今天是高端局,都是超级高大上的内容,惯例上目录

今天没有什么具体的栗子合集,大家的应用场景都很不一样,so,到具体知识点,我们再具体举栗子。
窗口函数
概念: 窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
基础语法
‹窗口函数› over (partition by ‹用于分组的列名›
order by ‹用于排序的列名›)关于这个语法点,下文会有详细的介绍
窗口函数分类
窗口函数总共分两类,一类是专用窗口函数,另一类是聚合函数
专用窗口函数
专用窗口函数大致又三个,rank(),, dense_rank(), row_number()三个,我们来一个一个看。
首先来看rank(),认真讲,这个大家应该很熟悉,作为窗口函数的用法,其实就是把rank()直接套进基础语法里面就可以了。
举个具体例子

我们要再每个班级内进行排名。
我们先来看看code怎么写
select *,rank() over (partition by 班级
order by 成绩 desc) as ranking from 班级表我们再来看看这个code里面的语法点。
先说不认识的,之前没见过的partition by,这个的作用跟group by差不多,就是对数据进行分组,我们的栗子里,就是对数据按照班级列进行分组。那partition by和group by有什么区别呢?我们为什么要学习两个功能相同的函数呢?
这是因为,group by汇总分组后,改变了表原有的行数,一行只有一个类别。而partition by和rank 函数,则不会改变原表的行数。


dense_rank,其实也是对函数进行排名。而row_number则是显示出每一行的行号。
举个栗子
select *, rank() over (order by 成绩 desc) as ranking,dense_rank() over (order by 成绩 desc) as dese_rank,row_number() over (order by 成绩 desc) as row_numfrom 班级表;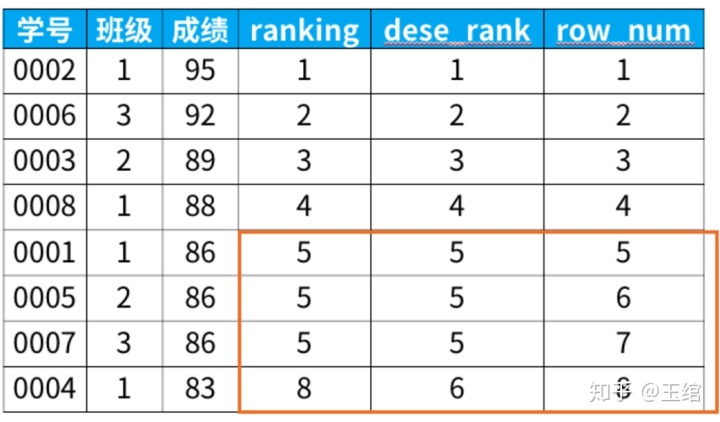
橘色框框的地方,其实就是重点显示它们三者不同之处的地方。说完了专用窗口函数,我们再来说说聚合窗口函数
聚合窗口函数
我们常说的聚合函数,其实就是,sum(), avg(),count(),min(),max()这些,这波又是一个code帮你搞定聚合窗口函数系列
select *, sum(成绩) over (order by 学号) as current_sum,avg(成绩) over (order by 学号) as current_avg,
count(成绩) over (order by 学号) as current_count,
max(成绩) over (order by 学号) as current_max,
min(成绩) over (order by 学号) as current_min from 班级表;输出结果
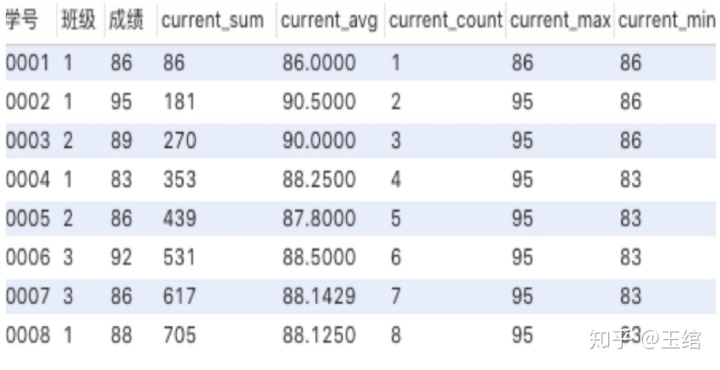
如果想要知道所有人成绩的总和、平均等聚合结果,看最后一行即可。
这样使用窗口函数有什么用呢?聚合函数作为窗口函数,可以在每一行的数据里直观的看到,截止到本行数据,统计数据是多少(最大值、最小值等)。同时可以看出每一行数据,对整体统计数据的影响。
avg()作为窗口函数时,如果我们想对返回数据做出限制的时候,一般情况下,我们会想到使用where语句。例如,我们要返回,比平均成绩高的学生。
select *,
avg(成绩) over (partition by 科目) as avg_score from 成绩表 where 成绩 › avg_score;但是这么写,SQL会出现错误,为什么呢?
