1.忍受大法
第一种解决办法,很简单,无他,不管他,没有读到也没事。这时业务不需要任何改造,你好,我好,她也好~
如果业务对于数据一致性要求不高,我们就可以采用这种方案。
2.数据同步写方案
主从数据同步方案,一般都是采用的异步方式同步给备库。
我们可以将其修改为同步方案,主从同步完成,主库上的写才能返回。
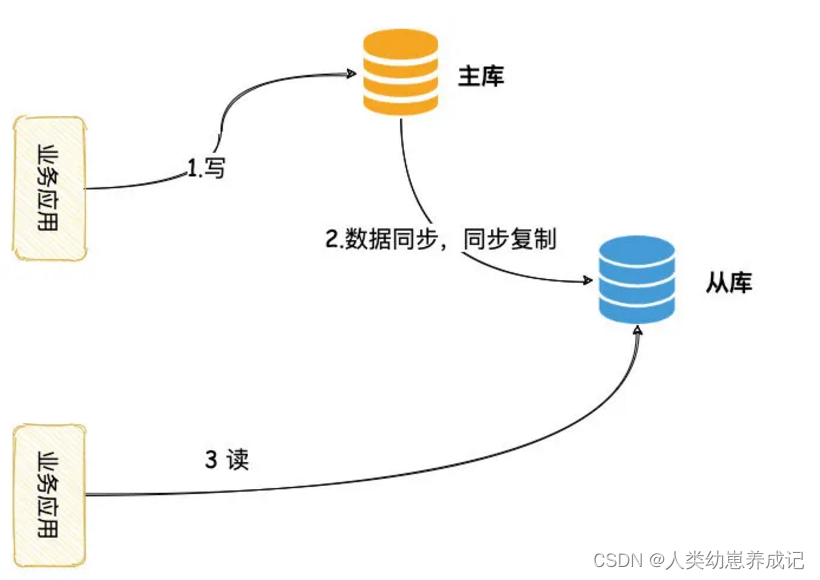
- 业务系统发起写操作,数据写主库
- 写请求需要等待主从同步完成才能返回
- 数据读从库,主从同步完成就能读到最新数据
这种方案,我们只需要修改数据库之间同步配置即可,业务层无需修改,相对简单。
「不过,由于主库写需要等待主从完成,写请求的时延将会增加,吞吐量将会降低。」
这一点对于现在在线业务,可能无法接受。
3.选择性强制读主
对于需要强一致的场景,我们可以将其的读请求都操作主库,这样「读写都在主库」,就没有不一致的情况。
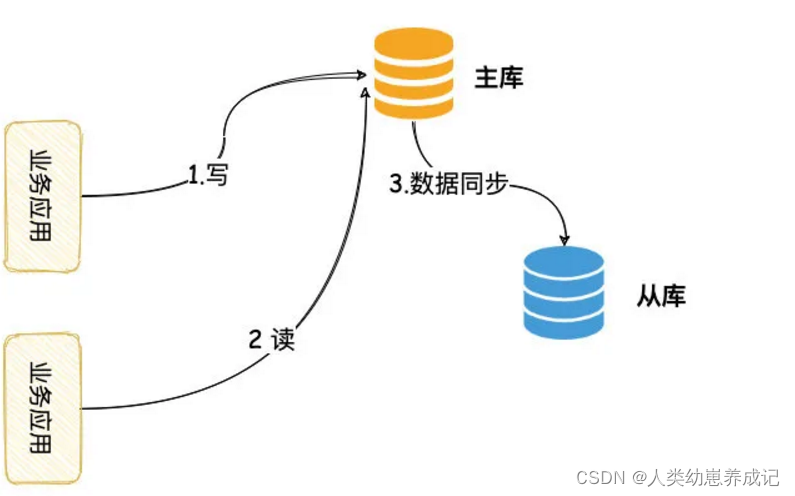
这种方案业务层需要改造一下,将其强制性读主,相对改造难度较低。
不过这种方案相对于浪费了另一个数据库,增加主库的压力。
4.中间件选择路由法
这种方案需要使用一个中间件,所有数据库操作都先发到中间件,由中间件再分发到相应的数据库。
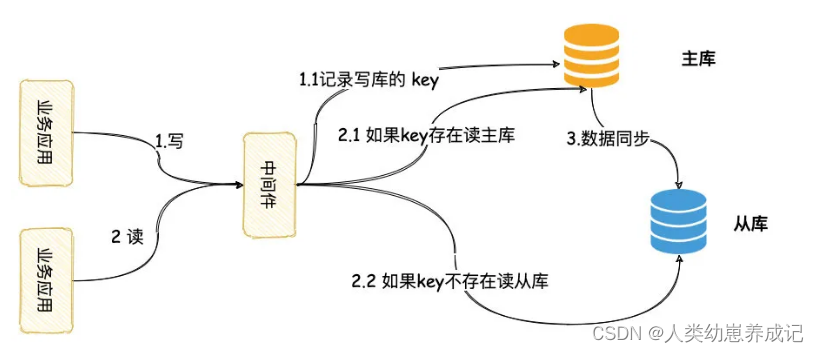
这时流程如下:
- 写请求,中间件将会发到主库,同时记录一下此时写请求的 key(操作表加主键等)
- 读请求,如果此时 key 存在,将会路由到主库
- 一定时间后(经验值),中间件认为主从同步完成,删除这个 key,后续读将会读从库
这种方案,可以保持数据读写的一致。
但是系统架构增加了一个中间件,整体复杂度变高,业务开发也变得复杂,学习成本也比较高。
5.缓存路由大法
这种方案与中间件的方案流程比较类似,不过改造成本相对较低,不需要增加任何中间件。

这时流程如下:
- 写请求发往主库,同时缓存记录操作的 key,缓存的失效时间设置为主从的延时
- 读请求首先判断缓存是否存在
-
- 若存在,代表刚发生过写操作,读请求操作主库
- 若不存在,代表近期没发生写操作,读请求操作从库
这种方案相对中间件的方案成本较低,但是呢我们此时又引入一个缓存组件,所有读写之间就又多了一步缓存操作。
总结
我们引入主从架构,数据读写分离,目的是为了解决业务快速发展,请求量变大,并发量变大,从而引发的数据库的读瓶颈。
不过当引入新一个架构解决问题时,势必会带来另外一个问题,数据库读写分离之后,主从延迟从而导致数据不一致的情况。,
为了解决主从延迟,数据不一致的情况,我们可以采用以下这几种方案:
- 忍受大法
- 数据库同步写方案
- 选择性强制读主
- 中间件选择路由法
- 缓存路由大法


)
)
——介绍和基本概念)
——详解线程的开始和创建)
——线程池)

——APM初探)

- C# ConcurrentBag的实现原理)

- 浅析C# Dictionary实现原理)




)

