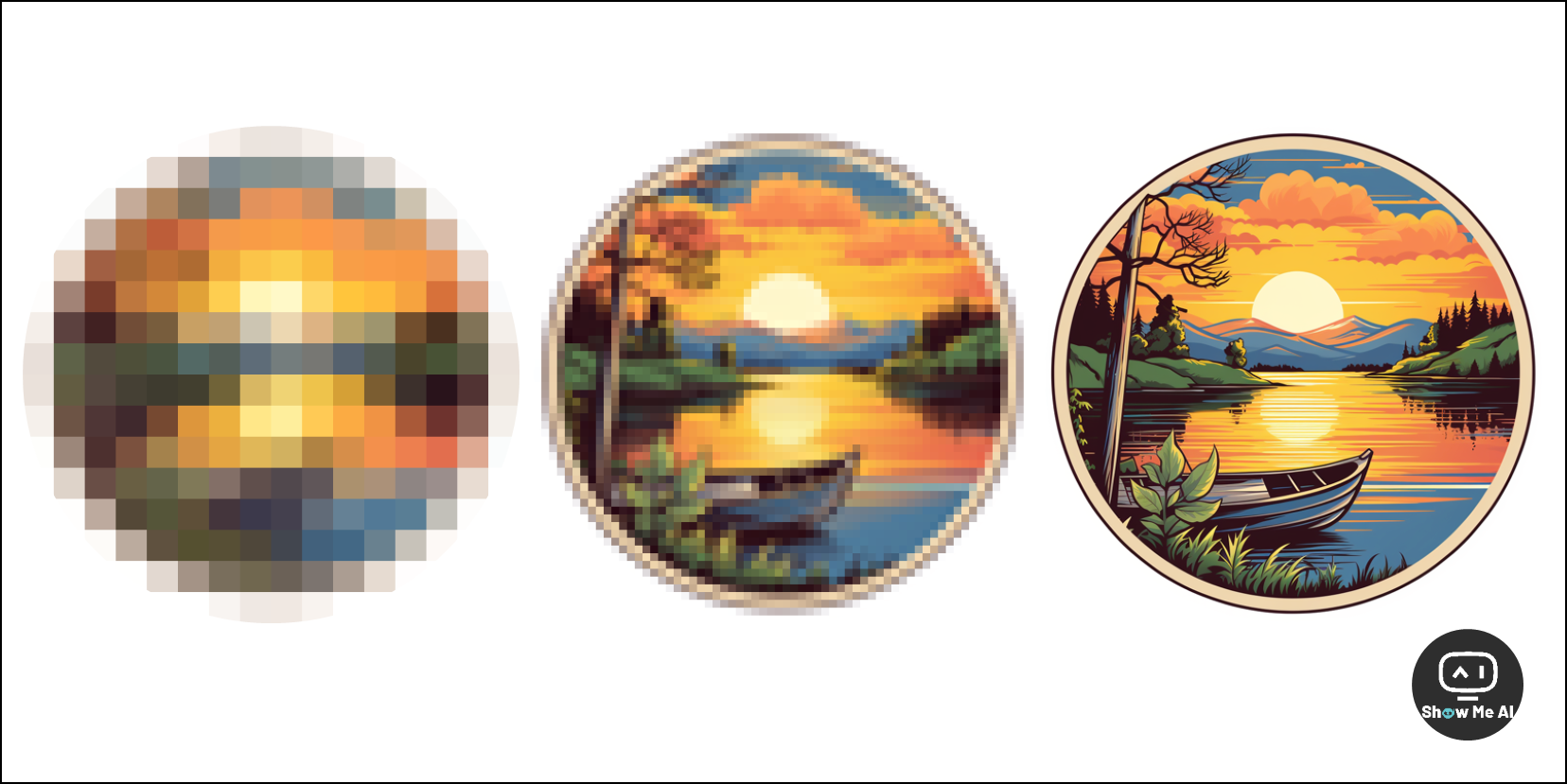
我们一直在谈论的大模型「智能涌现」到底是什么意思?为什么理解这个概念对我们这么重要呢?这篇文章从一幅图的像素数量入手,非常清晰地解释了概念,并探讨了7个非常核心的问题。
正如图所示,当像素的数量多到一定程度时,我们就可以看出图片的基本内容了。宏观涌现可能只是构成系统的微观因素的线性变化的结果。大模型的智能涌现也是同样的道理。
问题1:除600亿参数规模外,还存在其他阈值,可以让AI发生智能涌现吗?
存在多个阈值,对应AI的不同新能力
AI模型同理,600亿不是唯一阈值,要实现新的能力需要更大的参数量;涌现时AI表现不稳定,可确定处在一个阈值附近
问题2:随着AI参数规模的增加,AI的能力会持续提升,但这会有上限吗?
AI能力会持续增强,会跨越一个又一个阈值
但人类对此的感知有上限,100万亿参数量级接近人脑神经连接数,超过这个量级后,人类将完全感知不到AI的进步
问题3:未来二十年你将会如何感受AI?
未来每当AI跨越一个新阈值,人类会强烈感受到进步,但之后会逐渐感知不明显,直到下一个阈值突破
就像人对新款 iPhone 屏幕的感受,开始惊艳,最后陷入「似乎稍有不同」的微妙感受
问题4:什么是「知识压缩」,它跟AI有什么关系?
知识是压缩数据的方法,训练模型就是在寻找压缩方法 (知识),实现智能
图像压缩实验证明了知识使图像在低像素下依然涌现,压缩越高效,知识越本质
问题5:什么是智能?
智能是一个生成的过程,不是状态;高级智能具有更强的泛化能力,这来自大量知识的涌现,泛化是成规模知识涌现的结果
低级智能以还原为主,高级智能强在泛化,智能必须是生成的过程
问题6:OpenAI到底做对了什么?
OpenAI 让AI自主大规模寻找知识,并以生成为目标而非应用
解决了两个悖论:给AI自主学习的机会,以及将生成作为最重要目标 (OpenAI低估了这两点的价值)
问题7:什么是「世界模型」?
世界模型是外部世界在AI内部的建模和模拟,是AI的未来方向
它以层次方式组织知识并模拟世界运行,让AI拥有更强大的直觉式智能,能达到写出红楼梦的水平 ⋙ 阅读全文
🤖 对话「妙鸭」产品负责人:AIGC 的产品第一天不收钱,就可能收不到钱

