代码
# -- encoding:utf-8 --
"""
Create by ibf on 2018/5/6
"""import numpy as np
import tensorflow as tf# 1. 构造一个数据
np.random.seed(28)
N = 100
x = np.linspace(0, 6, N) + np.random.normal(loc=0.0, scale=2, size=N)
y = 14 * x - 7 + np.random.normal(loc=0.0, scale=5.0, size=N)
# 将x和y设置成为矩阵
x.shape = -1, 1
y.shape = -1, 1# 2. 模型构建
# 定义一个变量w和变量b
# random_uniform:(random意思:随机产生数据, uniform:均匀分布的意思) ==> 意思:产生一个服从均匀分布的随机数列
# shape: 产生多少数据/产生的数据格式是什么; minval:均匀分布中的可能出现的最小值,maxval: 均匀分布中可能出现的最大值
# tf.zeros:意思是产生一个全为 零 的矩阵,参数表明是一维的
w = tf.Variable(initial_value=tf.random_uniform(shape=[1], minval=-1.0, maxval=1.0), name='w')
b = tf.Variable(initial_value=tf.zeros([1]), name='b')
# 构建一个预测值
y_hat = w * x + b# 构建一个损失函数
# 以MSE作为损失函数(预测值和实际值之间的平方和)
loss = tf.reduce_mean(tf.square(y_hat - y), name='loss')# 以随机梯度下降的方式优化损失函数
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.05)
# 在优化的过程中,是让那个函数最小化,会自动更新w和b
train = optimizer.minimize(loss, name='train')# 全局变量更新
init_op = tf.global_variables_initializer()# 运行
def print_info(r_w, r_b, r_loss):print("w={},b={},loss={}".format(r_w, r_b, r_loss))with tf.Session() as sess:# 初始化sess.run(init_op)# 输出初始化的w、b、lossr_w, r_b, r_loss = sess.run([w, b, loss])print_info(r_w, r_b, r_loss)# 进行训练(n次)for step in range(100):# 模型训练sess.run(train)# 输出训练后的w、b、lossr_w, r_b, r_loss = sess.run([w, b, loss])print_info(r_w, r_b, r_loss)
运行结果
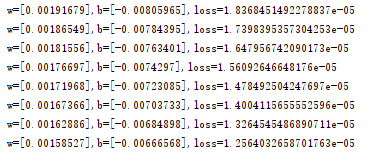





:OS相关)



:启动、中断、异常)
![[GCC for C]编译选项---IDE掩盖下的天空](http://pic.xiahunao.cn/[GCC for C]编译选项---IDE掩盖下的天空)

)

:系统调用)

)

:计算机体系结构、内存层次和地址生成)
