任务并行库 (TPL) 是 .NET Framework 4的 System.Threading 和 System.Threading.Tasks 命名空间中的一组公共类型和 API。TPL的目的在于简化向应用程序中添加并行性和并发性的过程,从而提高开发人员的工作效率。TPL会动态地按比例调节并发程度,以便最有效地使用所有可用的处理器。此外,TPL还处理工作分区、ThreadPool 上的线程调度、取消支持、状态管理以及其他低级别的细节操作。通过使用TPL,您可以在将精力集中于程序要完成的工作,同时最大程度地提高代码的性能。
从 .NET Framework 4 开始,TPL 是编写多线程代码和并行代码的首选方法。但是,并不是所有代码都适合并行化;例如,如果某个循环在每次迭代时只执行少量工作,或它在很多次迭代时都不运行,那么并行化的开销可能导致代码运行更慢。此外,像任何多线程代码一样,并行化会增加程序执行的复杂性(容易产生bug)。尽管 TPL 简化了多线程方案,但我们建议您对线程处理概念(例如,锁、死锁和争用条件《异步编程:同步基元对象(上)》)进行基本的了解,以便能够有效地使用 TPL。
示例:异步编程:.NET4.X数据并行.rar
传送门:异步编程系列目录……
本主题分两部分讲解:
《异步编程:.NET4.X任务并行》
《异步编程:.NET4.X 数据并行》,本节所述内容:
并发与并行
首先,我们要理解并发与并行的区别:
在理解和设计支持多核操作时,我们可以借用甘特图来帮助我们更清晰地知道多任务的运行情况,常用的甘特图软件有:GanttProject 、翰文横道图编制系统、Microsoft Office Project。
并发:一个处理器在“同一时段(时间间隔)”处理多个任务,各个任务之间快速交替执行。如图:
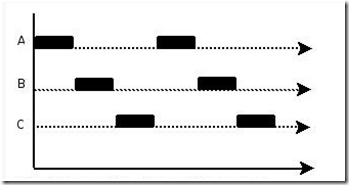
并行:多个处理器或者多核的处理器“同一时刻(时间点)”处理多个不同的任务。并行是真正的细粒度上的同时进行,既同一时间点上同时发生着多个并发。并行一定是并发,而并发不一定是并行。如图:

数据并行
数据并行是指对源集合或数组中的元素同时(即并行)执行相同操作的情况。
先稍微了解下Action和Func委托,此两委托由微软提供;Action是一个没有返回参数的委托,Func是一个有返回值的委托。
并行循环
当并行循环运行时,TPL会将数据源按照内置的分区算法(或者你可以自定义一个分区算法)将数据划分为多个不相交的子集,然后,从线程池中选择线程并行地处理这些数据子集,每个线程只负责处理一个数据子集。在后台,任务计划程序将根据系统资源和工作负荷来对任务进行分区。如有可能,计划程序会在工作负荷变得不平衡的情况下在多个线程和处理器之间重新分配工作。
在对任何代码(包括循环)进行并行化时,一个重要的目标是利用尽可能多的处理器,但不要过度并行化到使行处理的开销让任何性能优势消耗殆尽的程度。比如:对于嵌套循环,只会对外部循环进行并行化,原因是不会在内部循环中执行太多工作。少量工作和不良缓存影响的组合可能会导致嵌套并行循环的性能降低。
由于循环体是并行运行的,迭代范围的分区是根据可用的逻辑内核数、分区大小以及其他因素动态变化的,因此无法保证迭代的执行顺序。
1. Parallel.For
为固定数目的独立For循环迭代提供了负载均衡的潜在并行执行。Parallel内部通过RangeManger对象实现负载均衡。
负载均衡的执行会尝试将工作分发在不同的任务中,这样所有的任务在大部分时间内部可以保持繁忙。负载均衡总是试图减少任务的闲置时间。
| 1 2 3 4 5 6 7 8 9 | public static ParallelLoopResult For(int fromInclusive, int toExclusive , ParallelOptions parallelOptions, Action<int, ParallelLoopState> body); // 执行具有线程本地数据的 for 循环,泛型类型参数TLocal为本地线程数据类型。public static ParallelLoopResult For<TLocal>(int fromInclusive, int toExclusive , ParallelOptions parallelOptions , Func<TLocal> localInit , Func<int, ParallelLoopState, TLocal, TLocal> body , Action<TLocal> localFinally ); |
参数:
1) 返回ParallelLoopResult结构
System.Threading.Tasks.ParallelLoopResult是结构体,当所有线程均已完成时,For 将返回 ParallelLoopResult 对象。若你手动停止或中断循环迭代时,此返回值特别有用,因为 ParallelLoopResult 存储诸如完成运行的最后一个迭代等信息。
| 1 2 3 4 5 6 7 | public struct ParallelLoopResult { // 获取该循环是否已运行完成。 public bool IsCompleted { get; } // 获取从中调用 ParallelLoopState.Break() 的最低迭代的索引。 public long? LowestBreakIteration { get; }} |
l 如果 IsCompleted 返回 true,该循环的所有迭代均已执行,并且该循环没有收到提前结束的请求.
