大模型超越AI
前言
洁洁的个人主页
我就问你有没有发挥!
知行合一,志存高远。
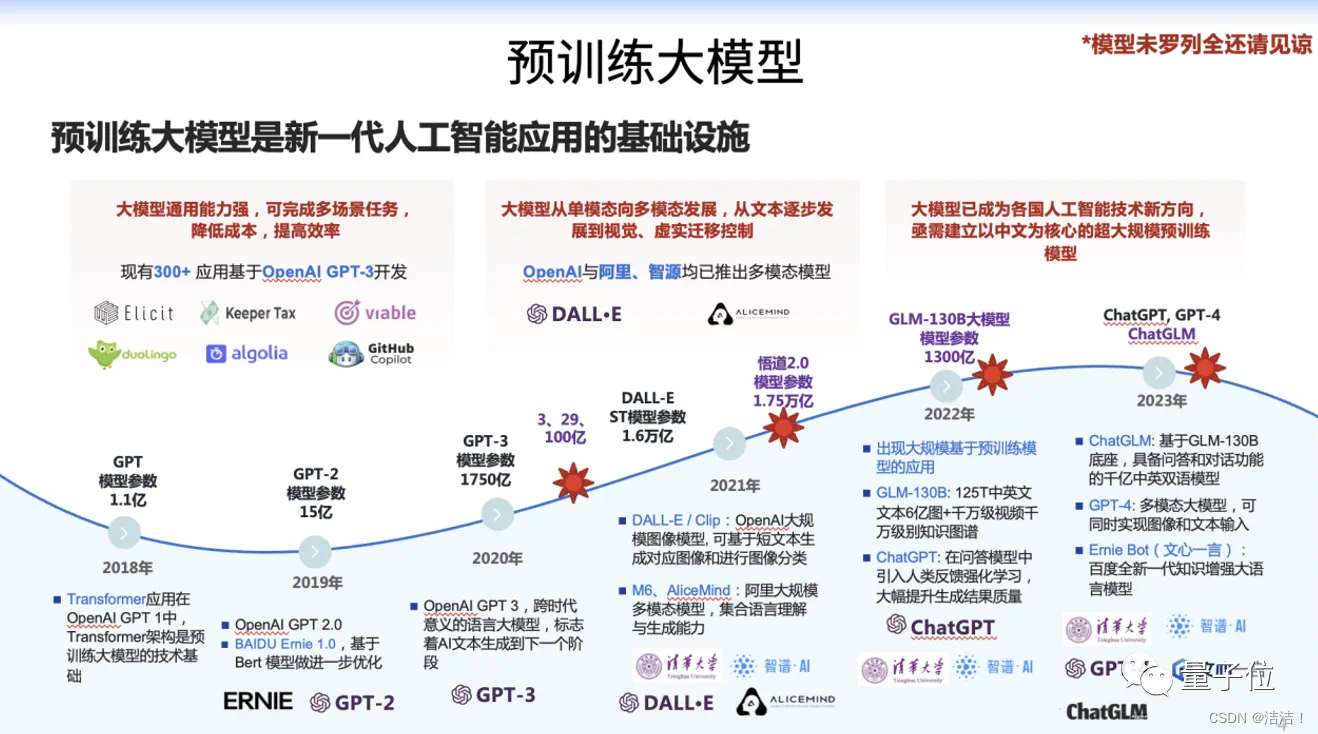
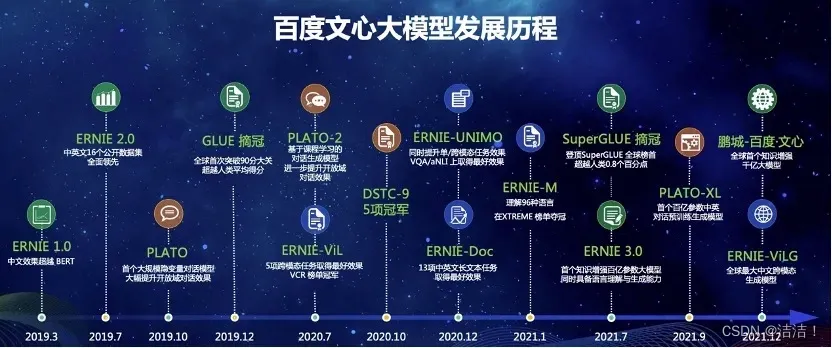
目前所指的大模型,是“大规模深度学习模型”的简称,指具有大量参数和复杂结构的机器学习模型,可以处理大规模的数据和复杂的问题,多应用于自然语言处理、计算机视觉、语音识别等领域。大模型具有更多的参数、更强的表达能力和更高的预测性能,对自然语言处理、计算机视觉和强化学习等任务产生了深远的影响。本文将探讨大模型的概念、训练技术和应用领域,以及与大模型相关的挑战和未来发展方向。

应用领域
首先来谈一谈大模型的·成就
大模型已经在许多应用领域取得了显著的成果,包括:
- 自然语言处理:
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration# 加载预训练模型和分词器
model = T5ForConditionalGeneration.from_pretrained('t5-base')
tokenizer = T5Tokenizer.from_pretrained('t5-base')# 输入文本
input_text = "Translate this text to French."# 分词和编码
input_ids = tokenizer.encode(input_text, return_tensors='pt')# 生成翻译
translated_ids = model.generate(input_ids)
translated_text = tokenizer.decode(translated_ids[0], skip_special_tokens=True)print("Translated Text:", translated_text)
- 计算机视觉:
import torch
import torchvision.models as models
import torchvision.transforms as transforms
from PIL import Image# 加载预训练模型和图像预处理
model = models.resnet50(pretrained=True)
preprocess = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加载图像
image = Image.open("image.jpg")# 图像预处理
input_tensor = preprocess(image)
input_batch = input_tensor.unsqueeze(0)# 使用GPU加速
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
input_batch = input_batch.to(device)# 前向传播
with torch.no_grad():output = model(input_batch)# 输出预测结果
_, predicted_idx = torch.max(output, 1)
predicted_label = predicted_idx.item()
print("Predicted Label:", predicted_label)
- 强化学习:
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F# 创建神经网络模型
class QNetwork(nn.Module):def __init__(self, state_size, action_size):super(QNetwork, self).__init__()self.fc1 = nn.Linear(state_size, 64)self.fc2 = nn.Linear(64, 64)self.fc3 = nn.Linear(64, action_size)def forward(self, x):x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x# 初始化环境和模型