记得我们之前重复了无数次的,SQL运行顺序嘛?再来复习一次。
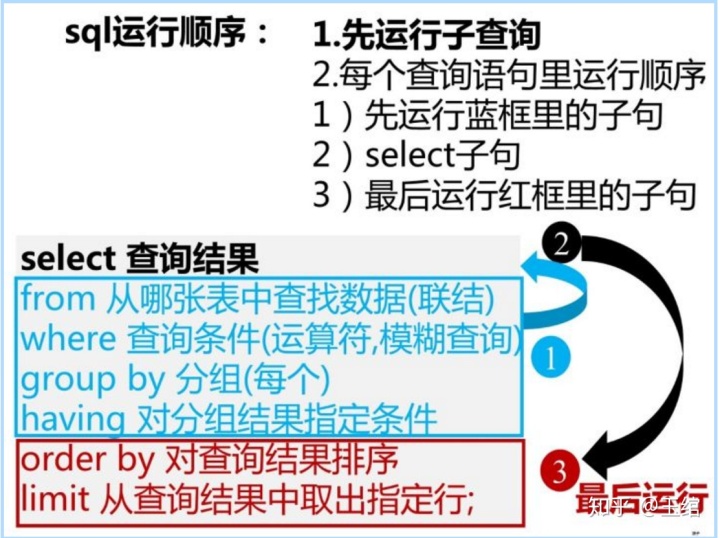
在我们,运行到,where语句的时候,我们在select里面求的平均值,根本都还没有运行,所以这个where条件没有办法执行。
解决方法:子查询
select * from
(select *, avg(成绩) over (partition by 科目) as avg_score from 成绩表) as b
where 成绩 › avg_score;窗口函数的移动平均
select *, avg(成绩) over (order by 学号 rows 2 preceding) as current_avg from 班级表;
出现了新的关键词!!!rows 2 preceding,欢迎大家来到英语翻译训练营,在这里rows 2 preceding 是说,之前两行。用在这里就是表明,结果就是自身记录及其前两行记录的平均。
注意事项
- 在上述的这三个专用窗口函数中,函数后面的括号不需要任何参数,保持()空着就可以,但是()不可省略。
- 窗口函数原则上只能写在select子句中。
- partition子句可是省略,就仅是按照成绩进行排序。
- 窗口函数,不减少原表的行数,所以经常用来在每组内排名。但是group by会减少原表行数(例如,同一组内两个最高分均为80,我们如果用group by就会只筛选出来一个。)
窗口函数使用场景
- 组内Top N 排名问题
- 累计求和
- 组内比较问题(eg.查找组内大于平均值数据)
SQL存储过程
概念: 这个存储过程,本质上就是记录记录和呼叫重复行为的语句。
分类 : 无参数存储过程,有参数存储过程以及默认参数存储过程
无参数存储过程
定义过程
create procedure 存储过程名称() begin ‹sql语句› ; end;呼叫过程
call 存储过程名称();有参数存储过程
定义过程
create procedure 存储过程名称(参数1,参数2,...) begin ‹sql语句› ; end;呼叫过程同上。
这个举个栗子,