l 如果 IsCompleted 返回 false:
i. LowestBreakIteration 返回 null,则为调用 ParallelLoopState.Stop() 提前结束循环。
ii. LowestBreakIteration 返回非 null 整数值,则为调用 ParallelLoopState.Break() 提前结束循环。
2) 迭代范围
对于迭代范围(fromInclusive<= x <toExclusive)中的每个值调用一次body委托。如果 fromInclusive 大于或等于 toExclusive,则该方法立即返回,而无需执行任何迭代。
3) ParallelOptions类型
ParallelOptions实例存储用于配置 Parallel 类的方法的操作的选项。
| 1 2 3 4 5 6 7 8 9 10 | public class ParallelOptions { public ParallelOptions(); // 获取或设置与此 ParallelOptions 实例关联的 CancellationToken。 public CancellationToken CancellationToken { get; set; } // 获取或设置此 ParallelOptions 实例所允许的最大并行度。 public int MaxDegreeOfParallelism { get; set; } // 获取或设置与此 ParallelOptions 实例关联的 TaskScheduler。 public TaskScheduler TaskScheduler { get; set; }} |
a) 提供一个无参数的构造函数,此构造函数使用默认值初始化实例。MaxDegreeOfParallelism 初始化为 -1,表示并行量没有上限设置;CancellationToken 初始化为CancellationToken.None不可取消的标记;TaskScheduler 初始化为默认计划程序 (TaskScheduler.Default)。(CancellationToken取消示例请看章节”协作式取消”)
b) 指定最大并行度
有时候,你并不希望在并行循环中使用所有的内核,因为你对剩余的内核有特定的需求和更好的使用计划。
通常指定Environment.ProcessorCount,或者是根据此值计算出来的值(eg:Environment.ProcessorCount-1)。默认情况下,如果没有指定最大并行度,TPL就会允许通过启发式算法提高或降低线程的数目,通常这样会高于ProcessorCount,因为这样可以更好地支持CPU和I/O混合型的工作负荷。
4) ParallelLoopState类型
可用来使 Tasks.Parallel 循环的迭代与其他迭代交互,并为 Parallel 类的循环提供提前退出循环的功能。此类的实例不要自行创建,它由 Parallel 类创建并提供给每个循环项,并且只应该在提供此实例的“循环内部”使用。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | public class ParallelLoopState{ // 获取循环的任何迭代是否已引发相应迭代未处理的异常。 public bool IsExceptional { get; } // 获取循环的任何迭代是否已调用 ParallelLoopState.Stop()。 public bool IsStopped { get; } // 获取在Parallel循环中调用 ParallelLoopState.Break() 的最低循环迭代。 public long? LowestBreakIteration { get; } // 获取循环的当前迭代是否应基于此迭代或其他迭代发出的请求退出。 public bool ShouldExitCurrentIteration { get; } //通知Parallel循环当前迭代”之后”的其他迭代不需要运行。 public void Break(); //通知Parallel循环当前迭代“之外”的所有其他迭代不需要运行。 public void Stop();} |
a) Break()
Break()用于通知Parallel循环当前迭代“之后”的其他迭代不需要运行。例如,对于从 0 到 1000 并行迭代的 for 循环,如果在第 100 次迭代调用 Break(),则低于 100 的所有迭代仍会运行(即使还未开始处理),并在退出循环之前处理完。从 101 到 1000 中还未开启的迭代则会被放弃。
对于已经在执行的长时间运行迭代,Break()将为已运行还未结束的迭代对应ParallelLoopResult结构的LowestBreakIteration属性设置为调用Bread()迭代项的索引。
b) Stop()
Stop() 用于通知Parallel循环当前迭代“之外”的所有其他迭代不需要运行,无论它们是位于当前迭代的上方还是下方。
对于已经在执行的长时间运行迭代,可以检查 IsStopped属性,在观测到是 true 时提前退出。
Stop 通常在基于搜索的算法中使用,在找到一个结果之后就不需要执行其他任何迭代。(比如在看视频或漫画时自动匹配响应最快的服务器)
c) ShouldExitCurrentIteration 属性
当循环的迭代调用 Break 或 Stop时,或一个迭代引发异常,或取消循环时,Parallel 类将主动尝试禁止开始执行循环的其他迭代。但是,可能有无法阻止其他迭代启动的情况。也可能是长时间运行的迭代已经开始执行的情况。在此类情况下,迭代可以通过显式检查 ShouldExitCurrentIteration 属性,在该属性返回 true 时停止执行。
5) 委托函数:localInit,body,localFinally(委托中注意并行访问问题)
a) localInit 用于返回每个线程的本地数据的初始状态的委托。
b) body 将为每个迭代调用一次的委托。
c) localFinally 用于对每个线程的本地状态执行一个最终操作的委托。