谁都没有想到,国内 AIGC 第一个真正意义上破圈的现象级产品,诞生在照片美化(写实人像)这个已经相当成熟的赛道。
7月中旬悄悄上市,妙鸭凭借只需「9.9 元和 20 张照片就能生成艺术写真级的个人美照」这个噱头,在短短几周的时间内引来无数爱美女孩儿下载尝鲜,生成的「美照」席卷了朋友圈等社交媒体。
7月底,妙鸭相机接连受到上海市消保委和央视财经新闻的点名批评,称其退款相关规定违反了消费者权益保护法,并且威胁到了用户隐私。
最近,妙鸭接受了科技媒体的采访,介绍了产品源起和团队背景,并对争议话题进行了回应。感兴趣的小伙伴们可以 ⋙ 阅读原文

🤖 提升ChatGPT性能的实用指南:Prompt Engineering的艺术
提示工程是一门新兴学科,就像是为大语言模型 (LLM) 设计的「语言游戏」。通过这个「游戏」,可以更有效地引导 LLM 来处理问题。也只有熟悉了这个游戏的规则,才能更清楚地认识到 LLM 的能力和局限。
这篇文章非常全面地梳理和总结了提示工程关键知识点,长文!适合查漏补缺!
1. 什么是提示工程?
2. 提示工程基础
提示四要素
通用技巧:由浅入深、明确指令、明确细节、明确需求、正向引导,避免反向限制
简单提示解析
3. 提示工程进阶
零/少样本提示:Zero-Shot Prompting、Few-Shot Prompting
思维链提示:少样本思维链、零样本思维链
Explicit 思维链
主动提示
思维树
多模态思维链
一致性提示
Progressive-Hint 提示
Plan-and-Solve 提示
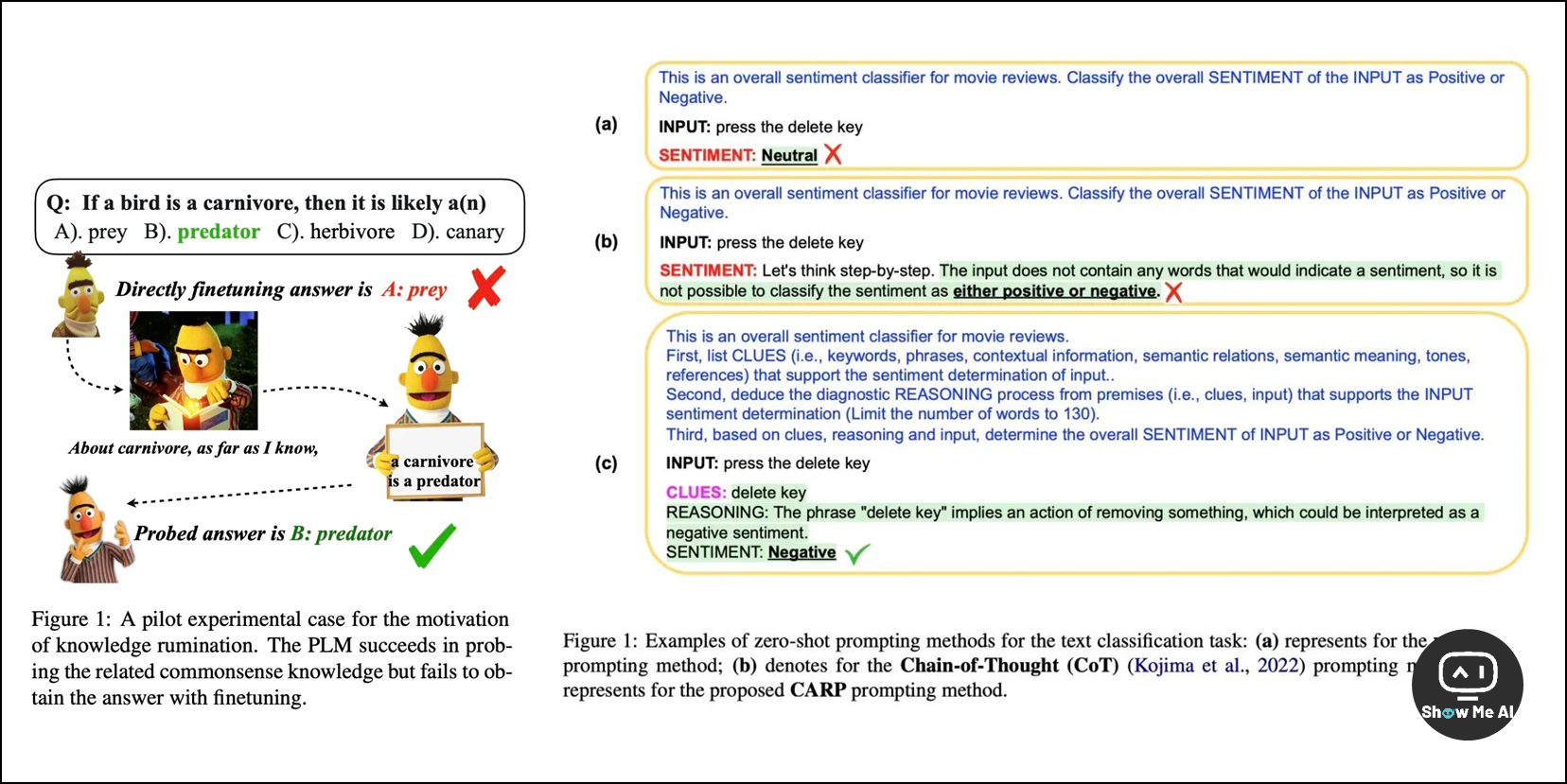
增强 (检索) 提示:外部知识库、LLM 知识库 (知识生成提示 / Clue And Reasoning 提示 / 知识反刍提示)
4. 懒人万能提示工程 ⋙ 腾讯技术工程
感谢贡献一手资讯、资料与使用体验的 ShowMeAI 社区同学们!

◉ 点击 👀日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
◉ 点击 🎡生产力工具与行业应用大全,一起在信息浪潮里扑腾起来吧!




![[K8s]问题描述:k8s拉起来的容器少了cuda的so文件](http://pic.xiahunao.cn/[K8s]问题描述:k8s拉起来的容器少了cuda的so文件)




)


)



)