env = gym.make('CartPole-v0')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
model = QNetwork(state_size, action_size)
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练过程
num_episodes = 100
for episode in range(num_episodes):state = env.reset()done = Falsewhile not done:# 选择动作state_tensor = torch.tensor(state, dtype=torch.float).unsqueeze(0)q_values = model(state_tensor)action = torch.argmax(q_values, dim=1).item()# 执行动作并观察结果next_state, reward, done, _ = env.step(action)# 计算损失函数next_state_tensor = torch.tensor(next_state, dtype=torch.float).unsqueeze(0)target_q_values = reward + 0.99 * torch.max(model(next_state_tensor))loss = F.mse_loss(q_values, target_q_values.unsqueeze(0))# 反向传播和优化器步骤optimizer.zero_grad()loss.backward()optimizer.step()state = next_state# 输出每个回合的总奖励print("Episode:", episode, "Reward:", reward)
- 推荐系统:
import torch
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
from torch.nn import Linear, ReLU, Softmax
import torch.optim as optim# 加载数据集
train_dataset = MNIST(root='.', train=True, download=True, transform=ToTensor())
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)# 创建推荐模型(多层感知机)
class Recommender(torch.nn.Module):def __init__(self):super(Recommender, self).__init__()self.flatten = torch.nn.Flatten()self.linear_relu_stack = torch.nn.Sequential(Linear(784, 512),ReLU(),Linear(512, 256),ReLU(),Linear(256, 10),Softmax(dim=1))def forward(self, x):x = self.flatten(x)logits = self.linear_relu_stack(x)return logitsmodel = Recommender()# 定义损失函数和优化器
loss_fn = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)# 训练过程
num_epochs = 10
for epoch in range(num_epochs):for batch, (images, labels) in enumerate(train_loader):# 前向传播outputs = model(images)loss = loss_fn(outputs, labels)# 反向传播和优化器步骤optimizer.zero_grad()loss.backward()optimizer.step()print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.item():.4f}")

什么是大模型?