对于参与循环执行的每个线程调用一次 localInit 委托(每个分区一个线程),并返回每个线程的初始本地状态。这些初始状态传递到每个线程上的第一个 body 调用。然后,该线程的每个后续body调用返回可能修改过的状态值,并传递给下一个body调用。最后,每个线程上最后body调用的返回值传递给 localFinally 委托。每个线程调用一次 localFinally 委托,以对每个线程的本地状态执行最终操作。
Parallel.For中三个委托执行流程如下:
i. 分区依据:Parallel.For也会为集合进行分区,分区算法由FCL内部RangeManger对象提供,以提供负载平衡。
ii. RangeManger根据最大并发度将集合源拆分为多个小集合,再并行访问其对应的RangeWorker的FindNewWork() 返回当前分区中是否还有迭代元素bool值。(FindNewWork()实现为无锁(Interlocked)循环结构)
iii. 三个委托之间的变量值传递由内部声明的局部变量支持。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | // 整体思路:依据内置RangeManger算法分区,再由多个线程“并行”执行下面委托// 第一步:Action action =()=> { try { localInit(); Label_00FF: body(); if(RangeWorker.FindNewWork()) { Goto Lable_00FF; } } catch(){} finaly { localFinally(); } }// 第二步:再将action传递给Task的内部派生类ParallelForReplicatingTask,// 根据最大并发级别(ParallelOptions.MaxDegreeOfParallelism)进行并行调用 |
6) 示例:(ParallelTest.cs,带本地变量的Parallel.For)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | public static void Parallel_For_Local_Test(){ int[] nums = Enumerable.Range(0, 1000000).ToArray<int>(); long total = 0; ParallelLoopResult result = Parallel.For<long>(0, nums.Length, () => { return 0; }, (j, loop, subtotal) => { // 延长任务时间,更方便观察下面得出的结论 Thread.SpinWait(200); Console.WriteLine("当前线程ID为:{0},j为{1},subtotal为:{2}。" , Thread.CurrentThread.ManagedThreadId, j.ToString(), subtotal.ToString()); if (j == 23) loop.Break(); if (j > loop.LowestBreakIteration) { Thread.Sleep(4000); Console.WriteLine("j为{0},等待4s种,用于判断已开启且大于阻断迭代是否会运行完。", j.ToString()); } Console.WriteLine("j为{0},LowestBreakIteration为:{1}", j.ToString(), loop.LowestBreakIteration); subtotal += nums[j]; return subtotal; }, (finalResult) => Interlocked.Add(ref total, finalResult) ); Console.WriteLine("total值为:{0}", total.ToString()); if (result.IsCompleted) Console.WriteLine("循环执行完毕"); else Console.WriteLine("{0}" , result.LowestBreakIteration.HasValue ? "调用了Break()阻断循环." : "调用了Stop()终止循环.");} |
运行截图:
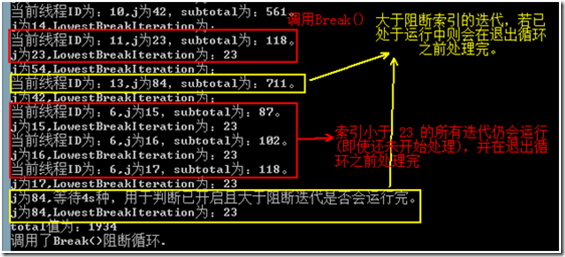
分析一下:
a) 泛型类型参数TLocal为本地线程数据类型,本示例设置为long。
b) 三个委托的参数解析body(j, loop, subtotal):首先初始委托localInit中返回了0,所以body委托中参数subtotal的初始值即为0,body委托的参数j对应的是当前迭代索引,参数loop为当前迭代状态ParallelLoopState对象;localFinally委托参数为body委托的返回值。
c) 三个委托三个阶段中都可能并行运行,因此您必须同步对任何共享变量的访问,如示例中在finally委托中使用了System.Threading.Interlocked对象。
d) 在索引为23的迭代中调用Break()后:
i. 索引小于23的所有迭代仍会运行(即使还未开始处理),并在退出循环之前处理完。
ii. 索引大于 23 的迭代若还未开启则会被放弃;若已处于运行中则会在退出循环之前处理完。
e) 对于调用Break()之后,在任何循环迭代中访问LowestBreakIteration属性都会返回调用Break()的迭代对应的索引。
2. Parallel.Foreach
