高并发分布式开发技术体系已然非常的庞大,从国内互联网企业使用情况,可发现RPC、Dubbo、ZK是最基础的技能要求。关于Zookeeper你是不是还停留在Dubbo注册中心的印象中呢?还有它的工作原理呢?经典应用场景呢?对前面三个问题,如若回答时没有自己的思路或者说并未了解,那么我觉得我可以帮助到你去入门,并深化这些知识,让你在面试中更好地去回答。
话不多说进入正题
1. 并发环境下面临的挑战
回忆我们学多线程的时候,网上有个图也是十分的有意思
其实我们把线程换成进程,相当于每台服务上跑了一个程序,相同的应用程序运行于多个服务器集群上,是为了解决单台服务面对高并发处理不来的情况。而尝试去处理这些情况,我们就会面临很多诸如此类的问题
比如说我们现在是3台服务器的一个集群, 怎么保证所有机器共享的配置信息保持一致?
有一台机器挂掉了,其他机器如何感知到这一变化并接管任务?
用户量突然的爆增,需要增加机器来缓解压力,如何做到不重启集群而完成机器的添加?
分布式系统,怎么高效协同多台服务对同一网络文件进行写操作(网络并不是即时的,它并不可靠,存在延时)?
此时我们就需要一个类似于线程协同机制的能让进程进行协同的工具
2. Zookeeper的介绍
① Zookeeper的名字由来
在apache上的许多开源项目都是以动物形象作为icon,比如tomcat就是一只猫,hive是只黄蜂等,zookeeper的工作就是把这些动物的行动进行协调
② Zookeeper的简介
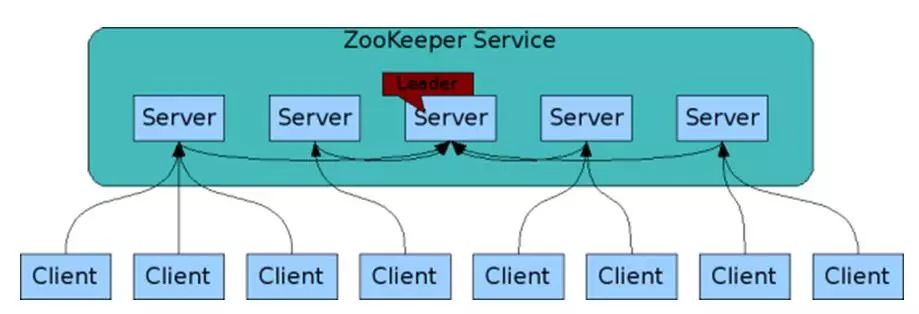
zookeeper就是一种用于分布式应用程序的高性能协调服务,它的特点就是数据是存于内存中的,持久化实现在日志中。它的内存类似于树形结构,且高吞吐低延迟,可以帮助我们实现分布式统一配置中心,服务注册,分布式锁等 组成ZooKeeper服务的服务器必须彼此了解。它们维护内存中的状态图像,以及持久性存储中的事务日志和快照。只要大多数服务器可用,ZooKeeper服务就可用。客户端连接到单个ZooKeeper服务器。客户端维护TCP连接,通过该连接发送请求,获取响应,获取监视事件以及发送tick。如果与服务器的TCP连接中断,则客户端将连接到其他服务器。
③ Zookeeper的安装(linux下)
1.JDK版本需要在1.6以上
2.下载:https://archive.apache.org/dist/zookeeper/zookeeper-3.5.2/zookeeper-3.5.2.tar.gz
3.解压后的conf目录,增加配置文件zoo.cfg
4.启动服务端 bin/zkServer.sh start
5.测试,客户端连接:bin/zkCli.sh -server 127.0.0.1:2181
zoo.cfg的关键配置有3个:tickTime=2000:一次心跳的基本时间,dataDir:数据与日志的存放处clientPort:端口号④ Zookeeper的特点
1.数据结构简单
类似于Unix文件系统树形结构,每个目录成为Znode节点,但它不同于文件系统,它既可以视为文件夹,也可以视为文件来存放数据,但是我们平时还是得叫它节点,别叫文件夹这么掉价。
需要注意:同一个节点下的子节点名称不能相同,且命名是有规范的,它的路径是没有相对路径的概念的,都是绝对路径,任何开始都以"/"开始,最后就是,它存放数据的大小是有限制的
2.数据模型特点
层次命名空间:就是上面已经提到的,类似于unix的文件系统,以"/"为根,节点可以包含关联数据和子节点,绝对路径 Znode:名称唯一,命名有规范,类型分4种:持久,顺序,临时,临时顺序,节点的数据构成之后再提
3.命名规范
节点名称除下列限制外,可以使用任何unicode字符:
1. null字符(u0000)不能作为路径名的一部分;
2. 以下字符不能使用,因为它们不能很好地显示,或者以令人困惑的方式呈现:u0001 - u0019和u007F - u009F。
3. 不允许使用以下字符:ud800 - uf8fff, uFFF0 - uFFFF。
