网络地址转换(NAT,Network Address Translation)属接入广域网(WAN)技术,是一种将私有(保留)地址转化为合法IP地址的转换技术。下面介绍两类不同方式实现的NAT:
- NAT(Network Address Translators):称为基本的NAT
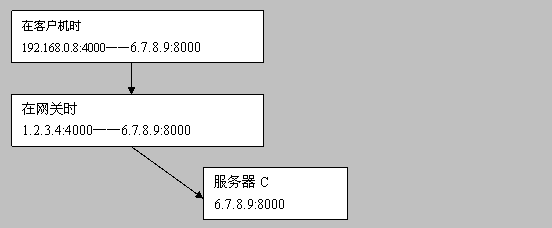
在客户机时 192.168.0.8:4000——6.7.8.9:8000
在网关时 1.2.3.4:4000——6.7.8.9:8000
服务器C 6.7.8.9:8000
其核心是替换IP地址而不是端口,这会导致192.168.0.8使用4000端口后,192.168.0.9如何处理?具体参考RFC 1631
基本上这种类型的NAT设备已经很少了。或许根本我们就没机会见到。
2. NAPT(Network Address/Port Translators):其实这种才是我们常说的 NAT
NAPT的特点是在网关时,会使用网关的 IP,但端口会选择一个和临时会话对应的临时端口。如下图:
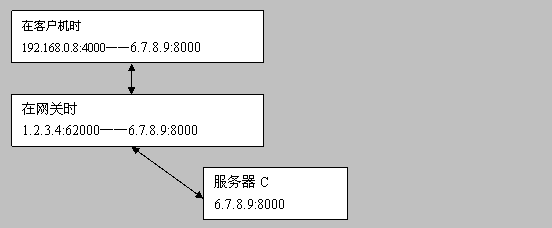
在客户机时 192.168.0.8:4000——6.7.8.9:8000
在网关时 1.2.3.4:62000——6.7.8.9:8000
服务器C 6.7.8.9:8000
网关上建立保持了一个1.2.3.4:62000的会话,用于192.168.0.8:4000与6.7.8.9:8000之间的通讯。
对于NAPT,又分了两个大的类型,差别在于,当两个内网用户同时与8000端口通信的处理方式不同:
2.1、Symmetric NAT型 (对称型)
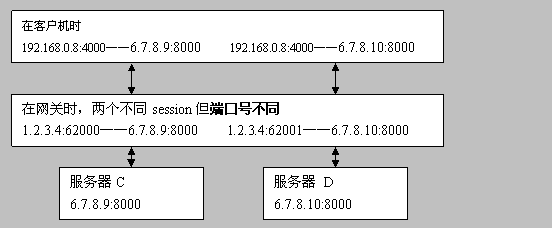
在客户机时 192.168.0.8:4000——6.7.8.9:8000 192.168.0.8:4000——6.7.8.10:8000
在网关时,两个不同session但端口号不同 1.2.3.4:62000——6.7.8.9:8000 1.2.3.4:62001——6.7.8.10:8000
服务器C 6.7.8.9:8000
服务器 D 6.7.8.10:8000
这种形式会让很多p2p软件失灵。
2.2、Cone NAT型(圆锥型)
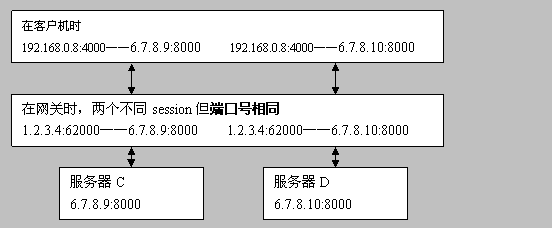
在客户机时 192.168.0.8:4000——6.7.8.9:8000 192.168.0.8:4000——6.7.8.10:8000
在网关时,两个不同session但端口号相同 1.2.3.4:62000——6.7.8.9:8000 1.2.3.4:62000——6.7.8.10:8000
服务器C 6.7.8.9:8000
服务器D 6.7.8.10:8000
目前绝大多数属于这种。Cone NAT又分了3种类型:
- a)Full Cone NAT(完全圆锥型):从同一私网地址端口192.168.0.8:4000发至公网的所有请求都映射成同一个公网地址端口1.2.3.4:62000 ,192.168.0.8可以收到任意外部主机发到1.2.3.4:62000的数据报。
- b)Address Restricted Cone NAT (地址限制圆锥型):从同一私网地址端口192.168.0.8:4000发至公网的所有请求都映射成同一个公网地址端口1.2.3.4:62000,只有当内部主机192.168.0.8先给服务器C 6.7.8.9发送一个数据报后,192.168.0.8才能收到6.7.8.9发送到1.2.3.4:62000的数据报。
- c)Port Restricted Cone NAT(端口限制圆锥型):从同一私网地址端口192.168.0.8:4000发至公网的所有请求都映射成同一个公网地址端口1.2.3.4:62000,只有当内部主机192.168.0.8先向外部主机地址端口6.7.8.9:8000发送一个数据报后,192.168.0.8才能收到6.7.8.9:8000发送到1.2.3.4:62000的数据报。
穿越NAT的实现
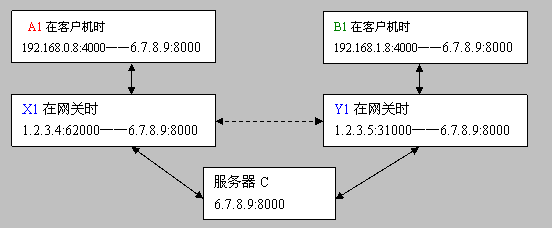
A1在客户机时 192.168.0.8:4000——6.7.8.9:8000
X1在网关时 1.2.3.4:62000——6.7.8.9:8000
服务器C 6.7.8.9:8000
B1在客户机时 192.168.1.8:4000——6.7.8.9:8000