为给定数目的独立ForEach循环迭代提供了负载均衡的潜在并行执行。这个方法还支持自定义分区程序(抽象类Partitioner<TSource>),让你可以完全掌控数据分发。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | // 对 System.Collections.IEnumerable 执行foreach 操作。public static ParallelLoopResult ForEach<TSource>(IEnumerable<TSource> source , ParallelOptions parallelOptions, Action<TSource, ParallelLoopState> body);// 对 System.Collections.IEnumerable 执行具有 64 位索引的 foreach 操作。public static ParallelLoopResult ForEach<TSource>(IEnumerable<TSource> source , ParallelOptions parallelOptions, Action<TSource, ParallelLoopState, long> body);// 对 System.Collections.IEnumerable 执行具有线程本地数据的 foreach 操作。public static ParallelLoopResult ForEach<TSource, TLocal>(IEnumerable<TSource> source , ParallelOptions parallelOptions, Func<TLocal> localInit , Func<TSource, ParallelLoopState, TLocal, TLocal> body, Action<TLocal> localFinally);// 对 System.Collections.IEnumerable 执行具有线程本地数据和 64 位索引的 foreach 操作。public static ParallelLoopResult ForEach<TSource, TLocal>(IEnumerable<TSource> source , ParallelOptions parallelOptions, Func<TLocal> localInit , Func<TSource, ParallelLoopState, long, TLocal, TLocal> body, Action<TLocal> localFinally); |
1) 如果打算要在 ForEach 方法中使用分区程序,你必须支持动态数量的分区,即:
a) 在Partitioner<TSource>的派生类中重写 GetDynamicPartitions() 方法和 SupportsDynamicPartitions属性
b) 在OrderablePartitioner<TSource>派生类中重写GetOrderableDynamicPartitions() 方法和SupportsDynamicPartitions 属性。
分区程序能够在循环执行过程中随时按需为新分区提供枚举器。基本上,每当循环添加一个新并行任务时,它都会为该任务请求一个新分区。动态数量的分区程序在本质上也是负载平衡的。
2) Parallel.ForEach还支持集合源为Partitioner<TSource>类型的重载,此重载不提供迭代索引。其中Partitioner<TSource>表示将一个数据源拆分成多个分区的特定方式。
| 1 2 3 4 5 6 7 8 9 10 11 12 | public abstract class Partitioner<TSource> // partitioner [pa:'tiʃənə]瓜分者,分割者{ protected Partitioner(); // 获取是否可以动态创建附加分区。 public virtual bool SupportsDynamicPartitions { get; } // 将基础集合分区成给定数目的分区,参数partitionCount为要创建的分区数。 // 返回一个包含 partitionCount 枚举器的列表。 public abstract IList<IEnumerator<TSource>> GetPartitions(int partitionCount); // 创建一个可将基础集合分区成可变数目的分区的对象。 // 返回一个可针对基础数据源创建分区的对象。 public virtual IEnumerable<TSource> GetDynamicPartitions();} |
示例见:CustomerPartitioner.cs
3) Parallel.ForEach还支持集合源为OrderablePartitioner<TSource>类型的重载。OrderablePartitioner<TSource>表示将一个可排序数据源拆分成多个分区的特定方式,因此次重载提供迭代索引。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | public abstract class OrderablePartitioner<TSource> : Partitioner<TSource>{ // 从派生类中的构造函数进行调用以便使用索引键上指定的约束初始化 OrderablePartitioner<TSource> protected OrderablePartitioner(bool keysOrderedInEachPartition , bool keysOrderedAcrossPartitions, bool keysNormalized); // 获取是否按键增加的顺序生成每个分区中的元素。 public bool KeysOrderedInEachPartition { get; } // 获取前一分区中的元素是否始终排在后一分区中的元素之前。 public bool KeysOrderedAcrossPartitions { get; } // 获取是否规范化顺序键。如果为 true,则所有顺序键为 [0 .. numberOfElements-1]。 // 如果为 false,顺序键仍必须互不相同,但只考虑其相对顺序,而不考虑其绝对值。 public bool KeysNormalized { get; } // 将基础集合分区成给定数目的可排序分区。 public override IList<IEnumerator<TSource>> GetPartitions(int partitionCount); // 创建一个可将基础集合分区成可变数目的分区的对象。 public override IEnumerable<TSource> GetDynamicPartitions(); // 创建一个可将基础集合分区成可变数目的分区的对象。 public virtual IEnumerable<KeyValuePair<long, TSource>> GetOrderableDynamicPartitions(); // 将基础集合分区成指定数目的可排序分区。 public abstract IList<IEnumerator<KeyValuePair<long, TSource>>> GetOrderablePartitions(int partitionCount);} |