4. “.”字符可以用作另一个名称的一部分,但是“.”和“..”不能单独用于指示路径上的节点,因为ZooKeeper不使用相对路径。
下列内容无效:“/a/b/. / c”或“c / a / b / . . /”。
5. “zookeeper”是保留节点名。
4.一些命令
因为我的电脑是window系统的,所以我找了一个window版本的zookeeper来进行演示
先大致解释一下各个目录的内容
bin ---> 包括了linux和window的运行程序的运行目录
conf ---> zookeeper的配置zoo.cfg
contrib ---> 其他一些组件和发行版本
dist-maven ---> maven发布下的一些jar包
docs ---> 文档
lib ---> 库
recipe ---> 一些应用实例
src ---> zookeeper的源码,因为zookeeper是java写出来的
启动bin目录下的zkServer.cmd,再启动zkClient.cmd即可,在我根本不知道该如何进行学习的时候,一般来说输入help,-help,-h这些指令就可以获取到帮助,下图我就是在客户端输入了-help指令
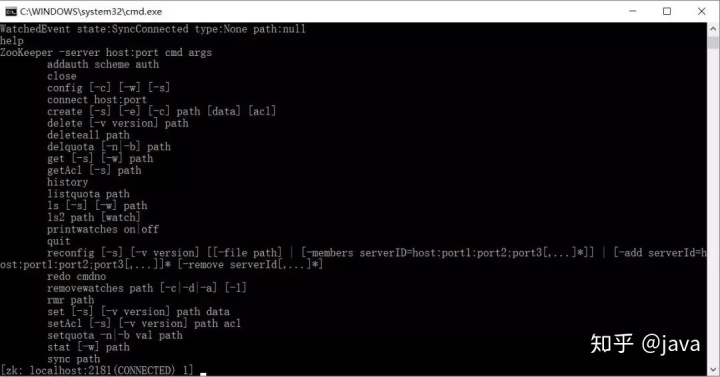
因为命令都相对简单所以也不进行演示了,唯一需要注意的是要注意路径"/"的问题,比如 ls / 就是根目录,create /zk 123,还有各个命令的依托条件,比如create必须要提供父节点,delete节点时次节点不能有子节点等···
5.Zookeeper的重要特点---有序
提供多种方式跟踪时间,ZooKeeper给每个更新贴上一个数字,这个数字反映了所有ZooKeeper事务的顺序,严格的顺序意味着可以在客户机上实现复杂的同步原语 解释czxid、version、zoo.cfg中ticks配置
Zxid :Zookeeper中每次写请求都对应一个唯一的事务id,称为 Zxid,它是全局的且有序的,如果 Zxid1 小于 Zxid2,那 Zxid1 就一定是发生在 Zxid2 前
version numbers :版本号,对节点的写请求都会导致该节点的3种版本号增加(其实套路和乐观锁差不多),dataVersion(对znode数据的更改次数),cversion(对znode子节点的更改次数),aclVersion(对znode ACL的更改次数
ticks :当使用多服务器Zookeeper时,服务器使用一个“滴答”来定义事件的时间,如状态上传,会话超时等,它通过最小会话超时(默认是滴答时间x2)间接公开,如果客户端请求超过这个时间,那客户端就不再能连接上服务器端
real time:Zookeeper并不使用真实时间
你可以使用stat path或者ls2来查看这些信息
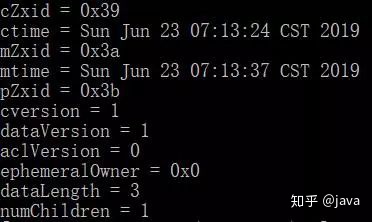
cZxid:创建该节点的zxid
ctime:该节点的创建时间
mZxid:该节点的最后修改zxid
mtime:该节点的最后修改时间
pZxid:该节点的最后子节点修改zxid
cversion:该节点的子节点变更次数
dataVersion:该节点数据被修改的次数
aclVersion:该节点的ACL变更次数
aphemeraOwner:临时节点所有者会话id,非临时的为0
dataLength:该节点数据长度
numChildren:子节点数
这些数据都在从侧面告诉我们,zookeeper是一个协调者
6.zookeeper的第二个特点---可复制
数据可复制,可备份。zookeeper可以快速地搭建一个集群,内部自带了这样的一些工具与机制,我们只需要设置一些配置即可,保证服务可靠,不会成为单点故障
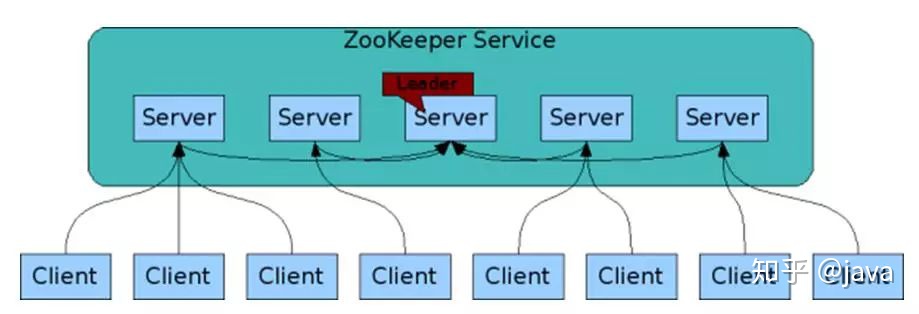
7.zookeeper的第三个特点---迅速
zookeeper的一些特点可以应用于大型分布式系统