Y1在网关时 1.2.3.5:31000——6.7.8.9:8000
两内网用户要实现通过各自网关的直接呼叫,需要以下过程:
1、 客户机A1、B1顺利通过格子网关访问服务器C ,均没有问题(类似于登录)
2、 服务器C保存了 A1、B1各自在其网关的信息(1.2.3.4:62000、1.2.3.5:31000)没有问题。并可将该信息告知A1、B2。
3、 此时A1发送给B1网关的1.2.3.5:31000是否会被B1收到?答案是基本上不行(除非Y1设置为完全圆锥型,但这种设置非常少),因为Y1上检测到其存活的会话中没有一个的目的IP或端口于1.2.3.4:62000有关而将数据包全部丢弃!
4、 此时要实现A1、B1通过X1、Y1来互访,需要服务器C告诉它们各自在自己的网关上建立“UDP隧道”,即命令A1发送一个 192.168.0.8:4000——1.2.3.5:31000的数据报,B1发送一个192.168.1.8:4000——1.2.3.4:62000的数据报,UDP形式,这样X1、Y1上均存在了IP端口相同的两个不同会话(很显然,这要求网关为Cone NAT型,否则,对称型Symmetric NAT设置网关将导致对不同会话开启了不同端口,而该端口无法为服务器和对方所知,也就没有意义)。
5、 此时A1发给Y1,或者B1发给X1的数据报将不会被丢弃且正确的被对方收到.
综合P2P可实现的条件需要:
1、 中间服务器保存信息、并能发出建立UDP隧道的命令
2、 网关均要求为Cone NAT类型。Symmetric NAT不适合。
3、 完全圆锥型网关可以无需建立udp隧道,但这种情况非常少,要求双方均为这种类型网关的更少。
4、 假如X1网关为Symmetric NAT, Y1为Address Restricted Cone NAT 或Full Cone NAT型网关,各自建立隧道后,A1可通过X1发送数据报给Y1到B1(因为Y1最多只进行IP级别的甄别),但B2发送给X1的将会被丢弃(因为发送来的数据报中端口与X1上存在会话的端口不一致,虽然IP地址一致),所以同样没有什么意义。
5、 假如双方均为Symmetric NAT的情形,新开了端口,对方可以在不知道的情况下尝试猜解,也可以达到目的,但这种情形成功率很低,且带来额外的系统开支,不是个好的解决办法。
6、 不同网关型设置的差异在于,对内会采用替换IP的方式、使用不同端口不同会话的方式,使用相同端口不同会话的方式;对外会采用什么都不限制、限制IP地址、限制IP地址及端口。
7、 这里还没有考虑同一内网不同用户同时访问同一服务器的情形,如果此时网关采用AddressRestricted Cone NAT 或Full Cone NAT型,有可能导致不同用户客户端可收到别人的数据包,这显然是不合适的。
UDP和TCP打洞
为什么网上讲到的P2P打洞基本上都是基于UDP协议的打洞?难道TCP不可能打洞?还是TCP打洞难于实现?
假设现在有内网客户端A和内网客户端B,有公网服务端S。
如果A和B想要进行UDP通信,则必须穿透双方的NAT路由。假设为NAT-A和NAT-B。
A发送数据包到公网S,B发送数据包到公网S,则S分别得到了A和B的公网IP,
S也和A B 分别建立了会话,由S发到NAT-A的数据包会被NAT-A直接转发给A,
由S发到NAT-B的数据包会被NAT-B直接转发给B,除了S发出的数据包之外的则会被丢弃。
所以:现在A B 都能分别和S进行全双工通讯了,但是A B之间还不能直接通讯。
解决办法是:A向B的公网IP发送一个数据包,则NAT-A能接收来自NAT-B的数据包
并转发给A了(即B现在能访问A了);再由S命令B向A的公网IP发送一个数据包,则
NAT-B能接收来自NAT-A的数据包并转发给B了(即A现在能访问B了)。以上就是“打洞”的原理。
为了保证A的路由器有与B的session,A要定时与B做心跳包,同样,B也要定时与A做心跳,这样,双方的通信通道都是通的,就可以进行任意的通信了。
但是TCP和UDP在打洞上却有点不同。这是因为伯克利socket(标准socket规范)的
API造成的。
UDP的socket允许多个socket绑定到同一个本地端口,而TCP的socket则不允许。
这是这样一个意思:A B要连接到S,肯定首先A B双方都会在本地创建一个socket,
去连接S上的socket。创建一个socket必然会绑定一个本地端口(就算应用程序里面没写
端口,实际上也是绑定了的,至少java确实如此),假设为8888,这样A和B才分别建立了到
S的通信信道。接下来就需要打洞了,打洞则需要A和B分别发送数据包到对方的公网IP。但是