三个bool值为true所要遵循的规则:
a) KeysOrderedInEachPartition :每个分区返回具有不断增加的键索引的元素。
b) KeysOrderedAcrossPartitions :对于返回的所有分区,分区 i 中的键索引大于分区 i-1 中的键索引。
c) KeysNormalized :所有键索引将从零开始单调递增(没有间隔)。
示例见:CustomerOrderablePartitioner.cs
4) ForEach中的3个委托调用流程:(委托中注意并行访问问题)
a) 对于Parallel.ForEach()使用IEnumerable<TSource>集合重载的循环,会转化为Parallel.For()循环调用逻辑。
b) 对于使用OrderablePartitioner<TSource>或Partitioner<TSource>派生类构造的自定义分区的循环逻辑如下:
i. 分区依据:由OrderablePartitioner<TSource>或Partitioner<TSource>派生类提供自定义分区算法,注意要重写动态数量分区相关方法。
ii. 在各个线程中,先取缓存中的enumerator,若没有才会获取动态分区(即每个线程的动态分区只会获取一次)
iii. 三个委托之间的变量值传递由内部声明局部变量支持。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | // 总体思路:依据自定义算法分区,再由多个线程“并行”执行下面代码// 第一步:Action action = ()=>{ try { localInit(); // 在各个线程中,先取缓存中的enumerator,若没有才会获取动态分区(即每个线程的动态分区只会获取一次) var enumerator = OrderablePartitioner<TSource>.GetOrderableDynamicPartitions(); // 若为Partitioner<TSource>对象,则var enumerator = Partitioner<TSource>.GetDynamicPartitions(); while(enumerator.MoveNext()) { body(); } } catch(){} finaly { localFinally(); }}// 第二步:再将action传递给Task的内部派生类ParallelForReplicatingTask,// 它根据最大并发级别(ParallelOptions. MaxDegreeOfParallelism)进行并行调用. |
5) 分析一个重载
| 1 2 3 | public static ParallelLoopResult ForEach<TSource, TLocal>(IEnumerable<TSource> source , ParallelOptions parallelOptions, Func<TLocal> localInit , Func<TSource, ParallelLoopState, long, TLocal, TLocal> body, Action<TLocal> localFinally); |
a) 返回ParallelLoopResult结构;泛型参数TSource指定集合源元素的类型,泛型参数TLocal指定线程本地变量的类型。
b) Func<TSource, ParallelLoopState, long, TLocal, TLocal> body委托参数解析:TSource为集合迭代特定项;ParallelLoopState为循环迭代项状态;long为迭代索引;第一个TLocal为localInit委托返回的初始值;第二个TLocal为body委托自身返回值类型。
示例:(详见:ParallelTest.cs)
| 1 2 3 4 5 6 7 8 9 10 11 12 | int[] nums = Enumerable.Range(100, 1000000).ToArray<int>();long total = 0;Parallel.ForEach<int, long>(nums, () => { return 0; }, (j, loop, index, subtotal) => { subtotal += j; Console.WriteLine("索引为{0},当前项值为{1}.", index.ToString(), j.ToString()); return subtotal; }, (finalResult) => Interlocked.Add(ref total, finalResult)); |
6) 将 ForEach 用于非泛型集合
可以用System.Linq命名空间中IEnumerable扩展API的 Cast<TResult>() 方法将集合转换为泛型集合。
| 1 2 3 4 5 6 7 8 9 10 11 | // 扩展APIpublic static class Enumerable{ …… public static IEnumerable<TResult> Cast<TResult>(this IEnumerable source);}// 示例System.Collections.ArrayList fruits = new System.Collections.ArrayList();fruits.Add("apple");fruits.Add("mango");IEnumerable<string> query = fruits.Cast<string>(); |
Parallel.Invoke
对给定的独立任务提供潜在的并行执行。
| 1 2 | public static void Invoke(params Action[] actions);public static void Invoke(ParallelOptions parallelOptions, params Action[] actions); |