比如,我要找到,学号为0001的学生姓名,这个过程,我不能直接定义学号0001叭,那万一,我下次要找学号为0002的学生呢?如果只能用一次,这个存储过程不久没意义了嘛!所以这个定义过程,应该是
create procedure getNum(num varchar(100))
begin select 姓名 from 学生表 where 学号=num; end;getNum后面定义值和值的类型。
然后,呼叫函数的时候,可以直接写成
call getNum(0001);就可以找到学号为0001的学生的姓名啦。
默认参数的储存过程
最后我们来说说,默认参数存储过程。
依然还是分三种,IN, OUT, INOUT(我没有在跳健身操,真的。)
IN 输入参数:参数初始值在存储过程前被指定为默认值,在存储过程中修改该参数的值不能被返回
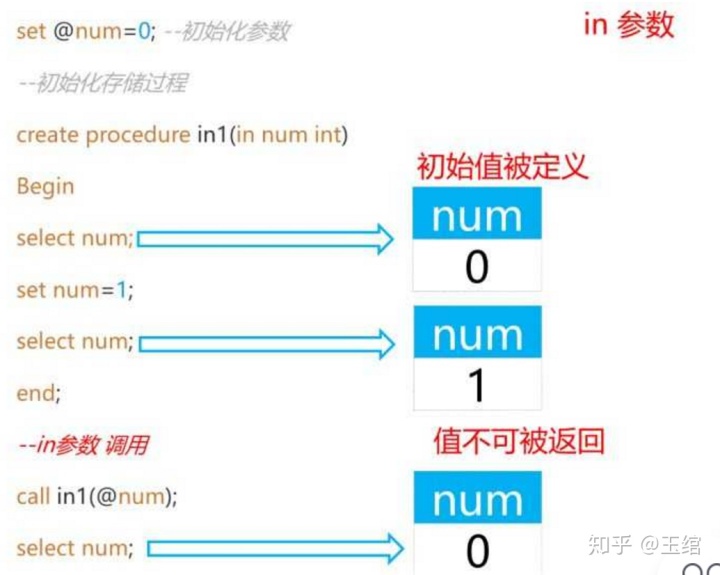
总结下来就是,我不管你怎么改,但是我改不认同,就是不认,最开始是多少就是多少。
OUT输出参数:参数初始值为空,该值可在存储过程内部被改变,并可返回
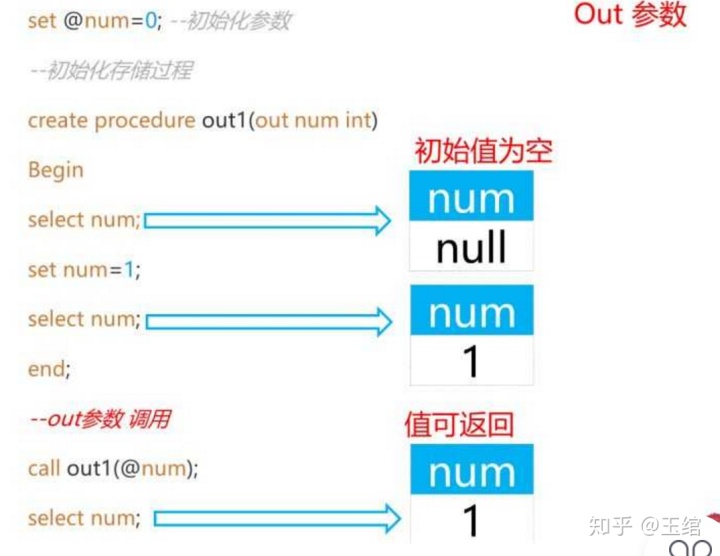
该改还是得改的OUT。
INOUT输入输出参数:参数初始值在存储过程前被指定为默认值,并且可在存储过程中被改变和在调用完毕后可被返回
注意事项
- 定义存储过程语法里的SQL语句代码块必须是完整的sql语句,必须用“;”结尾
- 定义的储存过程的名字,不可重复,否则会引起系统报错
- 存储过程和视图在实际应用中有什么区别
- 视图只是一段固定的sql语句,方便重复查询;
- 存储过程约等于编程,可以实现复杂的操作,例如传参、建表、写入、数据同步等过程。业务比较复杂、重复性工作比较多,存储过程会比较实用。
- 把重复要做的事情整理成一步一步的业务步骤,然后把业务步骤写成sql语句,然后再把sql语句写到存储过程的语法里。就像自动驾驶一样,把可能遇到的状况提前规划好,就不需要自己操纵方向盘,车子就按照我们写的步骤向前开了。
优缺点:
优点: 执行速度非常非常快,效率很高
缺点: 很难迁移到别的数据库。
鉴于这个缺点,所以这个存储过程的知识点,做个了解就好啦!不是太常用~今天的分享就到这里啦!









)