3.zookeeper的理论
① zookeeper的会话机制
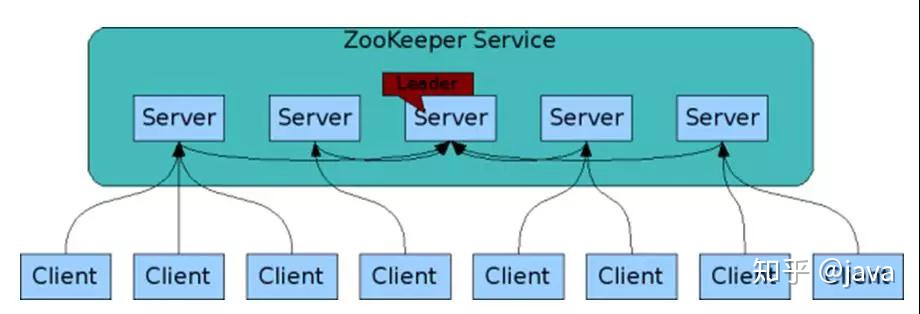
Session会话
1.一个客户端连接一个会话,由zookeeper分配唯一会话id
2.客户端以特定的时间间隔发送心跳以保持会话有效,
3.超过会话超时时间未收到客户端的心跳,则判断客户端无效(默认2倍tickTime)
4.会话中额请求是FIFO(先进先出原则)的顺序执行
② znode的数据构成
节点数据:存储的基本信息(状态,配置,位置等)
节点元数据:stat命令下的一些数据
数据大小:限制1M
③ znode的节点类型
1.持久节点:直接通过create path value所创建
2.临时节点:create -e path value
3.顺序节点:create -s path value
注意
1.session会话失效时,临时节点就会被删除
2.顺序节点的创建,后为10位十进制序号,每个父节点拥有一个计数器,这个计数器也是有限制的,到2147483647之后将溢出
3.顺序节点在会话结束仍然存在
④ Watch监听机制
客户端能在znodes上设置watch,监听znode的变化,包括增删改查,通过stat path ,ls2 path get path皆可查看
触发watch事件的条件有4种,create,delete,change,child(子节点事件)
watch的重要特性
1.仅一次性:watch触发后会立即删除,要持续监听变化的话就要持续提供设置watch,这也是watch的注意事项
2.有序性:客户端先得到watch通知才可查看变化结果
watch的注意事项
1.刚刚提及到的它的仅一次性
2.获取事件和发送watch,获取watch,这些请求有可能存在延时,所以不能绝对可靠得到每个节点发生的每个更改
3.一个watch对象只会被通知一次,如果一个watch同时注册了多个接口(exists,getData),如果此时删除节点,虽然这个事件对exists和getData都有效,但是watch只会被调用一次
阻塞线程唤醒机制—客户端可以被动接受其他客户端进程状态通知
⑤ zookeeper的特性
1.顺序一致性(Sequential Consistency),保证客户端操作是按顺序生效的;
2.原子性(Atomicity),更新成功或失败。没有部分结果。
3.单个系统映像,无论连接到哪个服务器,客户端都将看到相同的内容
4.可靠性,数据的变更不会丢失,除非被客户端覆盖修改。
5.及时性,保证系统的客户端当时读取到的数据是最新的。
finally
通过上面的阐述应该我们对于zookeeper有了一个初步的认识,之后会陆续说说分布式锁,集群还有一些场景的应用
原文作者 | 说出你的愿望吧
原文链接 | http://juejin.im/post/5d0bd358e51d45105e0212db

——定义导航菜单)
——分页实现)



——Json格式化)

——权限管理)

——扩展AbpSession)

——编写单元测试)

——如何升级Abp并调试源码)

——Redis缓存用起来)
)
——应用BootstrapTable表格插件)