Invoke内部通过Task.Factory.StartNew()来为每个委托参数创建并开启任务并且在最后调用Task.WaitAll(Tasks[])来等待所有任务执行完成,所以此方法在每个提供的操作都完成后才会返回,与完成是因为正常终止还是异常终止无关。
注意点:
1) 如果使用Parallel.Invoke加载运行委托的时间迥异,那么依需要最长时间的委托才能返回控制;并且还要考虑逻辑内核的使用情况,因为可能出现有单独一个委托被延迟到后面单独执行。
2) 在并行可扩展方面具有一定的局限性,因为Parallel.Invoke调用的是固定数目的委托。
3) 不能保证操作的执行顺序或是否并行执行。
分区程序
若要对数据源操作进行并行化,其中一个必要步骤是将源分区为可由多个线程同时访问的多个部分。
1. Parallel支持的两种分区程序:
1) 默认分区程序:”PLINQ并行查询”或“并行循环”提供了默认的分区程序,该分区程序将以透明方式工作,即Parallel.For() 中提到的RangeManage分区对象。
2) 自定义分区程序:在某些情况下(eg:一个自定义集合类,根据您对该类的内部结构的了解,您能够采用比默认分区程序更有效的方式对其进行分区。或者,根据您对在源集合中的不同位置处理元素所花费时间的了解,您可能需要创建大小不同的范围分区),可能值得通过继承OrderablePartitioner<TSource>或 Partitioner<TSource>抽象类实现您自己的分区程序。
2. 两种分区类型
1) 按范围分区(属于静态数量的分区):
a) 适用于数据和其他已建立索引的集合源(eg:IList集合);
b) 并行循环或PLINQ查询中的每个线程或任务分别接收唯一的开始和结束索引,以便在处理集合源时,不会覆盖任何其他线程或被任何其他线程覆盖;
c) 同步开销:涉及的唯一同步开销是创建范围的初始工作;
d) 缺点:如果一个线程提前完成,它将无法帮助其他线程完成它们的工作。
示例关键代码:
| 1 2 3 4 5 6 7 8 9 | var rangePartitioner = Partitioner.Create(0, source.Length);double[] results = new double[source.Length];Parallel.ForEach(rangePartitioner, (range, loopState) =>{ for (int i = range.Item1; i < range.Item2; i++) { results[i] = source[i] * Math.PI; }}); |
注意这个示例用范围还有一个优势:因为该示例主体开销非常小,倘若不使用范围分区,那么频繁调用主体委托会使并行循环效率更低。而依范围分区后,就使得一个区只会产生一次主体委托调用的开销。
2) 按区块分区(属于动态数量的分区):
a) 适用于长度未知的链接列表或其他集合;
b) 并行循环或PLINQ查询中的每个线程或任务分别处理一个区块中一定数量的源元素,然后返回检索其他元素。
c) 区块的大小可以任意(即使大小为1)。只要区块不是太大,这种分区在本质上是负载平衡的,原因是为线程分配元素的操作不是预先确定的;
d) 同步开销:当线程需要获取另一个区块时,都会产生同步开销;
示例关键代码:(详见MyDynamicOrderablePartitioner.cs文件)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | // 分区程序public override IEnumerable<KeyValuePair<long, TSource>> GetOrderableDynamicPartitions(){ return new ListDynamicPartitions(m_input);}// 枚举对象private class ListDynamicPartitions : IEnumerable<KeyValuePair<long, TSource>>{ private IList<TSource> m_input; private int m_pos = 0; public IEnumerator<KeyValuePair<long, TSource>> GetEnumerator() { while (true) { // 由于使用到公共资源只有m_pos值类型索引,所以只需要保证m_pos访问的原子性 int elemIndex = Interlocked.Increment(ref m_pos) - 1; if (elemIndex >= m_input.Count) { yield break; } yield return new KeyValuePair<long, TSource>(elemIndex, m_input[elemIndex]); } } …… } |
自定义分区程序
我们已经知道通过继承OrderablePartitioner<TSource>或 Partitioner<TSource>抽象类我们可以针对特定场合实现自己的分区程序。
下面展出一个示例,这个示例给我们展示了如何构建一个分区程序,这个示例为我们演示了“动态数量分区结合Parallel.ForEach()”和“静态数量分区结合Parallel.Invoke()”的使用方式。
示例见:CustomerPartitioner.cs
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | class SingleElementPartitioner<T> : Partitioner<T>{ …… }public static void Test(){ String[] collection = new string[]{"red", "orange", "yellow", "green", "blue", "indigo", "violet", "black", "white", "grey"}; SingleElementPartitioner<string> myPart = new SingleElementPartitioner<string>(collection); Console.WriteLine("示例:Parallel.ForEach"); Parallel.ForEach(myPart, item => { Console.WriteLine(" item = {0}, thread id = {1}" , item, Thread.CurrentThread.ManagedThreadId); } ); Console.WriteLine("静态数量的分区:2个分区,2个任务"); var staticPartitions = myPart.GetPartitions(2); int index = 0; Action staticAction = () => { int myIndex = Interlocked.Increment(ref index) - 1; var myItems = staticPartitions[myIndex]; int id = Thread.CurrentThread.ManagedThreadId; while (myItems.MoveNext()) { // 保证多个线程有机会执行 Thread.Sleep(50); Console.WriteLine(" item = {0}, thread id = {1}" , myItems.Current, Thread.CurrentThread.ManagedThreadId); } myItems.Dispose(); }; Parallel.Invoke(staticAction, staticAction); Console.WriteLine("动态分区: 3个任务 "); var dynamicPartitions = myPart.GetDynamicPartitions(); Action dynamicAction = () => { var enumerator = dynamicPartitions.GetEnumerator(); int id = Thread.CurrentThread.ManagedThreadId; while (enumerator.MoveNext()) { Thread.Sleep(50); Console.WriteLine(" item = {0}, thread id = {1}", enumerator.Current, id); } }; Parallel.Invoke(dynamicAction, dynamicAction, dynamicAction);} |
快速创建可排序分区
.NET为我们提供的System.Collections.Concurrent.Partitioner 对象可实现快速获得可排序分区的方式。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | namespace System.Collections.Concurrent{ // 提供针对数组、列表和可枚举项的常见分区策略,创建一个可排序分区程序。 public static class Partitioner { // 参数: // loadBalance:该值指示创建的分区程序是否应在各分区之间保持动态负载平衡,而不是静态负载平衡。 // EnumerablePartitionerOptions:控制分区缓冲行为的选项。 // rangeSize:每个子范围的大小。 // 范围:fromInclusive <= 范围< toExclusive public static OrderablePartitioner<TSource> Create<TSource>(IEnumerable<TSource> source); public static OrderablePartitioner<TSource> Create<TSource>(IEnumerable<TSource> source, EnumerablePartitionerOptions partitionerOptions); public static OrderablePartitioner<TSource> Create<TSource>(IList<TSource> list, bool loadBalance); public static OrderablePartitioner<Tuple<int, int>> Create(int fromInclusive, int toExclusive); public static OrderablePartitioner<Tuple<long, long>> Create(long fromInclusive, long toExclusive); public static OrderablePartitioner<TSource> Create<TSource>(TSource[] array, bool loadBalance); public static OrderablePartitioner<Tuple<int, int>> Create(int fromInclusive, int toExclusive, int rangeSize); public static OrderablePartitioner<Tuple<long, long>> Create(long fromInclusive, long toExclusive, long rangeSize);} [Flags][Serializable] public enum EnumerablePartitionerOptions { None = 0, NoBuffering = 1, }} |
1. Partitioner.Create创建的分区与负载平衡
| Partitioner.Create重载 | 负载平衡 |
| Create<TSource>(IEnumerable<TSource>) | 始终 |
| Create<TSource>(TSource[], Boolean) Create<TSource>(IList<TSource>, Boolean) | 将布尔型参数指定为 true 时 |
| Create(Int32, Int32) Create(Int32, Int32, Int32) Create(Int64, Int64) Create(Int64, Int64, Int64) | 从不 |
2. EnumerablePartitionerOptions