问题就在这里:因为NAT设备是根据端口号来确定session,如果是UDP的socket,A B可以
分别再创建socket,然后将socket绑定到8888,这样打洞就成功了。但是如果是TCP的
socket,则不能再创建socket并绑定到8888了,这样打洞就无法成功。
TCP打洞技术:
tcp打洞也需要NAT设备支持才行。
tcp的打洞流程和udp的基本一样,但tcp的api决定了tcp打洞的实现过程和udp不一样。
tcp按cs方式工作,一个端口只能用来connect或listen,所以需要使用端口重用,才能利用本地nat的端口映射关系。(设置SO_REUSEADDR,在支持SO_REUSEPORT的系统上,要设置这两个参数。)
连接过程:(以udp打洞的第2种情况为例(典型情况))
nat后的两个peer,A和B,A和B都bind自己listen的端口,向对方发起连接(connect),即使用相同的端口同时连接和等待连接。因为A和B发出连接的顺序有时间差,假设A的syn包到达B的nat时,B的syn包还没有发出,那么B的nat映射还没有建立,会导致A的连接请求失败(连接失败或无法连接,如果nat返回RST或者icmp差错,api上可能表现为被RST;有些nat不返回信息直接丢弃syn包(反而更好)),(应用程序发现失败时,不能关闭socket,closesocket()可能会导致NAT删除端口映射;隔一段时间(1-2s)后未连接还要继续尝试);但后发B的syn包在到达A的nat时,由于A的nat已经建立的映射关系,B的syn包会通过A的nat,被nat转给A的listen端口,从而进去三次握手,完成tcp连接。
从应用程序角度看,连接成功的过程可能有两种不同表现:(以上述假设过程为例)
1、连接建立成功表现为A的connect返回成功。即A端以TCP的同时打开流程完成连接。
2、A端通过listen的端口完成和B的握手,而connect尝试持续失败,应用程序通过accept获取到连接,最终放弃connect(这时可closesocket(conn_fd))。
多数Linux和Windows的协议栈表现为第2种。
但有一个问题是,建立连接的client端,其connect绑定的端口号就是主机listen的端口号,或许这个peer后续还会有更多的这种socket。虽然理论上说,socket是一个五元组,端口号是一个逻辑数字,传输层能够因为五元组的不同而区分开这些socket,但是是否存在实际上的异常,还有待更多观察。
另外的问题:
1、Windows XP SP2操作系统之前的主机,这些主机不能正确处理TCP同时开启,或者TCP套接字不支持SO_REUSEADDR的参数。需要让AB有序的发起连接才可能完成。
上述tcp连接过程,仅对NAT1、2、3有效,对NAT4(对称型)无效。
由于对称型nat通常采用规律的外部端口分配方法,对于nat4的打洞,可以采用端口预测的方式进行尝试。
一些现在常用的技术:
ALG(应用层网关):它可以是一个设备或插件,用于支持SIP协议,主要类似与在网关上专门开辟一个通道,用于建立内网与外网的连接,也就是说,这是一种定制的网关。更多只适用于使用他们的应用群体内部之间。
UpnP:它是让网关设备在进行工作时寻找一个全球共享的可路由IP来作为通道,这样避免端口造成的影响。要求设备支持且开启upnp功能,但大部分时候,这些功能处于安全考虑,是被关闭的。即时开启,实际应用效果还没经过测试。
STUN(Simple Traversalof UDP Through Network):这种方式即是类似于我们上面举例中服务器C的处理方式。也是目前普遍采用的方式。但具体实现要比我们描述的复杂许多,光是做网关Nat类型判断就由许多工作,RFC3489中详细描述了。
TURN(Traveral Using Relay NAT):该方式是将所有的数据交换都经由服务器来完成,这样NAT将没有障碍,但服务器的负载、丢包、延迟性就是很大的问题。目前很多游戏均采用该方式避开NAT的问题。这种方式不叫p2p。
ICE(Interactive Connectivity Establishment):是对上述各种技术的综合,但明显带来了复杂性。
-协同过滤1-UserCF、ItemCF)
)

-关联规则分析)

)
)

-协同过滤2-矩阵分解算法)




-VectorNet- Encoding HD Maps and Agent Dynamics from Vectorized Representation)


跨域解决方法)
-逻辑回归LR、POLY2、FM、FFM)