大模型是指具有庞大参数数量的机器学习模型。传统的机器学习模型通常只有几百或几千个参数,而大模型则可能拥有数亿或数十亿个参数。这种巨大的模型规模赋予了大模型更强的表达能力和预测能力,可以处理更为复杂的任务和数据。
训练大模型的挑战
训练大模型需要应对一系列挑战,包括:
-
以下是与大模型相关的一些代码示例:
- 计算资源需求:
import tensorflow as tf# 指定使用GPU进行训练 with tf.device('/gpu:0'):# 构建大模型model = build_large_model()# 使用大量计算资源进行训练model.fit(train_data, train_labels, epochs=10, batch_size=128)- 数据集规模:
import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator# 创建ImageDataGenerator对象,用于数据增强和扩充 datagen = ImageDataGenerator(rotation_range=20,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,fill_mode='nearest' )# 加载大规模的图像数据集 train_generator = datagen.flow_from_directory('train_data/',target_size=(224, 224),batch_size=32,class_mode='categorical' )# 使用大规模的数据集进行训练 model.fit(train_generator, epochs=10)

- 优化算法:
import tensorflow as tf
from tensorflow.keras.optimizers import Adam# 构建大模型
model = build_large_model()# 使用改进后的优化算法(例如Adam)进行训练
optimizer = Adam(learning_rate=0.001)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])# 使用大规模的数据集进行训练
model.fit(train_data, train_labels, epochs=10, batch_size=128)
- 模型压缩与部署:
import tensorflow as tf
from tensorflow.keras.models import load_model
from tensorflow.keras.models import Model# 加载已经训练好的大模型
model = load_model('large_model.h5')# 进行模型压缩,例如剪枝操作
pruned_model = prune_model(model)# 保存压缩后的模型
pruned_model.save('pruned_model.h5')# 部署压缩后的模型,例如使用TensorRT进行加速
trt_model = convert_to_tensorrt(pruned_model)
trt_model.save('trt_model.pb')

如何训练大模型
为了克服训练大模型的挑战,研究人员提出了一些关键的技术:
-
以下是一些与上述技术相关的代码示例:
分布式训练:
import torch import torch.nn as nn import torch.optim as optim import torch.multiprocessing as mp from torch.nn.parallel import DistributedDataParallel as DDPdef train(rank, world_size):# 初始化进程组dist.init_process_group("gloo", rank=rank, world_size=world_size)# 创建模型并移至指定的计算设备model = MyModel().to(rank)ddp_model = DDP(model, device_ids=[rank])# 定义优化器和损失函数optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)criterion = nn.CrossEntropyLoss()# 模拟数据集dataset = MyDataset()sampler = torch.utils.data.distributed.DistributedSampler(dataset, num_replicas=world_size, rank=rank)dataloader = torch.utils.data.DataLoader(dataset, batch_size=64, shuffle=False, sampler=sampler)# 训练循环for epoch in range(10):for inputs, targets in dataloader:optimizer.zero_grad()outputs = ddp_model(inputs)loss = criterion(outputs, targets)loss.backward()optimizer.step()if __name__ == '__main__':world_size = 4 # 进程数量mp.spawn(train, args=(world_size,), nprocs=world_size)模型并行:
import torch import torch.nn as nn from torch.nn.parallel import DataParallelclass MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=3)self.conv2 = nn.Conv2d(64, 128, kernel_size=3)self.fc = nn.Linear(128 * 10 * 10, 10)def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = x.view(x.size(0), -1)x = self.fc(x [Something went wrong, please try again later.] -
数据并行示例:
import torch
import torch.nn as nn
from torch.nn.parallel import DataParallel# 创建模型
class MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.fc = nn.Linear(10, 5)def forward(self, x):return self.fc(x)model = MyModel()
model_parallel = DataParallel(model) # 默认使用所有可用的GPU进行数据并行input = torch.randn(16, 10) # 输入数据
output = model_parallel(input)
3.混合精度训练示例:
import torch
import torch.nn as nn
import torch.optim as optim
from apex import amp# 创建模型和优化器
model = MyModel()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 混合精度训练初始化
model, optimizer = amp.initialize(model, optimizer, opt_level="O2")# 训练循环
for epoch in range(10):for inputs, targets in dataloader:optimizer.zero_grad()# 使用混合精度进行前向和反向传播with amp.autocast():outputs = model(inputs)loss = criterion(outputs, targets)# 反向传播和优化器步骤scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()
4.模型压缩示例:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.utils.prune as prune# 创建模型并加载预训练权重
model = MyModel()
model.load_state_dict(torch.load('pretrained_model.pth'))# 剪枝
parameters_to_prune = ((model.conv1, 'weight'), (model.fc, 'weight'))
prune.global_unstructured(parameters_to_prune,pruning_method=prune.L1Unstructured,amount=0.5,
)# 量化
model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
torch.quantization.prepare(model, inplace=True)
model.eval()
model = torch.quantization.convert(model, inplace=True)# 低秩分解
parameters_to_low_rank = ((model.conv1, 'weight'), (model.fc, 'weight'))
for module, name in parameters_to_low_rank:u, s, v = torch.svd(module.weight.data)k = int(s.size(0) * 0.1) # 保留前10%的奇异值module.weight.data = torch.mm(u[:, :k], torch.mm(torch.diag(s[:k]), v[:, :k].t()))# 训练和优化器步骤
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
criterion = nn.CrossEntropyLoss()
未来发展
尽管大模型在各个领域都取得了重要的进展,但仍然有很多挑战需要解决。未来的发展方向可能包括:
- 更高效的训练算法:研究人员将继续致力于开发更高效、可扩展的训练算法,以加快大模型的训练速度。
- 更智能的模型压缩技术:模型压缩和加速技术将继续发展,以减小大模型的计算和存储开销。
- 更好的计算平台支持:为了支持训练和部署大模型,计算平台将继续改进,提供更强大的计算资源和工具。
- 更好的跨模态应用:特别是在大场景下的表现能力十分突出。正在经历智能化、制造革新的“车”,就有不少可以展开无限想象的大模型应用场景。




