将EnumerablePartitionerOptions枚举传递给Partitioner.Create()用于指示在快速创建分区时是否启用缓存提高来实现最优性能。
1) 当传递EnumerablePartitionerOptions.None时,指示默认为启用缓存。在分好区后,每个线程会加锁,在临界区中,第一次迭代获取该分区元素时,会获取这一分区的所有迭代元素并缓存下来。
2) 当传递EnumerablePartitionerOptions.NoBuffering时,指示为不启用缓存。每个线程会加锁,在临界区中,每次迭代都从同一个集合源获取需要的一个迭代元素,因为每次只获取一个,所以也不会再进行分区。
处理并行循环中的异常
Parallel的For和 ForEach 重载没有任何用于处理可能引发的异常的特殊机制。并行循环中的异常处理逻辑需要处理可能在多个线程上同时引发类似异常的情况,以及一个线程上引发的异常导致在另一个线程上引发另一个异常的情况。通过将循环中的所有异常包装在 System.AggregateException 中。eg:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | try{ // 在 ProcessDataInParallel 抛出 throw new ArgumentException(); ProcessDataInParallel(data);}catch (AggregateException ae){ foreach (var ex in ae.InnerExceptions) { if (ex is ArgumentException) Console.WriteLine(ex.Message); else throw ex; }} |
注意事项
1. 在做性能测试时,请避免在循环内进行诸如 Console.WriteLine,Debug.Write 等调用。因为同步调用共享资源(如控制台或文件系统)将大幅降低并行循环的性能
2. 将串行代码转化为并行代码,需要检查可并行化的热点。
热点指的是代码中消费大量时间运行的部分,这是算法性能的瓶颈。如果热点可以被分解为很多能并行运行的部分,那么热点就可以获得加速。但如果被分解为多部分代码的单体并没有消费大量的运行时间,那么TPL所引入的开销就有可能会完全消减并行化带来的加速,甚至可能导致并行化的代码比串行化代码运行得还慢。(TPL所引入的开销:在转化过程中,我们常常需要将方法的局部变量变为委托方法的内部变量以创建安全无状态的并行化代码,这样的变化会让每次迭代执行更多指令;另外还增加了大量的内存分配操作,这也会致使垃圾回收器(GC)触发的更频繁)
3. 避免过度并行化
倘若对操作过度并行化,那么并行循环很可能比顺序循环的运行速度还慢。规则:
a) 嵌套循环中只对外部循环进行并行化。
b) 对于body委托开销小而循环次数多的情况,可以采取按范围分区的方式。
c) 循环中很多次迭代都不执行。
4. 不要调用非线程安全的方法。对于线程安全方法的调用也要清楚内部同步消耗,来判断是否应该使用并行化方式。
5. 避免在UI线程上执行并行循环。应该使用任务封装并行循环,比如:
| 1 2 3 4 5 6 7 8 9 | private void button1_Click(object sender, EventArgs e){ Task.Factory.StartNew(() => Parallel.For(0, N, i => { button1.Invoke((Action)delegate { DisplayProgress(i); }); }) );} |
6. 在由 Parallel.Invoke 调用的委托中等待时要小心
在某些情况下,当等待任务时,该任务可在正在执行等待操作的线程上以同步方式执行(详见:局部队列内联机制)。这样可提高性能,因为它利用了将以其他方式阻止的现有线程,因此不需要附加线程。但此性能优化在某些情况下可能会导致死锁。例如,两个任务可能运行相同的委托代码,该代码在事件发生时发出信号,并等待另一个任务发出信号。如果在相同线程上将第二个任务内联到第一个,并且第一个任务进入等待状态,则第二个任务将永远无法发出其事件信号。为了避免发生这种情况,您可以在等待操作上指定超时,或使用 Thread 或 ThreadPool 来确保任务不会发生内联。
7. 不要假定 ForEach、For 和 ForAll 的迭代始终并行执行
请务必谨记,For、ForEach 或 ForAll<TSource> 循环中的迭代不一定并行执行。因此,您应避免编写任何依赖于并行执行的正确性或依赖于按任何特定顺序执行迭代的代码。例如,此代码有可能会死锁:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | ManualResetEventSlim mre = new ManualResetEventSlim();Enumerable.Range(0, Environment.ProcessorCount * 100) .AsParallel() .ForAll((j) => { if (j == Environment.ProcessorCount) { Console.WriteLine("Set on {0} with value of {1}", Thread.CurrentThread.ManagedThreadId, j); mre.Set(); } else { Console.WriteLine("Waiting on {0} with value of {1}", Thread.CurrentThread.ManagedThreadId, j); mre.Wait(); } }); //deadlocks |
在此示例中,一个迭代设置事件,而所有其他迭代则等待事件。 在事件设置迭代完成之前,任何等待迭代均无法完成。但是,在事件设置迭代有机会执行之前,等待迭代可能会阻止用于执行并行循环的所有线程。这将导致死锁–事件设置迭代将从不执行,并且等待迭代将从不觉醒。
本节博文内容到此结束,主要是解说了Parallel处理数据并行化的方式、Parallel迭代原理、分区原理、自定义分区以及使用Parallel的注意事项。接下来我会写一篇关于Task类的博文,敬请观赏。若此文对你有帮助,还请园友多帮推荐、推荐……
参考资料:MSDN

)
)




)


)







)
